I have recently begun to work on the problem of information hazards: when spreading true information is causing danger. Since we normally regard information as a good thing this is a bit unusual and understudied, and in the case of existential risk it is important to get things right at the first try.
However, concealing information can also produce risk. This book is an excellent series of case studies of major disasters, showing how the practice of hiding information contributed to make them possible, worse, and hinder rescue/recovery.
Chernov and Sornette focus mainly on technological disasters such as the Vajont Dam, Three Mile Island, Bhopal, Chernobyl, the Ufa train disaster, Fukushima and so on, but they also cover financial disasters, military disasters, production industry failures and concealment of product risk. In all of these cases there was plentiful concealment going on at multiple levels, from workers blocking alarms to reports being classified or deliberately mislaid to active misinformation campaigns.
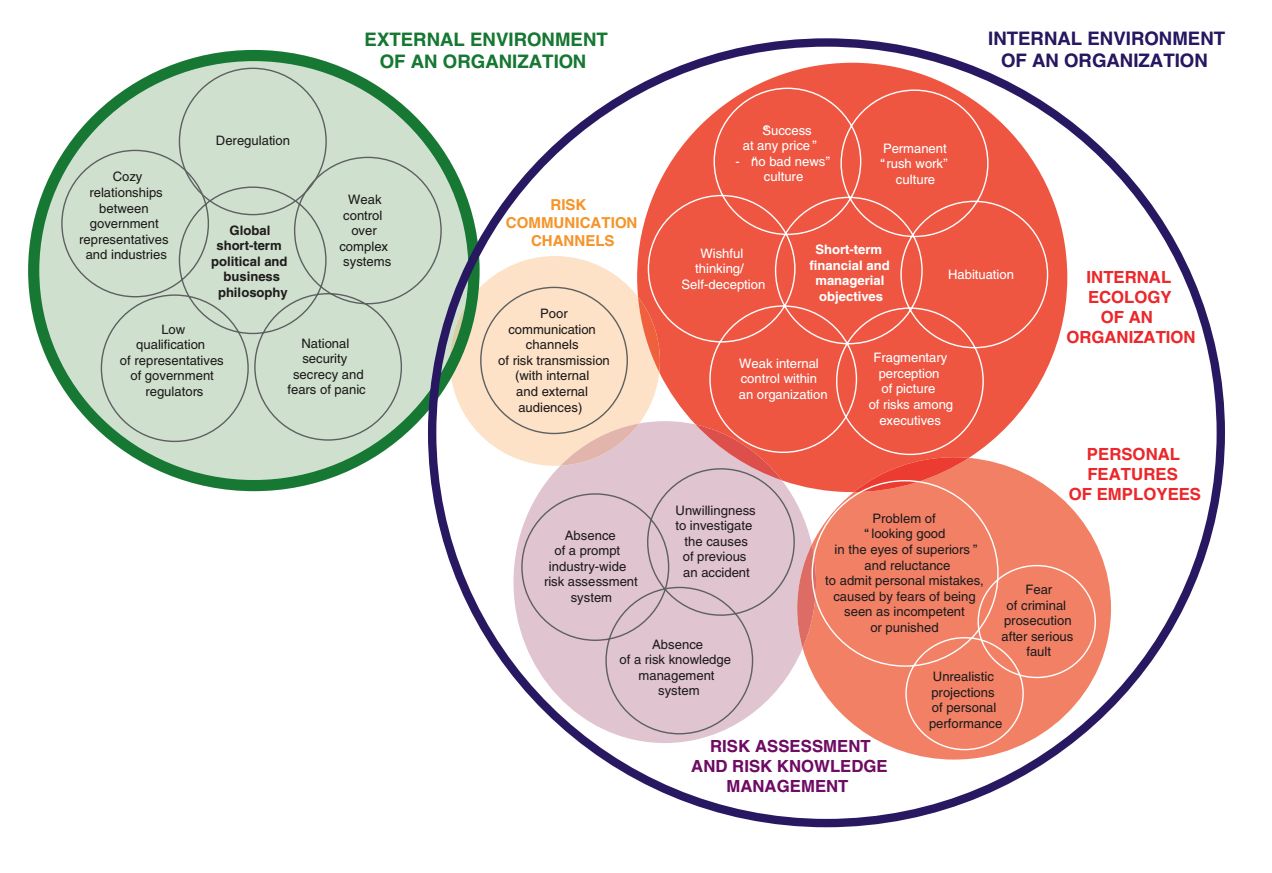
Chernov and Sornette’s model of the factors causing or contributing to risk concealment.
