December 30, 2005
A Schlocky Delight
 I received a marvellous Chrismas present from my friend Jenny: a sculpture of Schlock made of marzipan! It is even Schlock's current appearance.
I received a marvellous Chrismas present from my friend Jenny: a sculpture of Schlock made of marzipan! It is even Schlock's current appearance.
For those of my readers who don't know, Schlock Mercenary is one of my favorite webcomics. A mixture of military sf, humor and consistent physics. Besides, who can resist cute megalomaniacal AI-gods with humorous ship naming practices?
The next step is of course to engage in immune system combat with my Schlock. There can only be one!
December 28, 2005
Google Claus
 This week's CNE blog is about the question whether Google is Santa Claus. Google is becoming an increasingly useful resource in medicine, and a BMJ editorial suggests that a Google Medicine a la Google Scholar. This is seems like a good idea.
This week's CNE blog is about the question whether Google is Santa Claus. Google is becoming an increasingly useful resource in medicine, and a BMJ editorial suggests that a Google Medicine a la Google Scholar. This is seems like a good idea.
Here are some thinking I have been doing on the subject. This might be just me reinventing the wheel, but it is fun to consider how to build such a subject specific search engine.
Subject specific search engines are usually fairly handmade, with resources indexed based on submission or added by hand. They are little more than online indexes or database portals. This means a high concentration of high-relevance resources like Pubmed and publisher's websites, but also that there will be little of the totally unexpected resources that emerge rapidly and spontaneously - if someone comes up with (say) a great neurology wiki it will not be indexed. Relying on authors to submit sites moves us back to the bad old days when the only game in town was Yahoo.
So maybe we should start looking for automated detection of (say) scholarly and medical content. At least for certain fields there are language pecularities and other patterns that might be detectable in text mining, allowing an indexer to at least preliminarily categorize pages into fields. Texts contains literature references (in a particular style), uses terms like efferent or TFIDF or links to certain sites the probability of it being a particular field can be estimated. Once many pages have been categorized loosely network methods can be used to find core community within them.
The first problem is of course finding what signifies field membership. Having a big pile of example websites from medicine, engineering and politics can of course be used to train a Bayesian estimator using term frequencies. Hong Qu, Andrea La Pietra and Sarah Poon Blogs Classification Using NLP Techniques show that one can use fairly simple Bayesian analysis to classify blog subjects crudely.
Fritz Heckel and Nick Ward, Political Blog Analysis Using Bootstrapping Techniques use text mining methods to build a lexicon of political words from example blogs and then a SOM to map blogs using these lexicon words as features. This seems to work well in classifying them, and the same principle ought to work to build a lexicon of field-specific words that can be used to find field-related sites.
These blog studies are interesting in themselves, but also show that these methods are robust enough to deal with rather loosely themed sites. The real potential serependipty after all occurs when one include good sites in the search engine that may link to unexpected new subject areas.
Looking at link data gives a lot more information but also some problems. Miles Efron, The liberal media and right-wing conspiracies: using cocitation information to estimate political orientation in web documents uses co-citation to classify blogs into left- and right-wing blogs with quite good success. The orientation is estimated by taking two sets of blogs R and L (where R are rightwing blogs and L leftwing blogs) and then using the mutual information of co-citation: the leaning of the blog b is log2[(# of links to b shared with R)(# of links to L)/(# of links to b shared with L)(# of links to R) ].
But a kind of website (e.g. medical resource or roleplaying site) is probably just a very small subset of the set of all websites, making the estimator biased since the ratio of the counting terms (# of links to sites in the field)/(# of links to sites not in the field) becomes very small. A bit of fun calculation (at least I liked it, since I learned some new stuff here):
If there are on the order of 75 million websites and if we take a field like roleplaying we get around 4.3 million google hits and 573 million for medicine (this is of course a big overestimate since it counts all sites referring to the subject). A HP study shows that the number of pages per website follows a power law (as always) and re-binned I get an average number of pages per site around 10. (these links were found thanks to a good Google Answer, by the way - another present from Google Claus).
Hence there are less than 430,000 roleplaying sites and 57 million medicine sites, a fraction of 0.0057 and 0.76 respectively. Clearly Internet is mainly about medicine! A big surprise, I thought it was about porn.
