What are the weirdest probability distributions I have encountered? Probably the fractal synaptic distribution.
There is no shortage of probability distributions: over any measurable space you can define some function that sums to 1, and you have a probability distribution. Since the underlying space can be integers, rational numbers, real numbers, complex numbers, vectors, tensors, computer programs, or whatever, and the set of functions tends to be big (the power set of the underlying space) there is a lot of stuff out there.
In normal life I tend to encounter the usual distributions: uniform, Bernouilli, Beta, Gaussians, lognormal, exponential, Weibull (because of survival curves), Erlang (because of sums of exponentials), and a lot of power-laws because I am interested in extreme things.
The first “weird” distribution I encountered was the Chauchy distribution. It has a nice algebraic form, a suggestive normalization constant… and no mean, variance or higher order moments. I remember being very surprised as a student when I saw that. It was there on the paper, with a very obvious centre point, yet that centre was not the mean. Like most “pathological examples” it was of course a representative of the majority: having a mean is actually quite “rare”. These days, playing with power-laws, I am used to this and indeed find it practically important. It is no longer weird.
The Planck distribution isn’t too unusual, but has links to many cool special functions and is of course deeply important in physics. It is still surprisingly obscure as a mathematical probability distribution.
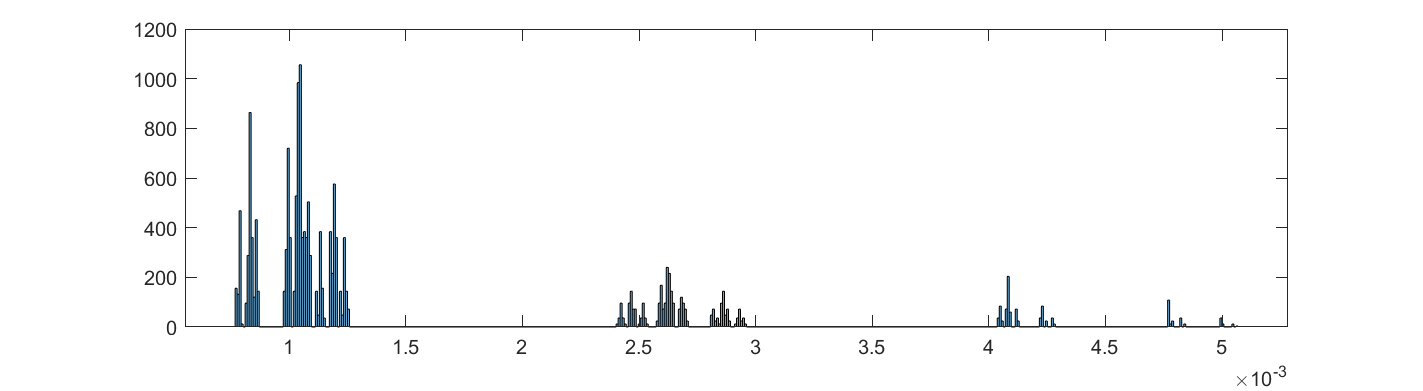
The weirdest distribution I have actually used (if only for a forgotten student report) is a fractal.
As a computational neuroscience student I looked into the distribution of synaptic weights in a forgetful attractor memory similar to the Hopfield network. In this case each weight would be updated with a +1 or -1 each time something was learned, added to the previous weight that had decayed somewhat: If there is no decay, k=1, the weights will gradually become a (discrete) Gaussian. For k=0 this is just the Bernouilli distribution.
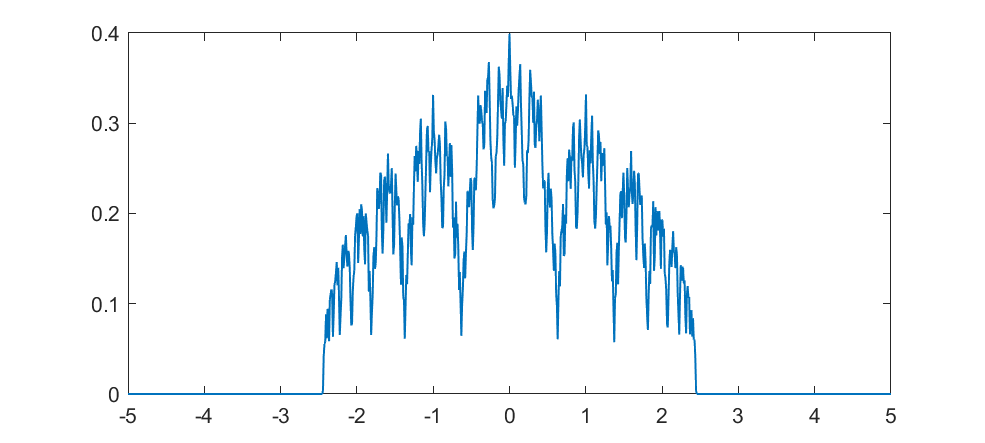
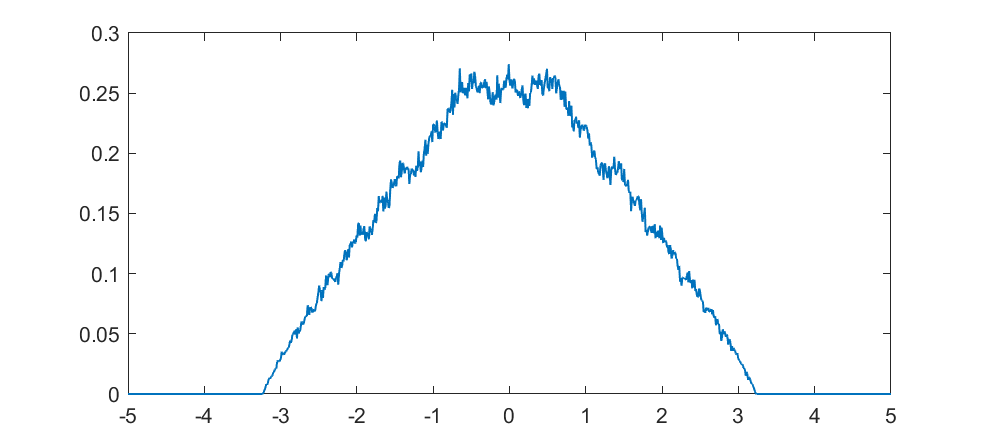
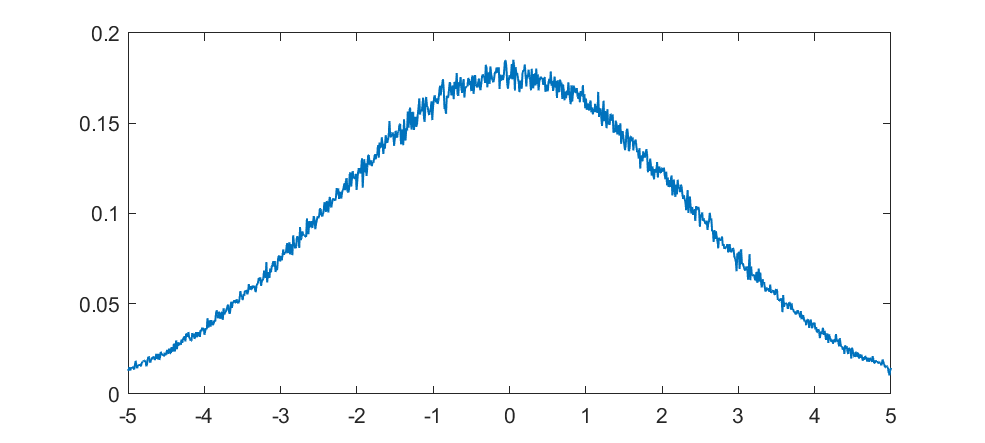
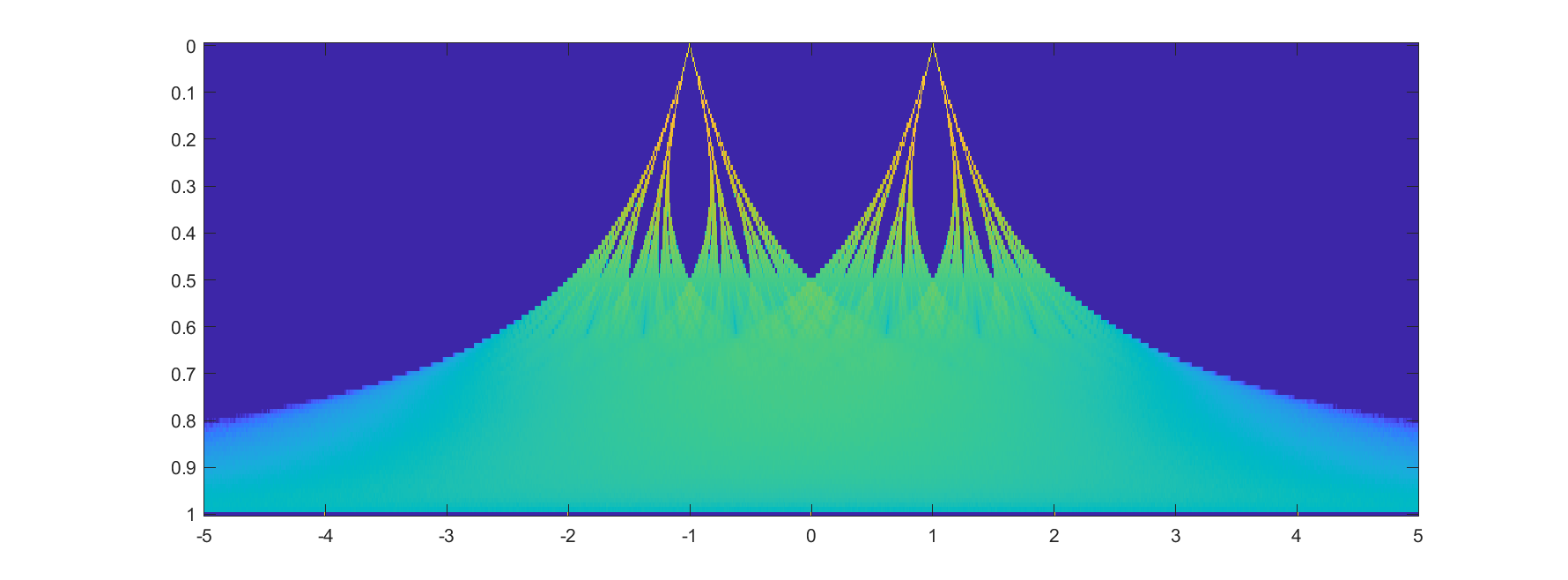
But what about intermediate cases? The update is basically mixing together two copies of the whole distribution. For small k, this produces a distribution across a Cantor set. As k increases the set gets thicker (that is, the fractal dimension increases towards 1), and at k=1/2 you get a uniform distribution. Indeed, it is a strange but true fact that you can not make a uniform distribution over the rational numbers in [0,1] but if we take an infinite sum obviously every single binary sequence will be possible and have equal probability, so it is the real number uniform distribution. Distributions and random numbers on the rationals are funny, since they are both discrete in the sense of being countable, yet so dense that most intuitions from discrete distributions fail and one tends to get fractal/recursive structures.
The real fun starts for k>1/2 since now peaks emerge on top of the uniform background. They happen because the two copies of the distribution blended together partially overlap, producing a recursive structure where there is a smaller peak between each pair of big peaks. This gets thicker and thicker, starting to look like a Weierstrass function curve and then eventually a Gaussian.
Plotting it in the (x,k) plane shows a neat overall structure, going from the Cantor sets to the fractal distributions towards the Gaussian (and, on the last k=1 row, the discrete Gaussian). The curves defining the edge of the distribution behave as , shooting off towards infinity as k approaches 1.
In practice, this distribution is unlikely to matter (real brains are too noisy and synapses do not work like that) but that doesn’t stop it from being neat.
I immediately tweeted one approach: take a d8 (octahedron), and subdivide each triangle recursively into 4 equal ones, projecting out to a sphere seven times. Then take the dual (vertices to faces, faces to vertices). The subdivision generates triangular faces. Each face has 3 vertices, shared between 6 faces, so the total number of vertices is 65536, and they become faces of my die.
This is wrong, as Greg Egan himself pointed out. (Note to self: never do math after midnight)
Euler’s formula states that Since each face on the subdivided d8 has three edges, shared by two sides . So . With I get … two vertices too much, which means that after dualization I end up with a d65538 intead of a d65536!
This is of course hilariously cursed. It will look almost perfect, but very rarely give numbers outside the expected range.
(What went wrong? My above argument ignored that some vertices – the original polyhedron corners – are different from others.)
Tim Freeman suggested an eminently reasonable approach: start with a tetrahedron, subdivide triangles 7 times with projection outwards, and you end up with a d65536. With triangular sides rather than the mostly hexagonal ones in the cartoon.
The curse of unfairness
But it gets better: when you subdivide a triangle the new vertices are projected out to the surrounding sphere. But that doesn’t mean the four new triangles have the same area. So the areas of the faces are uneven, and we have an unfair die.
