I have digital scar tissue.
I have digital scar tissue.
My first email address, nv91-asa@nada.kth.se is still haunting the net. I got it in 1991 when I started at university and it was valid for more than 15 years. During this time, I wrote many documents, websites, and academic papers, ensuring that it will be out there. Of course, it is no longer valid. Indeed, the department NADA has long since changed name to CSC… oh, that has become a different structure, and now CSC refers to a different, now also defunct program. The address is simultaneously dead (non-functional) and immortal (searchable forever).
In 2004 there was an offer of free email with one gigabyte of storage space from Google! I joined in, so my gmail address is actually a googlemail address. Fortunately, Google treats them as synonymous. Unlike my other gmail address, which is now broken.
When I got a Windows update many years ago, it demanded that I set up an account on live.com. Being privacy conscious, I did not use my real name but a name from a villain from a horror story. A few years later my Skype ID had to be merged with that live.com ID. Then I had to use it as my Windows ID. So now my “real” Windows identity is tied to that villain, and people sometimes get confused when I show up in Microsoft Teams with a different name. In a recent online workshop, I could not be moved to the smaller breakout sessions because of my weird status.
Digital Scar Tissue
If you are around long enough you will acquire multiple identities in multiple identity ecosystems. But as we change jobs, leave school, change name (or gender), or are subject to digital misfortunes ranging from lost passwords to identity theft many of these identities become obsolete. Yet much is tied to each of them, and these ties do not go away. In fact, these obsolete ties slowly turn into digital scar tissue.
I cannot use Slack. I have had several different accounts linked to different projects, often set up by people unaware that the email address they know me under is not the identity my browser knows me by – and that it is a very different identity from the professional or private identity I would prefer to handle it. The result after a few years is that I can in practice not use Slack because I cannot find whatever project I just got invited to. Since I find Slack annoying, I am not too interested in untangling the mess: just send me an email. On a working address.
My account for ChatGPT is linked to my previous academic email, which is now removed. Yet OpenAI in their wisdom has made it impossible to change the linked email address, and exporting one’s data can only be done to that address. So much for that account.
By now the Internet is littered with dead identities and references. This is to be expected. What I am concerned about is that we seem to be acquiring digital scar tissue that holds us back: access tied to near-dead or undead identities with access or security problems of their own, forgotten accounts forming attack surfaces, conflations of different people that cannot easily be disentangled, links (whether URLs or social references) pointing into the void or worse, at something else. Every identity or access operation has some probability of causing a problem, and they often interact with each other: slowly but surely problems will crop up. It happens faster if you have a broad and complex online presence, but trust me, given time anybody will get the scar tissue.
Sure, you can just delete all your accounts and start anew. But your old documents and posts are still archived somewhere unless you go to extreme lengths, and others will have dangling references to you. Also, the cost of wiping your online identity is usually too high for most people – it is after all a large part of our social and professional personae.
Much is due to the irreversibility of operations or rules. When two identities have been merged, they cannot be separated. A classic nightmare story about digital and administrative scar tissue is the story about Joseph Tartaro, who got the vanity plate NULL, and suddenly found himself fined for all parking violations where the registration plate was not validly read. He could not change his plate until he paid off the ever-arriving fines, which would mean he accepted the liability.
Why Scar Tissue is Bad
Scar tissue in biology is functionally different tissue from the original that is typically less flexible, sometimes painful, and can restrict movement. Digital scar tissue similarly restricts the “range of motion” online.
Digital systems are designed with an implicit assumption of stable, long-term identities. But human lives operate on a different timescale – we change jobs every few years, institutions reorganize, services pivot. Indeed, humans outlive the majority of companies (typical half-life 20 years). The mismatch accumulates as friction.
Early adopters are particularly vulnerable to this problem. You sign up to a service before it gets its final form, and then your identity gets awkwardly grandfathered in. I had serious problems paying for one important account since I needed 2-factor authentication to log in, but to set up 2FA I needed to log in: I had signed up before that account required 2FA. The process of actually being able to do this frustrated both me and company tech support, who also found that the system they had set up was not flexible enough to budge for this case.
The scar tissue reduces user power and portability. Control over an identity has been ceded to a platform – but often the platform itself has trouble performing operations on a sufficiently awkwardly embedded identity (other than just deleting it and losing a customer). Lack of portability is often a design feature, but it can come back and bite the organisation too.
