When @fermatslibrary brought up this 1940 paper about why we have nothing to worry about from nuclear chain reactions, I first checked that it was real and not a modern forgery. Because it seems almost too good to be true in the light of current AI safety talk.
It gives a summary of a recent fission experiment that demonstrate a chain reaction where neutrons released from a split atom induces other atoms to split. The article claimed this caused widespread unease:
“Wasn’t there a dangerous possibility that the uranium would at last become explosive ? That the samples being bombarded in the laboratories at Columbia University, for example, might blow up the whole of New York City ? To make matters more ominous, news of fission research from Germany, plentiful in the early part of 1 939, mysteriously and abruptly stopped for some months. Had government censorship been placed on what might be a secret of military importance ?
The press and populace, getting wind of these possibly lethal goings-on, raised a hue and cry.”
However, physicists were unafraid to of being blown up (and blowing up the rest of the world).
“Nothing daunted, however, the physicists worked on to find out whether or not they would be blown up, and the rest of us along with them.”
Then comes a good description of the recent French experiment in making a self-sustaining chain reaction. The resulting neutrons are too fast to interact much with other atoms, making the net number dwindle despite a few initial induced fission. And since it runs out, there is no risk.
There are some caveats, but don’t worry, scientific consensus seems to be firmly on the safety side!
“With typical French – and scientific – caution, they added that this was per haps true only for the particular conditions of their own experiment, which was carried out on a large mass of uranium under water. But most scientists agreed that it was very likely true in general.”
This article was 2 years before the Manhattan Project started, so it is unlikely to have been due to deliberate disinformation: it is an honest take on the state of knowledge at the time. Except of course that there was actually a fair bit to worry about soon…
Human engineering can change conditions *deliberately* to slow down neutrons with a moderator (making a reactor) or use an isotope where hot neutrons cause fission (the atomic bomb). The natural state is not a reliable indicator of the technical state.
It cannot have escaped the contemporary reader that this is very similar to many claims AI will remain safe. It is not reliable enough to self-improve or perform nefarious tasks well, so the chain reaction runs down. Surely nobody can make an AI moderator or find AI plutonium!
More generally, this seems a common argument failure mode: solid empirical evidence against something within known conditions cannot just be extrapolated reliably outside the conditions. What is needed is for the argument to work is (1) the conditions cannot be changed, (2) the result can be smoothly extrapolated, or (3) the impossibility needs to be relevant to the risk.
For nuclear chain reactions both (1) and (2) were wrong (moderators and plutonium). Arguments that AI will always hallucinate may be true, but that does not mean safety follows, since hallucinating humans (the results apply equally to us) are clearly potentially risky.
I think this is a relative to Arthur C. Clarke’s “failure of nerve” (not following extrapolation implications, often leading to overconfident impossibility claims) and “failure of imagination” (not looking outside the known domain or acknowledging there could be anything out there) he discusses in (1982). Profiles of the Future: An Inquiry to the Limits of the Possible.
Also, when reading the article I thought about my discussions with Tom Moynihanabout how many tropes are earlier than the discoveries or events enabling them to become real – in the Scientific American article we already have the planet-destroying explosion and scientists “going dark” for military secrecy.
The funny thing is that this allows enlightened writers to poke fun at those naive people who merely believe in tropes, rather than the real science. The problem is that sometimes we make tropes true.
Some of FHI research and reports are mentioned in passing. Their role is mainly in showing that there could be very bright futures or other existential risks, which undercuts the climate catastrophists that he is really criticising:
Several factors may help to explain why catastrophists sometimes view extreme climate change as more likely than other worst cases. Catastrophists confuse expected and extreme forecasts and thus view climate catastrophe as something we know will happen. But while the expected scenarios of manageable climate change derive from an accumulation of scientific evidence, the extreme ones do not. Catastrophists likewise interpret the present-day effects of climate change as the onset of their worst fears, but those effects are no more proof of existential catastrophes to come than is the 2015 Ebola epidemic a sign of a future civilization-destroying pandemic, or Siri of a coming Singularity
I think this is an important point for the existential risk community to be aware of. We are mostly interested in existential risks and global catastrophes that look possible but could be impossible (or avoided), rather than trying to predict risks that are going to happen. We deal in extreme cases that are intrinsically uncertain, and leave the more certain things to others (unless maybe they happen to be very under-researched). Siri gives us some singularity-evidence, but we think it is weak evidence, not proof (a hypothetical AI catastrophist would instead say “so, it begins”).
Confirmation bias is easy to fall for. If you are looking for signs of your favourite disaster emerging you will see them, and presumably loudly point at them in order to forestall the disaster. That suggests extra value in checking what might not be xrisks and shouldn’t be emphasised too much.
Catastrophizing is not very effective
The nuclear disarmament movement also used a lot of catastrophizing, with plenty of archetypal cartoons showing Earth blowing up as a result of nuclear war or commonly claiming it would end humanity. The fact that the likely outcome merely would be mega- or gigadeath and untold suffering was apparently not regarded as rhetorically punchy enough. Ironically, Threads, The Day After or the Charlottesville scenario in Effects of Nuclear War may have been far more effective in driving home the horror and undesirability of nuclear war better, largely by giving a smaller-scale more relateable scenarios. Scope insensitivity, psychic numbing, compassion fade and related effects make catastrophizing a weak, perhaps even counterproductive, tool.
Defending bad ideas
Another take-home message: when arguing for the importance of xrisk we should make sure we do not end up in the stupid loop he describes. If something is the most important thing ever, we better argue for it well and backed up with as much evidence and reason as can possibly be mustered. Turning it all into a game of overcoming cognitive bias through marketing or attributing psychological explanations to opposing views is risky.
The catastrophizing problem for very important risks is related to Janet Radcliffe-Richards’ analysis of what is wrong with political correctness (in an extended sense). A community argues for some high-minded ideal X using some arguments or facts Y. Someone points out a problem with Y. The rational response would be to drop Y and replace it with better arguments or facts Z (or, if it is really bad, drop X). The typical human response is to (implicitly or explicitly) assume that since Y is used to argue for X, then criticising Y is intended to reduce support for X. Since X is good (or at least of central tribal importance) the critic must be evil or at least a tribal enemy – get him! This way bad arguments or unlikely scenarios get embedded in a discourse.
Standard groupthink where people with doubts figure out that they better keep their heads down if they want to remain in the group strengthens the effect, and makes criticism even less common (and hence more salient and out-groupish when it happens).
Reasons to be cheerful?
An interesting detail about the opening: the GCR/Xrisk community seems to be way more optimistic than the climate community as described. I mentioned Warren Ellis little novel Normal earlier on this blog, which is about a mental asylum for futurists affected by looking into the abyss. I suspect he was maybe modelling them on the moody climate people but adding an overlay of other futurist ideas/tropes for the story.
Capability Caution Principle: There being no consensus, we should avoid strong assumptions regarding upper limits on future AI capabilities.
It is an important meta-principle in careful design to avoid assuming the most reassuring possibility and instead design based on the most awkward possibility.