When summed up, many patterns of information concealment recur again and again. They sketch out a model of the causes of concealment, with about 20 causes grouped into five major clusters: the external environment enticing concealment, risk communication channels blocked, an internal ecology stimulating concealment or ignorance, faulty risk assessment and knowledge management, and people having personal incentives to conceal.
The problem is very much systemic: having just one or two of the causative problems can be counteracted by good risk management, but when several causes start to act together they become much harder to deal with – especially since many corrode the risk management ability of the entire organisation. Once risks are hidden, it becomes harder to manage them (management, after all, is done through information). Conversely, they list examples of successful risk information management: risk concealment may be something that naturally tends to emerge, but it can be counteracted.
Chernov and Sornette also apply their model to some technologies they think show signs of risk concealment: shale energy, GMOs, real debt and liabilities of the US and China, and the global cyber arms race. They are not arguing that a disaster is imminent, but the patterns of concealment are a reason for concern: if they persist, they have potential to make things worse the day something breaks.
Is information concealment the cause of all major disasters? Definitely not: some disasters are just due to exogenous shocks or surprise failures of technology. But as Fukushima shows, risk concealment can make preparation brittle and handling the aftermath inefficient. There is also likely plentiful risk concealment in situations that will never come to attention because there is no disaster necessitating and enabling a thorough investigation. There is little to suggest that the examined disasters were all uniquely bad from a concealment perspective.
From an information hazard perspective, this book is an important rejoinder: yes, some information is risky. But lack of information can be dangerous too. Many of the reasons for concealment like national security secrecy, fear of panic, prevention of whistle-blowing, and personnel being worried about personally being held accountable for a serious fault are maladaptive information hazard management strategies. The worker not reporting a mistake is handling a personal information hazard, at the expense of the safety of the entire organisation. Institutional secrecy is explicitly intended to contain information hazards, but tends to compartmentalize and block relevant information flows.
A proper information hazard management strategy needs to take the concealment risk into account too: there is a risk cost of not sharing information. How these two risks should be rationally traded against each other is an important question to investigate.
The quick of it is that it will mess with our definitions of who happens to be dead, but that is mostly a matter of sorting out practice and definitions, and that it is somewhat questionable who is benefiting: the original patient is unlikely to recover, but we might get a moral patient we need to care for even if they are not a person, or even a different person (or most likely, just generally useful medical data but no surviving patient at all). The problem is that partial success might be worse than no success. But the only way of knowing is to try.
I have been working on the Fermi paradox for a while, and in particular the mathematical structure of the Drake equation. While it looks innocent, it has some surprising issues.
One area I have not seen much addressed is the independence of terms. To a first approximation they were made up to be independent: the fraction of life-bearing Earth-like planets is presumably determined by a very different process than the fraction of planets that are Earth-like, and these factors should have little to do with the longevity of civilizations. But as Häggström and Verendel showed, even a bit of correlation can cause trouble.
If different factors in the Drake equation vary spatially or temporally, we should expect potential clustering of civilizations: the average density may be low, but in areas where the parameters have larger values there would be a higher density of civilizations. A low may not be the whole story. Hence figuring out the typical size of patches (i.e. the autocorrelation distance) may tell us something relevant.
Astrophysical correlations
There is a sometimes overlooked spatial correlation in the first terms. In the orthodox formulation we are talking about earth-like planets orbiting stars with planets, which form at some rate in the Milky Way. This means that civilizations must be located in places where there are stars (galaxies), and not anywhere else. The rare earth crowd also argues that there is a spatial structure that makes earth-like worlds exist within a ring-shaped region in the galaxy. This implies an autocorrelation on the order of (tens of) kiloparsecs.