But making a Google Roleplaying or a Google Medicine would mean looking at the top sites in each category, the ones with lots of information. I was surprised by the small number of really big sites: just 4790 have more than 100 pages in the HP survey (this is probably an underestimate due to the crawler not indexing database driven sites and many blogs). Assuming the same fractions as above, that means there are maybe 3000 big medical sites and 28 really big rpg sites (here clearly we get an underestimate for the rpgs). These are the ones we want to find. But the ratios of 28 or 3000 to 75 million are rather small, producing a bias on the order of -21 and -14 (log2 used) to the classification. Even broadening the search to much less central sites we will still get a heavy bias in the co-citation search. By default, most sites can safely be assumed not to be about the field we are looking for. At least we would need to take this into account when calculating whether to include them in the bootstrapping set.
So my sketch of how to build your own subject search engine would be something like:
Select a number of example sites of the field we want. Use these to bootrap a lexicon of terminology used in them, hyperlink patterns and possibly website features. Dig up a large set of sites that fit this terminology and features. This would correspond to sites within the field, but most will likely not be high quality. Use PageRank or something similar on this set to find the authorities and hubs of the field. Index these in the search engine.
December 25, 2005
Merry Newtonmass, Second Iteration
 A small addendum to the previous post. I just couldn't resist celebrating Newton by making a fractal portrait of him.
A small addendum to the previous post. I just couldn't resist celebrating Newton by making a fractal portrait of him.
I placed three different portrait images in the complex plane, centered on the roots of z3-1. I then used the usual Newton iteration formula for coloring each point after the color found in first the pixel of the portraits it ended up in. The number of iterations was used to darken the pixel, making the Julia set of the iteration appear in black.
The distortion of the right field is rather extreme and not too flattering, but it fits the warped personality of the guy.
Merry Newtonmass!
 This is the time of celebrating family, calories, capitalism, the solstice and Sir Isaac Newton, i.e. things that make life worth living!
This is the time of celebrating family, calories, capitalism, the solstice and Sir Isaac Newton, i.e. things that make life worth living!
Just to add some random content:
The BMJ is as usual filled with interesting tounge-in cheek studies. Dissappearance rates for teaspoons (seems to fit in nicely with the linen study a few years back), the use of Cinderella and other literary allusions in biomedical titles, hangover prevention and the accident-reducing effects of Harry Potter books.
On the humorous information design side, I found this wonderful series of charts answering "why you should continue to date me" (via information aesthetics).
On the information physics side, secure classical communication might be achievable using just two resistors, computers exhibit chaotic performance and quantum time travel seems to work fine as long as one accepts that the future is probabilistic, the past deterministic and there are huge probability currents along CTCs.
There is also a Christmas mini-grow. Grow is one of the most amazing game concepts I have come across, taking a combinatoric (I would guess NP-complete) problem and turning it into nice cartoon fun.
December 21, 2005
Nutrigastronomics
 Last week's CNE blog was CNE Eat Your Greens If You Have a Faulty Gluthatione s-transferase: how having faulty enzyme genes helps protect against (some) cancers.
Last week's CNE blog was CNE Eat Your Greens If You Have a Faulty Gluthatione s-transferase: how having faulty enzyme genes helps protect against (some) cancers.
It is not exactly surprising that there is a variation in how the body breaks down healthpromoting chemicals in food given how wide variations there are in drug metabolism.
As always when there is a new medical area, ethicists rush in. The concerns are largely the expected (when to market, consumer protection, privacy, equity and regulation). And again, the goal is to 'foster public debate' - if ethicists avoid being normative, they will leave the formulation of normative statements to non-ethicists.
Personally I have always thought that the real issue is nutrigastronomics: making use of genetic information to enhance the pleasures of the table. This goes beyond nutrition, molecular gastronomy and functional food. Recognizing supertasters is just the beginning: the next step would be to identify brain systems and metabolic variations that affect eating enjoyment. Of course, the step after that is to engineer ourselves so that we can enjoy a wider range of pleasant tastes, just like modified mice.
December 19, 2005
The Latest Aeon Emanation
 I just saw the Aeon Flux (2005) movie, and of course it is not very good. Even on its own, without comparision to the original it is not a very inspired movie. A friend of mine calls certain sequels "cuckoos": they parasitize on the good name of their original. But this movie manages to go one step further and seems to be philosophically opposed to its original. But unfortunately it is not by design.