When inventing a cryptosystem, do not assume that the adversary is stupid and has limited resources: try to make something that can withstand a computationally and intellectually superior adversary. When testing a new explosive, do not assume it will be weak – stand as far away as possible. When trying to improve AI safety, do not assume AI will be stupid or weak, or that whoever implements it will be sane.
Often we think that the conservative choice is the pessimistic choice where nothing works. This is because “not working” is usually the most awkward possibility when building something. If I plan a project I should ensure that I can handle unforeseen delays and that my original plans and pathways have to be scrapped and replaced with something else. But from a safety or social impact perspective the most awkward situation is if something succeeds radically, in the near future, and we have to deal with the consequences.
This is an approach based on potential loss rather than probability. Most AI history tells us that wild dreams rarely, if ever, come true. But were we to get very powerful AI tools tomorrow it is not too hard to foresee a lot of damage and disruption. Even if you do not think the risk is existential you can probably imagine that autonomous hedge funds smarter than human traders, automated engineering in the hands of anybody and scalable automated identity theft could mess up the world system rather strongly. The fact that it might be unlikely is not as important as that the damage would be unacceptable. It is often easy to think that in uncertain cases the burden of proof is on the other party, rather than on the side where a mistaken belief would be dangerous.
As FLI stated it the principle goes both ways: do not assume the limits are super-high either. Maybe there is a complexity scaling making problem-solving systems unable to handle more than 7 things in “working memory” at the same time, limiting how deep their insights could be. Maybe social manipulation is not a tractable task. But this mainly means we should not count on the super-smart AI as a solution to problems (e.g. using one smart system to monitor another smart system). It is not an argument to be complacent.
People often misunderstand uncertainty:
Some think that uncertainty implies that non-action is reasonable, or at least action should wait till we know more. This is actually where the precautionary principle is sane: if there is a risk of something bad happening but you are not certain it will happen, you should still try to prevent it from happening or at least monitor what is going on.
Gaining more information sometimes reduces uncertainty in valuable ways, but the price of information can sometimes be too high, especially when there are intrinsically unknowable factors and noise clouding the situation.
Looking at the mean or expected case can be a mistake if there is a long tail of relatively unlikely but terrible possibilities: on the average day your house does not have a fire, but having insurance, a fire alarm and a fire extinguisher is a rational response.
Combinations of uncertain factors do not become less uncertain as they are combined (even if you describe them carefully and with scenarios): typically you get broader and heavier-tailed distributions, and should act on the tail risk.
FLI asks the intriguing question of how smart AI can get. I really want to know that too. But it is relatively unimportant for designing AI safety unless the ceiling is shockingly low; it is safer to assume it can be as smart as it wants to. Some AI safety schemes involve smart systems monitoring each other or performing very complex counterfactuals: these do hinge on an assumption of high intelligence (or whatever it takes to accurately model counterfactual worlds). But then the design criteria should be to assume that these things are hard to do well.
Under high uncertainty, assume Murphy’s law holds.
(But remember that good engineering and reasoning can bind Murphy – it is just that you cannot assume somebody else will do it for you.)
I have recently begun to work on the problem of information hazards: when spreading true information is causing danger. Since we normally regard information as a good thing this is a bit unusual and understudied, and in the case of existential risk it is important to get things right at the first try.
However, concealing information can also produce risk. This book is an excellent series of case studies of major disasters, showing how the practice of hiding information contributed to make them possible, worse, and hinder rescue/recovery.
Chernov and Sornette focus mainly on technological disasters such as the Vajont Dam, Three Mile Island, Bhopal, Chernobyl, the Ufa train disaster, Fukushima and so on, but they also cover financial disasters, military disasters, production industry failures and concealment of product risk. In all of these cases there was plentiful concealment going on at multiple levels, from workers blocking alarms to reports being classified or deliberately mislaid to active misinformation campaigns.
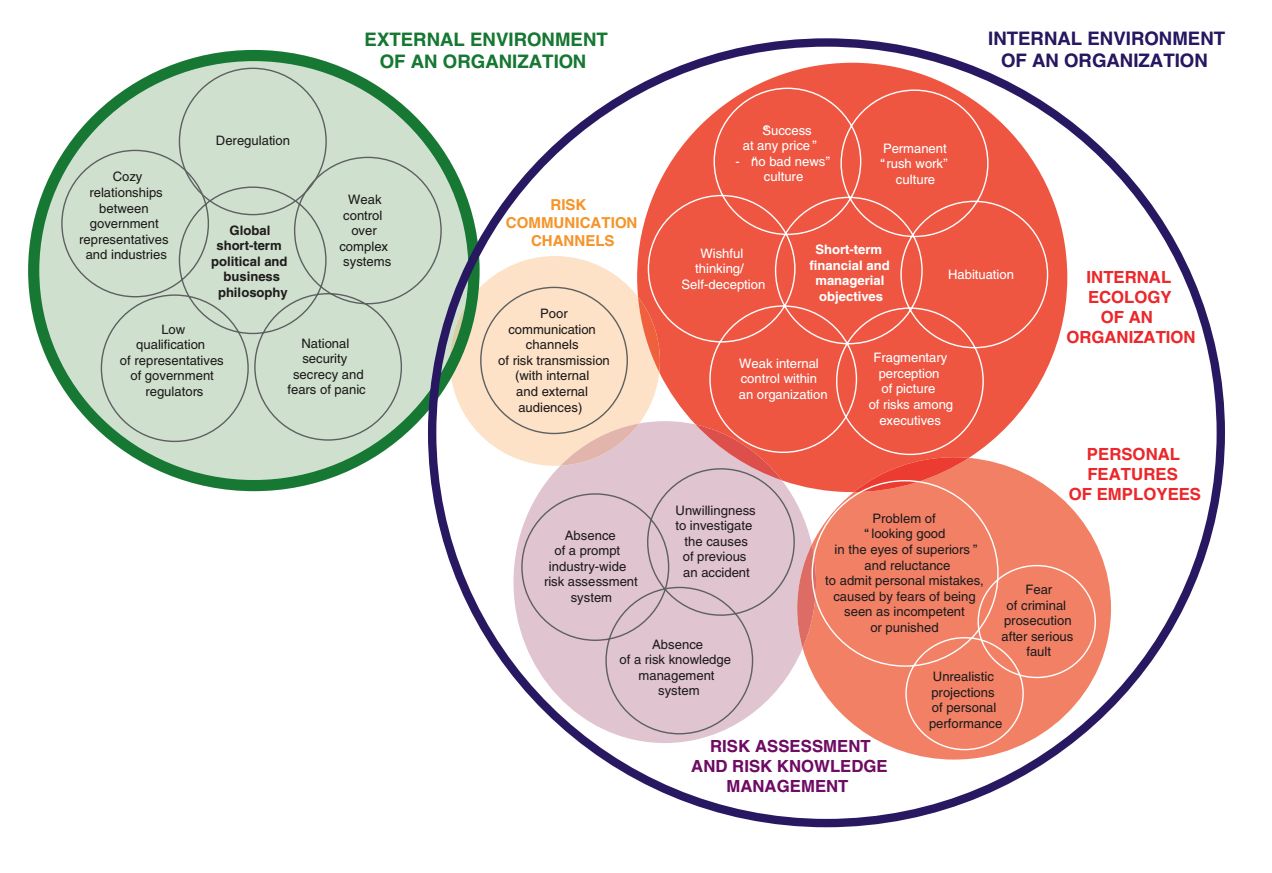
Chernov and Sornette’s model of the factors causing or contributing to risk concealment.