Coloring the sides by relative area shows the fractal pattern of areas.
Plotting a histogram of areas show the fractal unevenness. The biggest face has 6.56 times area of the smallest face, so it is not a neglible bias.
Note that dice with different face areas can also be fair. Imagine a n-sided prism with length . If the probability of landing on one of the end polygons while for each of the sides it is (and by symmetry they are all equal). If then the probability instead approaches 1 and the side probability approaches 0. So by continuity, in between there must be a where the probability of landing on one of the ends equals the probability of landing on one of the sides. There is no reason for the areas to be equal.
Dice that are fair by symmetry (and hence under any reasonable throwing dynamics) always have to have an even number of sides and belong to certain symmetry groups (Diaconis & Keller 1989).
The maybe-curse of the d(65536!)
A cool way to handle an unfair die is if the assignment of the numbers to the faces are completely scrambled between each roll. It does not matter how uneven the probabilities are, since after being scrambled once the probability of any number being on the most likely face will be the same.
How do you scramble fairly? The obvious approach is a gigantic d(65536!) die, marked with every possible permutation of the faces. This has sides.
But the previous problems give the nagging question: what if it is unfair?
We can of course scramble the d(65536!) with a d(65536!)! die. If that is fair, then things become fair. But what if we lack such a tremendous die, or there are no big dies that are fair?
Clearly a very unfair d(65536!) can prevent fair d65536-rolling. Imagine that the face with the unit permutation (leave all faces unchanged) has probability 1: the unfairness of the d65536 will remain. If the big die instead has probability close but not exactly 1 for the unit permutation then occasionally it will scramble faces. It could hence make the smaller die fair over long periods (but short-term it would tend to have the same bias towards some faces)… unless the other dominant faces on the d(65536!) were permutations that just moved faces with the same area to each other.
A nearly fair d(65536!) die will on the other hand scramble so that all permutation have some chance of happening, over time allowing the d65536 state to explore the full space of possibility (ergodic dynamics). This seems to be the generic case, with the unfairness-preserving dice as a peculiar special case. In general we should suspect that the typical behavior of mixing occurs: the first few permutations do not change the unfairness much, but after some (usually low) number of permutations the outcomes become very close to the uniform distribution. Hence rolling the d(65536!) die a few times between each roll of the d65536 die and permuting its face numbering accordingly will make it nearly perfectly uniform, assuming the available permutations are irreducible and aperiodic, and that we make enough extra rolls.
How many extra rolls are needed? Suppose all possible permutations are available on the d(65536!) die with nonzero probability. We want to know how many samples from it are needed to make their concatenation nearly uniformly distributed over the 65536! possible ones. If we are lucky the dynamics of the big die creates “rapid mixing dynamics” where this happens after a polynomial times a logarithm steps. Typically the time scales as where is the second largest eigenvalue of the transition matrix. In our case of subdividing the d4, the quite fast as we subdivide, making the effect of a big die of this type rapidly mixing. We likely only need a handful of rolls of the d(65536!) to scramble the d65536 enough to regard it as essentially fair.
But, the curse strikes again: we likely need another subdivision scheme to make the d(65536!) die than the d65536 die – this is just a plausibility result, not a proof.
Anyway, XKCD is right that it is hard to get the random bits for cryptography. I suggest flipping coins instead.
In a discussion Dennis Pamlin suggested that one could make a mortality table/survival curve for our species subject to existential risk, just as one can do for individuals. This also allows demonstrations of how changes in risk affect the expected future lifespan. This post is a small internal FHI paper I did just playing around with survivorship curves and other tools of survival analysis to see what they add to considerations of existential risk. The outcome was more qualitative than quantitative: I do not think we know enough to make a sensible mortality table. But it does tell us a few useful things:
We should try to reduce ongoing “state risks” as early as possible
Discrete “transition risks” that do not affect state risks matters less; we may want to put them off indefinitely.
Indefinite survival is possible if we make hazard decrease fast enough.
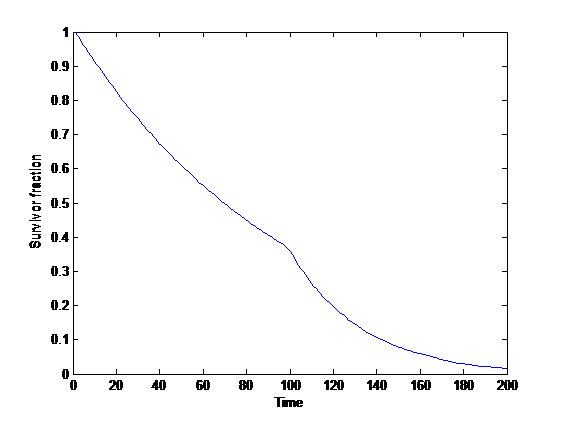
Simple model
Survivorship curve with constant risk.
A first, very simple model: assume a fixed population and power-law sized disasters that randomly kill a number of people proportional to their size every unit of time (if there are survivors, then they repopulate until next timestep). Then the expected survival curve is an exponential decay.
This is in fact independent of the distribution, and just depends on the chance of exceedance. If disasters happen at a rate and the probability of extinction , then the curve is
This can be viewed as a simple model of state risks, the ongoing background of risk to our species from e.g. asteroids and supernovas.
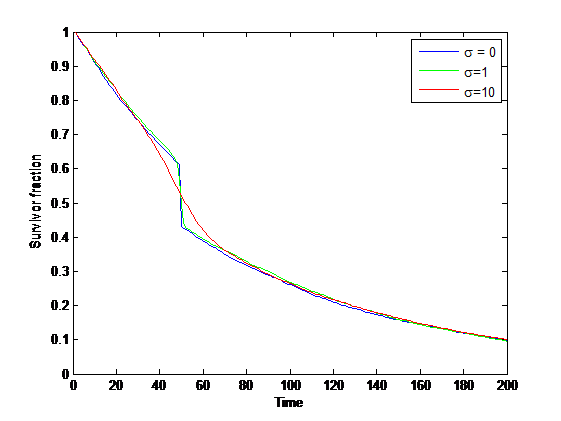
Correlations
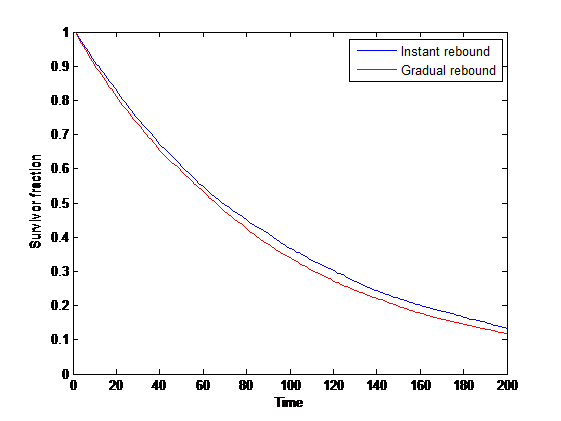
Survivorship curve with gradual rebound from disasters.
What if the population rebound is slower than the typical inter-disaster interval? During the rebound the population is more vulnerable to smaller disasters. However, if we average over longer time than the rebound time constant we end up with the same situation as before: an adjusted, slightly higher hazard, but still an exponential.
In ecology there has been a fair number of papers analyzing how correlated environmental noise affects extinction probability, generally concluding that correlated (“red”) noise is bad (e.g. (Ripa and Lundberg 1996), (Ovaskainen and Meerson 2010)) since the adverse conditions can be longer than the rebound time.
If events behave in a sufficiently correlated manner, then the basic survival curve may be misleading since it only shows the mean ensemble effect rather than the tail risks. Human societies are also highly path dependent over long timescales: our responses can create long memory effects, both positive and negative, and this can affect the risk autocorrelation.
Population growth
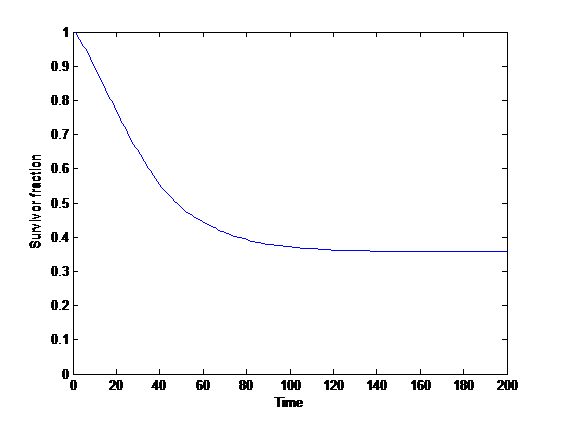
Survivorship curve with population increase.
If population increases exponentially at a rate and is reduced by disasters, then initially some instances will be wiped out, but many realizations achieve takeoff where they grow essentially forever. As the population becomes larger, risk declines as
This is somewhat similar to Stuart’s and my paper on indefinite survival using backups: when we grow fast enough there is a finite chance of surviving indefinitely. The growth may be in terms of individuals (making humanity more resilient to larger and larger disasters), or in terms of independent groups (making humanity more resilient to disasters affecting a location). If risks change in size in proportion to population or occur in different locations in a correlated manner this basic analysis may not apply.
General cases
Survivorship curve with increased state risk.
Overall, if there is a constant rate of risk, then we should expect exponential survival curves. If the rate grows or declines as a power of time, we get a Weibull distribution of time to extinction, which has a “stretched exponential” survival curve:
If we think of risk increasing from some original level to a new higher level, then the survival curve will essentially be piece-wise exponential with a more or less softly interpolating “knee”.
Transition risks
Survivorship curve with transition risk.
A transition risk is essentially an impulse of hazard. We can treat it as a Dirac delta function with some weight at a certain time , in which case it just reduces the survival curve so . If is randomly distributed it produces a softer decline, but with the same magnitude.
Rectangular survival curves
Human individual survival curves are rectangularish because of exponentially increasing hazard plus some constant hazard (the Gompertz-Makeham law of mortality). The increasing hazard is due to ageing: old people are more vulnerable than young people.
Do we have any reason to believe a similar increasing hazard for humanity? Considering the invention of new dangerous technologies as adding more state risk we should expect at least enough of an increase to get a more convex shape of the survival curve in the present era, possibly with transition risk steps added in the future. This was counteracted by the exponential growth of human population until recently.
How do species survival curves look in nature?
There is “van Valen’s law of extinction” claiming the normal extinction rate remains constant at least within families, finding exponential survivorship curves (van Valen 1973). It is worth noting that the extinction rate is different for different ecological niches and types of organisms.
However, fits with Weibull distributions seem to work better for Cenozoic foraminifera than exponentials (Arnold, Parker and Hansard 1995), suggesting the probability of extinction increases with species age. The difference in shape is however relatively small (k≈1.2), making the probability increase from 0.08/Myr at 1 Myr to 0.17/Myr at 40 Myr. Other data hint at slightly slowing extinction rates for marine plankton (Cermeno 2011).
In practice there are problems associated with speciation and time-varying extinction rates, not to mention biased data (Pease 1988). In the end, the best we can say at present appears to be that natural species survival is roughly exponentially distributed.
Conclusions for xrisk research
Survival curves contain a lot of useful information. The median lifespan is easy to read off by checking the intersection with the 50% survival line. The life expectancy is the area under the curve.
Survivorship curve with changed constant risk, semilog plot.
In a semilog-diagram an exponentially declining survival probability is a line with negative slope. The slope is set by the hazard rate. Changes in hazard rate makes the line a series of segments. An early reduction in hazard (i.e. the line slope becomes flatter) clearly improves the outlook at a later time more than a later equal improvement: to have a better effect the late improvement needs to reduce hazard significantly more.
A transition risk causes a vertical displacement of the line (or curve) downwards: the weight determines the distance. From a given future time, it does not matter when the transition risk occurs as long as the subsequent hazard rate is not dependent on it. If the weight changes depending on when it occurs (hardware overhang, technology ordering, population) then the position does matter. If there is a risky transition that reduces state risk we should want it earlier if it does not become worse.
Acknowledgments
Thanks to Toby Ord for pointing out a mistake in an earlier version.
Appendix: survival analysis
The main object of interest is the survival function where is a random variable denoting the time of death. In engineering it is commonly called reliability function. It is declining over time, and will approach zero unless indefinite survival is possible with a finite probability.
The event density denotes the rate of death per unit time.
The hazard function is the event rate at time conditional on survival until time or later. It is . Note that unlike the event density function this does not have to decline as the number of survivors gets low: this is the overall force of mortality at a given time.
The expected future lifetime given survival to time is Note that for exponential survival curves (i.e. constant hazard) it remains constant.
Robin Hanson mentions that some people take him to task for working on one scenario (WBE) that might not be the most likely future scenario (“standard AI”); he responds by noting that there are perhaps 100 times more people working on standard AI than WBE scenarios, yet the probability of AI is likely not a hundred times higher than WBE. He also notes that there is a tendency for thinkers to clump onto a few popular scenarios or issues. However:
In addition, due to diminishing returns, intellectual attention to future scenarios should probably be spread out more evenly than are probabilities. The first efforts to study each scenario can pick the low hanging fruit to make faster progress. In contrast, after many have worked on a scenario for a while there is less value to be gained from the next marginal effort on that scenario.
