Wired has an article about the CSER Existential Risk Conference in December 2016, rather flatteringly comparing us to superheroes. Plus a list of more or less likely risks we discussed. Calling them the “10 biggest threats” is perhaps exaggerating a fair bit: nobody is seriously worried about simulation shutdowns. But some of the others are worth working a lot more on.
High-energy demons
 I am cited as talking about existential risk from demon summoning. Since this is bound to be misunderstood, here is the full story:
I am cited as talking about existential risk from demon summoning. Since this is bound to be misunderstood, here is the full story:
As noted in the Wired list, we wrote a paper looking at the risk from the LHC, finding that there is a problem with analysing very unlikely (but high impact) risks: the probability of a mistake in the analysis overshadows the risk itself, making the analysis bad at bounding the risk. This can be handled by doing multiple independent risk bounds, which is a hassle, but it is the only (?) way to reliably conclude that things are safe.
I blogged a bit about the LHC issue before we wrote the paper, bringing up the problem of estimating probabilities for unprecedented experiments through the case of Taleb’s demon (which properly should be Taylor’s demon, but Stigler’s law of eponymy strikes again). That probably got me to have a demon association to the wider physics risk issues.
The issue of how to think about unprecedented risks without succumbing to precautionary paralysis is important: we cannot avoid doing new things, yet we should not be stupid about it. This is extra tricky when considering experiments that create things or conditions that are not found in nature.
Not so serious?
A closely related issue is when it is reasonable to regard a proposed risk as non-serious. Predictions of risk from strangelets, black holes, vacuum decay and other “theoretical noise” caused by theoretical physics theories at least is triggered by some serious physics thinking, even if it is far out. Physicists have generally tended to ignore such risks, but when forced by anxious acceleratorphobes the arguments had to be nontrivial: the initial dismissal was not really well founded. Yet it seems totally reasonable to dismiss some risks. If somebody worries that the alien spacegods will take exception to the accelerator we generally look for a psychiatrist rather than take them seriously. Some theories have so low prior probability that it seems rational to ignore them.
But what is the proper de minimis boundary here? One crude way of estimating it is to say that risks of destroying the world with lower probability than one in 10 billion can safely be ignored – they correspond to a risk of less than one person in expectation. But we would not accept that for an individual chemistry experiment: if the chance of being blown up if someone did it was “less than 100%” but still far above some tiny number, they would presumably want to avoid risking their neck. And in the physics risk case the same risk is borne by every living human. Worse, by Bostrom’s astronomical waste argument, existential risks risks more than 1046 possible future lives. So maybe we should put the boundary at less than 10-46: any risk more likely must be investigated in detail. That will be a lot of work. Still, there are risks far below this level: the probability that all humans were to die from natural causes within a year is around 10-7.2e11, which is OK.
One can argue that the boundary does not really exist: Martin Peterson argues that setting it at some fixed low probability, that realisations of the risk cannot be ascertained, or that it is below natural risks do not truly work: the boundary will be vague.
Demons lurking in the priors
Be as it may with the boundary, the real problem is that estimating prior probabilities is not always easy. They can vault over the vague boundary.
Hence my demon summoning example (from a blog post near Halloween I cannot find right now): what about the risk of somebody summoning a demon army? It might cause the end of the world. The theory “Demons are real and threatening” is not a hugely likely theory: atheists and modern Christians may assign it zero probability. But that breaks Cromwell’s rule: once you assign 0% to a probability no amount of evidence – including a demon army parading in front of you – will make you change your mind (or you are not applying probability theory correctly). The proper response is to assume some tiny probability  , conveniently below the boundary.
, conveniently below the boundary.