I just saw the Aeon Flux (2005) movie, and of course it is not very good. Even on its own, without comparision to the original it is not a very inspired movie. A friend of mine calls certain sequels "cuckoos": they parasitize on the good name of their original. But this movie manages to go one step further and seems to be philosophically opposed to its original. But unfortunately it is not by design.
Lots of spoilers ahead, of course.
The basic plot is about how the utopia is (surprise!) imperfect and how people are clones of previous versions of themselves. The movie ends with a sermon about how good it is to be born the natural way, how living eternally is just faking it and how death gives life meaning. People wander hand in hand out into the messy jungle (nature) rather than stay in the manicured garden city (civilization). A very standard Romantic homily, seen a thousand times over in other movies and books.
As an immortalist I have always been curious about how people can be so sure about the inferiority of immortality if they have never encountered or tried it. The real answer is of course that people want these reassuring motherhood statements to bear their current mortality. I expect that when functional life extension becomes available these views will be quietly discarded by most.
Compare this with the theme of "A Last Time for Everything", the episode of the original series about cloning. Here cloning (or more properly, copying since it clearly copies memories and personality and not just the body) is still seen as threatening individuality, but only insofar it is misused. When Aeon clones herself the copies are shown to be divergent individuals and in the end it is a clone who succeeds the original.
The fault of the movie is that it does not dare to be weird or have unsettling conclusions. Of course, that is the standard Hollywood problem. In the series allegiances even of the major characters were uncertain; here everything has been made clear, even the relationship between Aeon and Trevor. Rather than take any chance the movie starts out with spelling out its backstory in an infodump rather than allowing it to emerge. As a character remarks, "Whatever we are, we are not anarchists. There has to be rules". This is the problem of the movie and why it is not interesting.
Another movie with a strong biotechnology theme is Code 46. It demonstrates that it is possible for a movie to venture out towards Aeonland without failing completely. It might not have the aesthetics or special effects of the Aeon movie, but it does have the acceptance of weirdness.
By the way, considering the name Aeon Flux and gnosticism, could Trevor and Aeon by any chance be a syzygy, Ialdabaoth (the demiurge) and Sophia (the liberator)? It is too neat and elegant, so I think Chung just made up the name.
I think this is true for much apparent profundity in the series: it is more due to randomly put together strangeness, stimulating the viewer to build elaborate explanations and insights of the surreal events (not unlike how the PGO-spikes in the brain during sleep generate random activations that coalesce into dream experiences) . It is in many ways a better kind of profundity than a deliberately produced one, since it is far more open-ended. This is why we need anarchy in the story: to break out of old molds and allow us to invent new ones. The movie doesn't allow it, the series does. The surreal concretescapes of the series are paradoxally home to far more nature than the jungle of the movie.
December 16, 2005
Romantic Megastructures
 Imagine that God decided to reshape the universe as a homage to Piranesi, then leaving the system administration to Kafka and security to the AIs of The Matrix. That is the world of the manga Blame! by Nihei Tsutomu. The name, as usual, has nothing to do with the story whoever is to blame for the state of the world is not present in the story.
Imagine that God decided to reshape the universe as a homage to Piranesi, then leaving the system administration to Kafka and security to the AIs of The Matrix. That is the world of the manga Blame! by Nihei Tsutomu. The name, as usual, has nothing to do with the story whoever is to blame for the state of the world is not present in the story.
The storyline is relatively simple. A silent man named Killy searches through a gargantuan city/maze complex for a human with the net control genes, the ability to interface with the software running the world and set it right again. Humans live here and there, hiding from murderous safeguard cyborgs and the silicon creatures, another cyborg species (given the amount of enhancements, implants and apparent nanotechnology everything possesses species might be better defined by agenda than descent). Needless to say, both groups are happy to exterminate humans for their own obscure reasons. Above it all the Governing Agency ineffectually supports Killys quest, hoping to stop the random expansion of the city and the depredations of their safeguards.
 Much action, much silence. There is little dialogue or exposition. But the imagery is grand.
Much action, much silence. There is little dialogue or exposition. But the imagery is grand.
There is a love for the technical infrastructure here, of stairs and ramps on sheer concrete walls, structural members kilometres long, chambers large enough to hold their own weather systems and access surfaces hiding mysterious piping. It is a similar love found in Akira and Texhnolyze (Ichise and Killy would have gotten along perfectly, if silently). It is the same romantic eye for the drama and power of infrastructure that Piranesi had. Even when it is merely sheer and powerful without any elegance in symmetry or function there is something to be moved by. Maybe that is why many are so in love with megastructures: big is beautiful in its own way.