This is very similar to my own thinking about research effort. Should we focus on things that are likely to pan out, or explore a lot of possibilities just in case one of the less obvious cases happens? Given that early progress is quick and easy, we can often get a noticeable fraction of whatever utility the topic has by just a quick dip. The effective altruist heuristic of looking at neglected fields also is based on this intuition.
A model
But under what conditions does this actually work? Here is a simple model:
There are possible scenarios, one of which () will come about. They have probability . We allocate a unit budget of effort to the scenarios: . For the scenario that comes about, we get utility (diminishing returns).
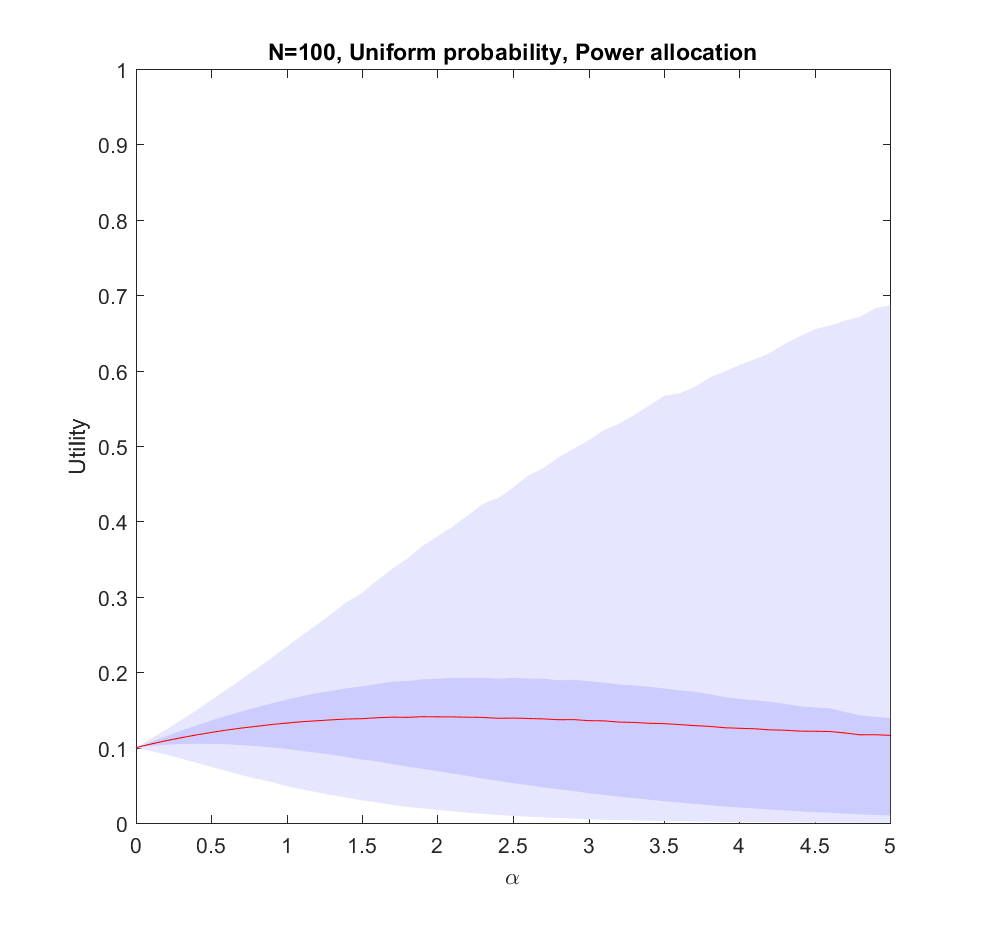
Here is what happens if we allocate proportional to a power of the scenarios, . corresponds to even allocation, 1 proportional to the likelihood, >1 to favoring the most likely scenarios. In the following I will run Monte Carlo simulations where the probabilities are randomly generated each instantiation. The outer bluish envelope represents the 95% of the outcomes, the inner ranges from the lower to the upper quartile of the utility gained, and the red line is the expected utility.
Utility of allocating effort as a power of the probability of scenarios. Red line is expected utility, deeper blue envelope is lower and upper quartiles, lighter blue 95% interval.
This is the case: we have two possible scenarios with probability and (where is uniformly distributed in [0,1]). Just allocating evenly gives us utility on average, but if we put in more effort on the more likely case we will get up to 0.8 utility. As we focus more and more on the likely case there is a corresponding increase in variance, since we may guess wrong and lose out. But 75% of the time we will do better than if we just allocated evenly. Still, allocating nearly everything to the most likely case means that one does lose out on a bit of hedging, so the expected utility declines slowly for large .
Utility of allocating effort as a power of the probability of scenarios. Red line is expected utility, deeper blue envelope is lower and upper quartiles, lighter blue 95% interval. 100 possible scenarios, with uniform probability on the simplex.
The case (where the probabilities are allocated based on a flat Dirichlet distribution) behaves similarly, but the expected utility is smaller since it is less likely that we will hit the right scenario.
What is going on?
This doesn’t seem to fit Robin’s or my intuitions at all! The best we can say about uniform allocation is that it doesn’t produce much regret: whatever happens, we will have made some allocation to the possibility. For large N this actually works out better than the directed allocation for a sizable fraction of realizations, but on average we get less utility than betting on the likely choices.
The problem with the model is of course that we actually know the probabilities before making the allocation. In reality, we do not know the likelihood of AI, WBE or alien invasions. We have some information, and we do have priors (like Robin’s view that ), but we are not able to allocate perfectly. A more plausible model would give us probability estimates instead of the actual probabilities.
We know nothing
Let us start by looking at the worst possible case: we do not know what the true probabilities are at all. We can draw estimates from the same distribution – it is just that they are uncorrelated with the true situation, so they are just noise.
Utility of allocating effort as a power of the probability of scenarios, but the probabilities are just random guesses. Red line is expected utility, deeper blue envelope is lower and upper quartiles, lighter blue 95% interval. 100 possible scenarios, with uniform probability on the simplex.
In this case uniform distribution of effort is optimal. Not only does it avoid regret, it has a higher expected utility than trying to focus on a few scenarios (). The larger N is, the less likely it is that we focus on the right scenario since we know nothing. The rationality of ignoring irrelevant information is pretty obvious.
Note that if we have to allocate a minimum effort to each investigated scenario we will be forced to effectively increase our above 0. The above result gives the somewhat optimistic conclusion that the loss of utility compared to an even spread is rather mild: in the uniform case we have a pretty low amount of effort allocated to the winning scenario, so the low chance of being right in the nonuniform case is being balanced by having a slightly higher effort allocation on the selected scenarios. For high there is a tail of rare big “wins” when we hit the right scenario that drags the expected utility upwards, even though in most realizations we bet on the wrong case. This is very much the hedgehog predictor story: ocasionally they have analysed the scenario that comes about in great detail and get intensely lauded, despite looking at the wrong things most of the time.
We know a bit
We can imagine that knowing more should allow us to gradually interpolate between the different results: the more you know, the more you should focus on the likely scenarios.
Optimal alpha as a function of how much information we have about the true probabilities (noise due to Monte Carlo and discrete steps of alpha). N=2 (N=100 looks similar).
If we take the mean of the true probabilities with some randomly drawn probabilities (the “half random” case) the curve looks quite similar to the case where we actually know the probabilities: we get a maximum for . In fact, we can mix in just a bit () of the true probability and get a fairly good guess where to allocate effort (i.e. we allocate effort as where is uncorrelated noise probabilities). The optimal alpha grows roughly linearly with , in this case.
We learn
Adding a bit of realism, we can consider a learning process: after allocating some effort to the different scenarios we get better information about the probabilities, and can now reallocate. A simple model may be that the standard deviation of noise behaves as where is the effort placed in exploring the probability of scenario . So if we begin by allocating uniformly we will have noise at reallocation of the order of . We can set , where is some constant denoting how tough it is to get information. Putting this together with the above result we get . After this exploration, now we use the remaining effort to work on the actual scenarios.
Expected utility as a function of amount of probability-estimating effort (gamma) for C=1 (hard to update probabilities), C=0.1 and C=0.01 (easy to update). N=100.
This is surprisingly inefficient. The reason is that the expected utility declines as and the gain is just the utility difference between the uniform case and optimal , which we know is pretty small. If C is small (i.e. a small amount of effort is enough to figure out the scenario probabilities) there is an optimal nonzero . This optimum decreases as C becomes smaller. If C is large, then the best approach is just to spread efforts evenly.
Conclusions
So, how should we focus? These results suggest that the key issue is knowing how little we know compared to what can be known, and how much effort it would take to know significantly more.
If there is little more that can be discovered about what scenarios are likely, because our state of knowledge is pretty good, the world is very random, or improving knowledge about what will happen will be costly, then we should roll with it and distribute effort either among likely scenarios (when we know them) or spread efforts widely (when we are in ignorance).
If we can acquire significant information about the probabilities of scenarios, then we should do it – but not overdo it. If it is very easy to get information we need to just expend some modest effort and then use the rest to flesh out our scenarios. If it is doable but costly, then we may spend a fair bit of our budget on it. But if it is hard, it is better to go directly on the object level scenario analysis as above. We should not expect the improvement to be enormous.
Here I have used a square root diminishing return model. That drives some of the flatness of the optima: had I used a logarithm function things would have been even flatter, while if the returns diminish more mildly the gains of optimal effort allocation would have been more noticeable. Clearly, understanding the diminishing returns, number of alternatives, and cost of learning probabilities better matters for setting your strategy.
In the case of future studies we know the number of scenarios are very large. We know that the returns to forecasting efforts are strongly diminishing for most kinds of forecasts. We know that extra efforts in reducing uncertainty about scenario probabilities in e.g. climate models also have strongly diminishing returns. Together this suggests that Robin is right, and it is rational to stop clustering too hard on favorite scenarios. Insofar we learn something useful from considering scenarios we should explore as many as feasible.
I recently nerded out about high-energy proton interaction with matter, enjoying reading up on the Bethe equation at the Particle Data Group review and elsewhere. That got me to look around at the PDL website, which is full of awesome stuff – everything from math and physics reviews to data for the most obscure “particles” ever, plus tests of how conserved the conservation laws are.
Historical graph of physical constant estimates from K.A. Olive et al. (Particle Data Group), Chin. Phys. C, 38, 090001 (2014) and 2015 update.
The first thing that strikes the viewer is that they have moved a fair bit, including often being far outside the original error bars. 6 of them have escaped them. That doesn’t look very good for science!
Fortunately, it turns out that these error bars are not 95% confidence intervals (the most common form in many branches of science) but 68.3% confidence intervals (one standard deviation, if things are normal). That means having half of them out of range is entirely reasonable! On the other hand, most researchers don’t understand error bars (original paper), and we should be able to do much better.
Sometimes large changes occur. These usually reflect the introduction of significant new data or the discarding of older data. Older data are discarded in favor of newer data when it is felt that the newer data have smaller systematic errors, or have more checks on systematic errors, or have made corrections unknown at the time of the older experiments, or simply have much smaller errors. Sometimes, the scale factor becomes large near the time at which a large jump takes place, reflecting the uncertainty introduced by the new and inconsistent data. By and large, however, a full scan of our history plots shows a dull progression toward greater precision at central values quite consistent with the first data points shown.
Overall, kudos to PDG for showing the history and making it clearer what is going on! But I do not agree it is a dull progression.
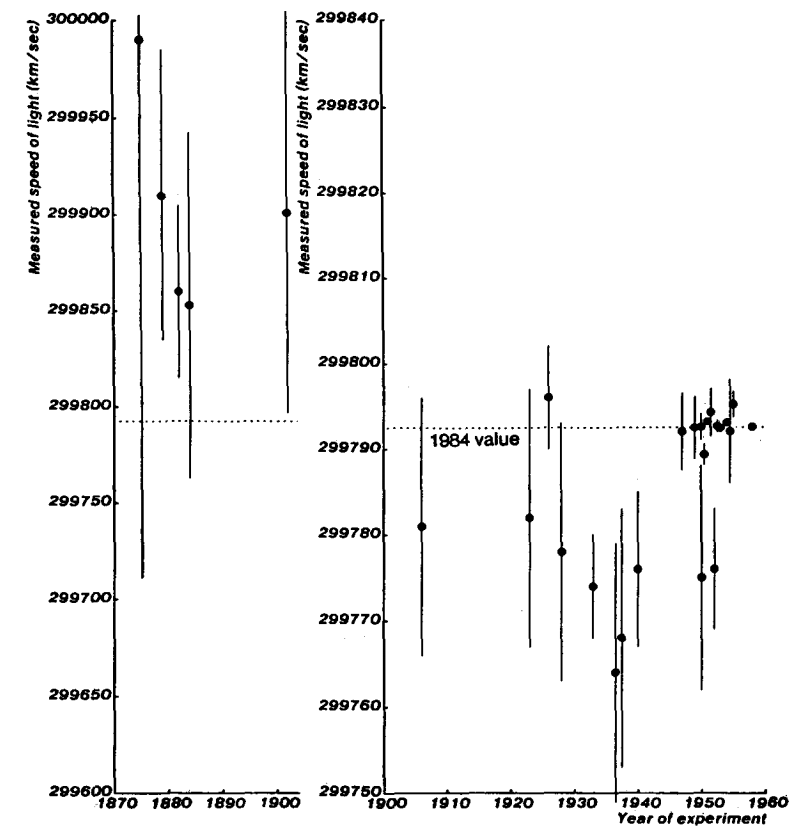
Plot of light-speed measurements 1875-1958. Error bars are standard error. From Max Henrion and Baruch Fischhoff. Assessing uncertainty in physical constants. American Journal of Physics 54, 791 (1986); doi: 10.1119/1.14447.