…except that there are a lot of old-fashioned believers who do think the theory “Demons are real and threatening” is a totally fine theory. Sure, most academic readers of this blog will not belong to this group and instead to the probability group. But knowing that there are people out there that think something different from your view should make you want to update your view in their direction a bit – after all, you could be wrong and they might know something you don’t. (Yes, they ought to move a bit in your direction too.) But now suppose you move 1% in the direction of the believers from your belief. You will now believe in the theory to  . That is, now you have a fairly good reason not to disregard the demon theory automatically. At least you should spend effort on checking it out. And once you are done with that you better start with the next crazy New Age theory, and the next conspiracy theory…
. That is, now you have a fairly good reason not to disregard the demon theory automatically. At least you should spend effort on checking it out. And once you are done with that you better start with the next crazy New Age theory, and the next conspiracy theory…
Reverend Bayes doesn’t help the unbeliever (or believer)
One way out is to argue that the probability of believers being right is so low that it can be disregarded. If they have probability of being right, then the actual demon risk is of size and we can ignore it – updates due to the others do not move us. But that is a pretty bold statement about human beliefs about anything: humans can surely be wrong about things, but being that certain that a common belief is wrong seems to require better evidence.
The believer will doubtlessly claim seeing a lot of evidence for the divine, giving some big update ![\Pr[belief|evidence]=\Pr[evidence|belief]\Pr[belief]/\Pr[evidence]](http://s0.wp.com/latex.php?latex=%5CPr%5Bbelief%7Cevidence%5D%3D%5CPr%5Bevidence%7Cbelief%5D%5CPr%5Bbelief%5D%2F%5CPr%5Bevidence%5D&bg=ffffff&fg=000000&s=0 "\Pr[belief|evidence]=\Pr[evidence|belief]\Pr[belief]/\Pr[evidence]") , but the non-believer will notice that the evidence is also pretty compatible with non-belief:
, but the non-believer will notice that the evidence is also pretty compatible with non-belief: ![\frac{\Pr[evidence|belief]}{\Pr[evidence|nonbelief]}\approx 1](http://s0.wp.com/latex.php?latex=%5Cfrac%7B%5CPr%5Bevidence%7Cbelief%5D%7D%7B%5CPr%5Bevidence%7Cnonbelief%5D%7D%5Capprox+1&bg=ffffff&fg=000000&s=0 "\frac{\Pr[evidence|belief]}{\Pr[evidence|nonbelief]}\approx 1") – most believers seem to have strong priors for their belief that they then strengthen by selective evidence or interpretation without taking into account the more relevant ratio
– most believers seem to have strong priors for their belief that they then strengthen by selective evidence or interpretation without taking into account the more relevant ratio ![\Pr[belief|evidence] / \Pr[nonbelief|evidence]](http://s0.wp.com/latex.php?latex=%5CPr%5Bbelief%7Cevidence%5D+%2F+%5CPr%5Bnonbelief%7Cevidence%5D&bg=ffffff&fg=000000&s=0 "\Pr[belief|evidence] / \Pr[nonbelief|evidence]") . And the believers counter that the same is true for the non-believers…
. And the believers counter that the same is true for the non-believers…
Insofar we are just messing around with our own evidence-free priors we should just assume that others might know something we don’t know (maybe even in a way that we do not even recognise epistemically) and update in their direction. Which again forces us to spend time investigating demon risk.
OK, let’s give in…
Another way of reasoning is to say that maybe we should investigate all risks somebody can make us guess a non-negligible prior for. It is just that we should allocate our efforts proportional to our current probability guesstimates. Start with the big risks, and work our way down towards the crazier ones. This is a bit like the post about the best problems to work on: setting priorities is important, and we want to go for the ones where we chew off most uninvestigated risk.
If we work our way down the list this way it seems that demon risk will be analysed relatively early, but also dismissed quickly: within the religious framework it is not a likely existential risk in most religions. In reality few if any religious people hold the view that demon summoning is an existential risk, since they tend to think that the end of the world is a religious drama and hence not intended to be triggered by humans – only divine powers or fate gets to start it, not curious demonologists.
That wasn’t too painful?
Have we defeated the demon summoning problem? Not quite. There is no reason for all those priors to sum to 1 – they are suggested by people with very different and even crazy views – and even if we normalise them we get a very long and heavy tail of weird small risks. We can easily use up any amount of effort on this, effort we might want to spend on doing other useful things like actually reducing real risks or doing fun particle physics.