The megastructure is big. The first hint is a mention that there is life 3000 floors above, but the observers are not sure whether it is human. Later on such a paltry distance seems right next door. Is it a globus cassus? Or a Dyson sphere? Or just infinite in all directions?
A clear visual inspiration has been H.R. Gigers biomechanoids. In many ways they are the least original part of the setting we have already seen their relatives in other places (whether The Matrix got their robots and human-converting agents from Blame! is unclear, but not unlikely). Another inspiration seems to be Iain M. Banks Feersum Endjinn, with its enormous palace where countries stretch across rooms and the megastructure itself is filled with advanced computing hardware. That story also has a similar theme: find the key for saving the world and get it to the right place, but Blame! is less assuring that there is even a chance it might work. Another obvious inspiration is Gregory Benfords galactic centre books (Great Sky River, Tides of Light, Furious Gulf, Sailing Bright Eternity) with both name similarities (e.g. Kileen and Killy) and the struggle with the machine civilizations.
Blame! is very much a romantic, even gothic story. Despite the composedness of the main character it is filled with the love of the infinite, drama and especially horror. There is even a bizarre love/parenthood story near the end that would have appealed to the romantics (if they got their heads around personality transfer/merging and nanotechnology). Maybe this is true techno-romanticism: the feelings of the humans are not the important, it is the feelings of the city that matters.
Romanticism loves horror. Good horror has several components. There is the sensory fear of great heights, dark spaces and precarious walkways. Then there is the direct adrenaline rush fear of ruthless attackers and the visceral disgust-horror of human-machine-corpse-insect-weapon hybrids. But the fourth kind of fear is the most interesting: the intellectual fear of the runaway system. "The city is continuing to expand at random" the builder machines are not under anybodys control and are creating more than both humans and the Governing Agency beings want. The cyborgs might be murderous but they are not expanding at the rate the city does. We know we can in principle stop a non-growing system, but something expanding faster than us will defeat us no matter what.
Im always on the lookout for interesting user interfaces. In Log 46 & 48 (the provisional connection registration request plotline) wading across a river is used as one of the most poetic fictional progress bars I have ever seen. There is even a good explanation of why it always takes longer than expected.
December 02, 2005
The Day K Days Before Tomorrow
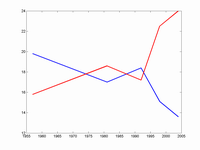 The paper by Brydem Longworth and Cunningham on Atlantic circulation in nature has triggered a flood of stupid climate speculation. Here is my own contribution based on dynamical systems.
The paper by Brydem Longworth and Cunningham on Atlantic circulation in nature has triggered a flood of stupid climate speculation. Here is my own contribution based on dynamical systems.
This paper is good news if you believe that anthropogenic CO2 is the cause of the slowing. Because it implies that we have a rapid regulatory feedback. In fact, far faster than most experts seem to have thought.
The traditional view of deep oceanic circulation is that it is very slow (thousands of years), so a change in ice formation/melting will produce a delayed shift (still faster than the actual water current, though - just like electrons in cables move only a few mm per second while the signals move at a fraction of lightspeed). But that delay tends to destabilize systems: if the cooling today depends on the temperature X years in the past, it is more likely that the delayed response will act to amplify variations today.
If warming since the 50's is enough to slow the Gulf stream we should be happy: it is likely to extend arctic ice sheets (great coolers) and counteract the warming with a short delay (about a half century, perhaps). Things may of course not be great, but we at least have a self-stabilizing climate. If the delay was longer we might get the weak gulf stream during a cooler period (say after the Kyoto XVII protocol) and move into an ice age instead. Oops, a Younger Dryas event again! In fact, this kind of very rapid feedback seems to undermine the standard explanation of that event.
It should be noted that the 30's to 50's was a notably warm period, with a cooling afterwards to the early 70's when the temperature started increasing again (never trust climate graphs not showing the entire 20th century! and always make sure the locations of the weather stations are not getting urbanized!) For a wonderful review, see John Baez temperature page and illustrations. Maybe we are seeing the effect of the mid-century warm period as the cooling in the 60's and 70's? It doesn't seem to fit the data, but it is an interesting idea if the feedback is fast.