When summed up, many patterns of information concealment recur again and again. They sketch out a model of the causes of concealment, with about 20 causes grouped into five major clusters: the external environment enticing concealment, risk communication channels blocked, an internal ecology stimulating concealment or ignorance, faulty risk assessment and knowledge management, and people having personal incentives to conceal.
The problem is very much systemic: having just one or two of the causative problems can be counteracted by good risk management, but when several causes start to act together they become much harder to deal with – especially since many corrode the risk management ability of the entire organisation. Once risks are hidden, it becomes harder to manage them (management, after all, is done through information). Conversely, they list examples of successful risk information management: risk concealment may be something that naturally tends to emerge, but it can be counteracted.
Chernov and Sornette also apply their model to some technologies they think show signs of risk concealment: shale energy, GMOs, real debt and liabilities of the US and China, and the global cyber arms race. They are not arguing that a disaster is imminent, but the patterns of concealment are a reason for concern: if they persist, they have potential to make things worse the day something breaks.
Is information concealment the cause of all major disasters? Definitely not: some disasters are just due to exogenous shocks or surprise failures of technology. But as Fukushima shows, risk concealment can make preparation brittle and handling the aftermath inefficient. There is also likely plentiful risk concealment in situations that will never come to attention because there is no disaster necessitating and enabling a thorough investigation. There is little to suggest that the examined disasters were all uniquely bad from a concealment perspective.
From an information hazard perspective, this book is an important rejoinder: yes, some information is risky. But lack of information can be dangerous too. Many of the reasons for concealment like national security secrecy, fear of panic, prevention of whistle-blowing, and personnel being worried about personally being held accountable for a serious fault are maladaptive information hazard management strategies. The worker not reporting a mistake is handling a personal information hazard, at the expense of the safety of the entire organisation. Institutional secrecy is explicitly intended to contain information hazards, but tends to compartmentalize and block relevant information flows.
A proper information hazard management strategy needs to take the concealment risk into account too: there is a risk cost of not sharing information. How these two risks should be rationally traded against each other is an important question to investigate.
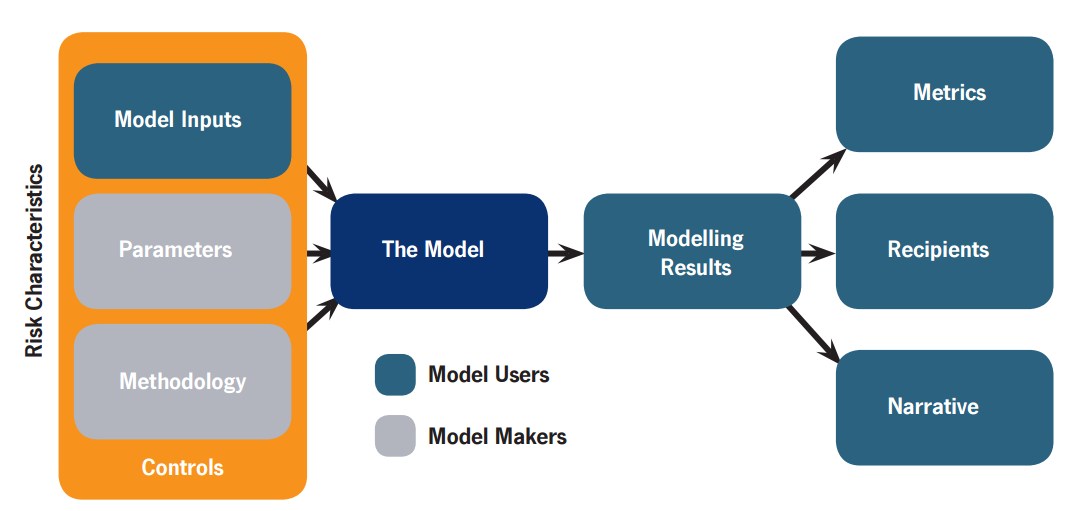
The basic story is that in insurance (and many other domains) people use statistical models to estimate risk, and then use these estimates plus human insight to come up with prices and decisions. It is well known (at least in insurance) that there is a measure of model risk due to the models not being perfect images of reality; ideally the users will take this into account. However, in reality (1) people tend to be swayed by models, (2) they suffer from various individual and collective cognitive biases making their model usage imperfect and correlates their errors, (3) the markets for models, industrial competition and regulation leads to fewer models being used than there could be. Together this creates a systemic risk: everybody makes correlated mistakes and decisions, which means that when a bad surprise happens – a big exogenous shock like a natural disaster or a burst of hyperinflation, or some endogenous trouble like a reinsurance spiral or financial bubble – the joint risk of a large chunk of the industry failing is much higher than it would have been if everybody had had independent, uncorrelated models. Cue bailouts or skyscrapers for sale.
Note that this is a generic problem. Insurance is just unusually self-aware about its limitations (a side effect of convincing everybody else that Bad Things Happen, not to mention seeing the rest of the financial industry running into major trouble). When we use models the model itself (the statistics and software) is just one part: the data fed into the model, the processes of building and tuning the model, how people use it in their everyday work, how the output leads to decisions, and how the eventual outcomes become feedback to the people involved – all of these factors are important parts in making model use useful. If there is no or too slow feedback people will not learn what behaviours are correct or not. If there are weak incentives to check errors of one type, but strong incentives for other errors, expect the system to become biased towards one side. It applies to climate models and military war-games too.
The key thing is to recognize that model usefulness is not something that is directly apparent: it requires a fair bit of expertise to evaluate, and that expertise is also not trivial to recognize or gain. We often compare models to other models rather than reality, and a successful career in predicting risk may actually be nothing more than good luck in avoiding rare but disastrous events.
What can we do about it? We suggest a scorecard as a first step: comparing oneself to some ideal modelling process is a good way of noticing where one could find room for improvement. The score does not matter as much as digging into one’s processes and seeing whether they have cruft that needs to be fixed – whether it is following standards mindlessly, employees not speaking up, basing decisions on single models rather than more broad views of risk, or having regulators push one into the same direction as everybody else. Fixing it may of course be tricky: just telling people to be less biased or to do extra error checking will not work, it has to be integrated into the organisation. But recognizing that there may be a problem and getting people on board is a great start.
What have we learned since 1957? Did we predict what it would be? And what does it tell us about our future?
Some notes for the panel discussion “‘We’ve never had it so good’ – how does the world today compare to 1957?” 11 May 2015 by Dr Anders Sandberg, James Martin Research Fellow at the Future of Humanity Institute, Oxford Martin School, Oxford University.
Taking the topic “how does the world today compare to 1957?” a bit literally and with a definite technological bent, I started reading old issues of Nature to see what people were thinking about back then.
Technology development
Space
In 1957 the space age began.