The scar tissue develops mostly at the interface between systems. Platforms solve identity in isolation, and then link them somewhat ad hoc. This means that there are two platforms (at least), each that can introduce trouble by changing something, as well as potential for the link (a phone number, an email, a name) to be set in error.
The current system has an implicit stability bias. People who change institutions frequently (academics, military families), people who change names (marriage, divorce, gender transition), people in long-term institutional instability (refugees, frequent movers) – they’ll accumulate scar tissue faster.
I suspect younger generations will develop a different kind of scars than me, since their media use involve different devices and media. But my prediction is that over time it will accrue, and it will have similar problems.
My concern is that past a certain threshold of complexity, some people may become effectively locked out of full digital participation not through lack of access, but through accumulated identity problems. Digital exclusion through technical debt.
Remedies
This is a chronic condition rather than a straightforward problem to solve.
It is not something that we can easily get rid of because the causes are too manifold. Like cancer, there are a myriad things that can trigger a digital scar, and each combination is individually rare and special case.
We can design against it if we build software and organisations carefully, but we will likely not have strong incentives all the time so we should not expect it to happen reliably. After all, the cost is externalised to the users for the most part, and users rarely select platforms based on thinking about their long-term effects.
So we need ways of managing it, including the insight that in the long run it is going to accumulate for all of us.
We could think of maintaining a digital identity hygiene approach:
- Identity triage: Deliberately decide which identities are temporary/disposable vs. core/permanent.
- Regular audits: Just as you’d do security reviews, periodic identity reviews – what’s still live, what should be documented before it dies, what attack surface exists?
- Documentation of identity archaeology: Keep a personal “identity map” – not for security, but topology. Where do the identities point? Wat can be migrated? What’s still tied to it?
This at first sounds reasonable and worth doing together with the security hygiene we all should be doing (you are doing it, right?). But the problem is that you cannot control if a service makes use of a disposable identity in an unexpected way that now forces you to retain it, like my live.com user – uncertainty about the future means identity triage is limited. Documenting the identity map is harder than it looks since we are often unaware of many of the links, and documenting it as we are going through our digital lives is an extra, distracting task. Maybe AI assistants can do it… at the price of yet another interface that could create truly creative snarls.
Since individual action alone won’t work, what might help at a higher level?
- Rights to correction: errors or snarls need to be fixable. But while this is sometimes mandated for maintaining legal identities and personal information, many of our identities are lightweight constructs not covered by law. For obsolete identities there may no longer be any responsible organization.
- Identity sunset protocols: Organizations could adopt standards for graceful identity decay. Rather than addresses going immediately dead, a 5-year forwarding period (University of Oxford has a 2 week email forwarding period, since obviously academics do not have long-running communications!). Archives of institutional identity mappings (“this person used to be reachable at X, is now at Y”). But who enforces them?
- Federated identity done right: OAuth/SSO was supposed to help, but it often just concentrates the problem into single points of failure. The ORCID system tries to be this for academic identities, overcoming the classic headache for academics undergoing name or gender changes risking losing their citation record – but their adoption is partial. What if we had better protocols for identity succession and equivalence?
- The right to digital death or reincarnation: Privacy regulations focus on deletion rights, but what about the right to cleanly sunset an identity? Not just delete data, but establish canonical “this identity is superseded by that one” records.
These ideas are in principle actionable, but the incentive structure to implement them is weak. Platforms benefit from lock-in, organizations face immediate costs for long-term benefits, and individual users cannot coordinate to demand change.
Hence we – people interested in having digital longevity and health – need to investigate how to make incentives stronger and more pervasive for any organization or individual managing identities. This is not a simple problem: it requires understanding how to create coordination where market forces, individual choice and political interest fail. We don’t yet know how to change these incentives at scale. But identifying this as the upstream intervention point may be more valuable than proposing solutions that no one has reason to implement.
Digital scar tissue will continue to accumulate. The question is whether we’ll develop the social technologies to manage it before it begins to seriously impair our collective digital function.