Here is a simple example, a set of coupled delay equations I whipped together. They were inspired by the climate issue but are no climate model (some signs are plainly wrong, it actually makes more sense if one switches the meanings of the ice and temperature variables): the point is to demonstrate the effect of increasing delay.
deltai=-(1-temp(t))*golf(t)
ice(t+1) = ice(t) + dt*[deltai]
temp(t+1) = temp(t) + dt*[(1-ice(t-K)-.1*temp(t))]
golf(t+1) = golf(t) + dt*[-deltai + .1*(.5-golf(t));
Running this with dt=0.1, 1000 timesteps and different amounts of delay K produces the following:
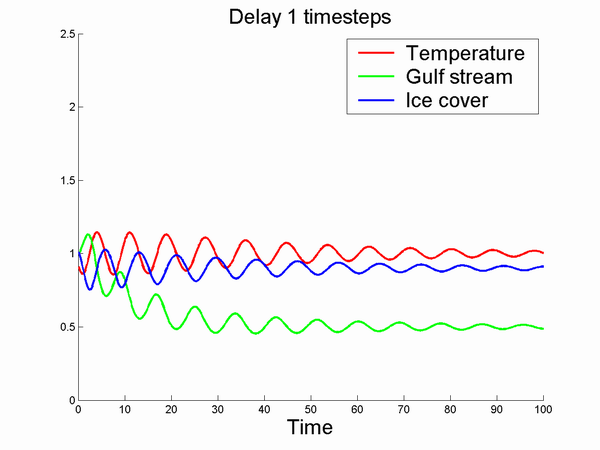
A nice convergence to a steady state. Increasing K makes this steady state oscillate more and more:
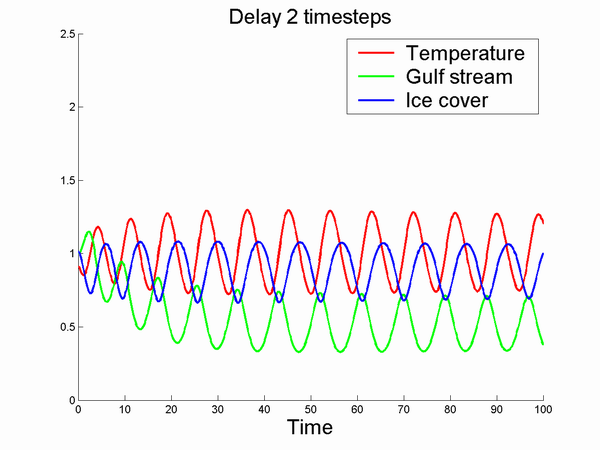
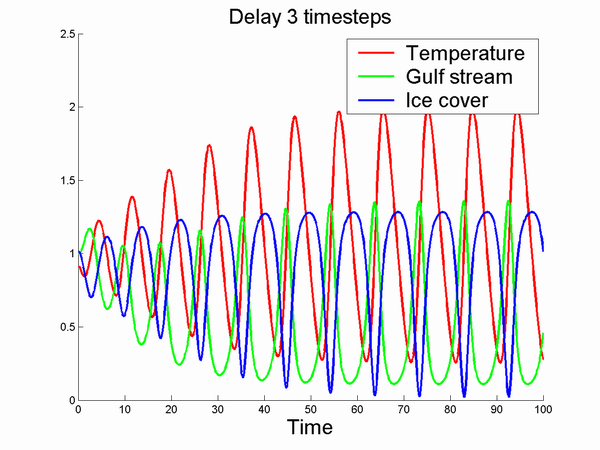
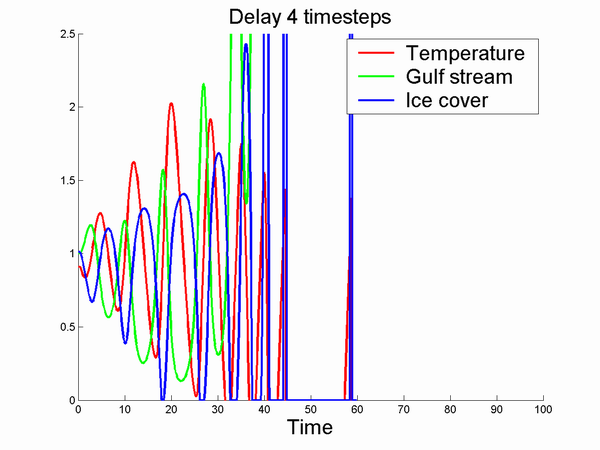
I wouldn't want to live in the last simulation.