Note that the shifts were far larger than the estimated error bars. The dip in the 1930s and 40s even made some physicists propose that c could be changing over time. Overall Henrion and Fischhoff find that physicists have been rather overconfident in their tight error bounds on their measurements. The approach towards current estimates is anything but dull, and hides many amusing historical anecdotes.
Stories like this might have been helpful; it is notable that the PDG histories on the right, for newer constants, seem to stay closer to the present value than the longer ones to the left. Maybe this is just because they have not had the time to veer off yet, but one can be hopeful.
Still, even if people are improving this might not mean the conclusions stay stable or approach truth monotonically. A related issue is “negative learning”, where more data and improved models make the consensus view of a topic move in the wrong direction: Oppenheimer, M., O’Neill, B. C., & Webster, M. (2008). Negative learning. Climatic Change, 89(1-2), 155-172. Here the problem is not just that people are overconfident in how certain they can be about their conclusions, but also that there is a bit of group-think, plus that the models change in structure and are affected in different ways by the same data. They point out how estimates of ozone depletion oscillated, or the consensus on the stability of climate has shifted from oscillatory (before 1968) towards instability (68-82), towards stability (82-96), and now towards instability again (96-06). These problems are not due to mere irrationality, but the fact that as we learn more and build better models these incomplete but better models may still deviate strongly from the ground truth because they miss some key component.
Noli fumare
This is related to what Nick Bostrom calls the “data fumes” problem. Early data will be fragmentary and explanations uncertain – but the data points and their patterns are very salient, just as the early models, since there is nothing else. So we begin to anchor on them. Then new data arrives and the models improve… and the old patterns are revealed as statistical noise, or bugs in the simulation or plotting routine. But since we anchored on them, we are unlikely to update as strongly towards the new most likely estimates. Worse, accommodating a new model takes mental work; our status quo bias will be pushing against the update. Even if we do accommodate the new state, things will likely change more – we may well end up either with a view anchored on early noise, or assume that the final state is far more uncertain than it actually is (since we weigh the early jumps strongly because of their saliency).
This is of course why most people prefer to believe a charismatic diet cultleader expert rather than trying to dig through 70 years of messy, conflicting dietary epidemiology.
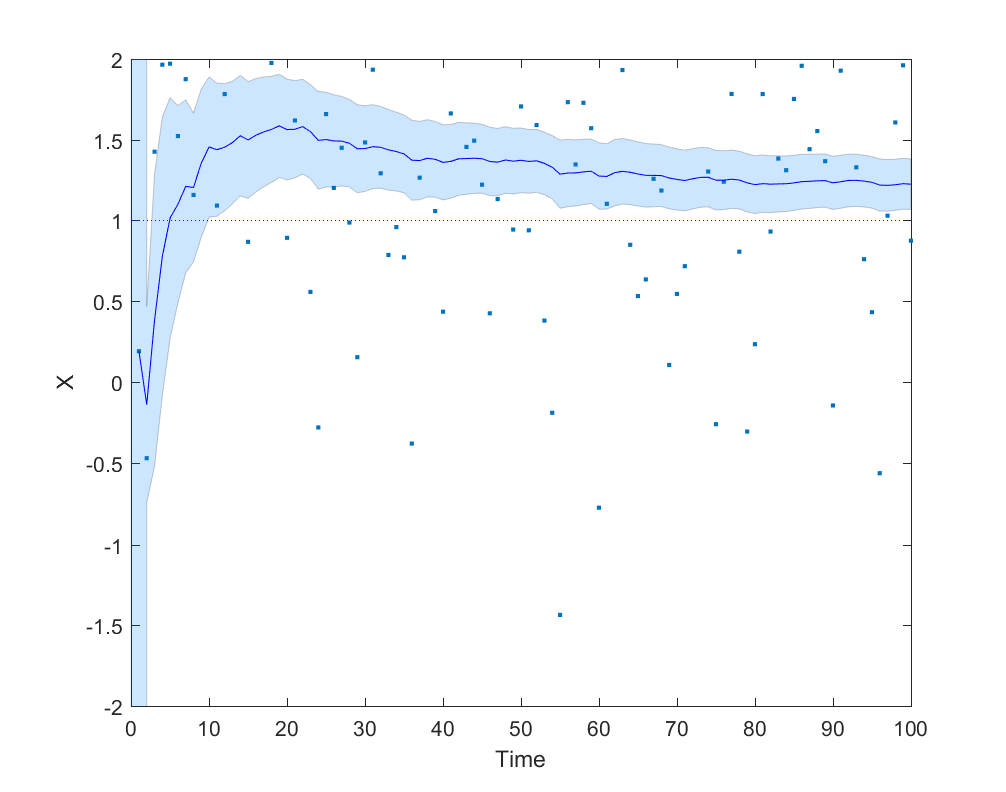
Here is a simple example where an agent is trying to do a maximum likelihood estimation of a Gaussian distribution with mean 1 and variance 1, but is hamstrung by giving double weight to the first 9 data points:
Simple data fume model, showing the slow and biased convergence when the first 9 data points are over-weighted. The blue area is a 95% confidence interval for the mean of the generating Gaussian distribution.
It is not hard to complicate the model with anchoring/recency/status quo bias (estimates get biased towards previous estimates), or that early data points are more polluted by differently distributed noise. Asymmetric error checking (you will look for bugs if results deviate from expectation and hence often find such bugs, but not look for bugs making your results closer to expectation) is another obvious factor for how data fumes can get integrated in models.
The problem with data fumes is that it is not easy to tell when you have stabilized enough to start trusting the data. It is even messier when the inputs are results generated by your own models or code. I like to approach it by using multiple models to guesstimate model error: for example, one mathematical model on paper and one Monte Carlo simulation – if they don’t agree, then I should disregard either answer and keep on improving.
Even when everything seems to be fine there may be a big crucial consideration one has missed. The Turing-Good estimator gives another way of estimating the risk of that: if you have acquired data points and seen big surprises (remember that the first data point counts as one!), then the probability of a new surprise for your next data point is . So if you expect data points in total, when you can start to trust the estimates… assuming surprises are uncorrelated etc. Which you will not be certain about. The progression towards greater precision may be anything but dull.
During my work on the Paris talk I began to wonder whether Paul Erdős (who I used as an example of a respected academic who used cognitive enhancers) could actually have been shown to have benefited from his amphetamine use, which began in 1971 according to Hill (2004). One way of investigating is his publication record: how many papers did he produce per year before or after 1971? Here is a plot, based on Jerrold Grossman’s 2010 bibliography:
Productivity of Paul Erdos over his life. Green dashed line: amphetamine use, red dashed line: death. Crosses mark named concepts.
The green dashed line is the start of amphetamine use, and the red dashed life is the date of death. Yes, there is a fairly significant posthumous tail: old mathematicians never die, they just asymptote towards zero. Overall, the later part is more productive per year than the early part (before 1971 the mean and standard deviation was 14.6±7.5, after 24.4±16.1; a Kruskal-Wallis test rejects that they are the same distribution, p=2.2e-10).
This does not prove anything. After all, his academic network was growing and he moved from topic to topic, so we cannot prove any causal effect of the amphetamine: for all we know, it might have been holding him back.
One possible argument might be that he did not do his best work on amphetamine. To check this, I took the Wikipedia article that lists things named after Erdős, and tried to find years for the discovery/conjecture. These are marked with red crosses in the diagram, slightly jittered. We can see a few clusters that may correspond to creative periods: one in 35-41, one in 46-51, one in 56-60. After 1970 the distribution was more even and sparse. 76% of the most famous results were done before 1971; given that this is 60% of the entire career it does not look that unlikely to be due to chance (a binomial test gives p=0.06).
Again this does not prove anything. Maybe mathematics really is a young man’s game, and we should expect key results early. There may also have been more time to recognize and name results from the earlier career.
In the end, this is merely a statistical anecdote. It does show that one can be a productive, well-renowned (if eccentric) academic while on enhancers for a long time. But given the N=1, firm conclusions or advice are hard to draw.
Erdős’s friends worried about his drug use, and in 1979 Graham bet Erdős $500 that he couldn’t stop taking amphetamines for a month. Erdős accepted, and went cold turkey for a complete month. Erdős’s comment at the end of the month was “You’ve showed me I’m not an addict. But I didn’t get any work done. I’d get up in the morning and stare at a blank piece of paper. I’d have no ideas, just like an ordinary person. You’ve set mathematics back a month.” He then immediately started taking amphetamines again. (Hill 2004)
If I have one piece of advice to give to people, it is that they typically have way more time now than they will ever have in the future. Do not procrastinate, take chances when you see them – you might never have the time to do it later.
One reason is the gradual speeding up of subjective time as we age: one day is less time for a 40 year old than for a 20 year old, and way less than the eon it is to a 5 year old. Another is that there is a finite risk that opportunities will go away (including our own finite lifespans). The main reason is of course the planning fallacy: since we underestimate how long our tasks will take, our lives tend to crowd up. Accepting to give a paper in several months time is easy, since there seems to be a lot of time to do it in between… which mysteriously disappears until you sit there doing an all-nighter. There is also the likely effect that as you grow in skill, reputation and career there will be more demands on your time. All in all, expect your time to grow in preciousness!
Mining my calendar
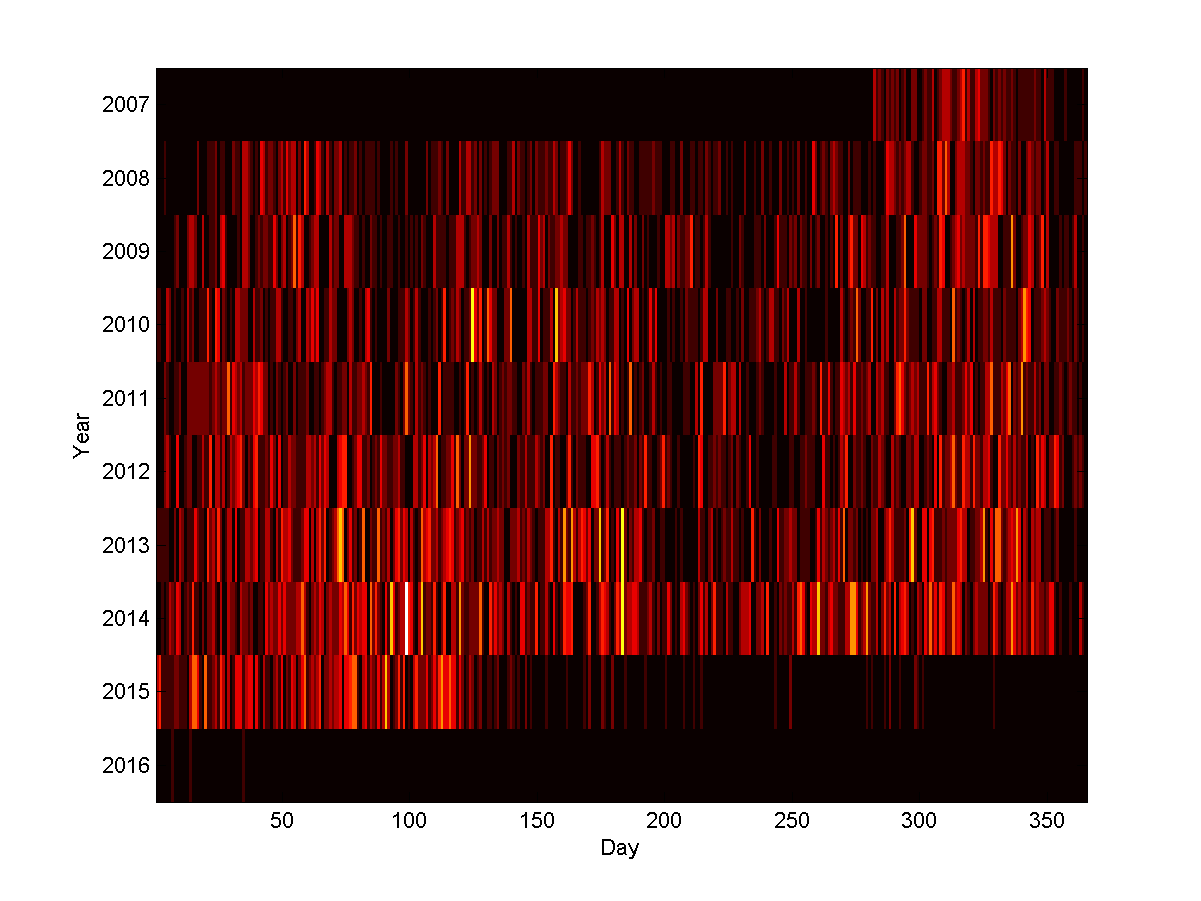
I recently noted that my calendar had filled up several weeks in advance, something I think did not happen to this extent a few years back. A sign of a career taking off, worsening time management, or just bad memory? I decided to do some self-quantification using my Google calendar. I exported the calendar as an .ics file and made a simple parser in Matlab.