Anders Sandberg,
nv91-asa@nada.kth.se
anders.sandberg@philosophy.ox.ac.uk
https://plus.google.com/114063364176861557136





") that maps states and action pairs to a probability of acting that way; this is set using a value function
that maps states and action pairs to a probability of acting that way; this is set using a value function ") where various states are assigned values. Morality in my sense is just the policy function and maybe the value function: they have been learned through interacting with the world in various ways.
where various states are assigned values. Morality in my sense is just the policy function and maybe the value function: they have been learned through interacting with the world in various ways.
 distributed as
distributed as ") . The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value
. The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value ![V=E[x]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x]-1") . Suppose a cursory investigation costing much less gives some indication about
. Suppose a cursory investigation costing much less gives some indication about  . One approach is to select all items above a threshold
. One approach is to select all items above a threshold  , making
, making ![V=E[x_i|y_i<\theta]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx_i%7Cy_i%3C%5Ctheta%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x_i|y_i<\theta]-1") .
., \epsilon \sim N(0,\sigma_\epsilon^2)") , then
, then  \Phi\left(\frac{t-\mu_x}{\sqrt{\sigma_x^2+\sigma_\epsilon^2}}\right)dt") . While one can ram through this using
. While one can ram through this using  (the correlation between x and y is 0.707, so this is not too much noise):
(the correlation between x and y is 0.707, so this is not too much noise):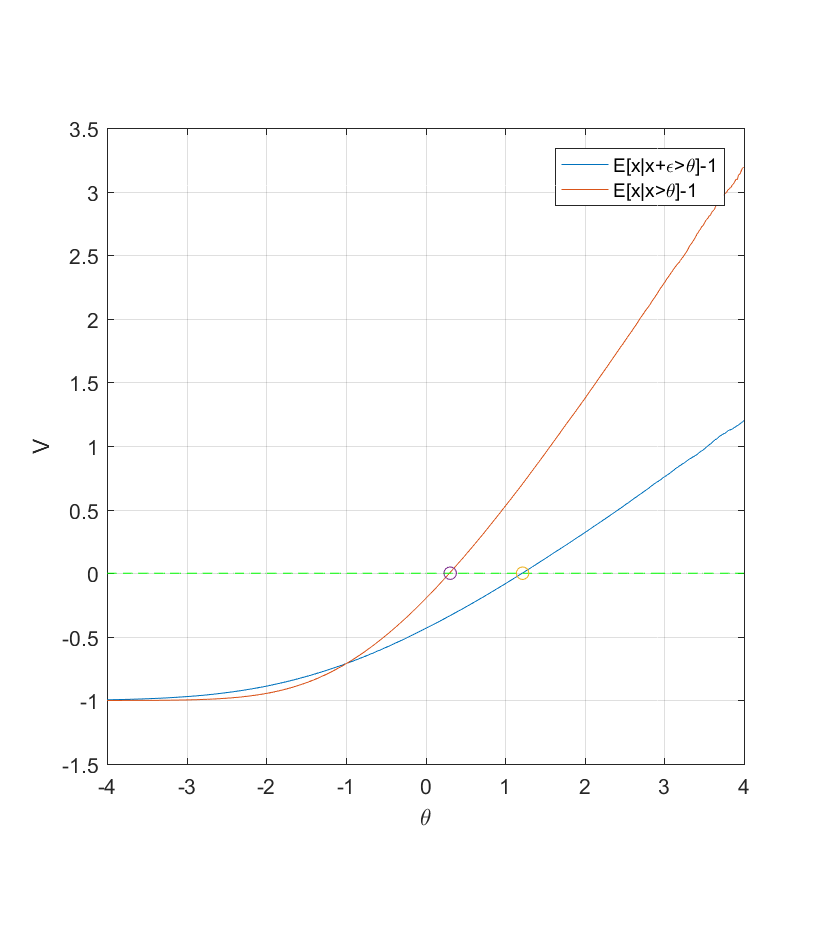
 random samples, the posterior distribution of
random samples, the posterior distribution of  , the number of pages, is
, the number of pages, is  = P(k|N)P(N)/P(k)") .
. , on my third try
, on my third try  , and so on:
, and so on: =(k-1)/N") . Of course, there has to be more pages than
. Of course, there has to be more pages than  , otherwise a repeat must have happened before step
, otherwise a repeat must have happened before step  . Otherwise,
. Otherwise, =0") for
for  .