There might be solutions to this issue by reasoning backwards: instead of looking at how X could cause Y that could cause Z that destroys the world we ask “If the world would be destroyed by Z, what would need to have happened to cause it?” Working backwards to Y, Y’, Y” and other possibilities covers a larger space than our initial chain from X. If we are successful we can now state what conditions are needed to get to dangerous Y-like states and how likely they are. This is a way of removing entire chunks of the risk landscape in efficient ways.
This is how I think we can actually handle these small, awkward and likely non-existent risks. We develop mental tools to efficiently get rid of lots of them in one fell sweep, leaving the stuff that needs to be investigated further. But doing this right… well, the devil lurks in the details. Especially the thicket of totally idiosyncratic risks that cannot be handled in a general way. Which is no reason not to push forward, armed with epsilons and Bayes’ rule.
Addendum (2017-02-14)
That the unbeliever may have to update a bit in the believer direction may look like a win for the believers. But they, if they are rational, should do a small update into the unbeliever direction. The most important consequence is that now they need to consider existential risks due to non-supernatural causes like nuclear war, AI or particle physics. They would assign them a lower credence than the unbeliever, but as per the usual arguments for the super-importance of existential risk this still means they may have to spend effort on thinking about and mitigating these risks that they otherwise would have dismissed as something God would have prevented. This may be far more annoying to them than unbelievers having to think a bit about demonology.
Emlyn O’Regan makes some great points over at Google+, which I think are worth analyzing:
- “Should you somehow incorporate the fact that the world has avoided destruction until now into your probabilities?”
- “Ideas without a tech angle might be shelved by saying there is no reason to expect them to happen soon.” (since they depend on world properties that have remained unchanged.)
- ” Ideas like demon summoning might be limited also by being shown to be likely to be the product of cognitive biases, rather than being coherent free-standing ideas about the universe.”
In the case of (1), observer selection effects can come into play. If there are no observers on a post demon-world (demons maybe don’t count) then we cannot expect to see instances of demon apocalypses in the past. This is why the cosmic ray argument for the safety of the LHC need to point to the survival of the Moon or other remote objects rather than the Earth to argue that being hit by cosmic rays over long periods prove that it is safe. Also, as noted by Emlyn, the Doomsday argument might imply that we should expect a relatively near-term end, given the length of our past: whether this matters or not depends a lot on how one handles observer selection theory.
In the case of (2), there might be development in summoning methods. Maybe medieval methods could not work, but modern computer-aided chaos magick is up to it. Or there could be rare “the stars are right” situations that made past disasters impossible. Still, if you understand the risk domain you may be able to show that the risk is constant and hence must have been low (or that we are otherwise living in a very unlikely world). Traditions that do not believe in a growth of esoteric knowledge would presumably accept that past failures are evidence of future inability.
(3) is an error theory: believers in the risk are believers not because of proper evidence but from faulty reasoning of some kind, so they are not our epistemic peers and we do not need to update in their direction. If somebody is trying to blow up a building with a bomb we call the police, but if they try to do it by cursing we may just watch with amusement: past evidence of the efficacy of magic at causing big effects is nonexistent. So we have one set of evidence-supported theories (physics) and another set lacking evidence (magic), and we make the judgement that people believing in magic are just deluded and can be ignored.
(Real practitioners may argue that there sure is evidence for magic, it is just that magic is subtle and might act through convenient coincidences that look like they could have happened naturally but occur too often or too meaningfully to be just chance. However, the skeptic will want to actually see some statistics for this, and in any case demon apocalypses look like they are way out of the league for this kind of coincidental magic).
Emlyn suggests that maybe we could scoop all the non-physics like human ideas due to brain architecture into one bundle, and assign them one epsilon of probability as a group. But now we have the problem of assigning an idea to this group or not: if we are a bit uncertain about whether it should have probability or a big one, then it will get at least some fraction of the big probability and be outside the group. We can only do this if we are really certain that we can assign ideas accurately, and looking at how many people psychoanalyse, sociologise or historicise topics in engineering and physics to “debunk” them without looking at actual empirical content, we should be wary of our own ability to do it.