Sputnik 1
Sputnik 1, the first artificial satellite, was launched on 4 October 1957. On November 3 Sputnik 2 was launched, with Laika, the first animal to orbit the Earth. The US didn’t quite manage to follow up within the year, but succeeded with Explorer 1 in January 1958.
Right now, Voyager 1 is 19 billion km from earth, leaving the solar system for interstellar space. Probes have visited all the major bodies of the solar system. There are several thousand satellites orbiting Earth and other bodies. Humans have set their footprint on the Moon – although the last astronaut on the moon left closer to 1957 than the present.
There is a pair of surprises here. The first is how fast humanity went from primitive rockets and satellites to actual moon landings – 12 years. The second is that the space age did not grow into a roaring colonization of the cosmos, despite the confident predictions of nearly anybody in the 1950s. In many ways space embodies the surprises of technological progress – it can go both faster and slower than expected, often at the same time.
Nuclear
1957 also marks the first time that power was generated from a commercial nuclear plant, at Santa Susana, California, and the first full-scale nuclear power plant (Shippingport, Pennsylvania). Now LA housewives were cooking with their friend the atom! Ford announced their Nucleon atomic concept car 1958 – whatever the future held, it was sure to be nuclear powered!
Except that just like the Space Age the Atomic Age turned out to be a bit less pervasive than imagined in 1957.
One reason might be found in the UK Windscale nuclear power plant accident on 10th October 1957. Santa Susana also turned into an expensive superfund clean-up site. Making safe and easily decommissioned nuclear plants turned out to be far harder than imagined in the 1950s. Maybe, as Freeman Dyson has suggested[1], the world simply choose the wrong branch of the technology tree to walk down, selecting the big and complex plants suitable for nuclear weapons isotopes rather than small, simple and robust plants. In any case, today nuclear power is struggling both against cost and broadly negative public perceptions.
In April 1957 IBM sells the first compiler for the FORTRAN scientific programming language, as a hefty package of punched cards. This represents the first time software allowing a computer to write software is sold.
The term “artificial intelligence” had been invented the year before at the famous Dartmouth conference on artificial intelligence, which set out the research agenda to make machines that could mimic human problem solving. Newell, Shaw and Simon demonstrated the General Problem Solver (GPS) in 1957, a first piece of tangible progress.
While the Fortran compiler was a completely independent project it does represent the automation of programming. Today software development involves using modular libraries, automated development and testing: a single programmer can today do projects far outside what would have been possible in the 1950s. Cars run software on the order of 100s of million lines of code, and modern operating systems easily run into the high tens of millions of lines of code[2].
Moore’s law, fitted with Jacknifed sigmoids. Green lines mark 98% confidence interval. Data from Nordhaus.
In 1957 Moore’s law was not yet coined as a term, but the dynamics was already ongoing: computer operations per second per dollar was increasing exponentially (this is the important form of Moore’s law, rather than transistor density – few outside the semiconductor industry actually care about that). Today we can get about 440 billion times as many computations per second per dollar now as in 1957. Similar laws apply to storage (in 1956 IBM shipped the first hard drive in the RAMAC 305 system. The drive held 5MB of data at $10,000 a megabyte, as big as two refrigerators), memory prices, sizes of systems and sensors.
This tremendous growth have not only made complex and large programs possible, or enabled supercomputing (today’s best supercomputer is about 67 billion times more powerful than the first ones in 1964), but has also allowed smaller and cheaper devices that can be portable and used everywhere. The performance improvement can be traded for price and size.
In 1957 the first electric watch – the Hamilton Ventura – was sold. Today we have the Apple watch. Both have the same main function, to show off the wealth of their owner (and incidentally tell time), but the modern watch is also a powerful computer able to act as a portal into our shared information world. Embedded processors are everywhere, from washing machines to streetlights to pacemakers.
Why did the computers take off? Obviously there was a great demand for computing, but the technology also contained the seeds of making itself more powerful, more flexible, cheaper and useful in ever larger domains. As Gordon Bell noted in 1970, “Roughly every decade a new, lower priced computer class forms based on a new programming platform, network, and interface resulting in new usage and the establishment of a new industry.”[3]
At the same time, artificial intelligence has had a wildly bumpy ride. From confident predictions of human level intelligence within a generation to the 1970s “AI winter” when nobody wanted to touch the overhyped and obsolete area, to the current massive investments in machine learning. The problem was to a large extent that we could not tell how hard problems in the field were: some like algebra and certain games yielded with ease, others like computer vision turned out to be profoundly hard.
Biotechnology
In 1957 Francis Crick laid out the “central dogma of molecular biology”, which explained the relationship between DNA, RNA, and proteins (DNA is translated into RNA, which is translated into proteins, and information only flows this way). The DNA structure had been unveiled four years earlier and people were just starting to figure out how genetics truly worked.
(Incidentally, the reason for the term “dogma” was that Crick, a nonbeliever, thought the term meant something that was unsupported by evidence and just had to be taken by faith, rather than the real meaning of the term, something that has to be believed no matter what. Just like “black holes” and the “big bang”, names deliberately coined to mock, it stuck.)
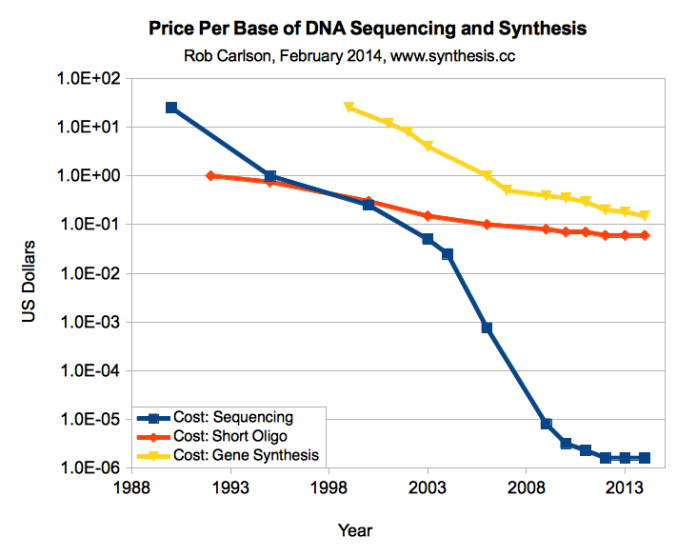
It took time to learn how to use DNA, but in the 1960s we learned the language of the genetic code, by the early 1970s we learned how to write new information into DNA, by the 1980s commercial applications began, by the 1990s short genomes were sequenced…
Today we have DNA synthesis machines that can be bought on eBay, unless you want to order your DNA sequence online and get a vial in the mail. Conversely, you can send off a saliva sample and get a map (or the entire sequence) of your genome back. The synthetic biology movement are sharing “biobricks”, modular genetic devices that can be combined and used to program cells. Students have competitions in genetic design.
The dramatic fall in price of DNA sequencing and synthesis mimics Moore’s law and is in some sense a result of it: better computation and microtechnology enables better biotechnology. Conversely, the cheaper it is, the more uses can be found – from marking burglars with DNA spray to identifying the true origins of sushi. This also speeds up research, leading to discoveries of new useulf tricks, for example leading to the current era of CRISPR/Cas genetic editing which promises vastly improved precision and efficiency over previous methods.