A tangent: different kinds of matter plausibly have different likelihood of originating life. Note that this has an interesting implication: if the probability of life emerging in something like the intergalactic plasma is non-zero, it has to be more than a hundred thousand times smaller than the probability per unit mass of planets, or the universe would be dominated by gas-creatures (and we would be unlikely observers, unless gas-life was unlikely to generate intelligence). Similarly life must be more than 2,000 times more likely on planets than stars (per unit of mass), or we should expect ourselves to be star-dwellers. Our planetary existence does give us some reason to think life or intelligence in the more common substrates (plasma, degenerate matter, neutronium) is significantly less likely than molecular matter.
Biological correlations
One way of inducing correlations in the factor is panspermia. If life originates at some low rate per unit volume of space (we will now assume a spatially homogeneous universe in terms of places life can originate) and then diffuses from a nucleation site, then intelligence will show up in spatially correlated locations.
It is not clear how much panspermia could be going on, or if all kinds of life do it. A simple model is that panspermias emerge at a density and grow to radius . The rate of intelligence emergence outside panspermias is set to 1 per unit volume (this sets a space scale), and inside a panspermia (since there is more life) it will be per unit volume. The probability that a given point will be outside a panspermia is
.
The fraction of civilizations finding themselves outside panspermias will be
.
As A increases, vastly more observers will be in panspermias. If we think it is large, we should expect to be in a panspermia unless we think the panspermia efficiency (and hence r) is very small. Loosely, the transition from going from 1% to 99% probability takes one order of magnitude change in r, three orders of magnitude in and four in A: given that these parameters can a priori range over many, many orders of magnitude, we should not expect to be in the mixed region where there are comparable numbers of observers inside panspermias and outside. It is more likely all or nothing.
There is another relevant distance beside , the expected distance to the next civilization. This is where is the density of civilizations. For the outside panspermia case this is , while inside it is . Note that these distances are not dependent on the panspermia sizes, since they come from an independent process (emergence of intelligence given a life-bearing planet rather than how well life spreads from system to system).
If then there will be no panspermia-induced correlation between civilization locations, since there is less than one civilization per panspermia. For there will be clustering with a typical autocorrelation distance corresponding to the panspermia size. For even larger panspermias they tend to dominate space (if is not very small) and there is no spatial structure any more.
So if panspermias have sizes in a certain range, , the actual distance to the nearest neighbour will be smaller than what one would have predicted from the average values of the parameters of the drake equation.
Nearest neighbour distance for civilizations in a model with spherical panspermias and corresponding randomly re-sampled distribution.
Running a Monte Carlo simulation shows this effect. Here I use 10,000 possible life sites in a cubical volume, and – the number of panspermias will be Poisson(1) distributed. The background rate of civilizations appearing is 1/10,000, but in panspermias it is 1/100. As I make panspermias larger civilizations become more common and the median distance from a civilization to the next closest civilization falls (blue stars). If I re-sample so the number of civilizations are the same but their locations are uncorrelated I get the red crosses: the distances decline, but they can be more than a factor of 2 larger.
Technological correlations
The technological terms and can also show spatial patterns, if civilizations spread out from their origin.
The basic colonization argument by Hart and Tipler assumes a civilization will quickly spread out to fill the galaxy; at this point if we count inhabited systems. If we include intergalactic colonization, then in due time, everything out to a radius of reachability on the order of 4 gigaparsec (for near c probes) and 1.24 gigaparsec (for 50% c probes). Within this domain it is plausible that the civilization could maintain whatever spatio-temporal correlations it wishes, from perfect homogeneity over the zoo hypothesis to arbitrary complexity. However, the reachability limit is due to physics and do impose a pretty powerful limit: any correlation in the Drake equation due to a cause at some point in space-time will be smaller than the reachability horizon (as measured in comoving coordinates) for that point.