Increasing delays means increasing instability in general since they promote overcompensation. An old feedback classic.
This is why The Day after Tomorrow is so absurd. Global warming makes the gulf stream stop, and immediately (weeks) the north hemisphere freezes over. The amount of salty deep water that would produce would jumpstart a gulf stream like the world has never seen before, probably melting the icecap even faster. The assumed short delay in climate response makes the whole movie stupid. In fact, had I written the end of the story I would have threatened the world with exponentially increasing oscillations instead. At least that is a new climate disaster.
People often defend that awful movie with "but at least it gets people to think about the climate". The problem is that it promotes simplistic thinking. The climate is a complex dynamical system that clearly has several metastable attractor states, but also demonstrates a high degree of resiliency. If it did not we would all be cooked or frozen.
The moral ought to be that if we dislike what the climate is doing - for whatever reason - and think we can affect it - through whatever means - then we should consider controlling it. Most climate discussions focus on reducing economy and the effects of civilization rather than fixing the climate per se. That is why it took so long for ideas of carbon sequestration to be accepted and why organisations seem more interested in debating how to stop climate change while agreeing that it is unlikely to succeed than the more practical matter of adapting to it - it is the aims that are important, not the result. There is a strong stream of antimodernist ideas from Rosseau and onward linked to environmentalism that make proponents more interested in being anticapitalist, anticar, antiindustry rather than being primarily for a nice climate (however defined - I want Scandinavia to have a climate and ecology like the bronze age heat maximum myself).
In the long run we better control the eigenvalues of the critical points of the climate dynamical system. That is both the practical and moral thing to do.
In writing this entry, I ran across www.chooseclimate.org that has a wonderful climate simulation applet one can experiment with. We need more such tools to make people aware of the dynamical properties of world systems. It would be rather interesting to combine it with an economic model too, to let the user see some of the human (rather than geospheric) impact of the approaches.
The site also has a critical review of climate engineering well worth reading (although much has happened since it was written). I disagree with the author's view that climate engineering would be bad because it would suck attention and money away from 'real' climate correction. Such a sociological danger might exist, but should be compared to the rather obvious sociological problem today that attention and money are mainly spent on the current climate change dogmas.
December 01, 2005
Synthetic Biology
 This week's CNE Health blog was about synthetic biology and the youthful feeling surrounding the field, be it cartoons in Nature or biotech jamborees where participants make modified bacteria rather than knots.
This week's CNE Health blog was about synthetic biology and the youthful feeling surrounding the field, be it cartoons in Nature or biotech jamborees where participants make modified bacteria rather than knots.
Of course, much of what is being done is pretty standard genetic modifications, nothing per se revolutionary these days. It is the marriage between systems biology, easy hybridization, large parts registers and a willingness to approach biology as engineering that is something new. The experience of putting together dynamical systems from software engineering fits in with the healthy hubris of seeing biology as something understandable and modifiable.
In my experience quite a few older (more mature?) scientists tend to view biology with too much awe: the sheer complexity is often taken as evidence that it will never be understandable or managable. To some extent this is of course true and hard won experience. But it is also paralysing. Not knowing that things are impossible is a good preparation for actually doing them (be they multilayer perceptron learning or robustly evolving software code - both by the way a kind of precursors to synthetic biology). Computational neuroscience often suffers at the hands of people who think we have to model every tiny detail in order to make a "correct" simulation. They cannot conceive that sometimes good enough is enough to achieve scientific or practical results.
One thing that I noted in the papers on synthetic biology is the repeated calls for a "synthetic biology Asilomar conference". The premise is that in order to forestall public unease scientists ought to self regulate. But as I have argued in various other publications, a new Asilomar might not work at all. In fact, the old Asilomar conference did not calm public views but may rather have made people more nervous (the scientists are having meetings about how dangerous and how little we know of this technology?!) despite its rather sane decisions. Instead I think trust can be built by getting people into the labs (figuratively and literally), letting them see what is being done, why and by what kind of people - as well as participate. I think the danish leftist newspaper Gateavisen got it right when it proclaimed that genetic engineering should belong to the people. The emergence of a young synthetic biology and biohacking is a good start for a trustworthy people's biotechnology.
