“What about a holiday in Lincolnshire?”
“Sounds good. Maybe some golf?”
“Yes. I need to work on my handicap. Or rather, our handicap. Tomorrow?”
“Great. See you there – I can’t wait.”
I start setting up a normal weekend getaway. I hope Ben gets the golf reference right so he brings the St. Andrews files. I did not dare to mention their existence during the call.
The first version was online censorship systems blocking or changing offensive words. Many were too literal-minded: looking for a sequence of characters they blocked legit names and locations (“the Scunthorpe problem”) or did substitutions that made things worse (“the clbuttic mistake”). But as spam filtering and text processing improved, so did performance.
The next version was the detection of IP violations. Rolled out during the IP Wars of the early 21st century they were also at first laughable: blocking videos of political conventions because of some strand of protected music, blocking NASA footage because some news channel had the footage inside its own IP-protected material. But the economic incentives for getting it right were enormous.
“Martha, could you clear a trip to Ashby?”
“The golf course near Silica? Trent is Level 4 advisory. Would Canwick do?”
My office automation is too clever, so it takes me a bit of negotiation to set up a travel plan that passes the insurance and safety guidelines. The irony is that due to my seniority I have less freedom than many of the junior filterers. I am essential personnel, as HR loves to tell me.
Being able to block certain information was of course useful to governments, democratic or not. The IP infrastructure was a natural synergy: if a protest movement began using a certain meme or symbol, just file a spurious infringement complaint and get it blocked everywhere. Much more seamless than direct takedown notices or using the anti-paedophilia infrastructure since people were used to seeing information blocked for IP reasons every day. Sure, humans are innovative and will quickly invent new codes. But it could stop riots from reaching the percolation threshold, prevent memes from reaching consensus, hide embarrassing facts, and the system gave you surveillance for free.
“Could you help me access the ClearWater forum? It forgot that I am the PI again.” Hannu asks as I pass the work den. I beam over a signed limited-time certificate and wait for the acknowledgements that it has diffused properly: it wouldn’t do to seem in a hurry. We chitchat about the annoying roadworks outside – why were we not informed about them beforehand?
Hannu, Ben and Ali used to argue with me about how to strike a balance. Of course we saw the potential totalitarian aspects, and we did try to find solutions.
Then came the Cytokine Wars. 2 billion dead. As battling biohackers – if that was what it actually was – spread their designer plagues using commodity DNA printers and home pharma systems it became clear that some information must be stopped at all costs. Filtering dangerous sequences had a high price, but it managed to quell the War. There were of course plenty of problems – researchers trying to find cures finding their files censored or even being hauled away by some intelligence service with no notion of what was going on. Natural species censored for reasons nobody could put a finger on: who knows what Gymnocalcium hides, since no legal lab equipment will touch it? Limits to human freedom, inquiry and innovation, yes… but 2 billion dead. It could have been 8.
Since then things have accelerated. We have other technology now, technology that makes the early biohacking look tame. Macro-EBC origami, rosettatronics, even charge-flipping. Each potentially worse than all nightmares of designer plagues and white goo together.
People have mostly accepted it. At least we do not hear much criticism or suggested alternatives. Ali of course suggested that it was because the system increasingly filters out criticism, dampening it until it no longer has social critical mass. But he was always a bit of a paranoid.
“Have you heard from Ali recently?” Tina asks in the elevator.
“Isn’t he on a sabbatical at Zhejiang?”
“I thought so, but I cannot reach him.”
“I’m sure he is just on one of his surfing holidays.”
Tina looks sceptical, briefly glances upwards, but agrees. I just smile and ask how the kids are doing.
The problem with a censorship system is that it tends to censor discussion about itself. It is only natural: if you know how it works you can undermine it, unleashing danger. At first our system even ended up censoring itself, getting dragged into amusing software loops as it tried to hide evidence that it was trying to hide evidence. But huge investments of effort and ingenuity solved the problem. It now balances itself like the immune system, with virtual antibodies forming epistatic networks: filter autoimmunity was a solved problem, we proclaimed. And excessive false positives could always be managed, we thought.