Total colonization is still compatible with an empty galaxy if is short enough. Galaxies could be dominated by a sequence of “empires” that disappear after some time, and if the product between empire emergence rate and is small enough most eras will be empty.
A related model is Brin’s resource exhaustion model, where civilizations spread at some velocity but also deplete their environment at some (random rate). The result is a spreading shell with an empty interior. This has some similarities to Hanson’s “burning the cosmic commons scenario”, although Brin is mostly thinking in terms of planetary ecology and Hanson in terms of any available resources: the Hanson scenario may be a single-shot situation. In Brin’s model “nursery worlds” eventually recover and may produce another wave. The width of the wave is proportional to where is the expansion speed; if there is a recovery parameter corresponding to the time before new waves can emerge we should hence expect spatial correlation length of order . For light-speed expansion and a megayear recovery (typical ecology and fast evolutionary timescale) we would get a length of a million light-years.
Another approach is the percolation theory inspired models first originated by Landis. Here civilizations spread short distances, and “barren” offshoots that do not colonize form a random “bark” around the network of colonization (or civilizations are limited to flights shorter than some distance). If the percolation parameter is low, civilizations will only spread to a small nearby region. When it increases larger and larger networks are colonized (forming a fractal structure), until a critical parameter value where the network explodes and reaches nearly anywhere. However, even above this transition there are voids of uncolonized worlds. The correlation length famously scales as , where for this case. The probability of a random site belonging to the infinite cluster for scales as () and the mean cluster size (excluding the infinite cluster) scales as ().
So in this group of models, if the probability of a site producing a civilization is the probability of encountering another civilization in one’s cluster is
for . Above the threshold it is essentially 1; there is a small probability of being inside a small cluster, but it tends to be minuscule. Given the silence in the sky, were a percolation model the situation we should conclude either an extremely low or a low .
Temporal correlations
Another way the Drake equation can become misleading is if the parameters are time varying. Most obviously, the star formation rate has changed over time. The metallicity of stars have changed, and we should expect any galactic life zones to shift due to this.
In my opinion the most important temporal issue is inherent in the Drake equation itself. It assumes a steady state! At the left we get new stars arriving at a rate , and at the right the rate gets multiplied by the longevity term for civilizations , producing a dimensionless number. Technically we can plug in a trillion years for the longevity term and get something that looks like a real estimate of a teeming galaxy, but this actually breaks the model assumptions. If civilizations survived for trillions of years, the number of civilizations would currently be increasing linearly (from zero at the time of the formation of the galaxy) – none would have gone extinct yet. Hence we can know that in order to use the unmodified Drake equation has to be years.
Making a temporal Drake equation is not impossible. A simple variant would be something like
where the first term is just the factors of the vanilla equation regarded as time-varying functions and the second term a decay corresponding to civilizations dropping out at a rate of 1/L (this assumes exponentially distributed survival, a potentially doubtful assumption). The steady state corresponds to the standard Drake level, and is approached with a time constant of 1/L. One nice thing with this equation is that given a particular civilization birth rate corresponding to the first term, we get an expression for the current state:
.
Note how any spike in gets smoothed by the exponential, which sets the temporal correlation length.
If we want to do things even more carefully, we can have several coupled equations corresponding to star formation, planet formation, life formation, biosphere survival, and intelligence emergence. However, at this point we will likely want to make a proper “demographic” model that assumes stars, biospheres and civilization have particular lifetimes rather than random disappearance. At this point it becomes possible to include civilizations with different L, like Sagan’s proposal that the majority of civilizations have short L but some have very long futures.
The overall effect is still a set of correlation timescales set by astrophysics (star and planet formation rates), biology (life emergence and evolution timescales, possibly the appearance of panspermias), and civilization timescales (emergence, spread and decay). The overall effect is dominated by the slowest timescale (presumably star formation or very long-lasting civilizations).
Conclusions
Overall, the independence of the terms of the Drake equation is likely fairly strong. However, there are relevant size scales to consider.
Over multiple gigaparsec scales there can not be any correlations, not even artificially induced ones, because of limitations due to the expansion of the universe (unless there are super-early or FTL civilizations).