So, in short, (1) and (2) do not reduce our credence in the risk enough to make it irrelevant unless we get a lot of extra information. (3) is decent at making us sceptical, but our own fallibility at judging cognitive bias and mistakes (which follows from claiming others are making mistakes!) makes error theories weaker than they look. Still, the really consistent lack of evidence of anything resembling the risk being real and that claims internal to the systems of ideas that accept the possibility imply that there should be smaller, non-existential, instances that should be observable (e.g. individual Fausts getting caught on camera visibly succeeding in summoning demons), and hence we can discount these systems strongly in favor of more boring but safe physics or hard-to-disprove but safe coincidental magic.





 distributed as
distributed as ") . The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value
. The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value ![V=E[x]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x]-1") . Suppose a cursory investigation costing much less gives some indication about
. Suppose a cursory investigation costing much less gives some indication about  . One approach is to select all items above a threshold
. One approach is to select all items above a threshold  , making
, making ![V=E[x_i|y_i<\theta]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx_i%7Cy_i%3C%5Ctheta%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x_i|y_i<\theta]-1") .
., \epsilon \sim N(0,\sigma_\epsilon^2)") , then
, then  \Phi\left(\frac{t-\mu_x}{\sqrt{\sigma_x^2+\sigma_\epsilon^2}}\right)dt") . While one can ram through this using
. While one can ram through this using  (the correlation between x and y is 0.707, so this is not too much noise):
(the correlation between x and y is 0.707, so this is not too much noise):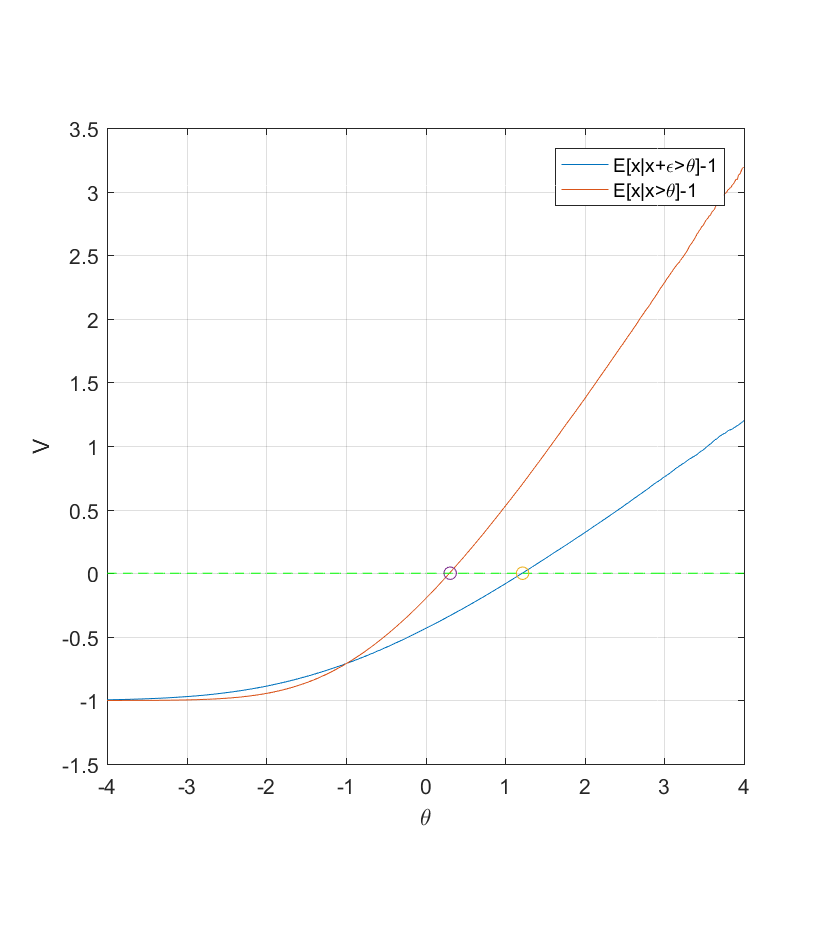



{kind=link}