.") needs to be decided. One approach is to assume that websites have
needs to be decided. One approach is to assume that websites have  = N^{-\alpha}/\zeta(\alpha)") . Note the appearance of the Riemann zeta function as a normalisation factor.
. Note the appearance of the Riemann zeta function as a normalisation factor.") by summing over the different possible
by summing over the different possible =\sum_{N=1}^\infty P(k|N)P(N) = \frac{k-1}{\zeta(\alpha)}\sum_{N=k-1}^\infty N^{-(\alpha+1)}")
}(\zeta(\alpha+1)-\sum_{i=1}^{k-2}i^{-(\alpha+1)})") .
.=N^{-(\alpha+1)}/(\zeta(\alpha+1) -\sum_{i=1}^{k-2}i^{-(\alpha+1)})") for
for  . The posterior distribution of number of pages is another power-law. Note that the dependency on
. The posterior distribution of number of pages is another power-law. Note that the dependency on =\sum_{N=1}^\infty N P(N|k) = \sum_{N=k-1}^\infty N^{-\alpha}/(\zeta(\alpha+1) -\sum_{i=1}^{k-2}i^{-(\alpha+1)})")
-\sum_{i=1}^{k-2} i^{-\alpha}}{\zeta(\alpha+1)-\sum_{i=1}^{k-2}i^{-(\alpha+1)}}") . The expectation is the ratio of the zeta functions of
. The expectation is the ratio of the zeta functions of  and
and  , minus the first
, minus the first  terms of their series.
terms of their series.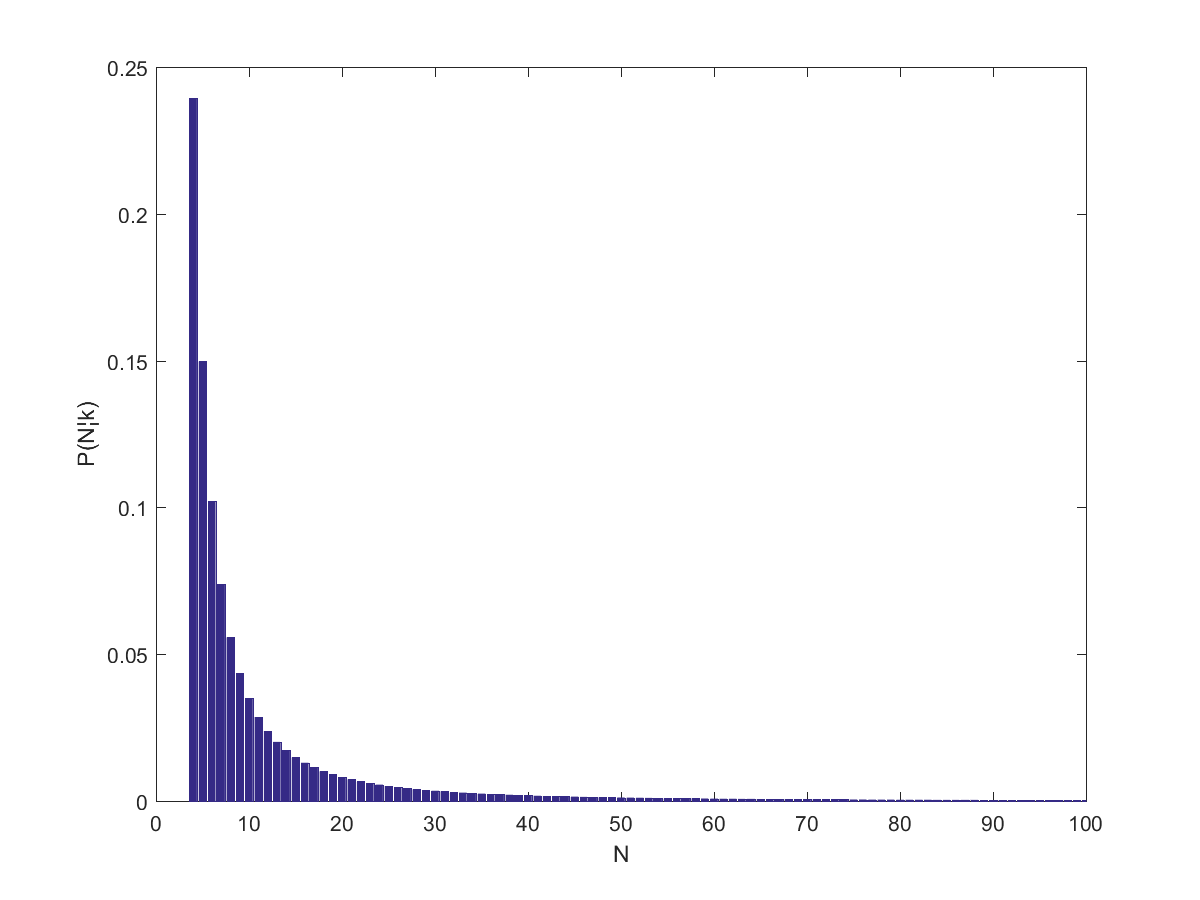
 (close to the behavior of big websites), it predicts
(close to the behavior of big websites), it predicts \approx 21.28") . If one assumes a higher
. If one assumes a higher  the number of pages would be 7 (which was close to the size of the wiki when I looked at it last night – it has grown enough today for k to equal 13 when I tried it today).