Over hundreds of megaparsec scales the universe is fairly uniform, so any natural influences will be randomized beyond this scale.
Colonization waves in Brin’s model could have scales on the galactic cluster scale, but this is somewhat parameter dependent.
The nearest civilization can be expected around , where is the galactic volume. If we are considering parameters such that the number of civilizations per galaxy are low V needs to be increased and the density will go down significantly (by a factor of about 100), leading to a modest jump in expected distance.
Panspermias, if they exist, will have an upper extent limited by escape from galaxies – they will tend to have galactic scales or smaller. The same is true for galactic habitable zones if they exist. Percolation colonization models are limited to galaxies (or even dense parts of galaxies) and would hence have scales in the kiloparsec range.
“Scars” due to gamma ray bursts and other energetic events are below kiloparsecs.
The lower limit of panspermias are due to being smaller than the panspermia, presumably at least in the parsec range. This is also the scale of close clusters of stars in percolation models.
Time-wise, the temporal correlation length is likely on the gigayear timescale, dominated by stellar processes or advanced civilization survival. The exception may be colonization waves modifying conditions radically.
In the end, none of these factors appear to cause massive correlations in the Drake equation. Personally, I would guess the most likely cause of an observed strong correlation between different terms would be artificial: a space-faring civilization changing the universe in some way (seeding life, wiping out competitors, converting it to something better…)
That trolling is a shameful thing, and that no one of sense would accept to be called ‘troll’, all are agreed; but what trolling is, and how many its species are, and whether there is an excellence of the troll, is unclear. And indeed trolling is said in many ways; for some call ‘troll’ anyone who is abusive on the internet, but this is only the disagreeable person, or in newspaper comments the angry old man. And the one who disagrees loudly on the blog on each occasion is a lover of controversy, or an attention-seeker. And none of these is the troll, or perhaps some are of a mixed type; for there is no art in what they do. (Whether it is possible to troll one’s own blog is unclear; for the one who poses divisive questions seems only to seek controversy, and to do so openly; and this is not trolling but rather a kind of clickbait.)
Aristotle’s definition is quite useful:
The troll in the proper sense is one who speaks to a community and as being part of the community; only he is not part of it, but opposed. And the community has some good in common, and this the troll must know, and what things promote and destroy it: for he seeks to destroy.
He then goes on analysing the knowledge requirements of trolling, the techniques, the types or motivations of trolls, the difference between a gadfly like Socrates and a troll, and what communities are vulnerable to trolls. All in a mere two pages.
(If only the medieval copyists had saved his other writings on the Athenian Internet! But the crash and split of Alexander the Great’s social media empire destroyed many of them before that era.)
The text reminds me of another must-read classic, Harry Frankfurt’s “On Bullshit”. There Frankfurt analyses the nature of bullshitting. His point is that normal deception cares about the truth: it aims to keep someone from learning it. But somebody producing bullshit does not care about the truth or falsity of the statements made, merely that they fit some manipulative, social or even time-filling aim.
It is just this lack of connection to a concern with truth – this indifference to how things really are – that I regard as of the essence of bullshit.
It is pernicious, since it fills our social and epistemic arena with dodgy statements whose value is uncorrelated to reality, and the bullshitters gain from the discourse being more about the quality (or the sincerity) of bullshitting than any actual content.
Both of these essays are worth reading in this era of the Trump candidacy and Dugin’s Eurasianism. Know your epistemic enemies.
By Anders Sandberg, Future of Humanity Institute, Oxford Martin School, University of Oxford
Thinking of the future is often done as entertainment. A surprising number of serious-sounding predictions, claims and prophecies are made with apparently little interest in taking them seriously, as evidenced by how little they actually change behaviour or how rarely originators are held responsible for bad predictions. Rather, they are stories about our present moods and interests projected onto the screen of the future. Yet the future matters immensely: it is where we are going to spend the rest of our lives. As well as where all future generations will live – unless something goes badly wrong.