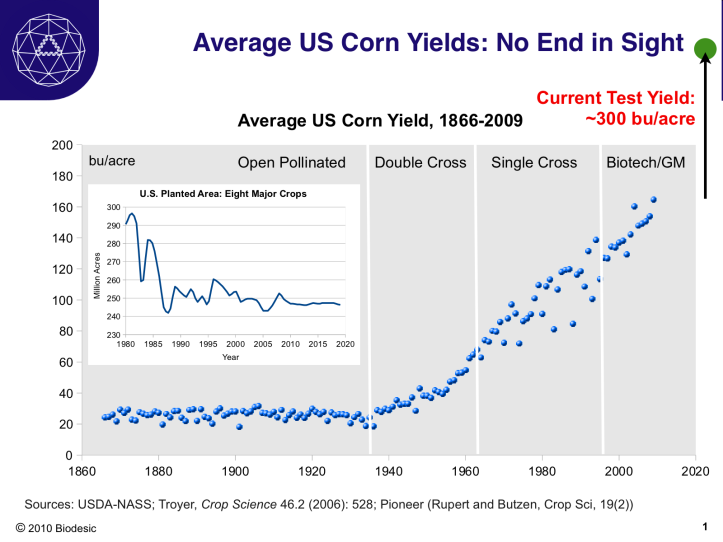
Biotechnology is of course more than genetics. One of the most important aspects of making the world better is food security. The gains in agricultural productivity have also been amazing. One of the important take-home messages in the above graph is that the improvement began before we started to explicitly tinker with the genes: crossing methods in the post-war era already were improving yields. Also, the Green Revolution in the 1960s was driven not just by better varieties, but by changes in land use, irrigation, fertilization and other less glamorous – but important – factors. The utility of biotechnology in the large is strongly linked to how it fits with the infrastructure of society.
Learning about what is easy and hard requires experience. Space was on one hand easy – it only took 17 years from Sputnik before the astronauts left the moon – but making it sustained turned out to be hard. Nuclear power was easy to make, but hard to make safe enough to be cheap and acceptable. Software has taken off tremendously, but compilers have not turned into “do what I mean” – yet routine computer engineering is regularly producing feats beyond belief that have transformed our world. AI has died the hype death several times, yet automated translation, driving, games, logistics and information services are major business today. Biotechnology had a slow ramp-up, then erupted and now schoolchildren modifying genes – yet heavy resistance holds it back, largely not because of any objective danger but because of cultural views.
If we are so bad at predicting what future technology will transform the world, what are we to do when we are searching for the Next Big Thing to solve our crises? The best approach is to experiment widely. Technologies with low thresholds of entry – such as software and now biotechnology – allow for more creative exploration. More people, more approaches and more aims can be brought to bear, and will find unexpected use for them.
The main way technologies become cheap and ubiquitous is that they are mass produced. As long as spacecraft and nuclear reactors nearly one-offs they will remain expensive. But as T. P. Wright observed, the learning curve makes each new order a bit cheaper or better. If we can reach the point where many are churned out they will not just be cheap, they will also be used for new things. This is the secret of the transistor and electronic circuit: by becoming so cheap they could be integrated anywhere they also found uses everywhere.
So the most world-transforming technologies are likely to be those that can be mass-produced, even if they from the start look awfully specialized. CCDs were once tools for astronomy, and now are in every camera and phone. Cellphones went from a moveable telephone to a platform for interfacing with the noosphere. Expect the same from gene sequencing, cubesats and machine learning. But predicting what technologies will dominate the world in 60 years’ time will not be possible.
Are we better off?
Having more technology, being able to reach higher temperatures, lower pressures, faster computations or finer resolutions, does not equate to being better off as humans.
Healthy and wise
Life expectancy (male and female) in England and Wales.
Perhaps the most obvious improvement has been health and life expectancy. Our “physiological capital” has been improving significantly. Life expectancy at birth has increased from about 70 in 1957 to 80 at a steady pace. The chance of living until 100 went up from 12.2% in 1957 to 29.9% in 2011[4].
The most important thing here is that better hygiene, antibiotics, and vaccinations happened before 1957! They were certainly getting better afterwards, but the biggest gains were likely early. Since 1957 it is likely that the main causes have been even better nutrition, hygiene, safety, early detection of many conditions, as well as reduction of risk factors like smoking.
Advanced biomedicine certainly has a role here, but it has been smaller than one might be led to think until about the 1970s. “Whether or not medical interventions have contributed more to declining mortality over the last 20 years than social change or lifestyle change is not so clear.”[5] This is in many ways good news: we may have a reserve of research waiting to really make an impact. After all, “evidence based medicine”, where careful experiment and statistics are applied to medical procedure, began properly in the 1970s!
A key factor is good health habits, underpinned by research, availability of information, and education level. These lead to preventative measures and avoiding risk factors. This is something that has been empowered by the radical improvements in information technology.
Consider the cost of accessing an encyclopaedia. In 1957 encyclopaedias were major purchases for middle class families, and if you didn’t have one you better have bus money to go to the local library to look up their copy. In the 1990s the traditional encyclopaedias were largely killed by low-cost CD ROMs… before Wikipedia appeared. Wikipedia is nearly free (you still need an internet connection) and vastly more extensive than any traditional encyclopaedia. But the Internet is vastly larger than Wikipedia as a repository of knowledge. The curious kid also has the same access to the ArXiv preprint server as any research physicist: they can reach the latest paper at the same time. Not to mention free educational courses, raw data, tutorials, and ways of networking with other interested people.
Wikipedia is also good demonstration of how the rules change when you get something cheap enough – having volunteers build and maintain something as sophisticated as an encyclopaedia requires a large and diverse community (it is often better to have many volunteers than a handful of experts, as competitors like Scholarpedia have discovered), and this would not be possible without easy access. It also illustrates that new things can be made in “alien” ways that cannot be predicted before they are tried.
Risk
But our risks may have grown too.
1957 also marks the launch of the first ICBM, a Soviet R-7. In many ways it is intrinsically linked to spaceflight: an ICBM is just a satellite with a ground-intersecting orbit. If you can make one, you can build the other.
By 1957 the nuclear warhead stockpiles were going up exponentially and had reached 10,000 warheads, each potentially able to destroy a city. Yields of thermonuclear weapons were growing larger, as imprecise targeting made it reasonable to destroy large areas in order to guarantee destruction of the target.
Nuclear warhead stockpiles. From the Center of Arms Control and Non-Proliferation.
While the stockpiles have decreased and the tensions are not as high as during the peak of the cold war in the early 80s, we have more nuclear powers, some of which are decidedly unstable. The intervening years have also shown a worrying number of close calls – not just the Cuban Missile crisis but many other under-reported crises, flare-ups and technical mishaps (Indeed, in May 22 1957 a 42,000-pound hydrogen bomb accidentally fell from a bomber near Albuquerque). The fact that we got out of the Cold War unscathed is surprising – or maybe not, since we would not be having this discussion if it had turned hot.