the number of pages would be 7 (which was close to the size of the wiki when I looked at it last night – it has grown enough today for k to equal 13 when I tried it today).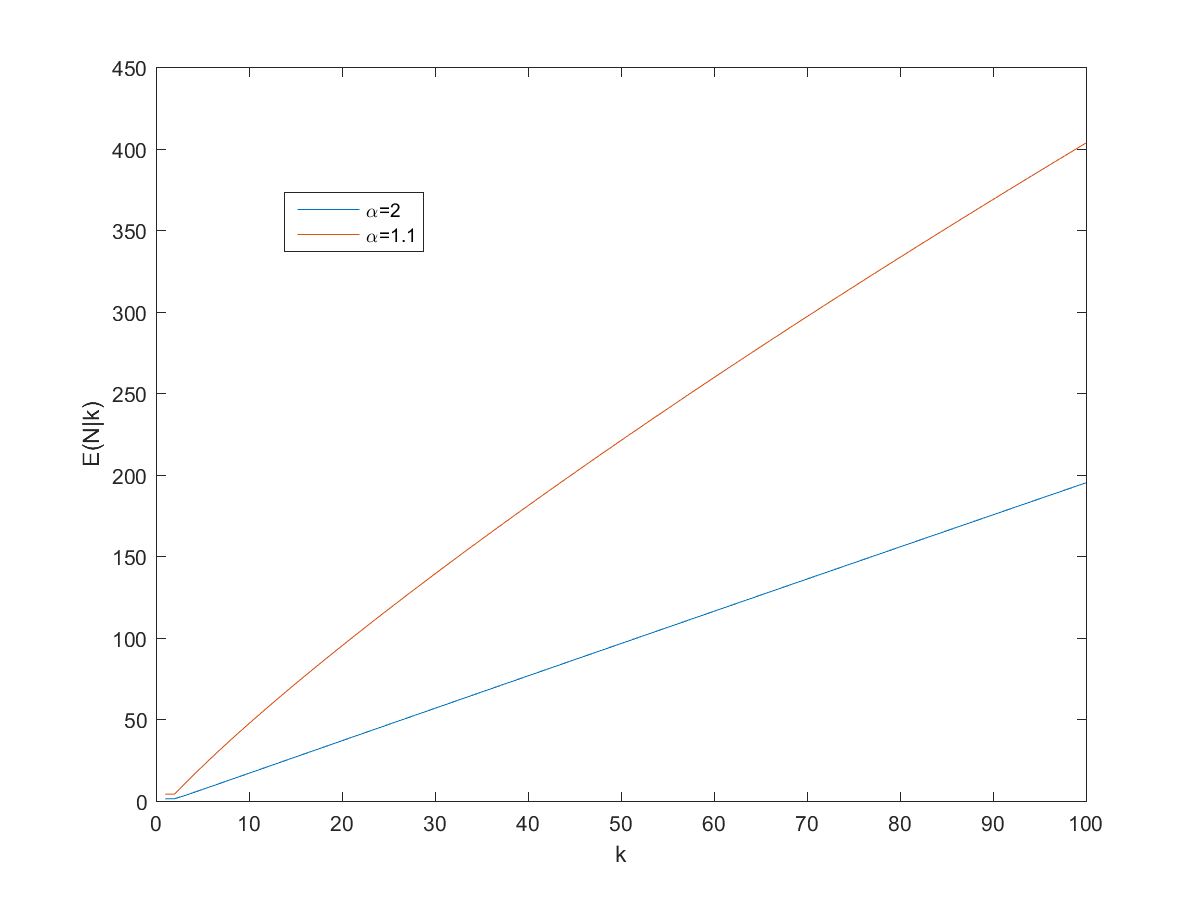
") approaches proportionality, especially for larger