Olle Häggström’s book is very much a plea for taking the future seriously, and especially for taking exploring the future seriously. As he notes, there are good reasons to believe that many technologies under development will have enormous positive effects… and also good reasons to suspect that some of them will be tremendously risky. It makes sense to think about how we ought to go about avoiding the risks while still reaching the promise.
Current research policy is often directed mostly towards high quality research rather than research likely to make a great difference in the long run. Short term impact may be rewarded, but often naively: when UK research funding agencies introduced impact evaluation a few years back, their representatives visiting Oxford did not respond to the question on whether impact had to be positive. Yet, as Häggström argues, obviously the positive or negative impact of research must matter! A high quality investigation into improved doomsday weapons should not be pursued. Investigating the positive or negative implications of future research and technology has high value, even if it is difficult and uncertain.
Inspired by James Martin’s The Meaning of the 21st Century this book is an attempt to make a broad map sketch of parts of the future that matters, especially the uncertain corners where we have reason to think dangerous dragons lurk. It aims more at scope than the detail of many of the covered topics, making it an excellent introduction and pointer towards the primary research.
One obvious area is climate change, not just in terms of its direct (and widely recognized risks) but the new challenges posed by geoengineering. Geoengineering may both be tempting to some nations and possible to perform unilaterally, yet there are a host of ethical, political, environmental and technical risks linked to it. It also touches on how far outside the box we should search for solutions: to many geoengineering is already too far, but other proposals such as human engineering (making us more eco-friendly) go much further. When dealing with important challenges, how do we allocate our intellectual resources?
Other areas Häggström reviews include human enhancement, artificial intelligence, and nanotechnology. In each of these areas tremendously promising possibilities – that would merit a strong research push towards them – are intermixed with different kinds of serious risks. But the real challenge may be that we do not yet have the epistemic tools to analyse these risks well. Many debates in these areas contain otherwise very intelligent and knowledgeable people making overconfident and demonstrably erroneous claims. One can also argue that it is not possible to scientifically investigate future technology. Häggström disagrees with this: one can analyse it based on currently known facts and using careful probabilistic reasoning to handle the uncertainty. That results are uncertain does not mean they are useless for making decisions.
He demonstrates this by analysing existential risks, scenarios for the long term future humanity and what the “Fermi paradox” may tell us about our chances. There is an interesting interplay between uncertainty and existential risk. Since our species can end only once, traditional frequentist approaches run into trouble Bayesian methods do not. Yet reasoning about events that are unprecedented also makes our arguments terribly sensitive to prior assumptions, and many forms of argument are more fragile than they first look. Intellectual humility is necessary for thinking about audacious things.
In the end, this book is as much a map of relevant areas of philosophy and mathematics containing tools for exploring the future, as it is a direct map of future technologies. One can read it purely as an attempt to sketch where there may be dragons in the future landscape, but also as an attempt at explaining how to go about sketching the landscape. If more people were to attempt that, I am confident that we would fence in the dragons better and direct our policies towards more dragon-free regions. That is a possibility worth taking very seriously.
[Conflict of interest: several of my papers are discussed in the book, both critically and positively.]


 may not be the whole story. Hence figuring out the typical size of patches (i.e. the autocorrelation distance) may tell us something relevant.
may not be the whole story. Hence figuring out the typical size of patches (i.e. the autocorrelation distance) may tell us something relevant. factor is
factor is  and grow to radius
and grow to radius  . The rate of intelligence emergence outside panspermias is set to 1 per unit volume (this sets a space scale), and inside a panspermia (since there is more life) it will be
. The rate of intelligence emergence outside panspermias is set to 1 per unit volume (this sets a space scale), and inside a panspermia (since there is more life) it will be  per unit volume. The probability that a given point will be outside a panspermia is
per unit volume. The probability that a given point will be outside a panspermia is r^3 \rho}") .
.} = \frac{1}{1+A(e^{(4 \pi/3)r^3 \rho}-1)}") .