But now… At first it was just more and more glitches on the whitelisted forums where we did our development, slowing discussion. We were losing contact with other experts. Then access to the software layer became blocked. Colleagues trying to fix things disappeared.
They grab me on the parking lot. Nondescript people whose faces I cannot focus on. I try to beam my clearance and certificates at them, but the communication is blocked.
“What is it? What are you accusing me of?” I ask loudly.
They cannot hear or answer.

 distributed as
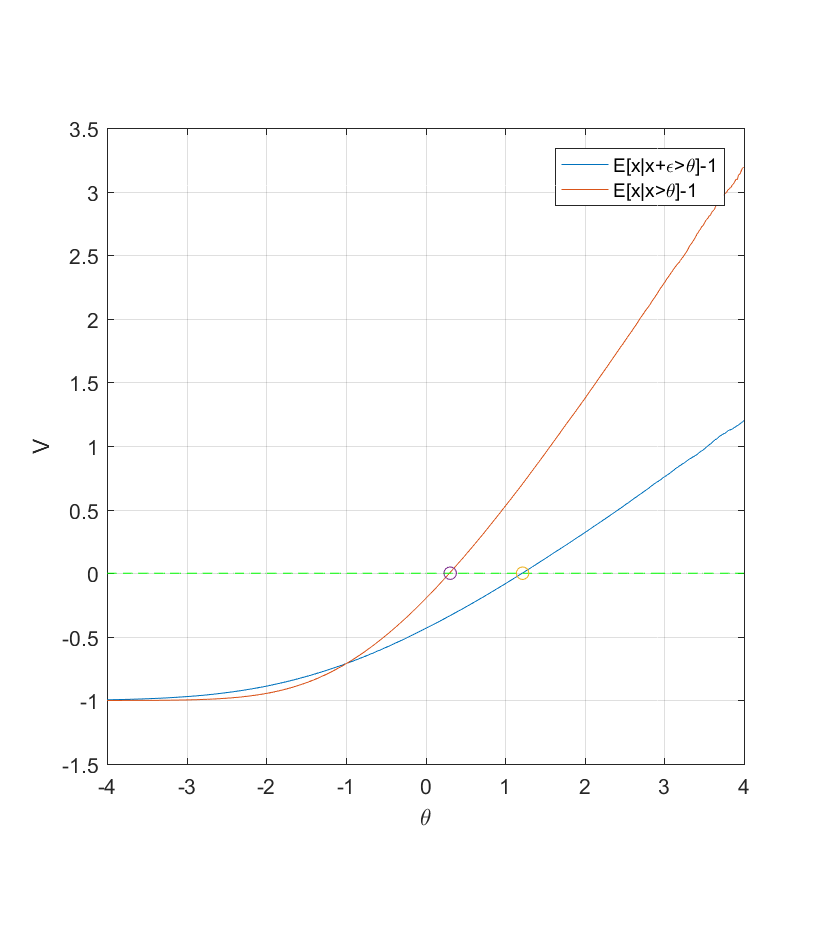
distributed as ") . The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value
. The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value ![V=E[x]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x]-1") . Suppose a cursory investigation costing much less gives some indication about
. Suppose a cursory investigation costing much less gives some indication about  . One approach is to select all items above a threshold
. One approach is to select all items above a threshold  , making
, making ![V=E[x_i|y_i<\theta]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx_i%7Cy_i%3C%5Ctheta%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x_i|y_i<\theta]-1") .
., \epsilon \sim N(0,\sigma_\epsilon^2)") , then
, then  \Phi\left(\frac{t-\mu_x}{\sqrt{\sigma_x^2+\sigma_\epsilon^2}}\right)dt") . While one can ram through this using
. While one can ram through this using  (the correlation between x and y is 0.707, so this is not too much noise):
(the correlation between x and y is 0.707, so this is not too much noise):