Histogram of time distance between scheduling time and actual event.
It is pretty clear from a scatter plot that most entries are for the near future – a few days or weeks ahead. Looking at a histogram shows that most are within a month (a few are in the past – I sometimes use my calendar to note when I have done something like an interview that I may want to remember later).
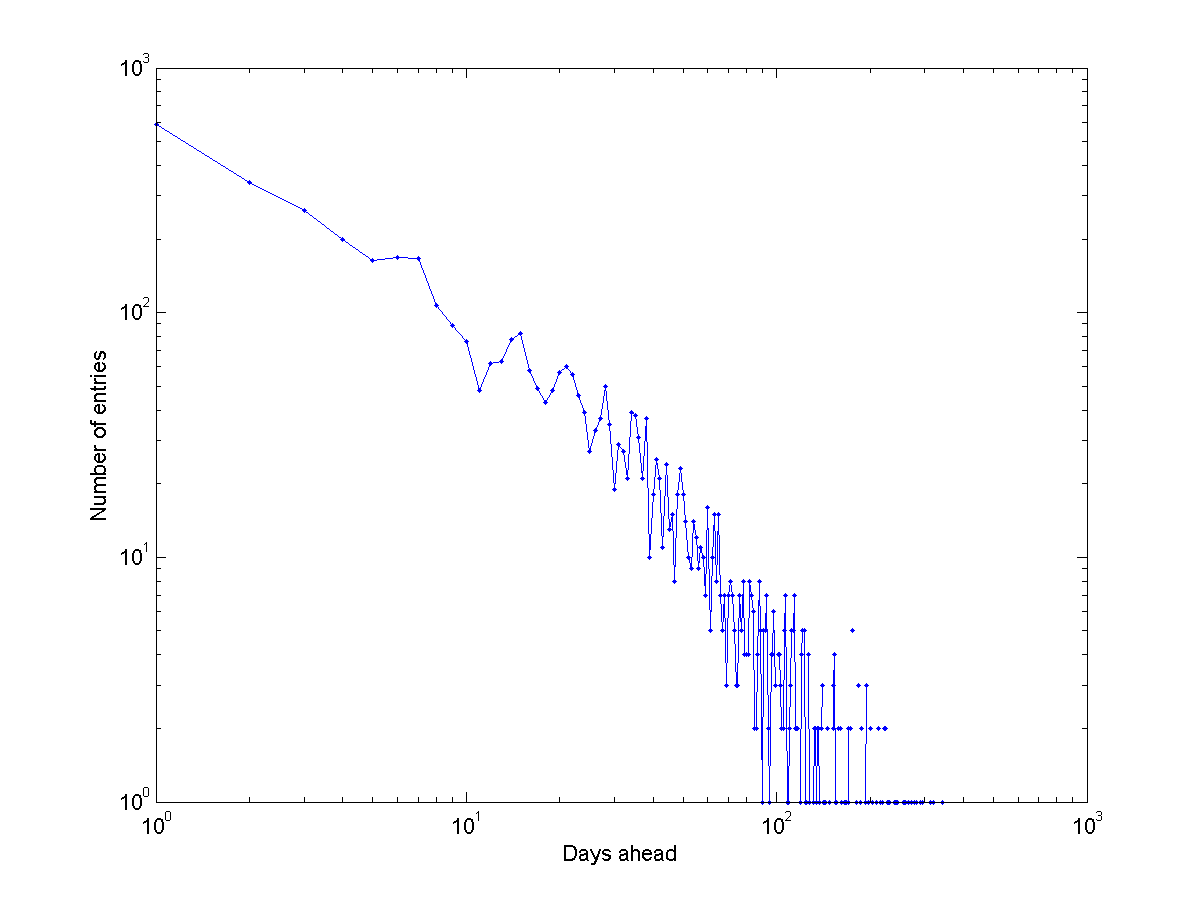
Log-log plot of the histogram of event scheduling intervals.
Plotting it as a log-log diagram suggests it is lighter-tailed than a power-law: there is a characteristic scale. And there are a few wobbles suggesting 1-week, 2-week and 3-week periodicities.
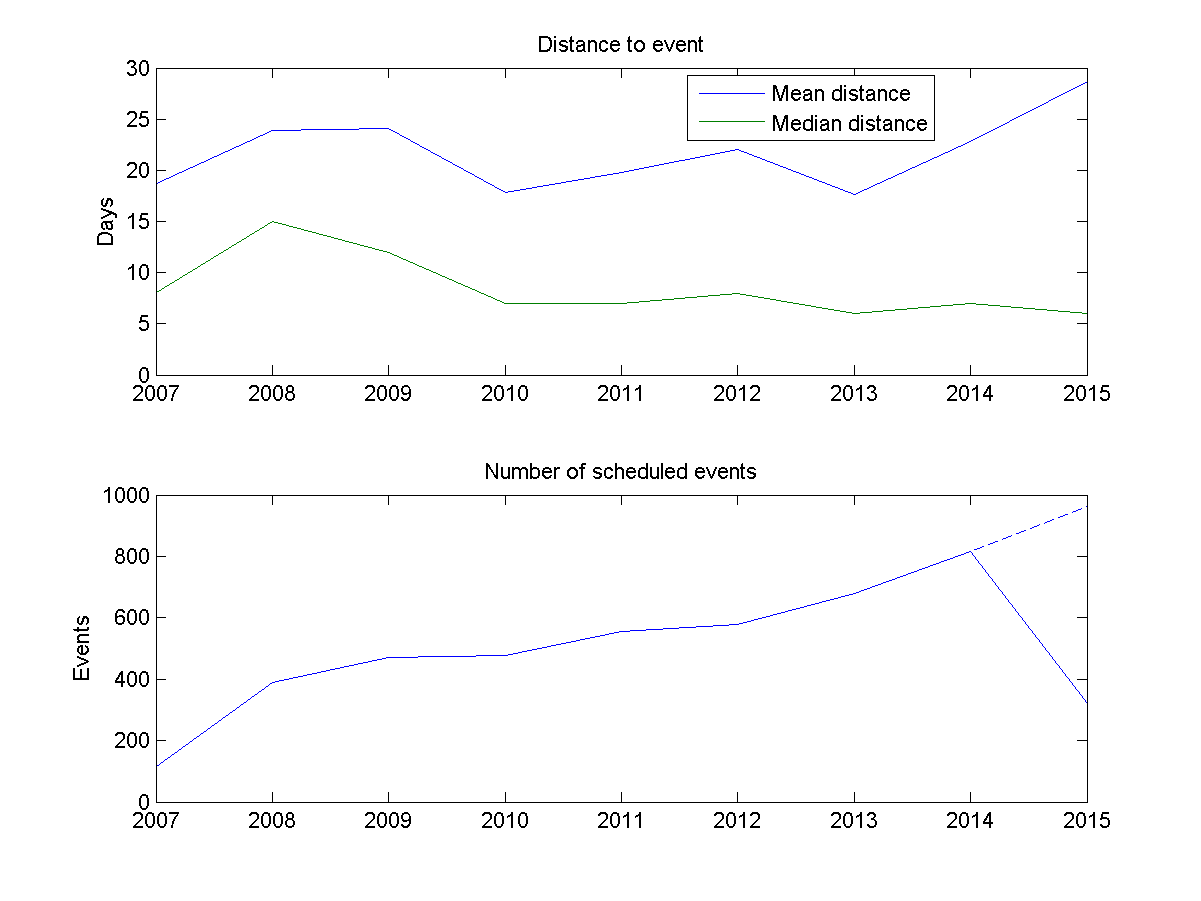
Mean and median distance to newly scheduled events (top), annual number of events scheduled (bottom). The eventual 2015 annual number has been estimated (dashed line).
Am I getting busier? Plotting the mean and median distance to scheduled events, and the number of events per year, suggests yes. The median distance to the things I schedule seems to be creeping downwards, while the number of events per year has clearly doubled from about 400 in 2008 to 800 in 2014 (and extrapolating 2015 suggests about 1000 scheduled events).
Number of calendar events per 14 day period. Red line marks present.
Plotting the number of events I had per 14-day period also suggests that I have way more going on now than a few years ago. The peaks are getting higher and the mean period is more intense.
When am I free?
A good measure of busyness would be the time horizon: how far ahead should you ask me for a meeting if you want to have a high chance of getting it?
One approach would be to look for the probability that a day days ahead is entirely empty. If the probability that I will fill in something days ahead is , then the chance for an empty day is . We can estimate by doing a curve-fit (a second degree curve works well), but we can of course just estimate from the histogram counts: .
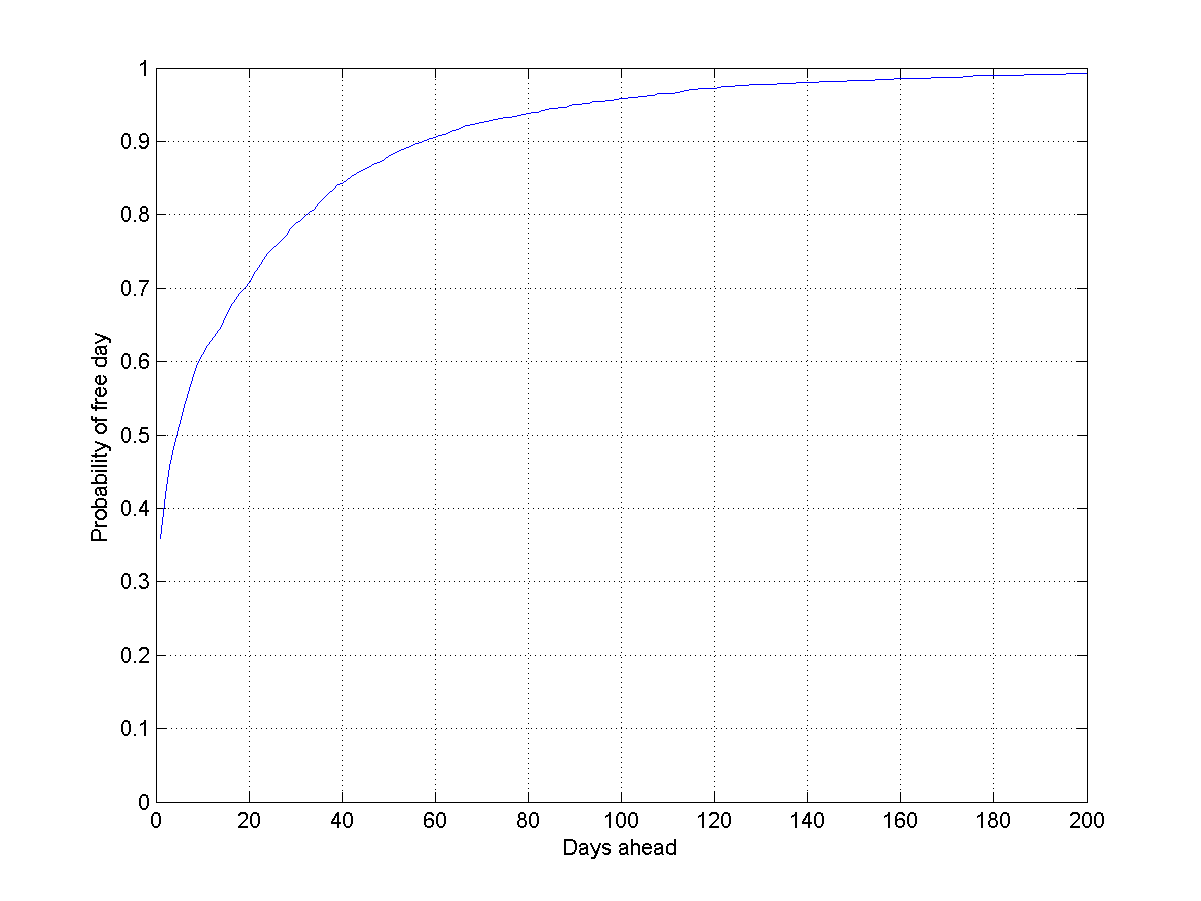
Probability that I will have an entirely free day a certain number of days ahead.