The biological risks are also with us. The Asian Bird Flu pandemic in 1957 claimed over 150,000 lives world-wide. Current gain-of-function research may, if we are very unlucky, lead to a man-made pandemic with a worse outcome. The paradox here is that this particular research is motivated by a desire to understand how bird flu can make the jump from birds to an infectious human pathogen: we need to understand this better, yet making new pathogens may be a risky path.
The SARS and Ebola crises show that we both have become better at handling a pandemic emergency, but also have far to go. It seems that the natural biological risk may have gone down a bit because of better healthcare (and increased a bit due to more global travel), but the real risks from misuse of synthetic biology are not here yet. While biowarfare and bioterrorism are rare, they can have potentially unbounded effects – and cheaper, more widely available technology means it may be harder to control what groups can attempt it.
1957 also marks the year when Africanized bees escaped in Brazil, becoming one of the most successful and troublesome invasive (sub)species. Biological risks can be directed to agriculture or the ecosystem too. Again, the intervening 60 years have shown a remarkably mixed story: on one hand significant losses of habitat, the spread of many invasive species, and the development of anti-agricultural bioweapons. On the other hand a significant growth of our understanding of ecology, biosafety, food security, methods of managing ecosystems and environmental awareness. Which trend will win out remains uncertain.
The good news is that risk is not a one-way street. We likely have reduced the risk of nuclear war since the heights of the Cold War. We have better methods of responding to pandemics today than in 1957. We are aware of risks in a way that seems more actionable than in the past: risk is something that is on the agenda (sometimes excessively so).
Coordination
1957/1958 was the International Geophysical Year. The Geophysical Year saw the US and Soviet Union – still fierce rivals – cooperate on understanding and monitoring the global system, an ever more vital part of our civilization.
1957 was also the year of the treaty of Rome, one of the founding treaties of what would become the EU. For all its faults the European Union demonstrates that it is possible through trade to stabilize a region that had been embroiled in wars for centuries.
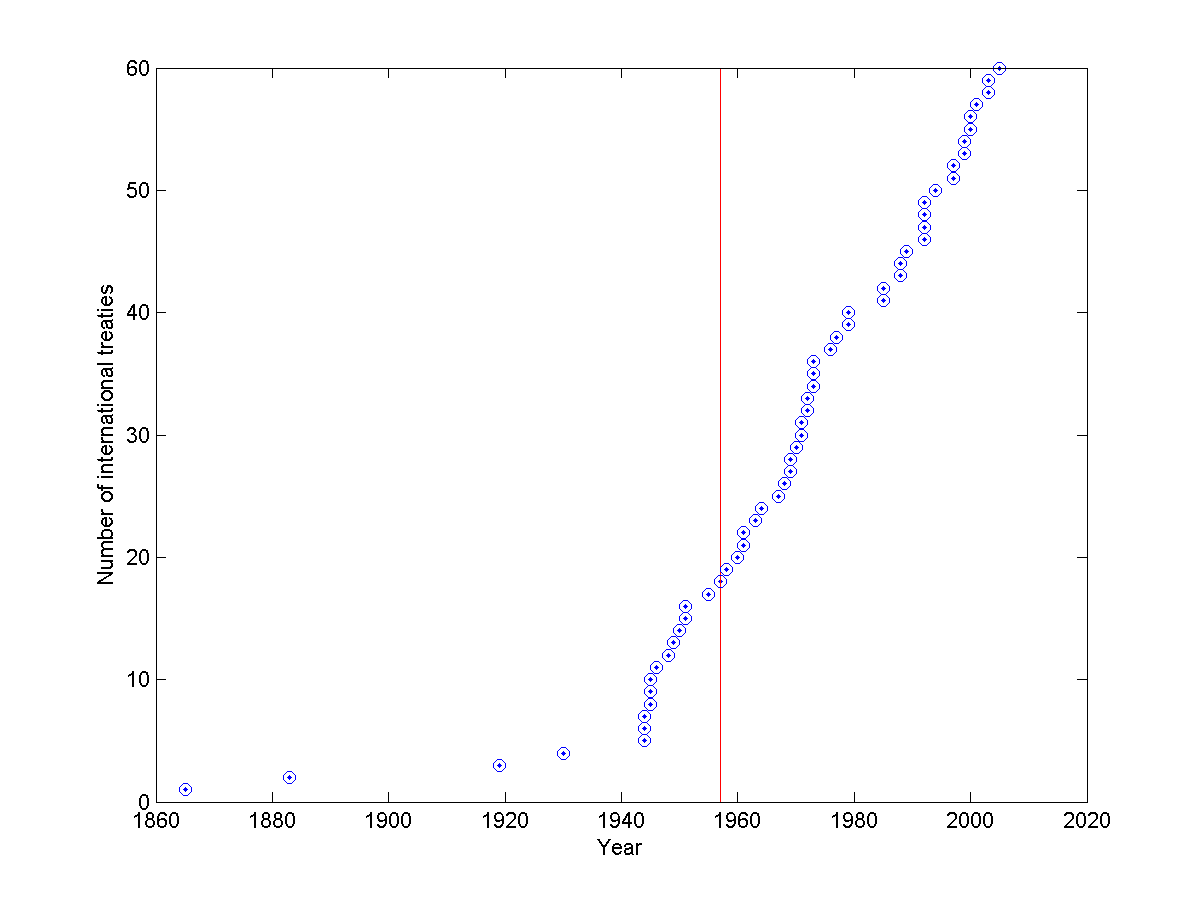
Number of international treaties over time. Data from Wikipedia.
The number of international treaties has grown from 18 in 1957 to 60 today. While not all represent sterling examples of cooperation they are a sign that the world is getting somewhat more coordinated.
Globalisation means that we actually care about what goes on in far corners of the world, and we will often hear about it quickly. It took days after the Chernobyl disaster in 1986 before it was confirmed – in 2011 I watched the Fukushima YouTube clip 25 minutes after the accident, alerted by Twitter. It has become harder to hide a problem, and easier to request help (overcoming one’s pride to do it, though, remains as hard as ever).
The world on 1957 was closed in many ways: two sides of the Cold War, most countries with closed borders, news traveling through narrow broadcasting channels and transport/travel hard and expensive. Today the world is vastly more open, both to individuals and to governments. This has been enabled by better coordination. Ironically, it also creates more joint problems requiring joint solutions – and the rest of the world will be watching the proceedings, noting lack of cooperation.
Final thoughts
The real challenges for our technological future are complexity and risk.
We have in many ways plucked the low-hanging fruits of simple, high-performance technologies that vastly extend our reach in energy, material wealth, speed and so on, but run into subtler limits due to the complexity of the vast technological systems we need. The problem of writing software today is not memory or processing speed but handling a myriad of contingencies in distributed systems subject to deliberate attacks, emergence, localization, and technological obsolescence. Biotechnology can do wonders, yet has to contend with organic systems that have not been designed for upgradeability and spontaneously adapt to our interventions. Handling complex systems is going to be the great challenge for this century, requiring multidisciplinary research and innovations – and quite likely some new insights on the same level as the earth-shattering physical insights of the 20th century.