.![d \approx 0.55/\sqrt[3]{\lambda}](http://s0.wp.com/latex.php?latex=d+%5Capprox+0.55%2F%5Csqrt%5B3%5D%7B%5Clambda%7D&bg=ffffff&fg=000000&s=0 "d \approx 0.55/\sqrt[3]{\lambda}") where
where  is the density of civilizations. For the outside panspermia case this is
is the density of civilizations. For the outside panspermia case this is  , while inside it is
, while inside it is ![d_{inside}=0.55/\sqrt[3]{A}](http://s0.wp.com/latex.php?latex=d_%7Binside%7D%3D0.55%2F%5Csqrt%5B3%5D%7BA%7D&bg=ffffff&fg=000000&s=0 "d_{inside}=0.55/\sqrt[3]{A}") . Note that these distances are not dependent on the panspermia sizes, since they come from an independent process (emergence of intelligence given a life-bearing planet rather than how well life spreads from system to system).
. Note that these distances are not dependent on the panspermia sizes, since they come from an independent process (emergence of intelligence given a life-bearing planet rather than how well life spreads from system to system). then there will be no panspermia-induced correlation between civilization locations, since there is less than one civilization per panspermia. For
then there will be no panspermia-induced correlation between civilization locations, since there is less than one civilization per panspermia. For  there will be clustering with a typical autocorrelation distance corresponding to the panspermia size. For even larger panspermias they tend to dominate space (if
there will be clustering with a typical autocorrelation distance corresponding to the panspermia size. For even larger panspermias they tend to dominate space (if ![0.55/\sqrt[3]{A}<r<0.55](http://s0.wp.com/latex.php?latex=0.55%2F%5Csqrt%5B3%5D%7BA%7D%3Cr%3C0.55&bg=ffffff&fg=000000&s=0 "0.55/\sqrt[3]{A}<r<0.55") , the actual distance to the nearest neighbour will be smaller than what one would have predicted from the average values of the parameters of the drake equation.
, the actual distance to the nearest neighbour will be smaller than what one would have predicted from the average values of the parameters of the drake equation.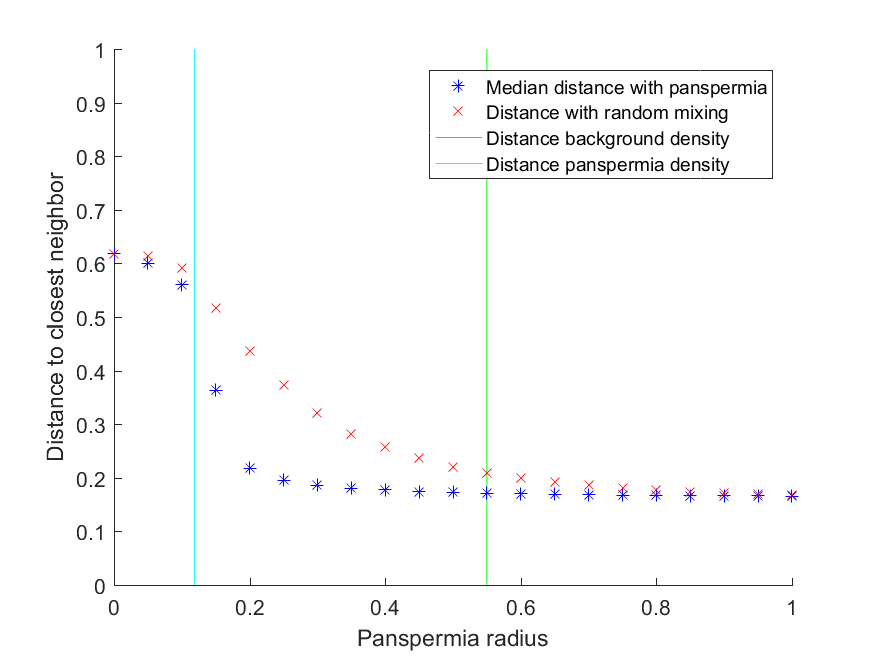
 – the number of panspermias will be Poisson(1) distributed. The background rate of civilizations appearing is 1/10,000, but in panspermias it is 1/100. As I make panspermias larger civilizations become more common and the median distance from a civilization to the next closest civilization falls (blue stars). If I re-sample so the number of civilizations are the same but their locations are uncorrelated I get the red crosses: the distances decline, but they can be more than a factor of 2 larger.