However, this method is slightly wrong. Some days are free, others have many different events. If I schedule twice as many events the chance of a free day should be lower. A better way of estimating is to think in terms of the rate of scheduling. We can view this as a Poisson process, where the rate of scheduling tells us how often I schedule something days ahead. An approximation is , where is the time interval we base our estimate on. This way .
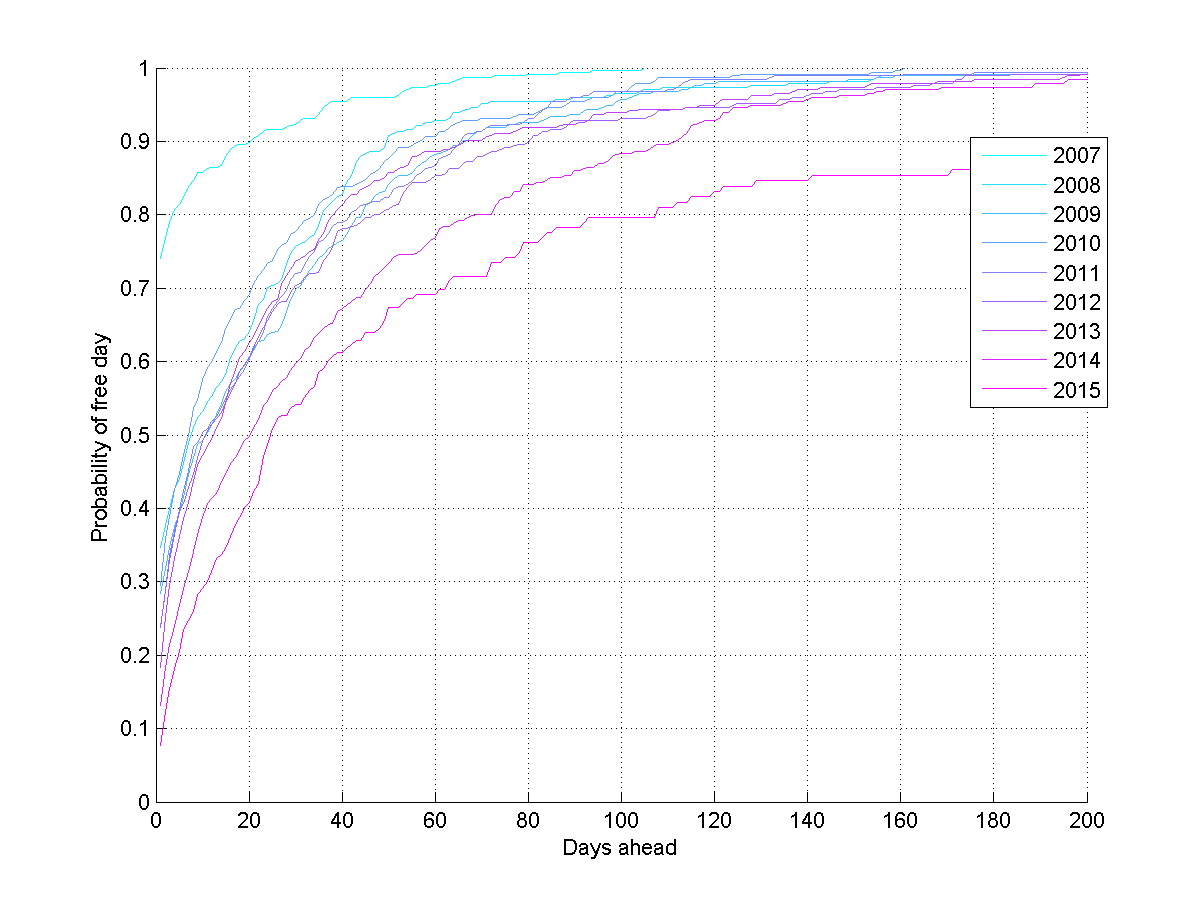
Probability that I will be free a certain number of days ahead for different years of my calender, estimated using a Poisson rate model.
If we slice the data by year, then there seems to be a fairly clear trend towards the planning horizon growing – I have more and more events far into future, and I have more to do. Oh, those halcyon days in 2007 when I presumably just lazed around…
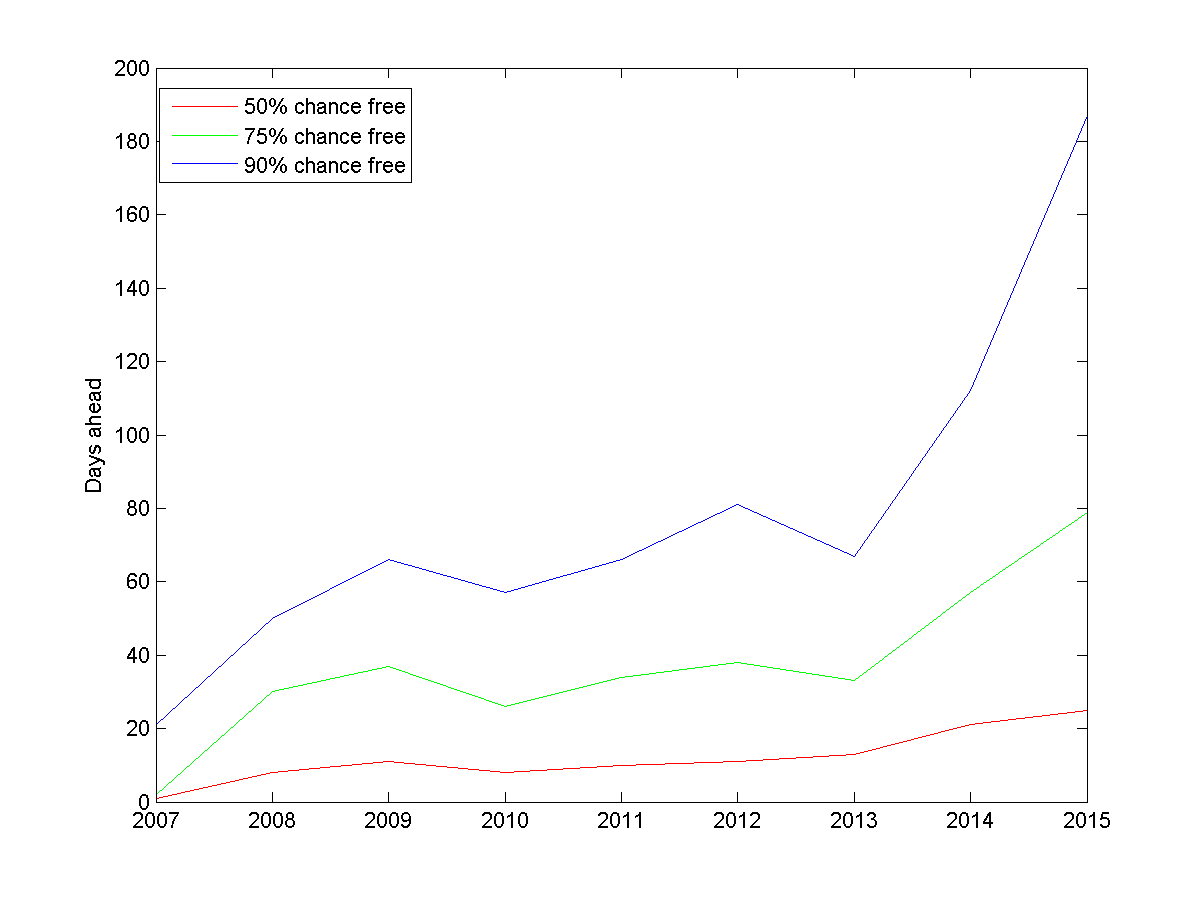
Distance to first day where I have 50%, 75% or 90% chance of being entirely unscheduled.
If we plot when I have 50%, 75% and 90% chance of being free, the trend is even clearer. At present you need to ask about three weeks in advance to have a 50% chance of grabbing me, and 187 days in advance to be 90% certain (if you want an entire working week with 50% chance, this is close to where you should go). Back in 2008 the 50% point was about a week and the 90% point 1.5 months ahead. I have become around 3 times busier.
Conclusions
So, I have become busier. This is of course no evidence of getting more done – a lot of events are pointless meetings, and who knows if I am doing anything helpful at the other events. Plus, I might actually be wasting my time doing statistics and blogging instead of working.
But the exercise shows that it is possible to automatically estimate necessary planning horizons. Maybe we should add this to calendar apps to help scheduling: my contact page or virtual secretary might give you an automatically updated estimate of how far ahead you need to schedule things to have a good chance of getting me. It doesn’t have to tell you my detailed schedule (in principle one could do a privacy attack on the schedule by asking for very specific dates and seeing if they were blocked).
We can also use this method to look at levels of busyness across organisations. Who have flexibility in their schedules, who are so overloaded that they cannot be effectively involved in projects? In the past, tasks tended to be simple and the issue was just the amount of time people had. But today we work individually yet as part of teams, and coordination (meetings, seminars, lectures) are the key links: figuring out how to schedule them right is important for effectivity.
If team member has scheduling rates and they are are uncorrelated (yeah, right), then . The most important lesson is that the chance of everybody being able to make it to any given meeting day declines exponentially with the number of people. If the decline exponentially with time (plausible in at least my case) then scheduling a meeting requires the time ahead to be proportional to the number of people involved: double the meeting size, at least double the planning horizon. So if you want nimble meetings, make them tiny.
In the end, I prefer to live by the advice my German teacher Ulla Landvik once gave me, glancing at the school clock: “I see we have 30 seconds left of the lesson. Let’s do this excercise – we have plenty of time!” Time not only flies, it can be stretched too.
Addendum 2015-05-01
Some further explorations.
Days until next completely free day as a function of time. Grey shows data day-by-day, blue averaged over 7 days, green 30 days and red one year.
Owen Cotton-Barratt pointed out that another measure of busyness might be the distance to the next free day. Plotting it shows a very bursty pattern, with noisy peaks. The mean time was about 2-3 days: even though a lot of time the horizon is far away, often an empty day slips through too. It is just that it cannot be relied on.
Histogram of the timing of events by weekday.
Are there periodicities? The most obvious is the weekly dynamics: Thursdays are busiest, weekend least busy. I tend to do scheduling in a roughly similar manner, with Tuesdays as the top scheduling day.
Number of events scheduled per day, plotted across my calendar.
Over the years, plotting the number of events per day (“event intensity”) it is also clear that there is a loose pattern. Back in 2008-2011 one can see a lower rate around day 75 – that is the break between Hilary and Trinity term here in Oxford. There is another trough around day 200-250, the summer break and the time before the Michaelmas term. However, this is getting filled up over time.
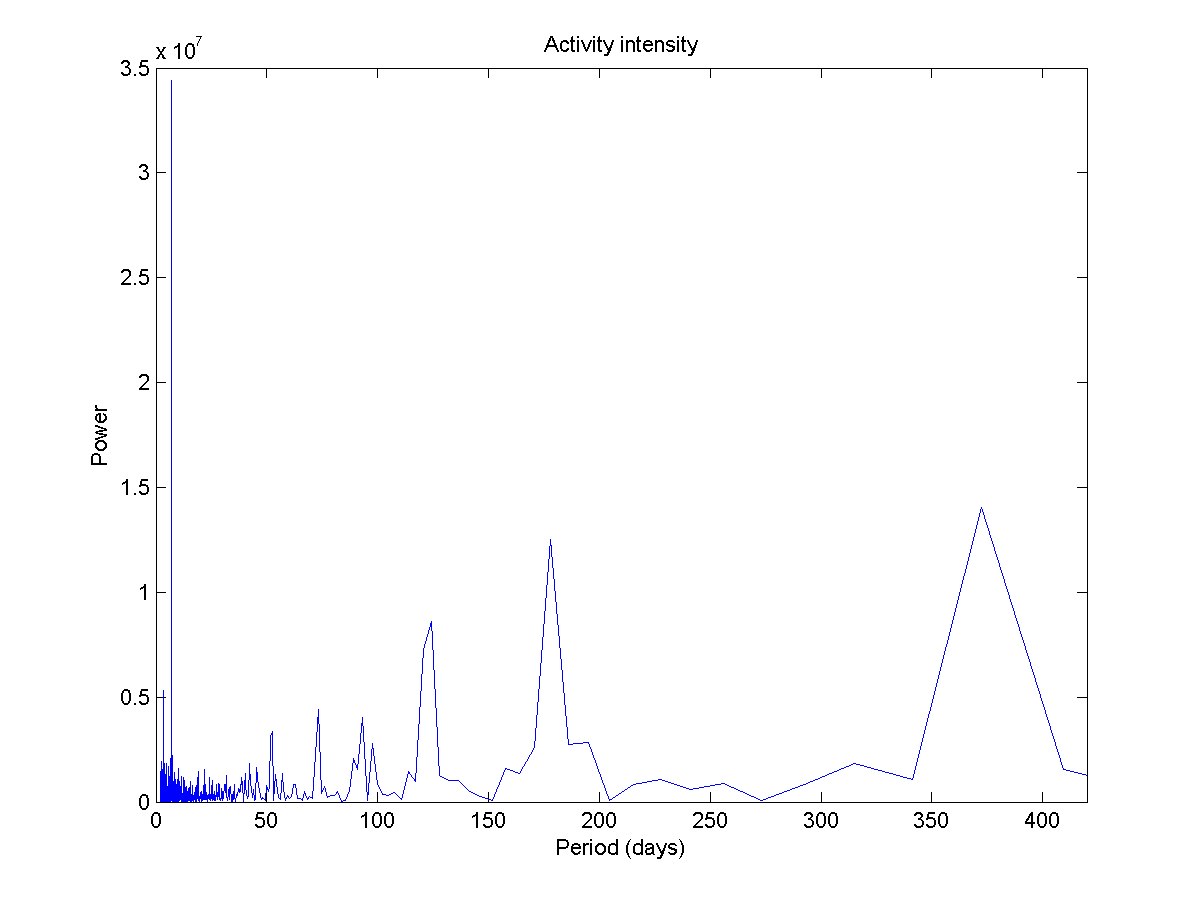
Periodogram of event intensity, showing periodicities in my schedule. Note the weekly and yearly peaks.