More powerful technology is also more risky, since it can have greater consequences. The reach of the causal chains that can be triggered with a key press today are enormously longer than in 1957. Paradoxically, the technologies that threaten us also have the potential to help us reduce risk. Spaceflight makes ICBMs possible, but allows global monitoring and opens the possibility of becoming a multi-planetary species. Biotechnology allows for bioweapons, but also disease surveillance and rapid responses. Gene drives can control invasive species and disease vectors, or sabotage ecosystems. Surveillance can threaten privacy and political freedom, yet allow us to detect and respond to collective threats. Artificial intelligence can empower us, or produce autonomous technological systems that we have no control over. Handling risk requires both having an adequate understanding of what matters, designing the technologies, institutions or incentives that can reduce the risk – and convincing the world to use them.
The future of our species depends on what combination of technology, insight and coordination ability we have. Merely having one or two of them is not enough: without technology we are impotent, without insight we are likely to go in the wrong direction, and without coordination we will pull apart.
Fortunately, since 1957 I think we have not just improved our technological abilities, but we have shown a growth of insight and coordination ability. Today we are aware of global environmental and systemic problems to a new degree. We have integrated our world to an unprecedented degree, whether through international treaties, unions like the EU, or social media. We are by no means “there” yet, but we have been moving in the right direction. Hence I think we never had it so good.
[1]Freeman Dyson, Imagined Worlds. Harvard University Press (1997) P. 34-37, p. 183-185
Background: in WW2, Heisenberg was working on the German atomic reactor project (was he bad? see the fascinating play “Copenhagen” to find out!). His team almost finished a nuclear reactor. He thought that a reaction with natural uranium would be self-limiting (spoiler: it wouldn’t), so had no cadmium control rods or other means of stopping a chain reaction.
But, no worries: his team has “a lump of cadmium” that they could toss into the reactor if things got out of hand. So, now, if someone has a level of precaution woefully inadequate to the risk at hand, I will call it a lump of cadmium.
To understand it we must say something about Heisenberg’s concept of reactor design. He persuaded himself that a reactor designed with natural uranium and, say, a heavy water moderator would be self-stabilizing and could not run away. He noted that U(238) has absorption resonances in the 1-eV region, which means that a neutron with this kind of energy has a good chance of being absorbed and thus removed from the chain reaction. This is one of the challenges in reactor design—slowing the neutrons with the moderator without losing them all to absorption. Conversely, if the reactor begins to run away (become supercritical) , these resonances would broaden and neutrons would be more readily absorbed. Moreover, the expanding material would lengthen the mean free paths by decreasing the density and this expansion would also stop the chain reaction. In short, we might experience a nasty chemical explosion but not a nuclear holocaust. Whether Heisenberg realized the consequences of such a chemical explosion is not clear. In any event, no safety elements like cadmium rods were built into Heisenberg’s reactors. At best, a lump of cadmium was kepton hand in case things threatened to get out of control. He also never considered delayed neutrons, which, as we know, play an essential role in reactor safety. Because none of Heisenberg’s reactors went critical, this dubious strategy was never put to the test.
(Jeremy Bernstein, Heisenberg and the critical mass. Am. J. Phys. 70, 911 (2002); http://dx.doi.org/10.1119/1.1495409)
This reminds me a lot of the modelling errors we discuss in the “Probing the improbable” paper, especially of course the (ahem) energetic error giving Castle Bravo 15 megatons of yield instead of the predicted 4-8 megatons. Leaving out Li(7) from the calculations turned out to leave out the major contributor of energy.
Note that Heisenberg did have an argument for his safety, in fact two independent ones! The problem might have been that he was thinking in terms of mostly U(238) and then getting any kind of chain reaction going would be hard, so he was biased against the model of explosive chain reactions (but as the Bernstein paper notes, somebody in the project had correct calculations for explosive critical masses). Both arguments were flawed when dealing with reactors enriched in U(235). Coming at nuclear power from the perspective of nuclear explosions on the other hand makes it natural to consider how to keep things from blowing up.
We may hence end up with lumps of cadmium because we approach a risk from the wrong perspective. The antidote should always be to consider the risks from multiple angles, ideally a few adversarial ones. The more energy, speed or transformative power we expect something to produce, the more we should scrutinize existing safeguards for them being lumps of cadmium. If we think our project does not have that kind of power, we should both question why we are even doing it, and whether it might actually have some hidden critical mass.
There are some texts that are worth reading, even if you are outside the group they are intended for. Here is one that I think everybody should read at least the first half of:
Haldane, the Executive Director for Financial Stability at Bank of England, brings up the topic is how to act in situations of uncertainty, and the role of our models of reality in making the right decision. How complex should they be in the face of a complex reality? The answer, based on the literature on heuristics, biases and modelling, and the practical world of financial disasters, is simple: they should be simple.
Using too complex models means that they tend to overfit scarce data, weight data randomly, require significant effort to set up – and tends to promote overconfidence. As Haldane then moves on to his own main topic, banking regulation. Complex regulations – which are in a sense models of how banks ought to act – have the same problem, and also act as incentives for playing the rules to gain advantage. The end result is an enormous waste of everybody’s time and effort that does not give the desired reduction of banking risk.
It is striking how many people have been seduced by the siren call of complex regulation or models, thinking their ability to include every conceivable special case is a sign of strength. Finance and finance regulation are full of smart people who make the same mistake, as is science. If there is one thing I learned in computational biology is that your model better produce more nontrivial results than the number of parameters it has.
But coming up with simple rules or models is not easy: knowing what to include and what not to include requires expertise and effort. In many ways this may be why people like complex models, since there are no tricky judgement calls.
The minimal example would be if each risk had 50% independent chance of happening: then the observable correlation coefficient would be -0.5 (not -1, since there is 1/3 chance to get neither risk; the possible outcomes are: no event, risk A, and risk B). If the probability of no disaster happening is N/(N+2) and the risks are equal 1/(N+2), then the correlation will be -1/(N+1).