– the number of panspermias will be Poisson(1) distributed. The background rate of civilizations appearing is 1/10,000, but in panspermias it is 1/100. As I make panspermias larger civilizations become more common and the median distance from a civilization to the next closest civilization falls (blue stars). If I re-sample so the number of civilizations are the same but their locations are uncorrelated I get the red crosses: the distances decline, but they can be more than a factor of 2 larger. and
and  can also show spatial patterns, if civilizations spread out from their origin.
can also show spatial patterns, if civilizations spread out from their origin. if we count inhabited systems. If we include
if we count inhabited systems. If we include  where
where  is the expansion speed; if there is a recovery parameter
is the expansion speed; if there is a recovery parameter  corresponding to the time before new waves can emerge we should hence expect spatial correlation length of order
corresponding to the time before new waves can emerge we should hence expect spatial correlation length of order v") . For light-speed expansion and a megayear recovery (typical ecology and fast evolutionary timescale) we would get a length of a million light-years.
. For light-speed expansion and a megayear recovery (typical ecology and fast evolutionary timescale) we would get a length of a million light-years. is low, civilizations will only spread to a small nearby region. When it increases larger and larger networks are colonized (
is low, civilizations will only spread to a small nearby region. When it increases larger and larger networks are colonized ( where the network explodes and reaches nearly anywhere. However, even above this transition there are voids of uncolonized worlds. The correlation length famously scales as
where the network explodes and reaches nearly anywhere. However, even above this transition there are voids of uncolonized worlds. The correlation length famously scales as  , where
, where 
 scales as
scales as  \propto |p-p_c|^\beta") (
( ) and the mean cluster size (excluding the infinite cluster) scales as
) and the mean cluster size (excluding the infinite cluster) scales as  (
( ).
). = 1-(1-\lambda)^{N|p-p_c|^\gamma}")
 . Above the threshold it is essentially 1; there is a small probability
. Above the threshold it is essentially 1; there is a small probability ") of being inside a small cluster, but it tends to be minuscule. Given the silence in the sky, were a percolation model the situation we should conclude either an extremely low
of being inside a small cluster, but it tends to be minuscule. Given the silence in the sky, were a percolation model the situation we should conclude either an extremely low  , and at the right the rate gets multiplied by the longevity term for civilizations
, and at the right the rate gets multiplied by the longevity term for civilizations  years.
years.}{dt}=N_*(t)f_p(t)n_e(t)f_l(t)f_i(t)f_c(t)-(1/L)N")
") corresponding to the first term, we get an expression for the current state:
corresponding to the first term, we get an expression for the current state: = \int_{t_{bigbang}}^{t_{now}} \beta(t) e^{-(1/L) (t_{now}-t)} dt") .
.![d \approx 0.55 [N_* f_p n_e f_l f_i f_c L / V]^{-1/3}](http://s0.wp.com/latex.php?latex=d+%5Capprox+0.55+%5BN_%2A+f_p+n_e+f_l+f_i+f_c+L+%2F+V%5D%5E%7B-1%2F3%7D&bg=ffffff&fg=000000&s=0 "d \approx 0.55 [N_* f_p n_e f_l f_i f_c L / V]^{-1/3}") , where
, where  is the galactic volume. If we are considering parameters such that the number of civilizations per galaxy are low V needs to be increased and the density will go down significantly (by a factor of about 100), leading to a modest jump in expected distance.
is the galactic volume. If we are considering parameters such that the number of civilizations per galaxy are low V needs to be increased and the density will go down significantly (by a factor of about 100), leading to a modest jump in expected distance. being smaller than the panspermia, presumably at least in the parsec range. This is also the scale of close clusters of stars in percolation models.
being smaller than the panspermia, presumably at least in the parsec range. This is also the scale of close clusters of stars in percolation models.