Making a periodogram produces an obvious peak for 7 days, and a loose yearly periodicity. Between them there is a bunch of harmonics. The funny thing is that the week periodicity is very strong but hard to see in the map above.
Pew Research has posted their Morality Interactive Topline Results for their spring 2013 and winter 2013-2014 survey of moral views around the world. These are national samples, so for each moral issue the survey gives how many thinks it is morally unacceptable, morally acceptable, not a moral issue or whether it depends on the situation.
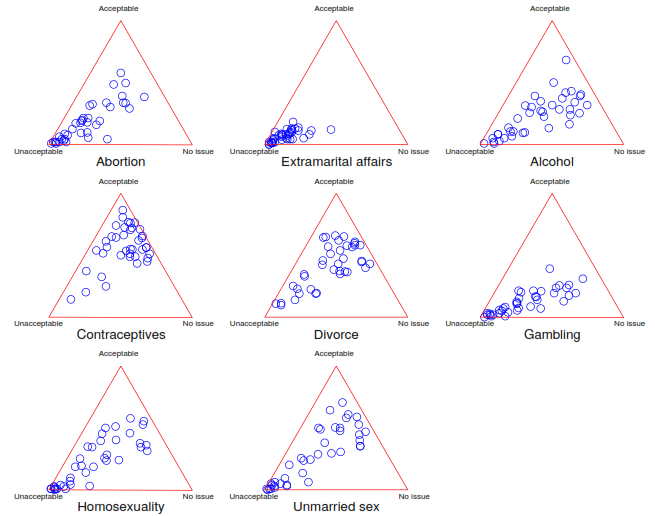
Plotting countries by whether issues are morally acceptable, morally unacceptable or morally irrelevant gives the following distributions.
Overall, there are many countries that are morally against everything, and a tail pointing towards some balance between acceptable or morally irrelevant.
The situation-dependence scores tended to be low: most people do think there are moral absolutes. The highest situation-dependency scores tended to be in the middle between the morally unacceptable point and the OK side; I suspect there was just a fair bit of confusion going on.
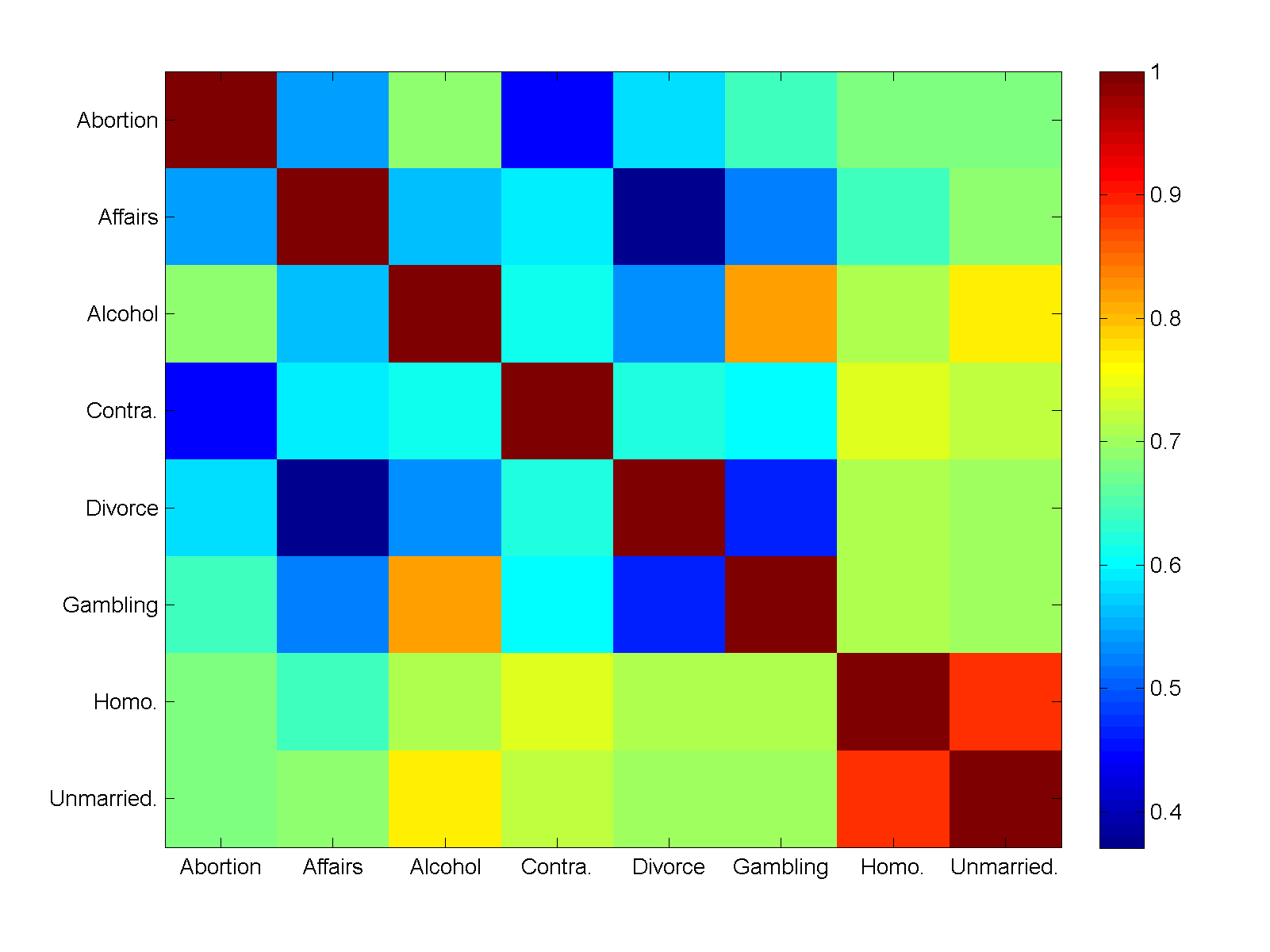
Looking at the correlations between morally unacceptable answers suggested that unmarried sex and homosexuality stands out: views there were firmly correlated but not strongly influenced by views on other things. I regard this as a “sex for fun” factor. However, it should be noted that almost everything is firmly correlated: if a country is against X, it is likely against Y too. Looking at correlations between acceptable or no issue answers did not show any clear picture.
The real sledgehammer is of course principal component analysis. Running it for the whole data produces a firm conclusion: the key factor is something we could call “moral conservatism”, which explains 73% of the variance. Countries that score high find unmarried sex, homosexuality, alcohol, gambling, abortion and divorce unacceptable.
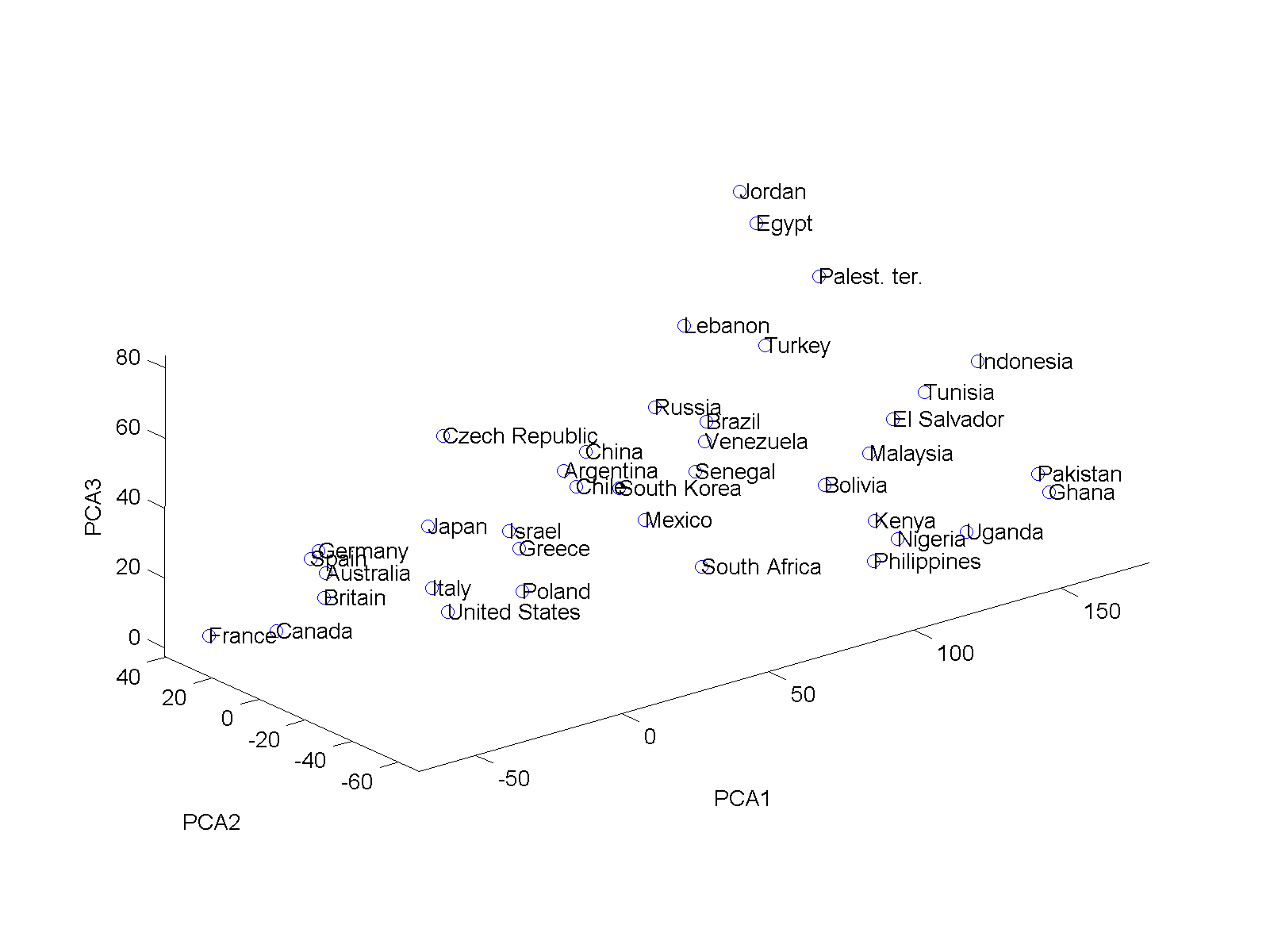
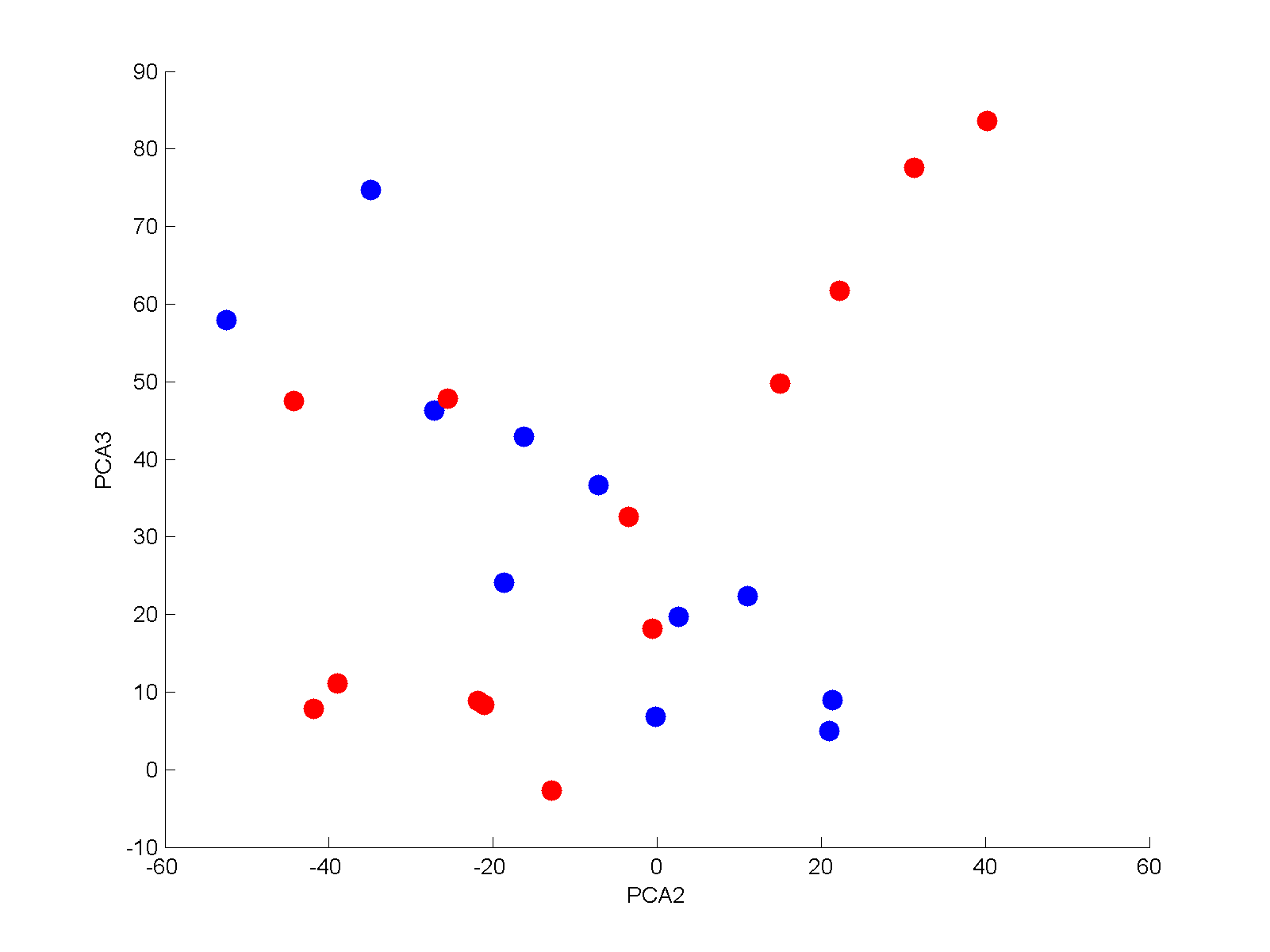
The second factor, explaining 9%, seems to denote whether things are morally acceptable or simply morally not an issue. However, it has some unexpected interaction with whether unmarried sex is unacceptable. This links to the third factor, explaining 7%, which seems to be linked to views on divorce and contraception. Looking at the 3D plot of the data, it becomes clear that for countries scoring low on the moral conservatism scale (“modern countries”) there is a negative correlation between these two factors, while for conservative countries there is a positive correlation.