The illustration is a composition of the amazing cubesolver by J.P. Brown and a metabolism shcart from the International Union of Biochemstry & Molecular Biology.
Is P≠NP a Physical Law?
 I ran into http://www.scottaaronson.com/, a polymath site worth visiting, especially for his papers on quantum computing and complexity.
I ran into http://www.scottaaronson.com/, a polymath site worth visiting, especially for his papers on quantum computing and complexity.
I found "NP-complete Problems and Physical Reality" especially interesting. This is a review of proposed physical means of solving NP complete problems efficiently. He disproves that soap bubbles do a good job of finding Steiner trees, looks into the various forms of quantum computing and more exotic approaches like closed timelike curves, odd spacetimes and anthropic computing. The conclusion is rather interesting: so far we have no evidence whatsoever that physics allows efficient solving of NP-complete problems. In fact, PP≠NP might be a physical law on par with the nonexistence of perpetual motion machines, and with similarly profound implications.
It is interesting to consider this limitation in the light of the supercomputing ideas I and others have proposed; we have mostly looked at limits of the quantity of computation that can be done, while Scott looks at quality limits. And quality is quantity, of course.
He points out that if there really existed a way of solving NP problems physically the consequences would be major. Not just some advances in optimization, but the possibility of creatng minimal circuits that represent stock market data, Shakespeare or evolution. Insight (the succinct representation of regularities in data/experience) would be entirely mechanizable.
With that kind of power the requirements for M-brains go down enormously (they do not vanish, you still need to store all your acquired knowledge or your mindstate). This might be reformulated into the prediction that if P=NP or physics can solve NP efficiently, we will not see any alien M-brains beyond data storage.
 Quantum Search of Spatial Regions deals with quantum searches. Grover's algorithm for quantum searching an unsorted database allows one to find a particular item in O(N
Quantum Search of Spatial Regions deals with quantum searches. Grover's algorithm for quantum searching an unsorted database allows one to find a particular item in O(N
While quantum robots are theoretical entities more akin to datastructures looking through other datastructures, I can't help thinking of physical implementations. Nanomachines are after all largely classical objects, too large to spread out their wavefunctions over atomic distances. If we ever get to femtotech it seems plausible that femtomachines will by their nature be quantum robots. A quantum robot would have interesting positioning problems, or rather, have to live without a well defined position. Parts of the system would have to keep their relations using other means that physical contact (e.g. by some form of tuned particle exchange). I wonder what that implies for e.g. manufacturing? A femtoassembler would have roughly the same problem as a quantum computer in selecting a particular eigenfunction (a solution for the computer, an assembly step for the assembler), unless it was assembling objects that also exist in superpositions. The speed of quantum search might imply that reconfiguration of femtotech systems could be made significantly more efficient than for classical systems if they could exist at the same size scale.
The Complexity of Agreement deals with how quickly two agents can come into agreement on something. It turns out that agreement to within epsilon can be achieved by exchanging on the order of 1/epsilon^2 bits, and they can do a perfect simulation of Bayesian rationality. This fits in nicely with Robin Hanson's papers on related agreement topics (and Scott also acknowledges him for introducing him to the issue).
 Who Can Name the Bigger Number? is a popular science talk with some good explanations and a memorable insight near the end:
Who Can Name the Bigger Number? is a popular science talk with some good explanations and a memorable insight near the end:
Indeed, one could define science as reasons attempt to compensate for our inability to perceive big numbers. If we could run at 280,000,000 meters per second, thered be no need for a special theory of relativity: itd be obvious to everyone that the faster we go, the heavier and squatter we get, and the faster time elapses in the rest of the world. If we could live for 70,000,000 years, thered be no theory of evolution, and certainly no creationism: we could watch speciation and adaptation with our eyes, instead of painstakingly reconstructing events from fossils and DNA. If we could bake bread at 20,000,000 degrees Kelvin, nuclear fusion would be not the esoteric domain of physicists but ordinary household knowledge. But we cant do any of these things, and so we have science, to deduce about the gargantuan what we, with our infinitesimal faculties, will never sense. If people fear big numbers, is it any wonder that they fear science as well and turn for solace to the comforting smallness of mysticism?
The wave pictures were made using the excellent physics applets at the Math, Physics, and Engineering Applets site.