approaches proportionality, especially for larger 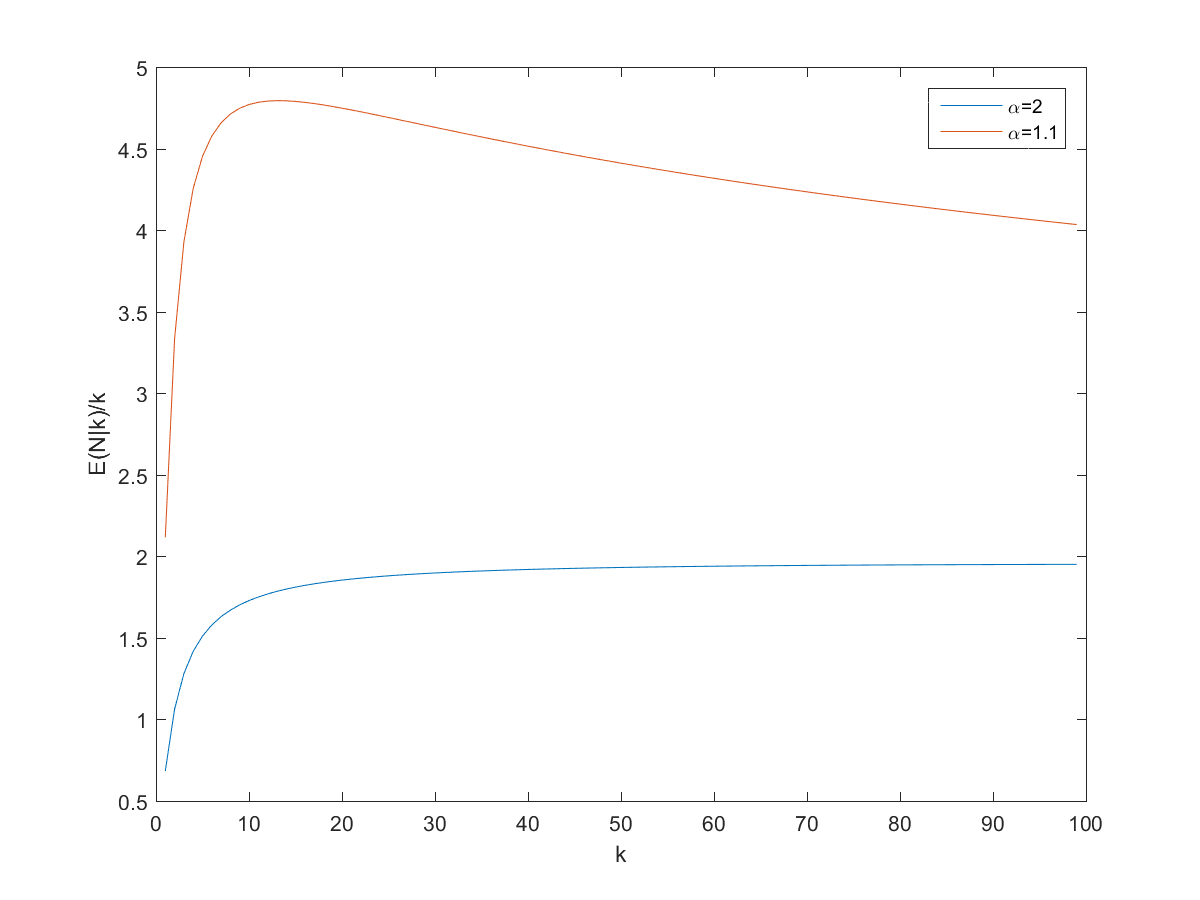
 and
and  pages on the site. However, remember that we are dealing with power-laws, so the variance can be surprisingly high.
pages on the site. However, remember that we are dealing with power-laws, so the variance can be surprisingly high.