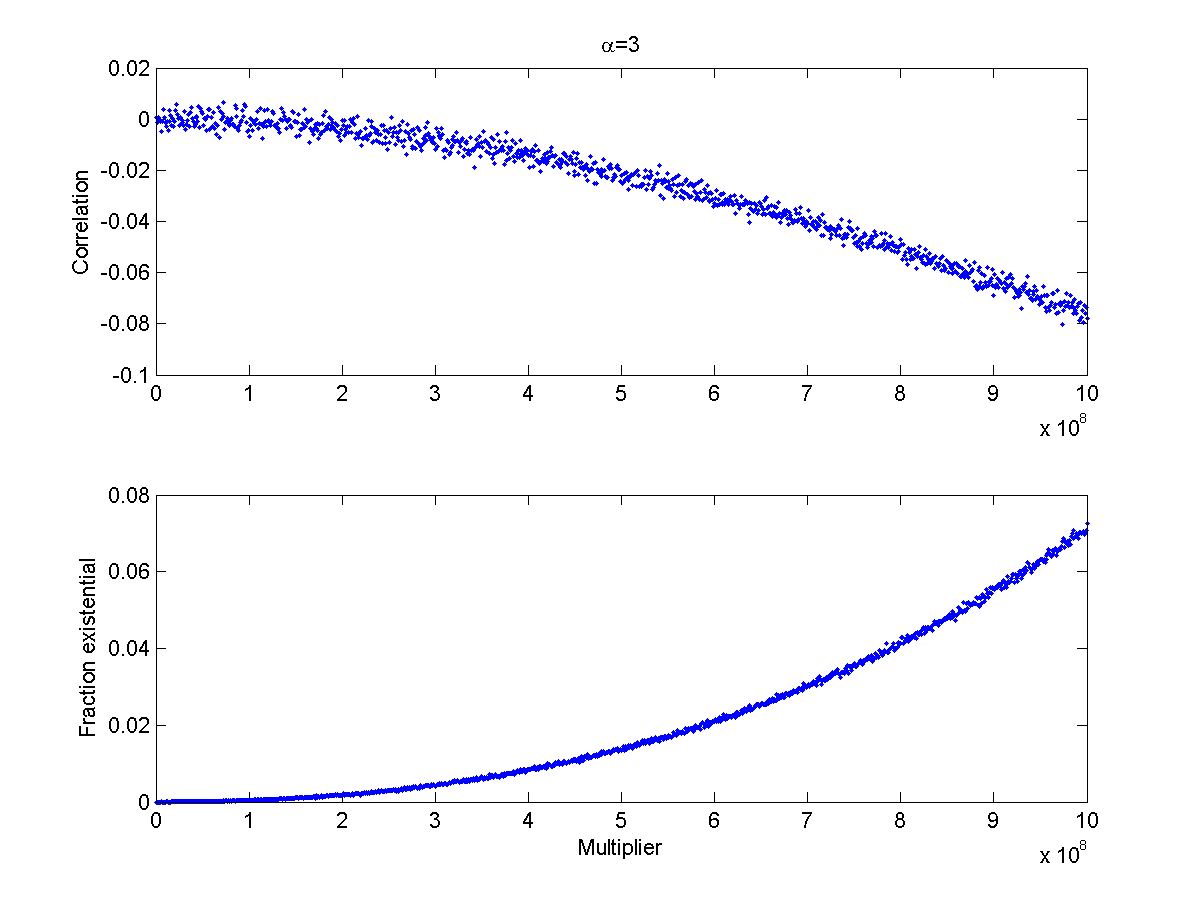
I tried a slightly more elaborate model. Assume X and Y to be independent power-law distributed disasters (say war and pestillence outbreaks), and that if X+Y is larger than seven billion no observers will remain to see the outcome. If we ramp up their size (by multiplying X and Y with some constant) we get the following behaviour (for alpha=3):
(Top) correlation between observed power-law distributed independent variables multiplied by an increasing multiplier, where observation is contingent on their sum being smaller than 7 billion. Each point corresponds to 100,000 trials. (Bottom) Fraction of trials where observers were wiped out.
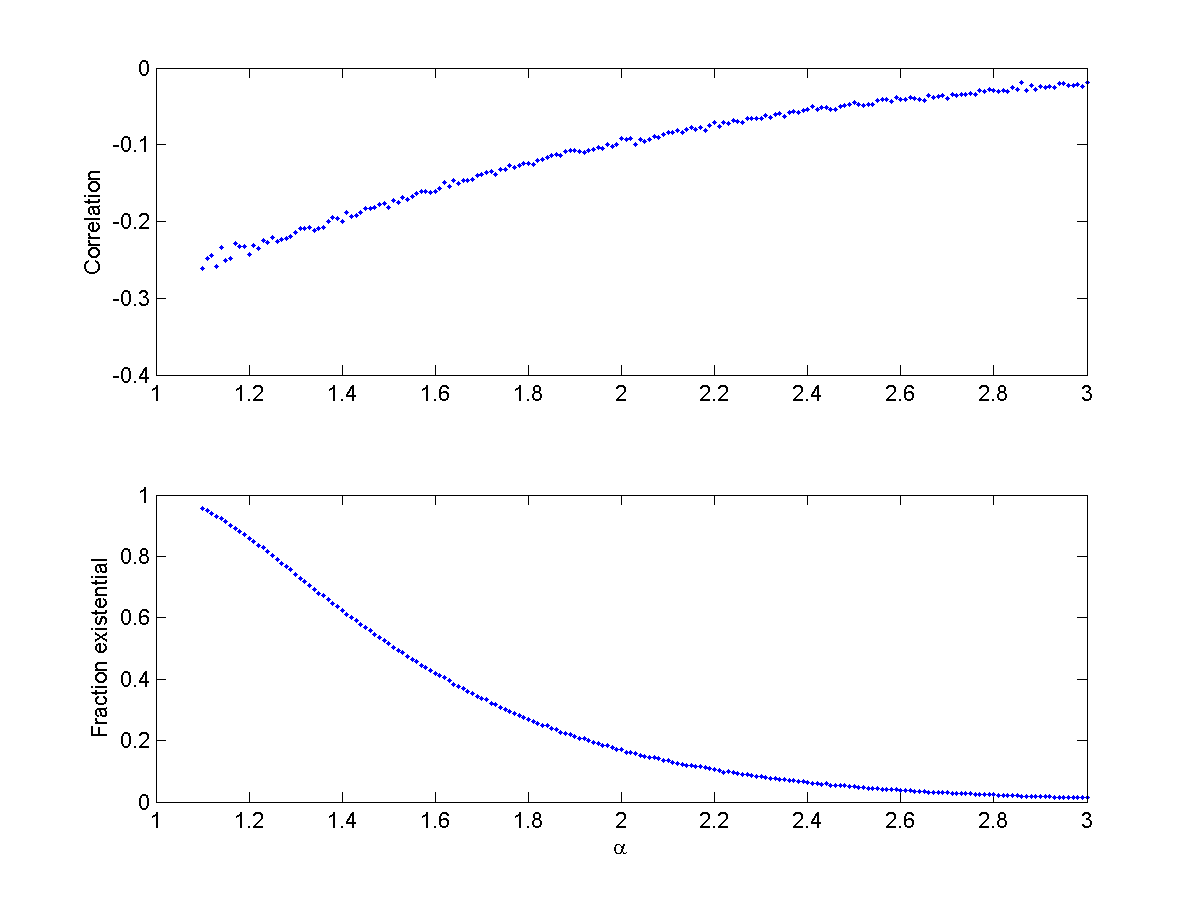
As the situation gets more deadly the correlation becomes more negative. This also happens when allowing the exponent run from the very fat (alpha=1) to the thinner (alpha=3):
(top) Correlation between observed independent power-law distributed variables (where observability requires their sum to be smaller than seven billion) for different exponents. (Bottom) fraction of trials ending in existential disaster. Multiplier=500 million.
The same thing also happens if we multiply X and Y.
I like the phenomenon: it gives us a way to look for anthropic effects by looking for suspicious anticorrelations. In particular, for the same variable the correlation ought to shift from near zero for small cases to negative for large cases. One prediction might be that periods of high superpower tension would be anticorrelated with mishaps in the nuclear weapon control systems. Of course, getting the data might be another matter. We might start by looking at extant companies with multiple risk factors like insurance companies and see if capital risk becomes anticorrelated with insurance risk at the high end.

















{kind=link}