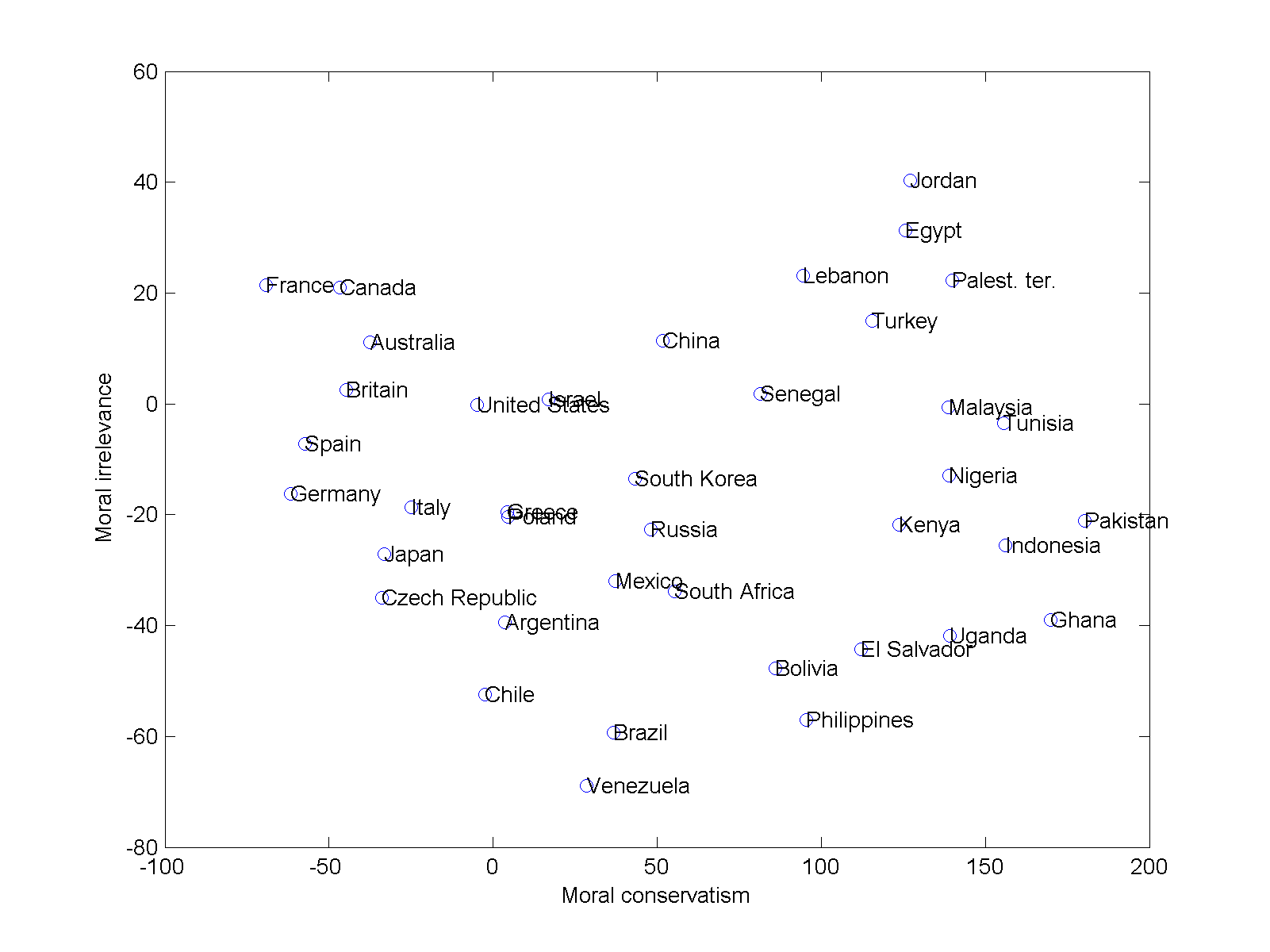
Plotting the most conservative (red) and least (blue) countries supports this. The lower blue corner is the typical Western countries (France, Canada, US, Australia) while the upper blue corner is more traditionalist (?) countries (Czech republic, Chile, Spain). The lower red corner has Ghana, Uganda, Pakistan and Nigeria, while the upper red is clearly Arab: Egypt, the Palestinian territories, Jordan.
In the end, I guess the data doesn’t tell us that much truly new. A large part of the world hold traditional conservative moral views. Perhaps the most interesting part is that the things people regard as morally salient or not interacts in a complicated manner with local culture. There are also noticeable differences even within the same cultural sphere: Tunisia has very different views from Egypt on divorce.
For those interested, here is my somewhat messy Matlab code and data to generate these pictures.
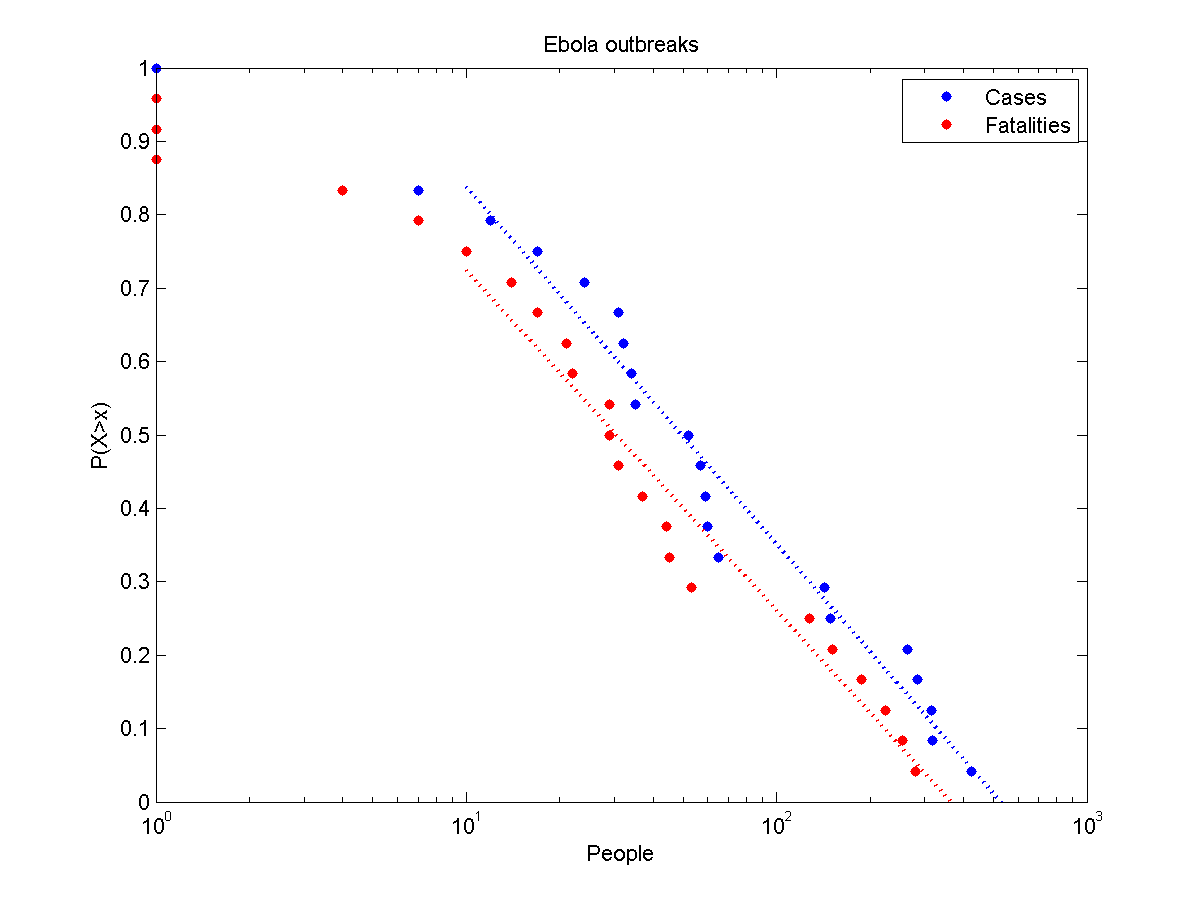
Here is a reason not to worry too much about Ebola… yet. I took the WHO data on Ebola outbreaks and plotted it. The distribution is not power-law distributed (looks bent on a loglog scale) but is decently exponential (straight on a semilog scale). The probability goes down fast with size.
However, when we add the final toll from the current outbreak (1603 suspected cases with 887 fatalities at August 1) it might turn out to be a “dragon-king” bucking the line: in that case we should expect that large international outbreaks follow an entirely new dynamic. This is mildly worrying. Still, it is early days.
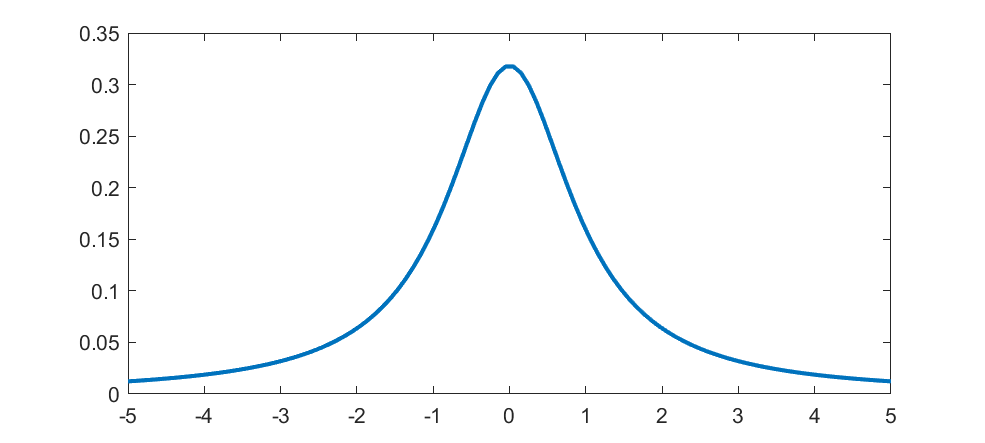 The first “weird” distribution I encountered was the Chauchy distribution. It has a nice algebraic form, a suggestive normalization constant… and no mean, variance or higher order moments. I remember being very surprised as a student when I saw that. It was there on the paper, with a very obvious centre point, yet that centre was not the mean. Like most “pathological examples” it was of course a representative of the majority: having a mean is actually quite “rare”. These days, playing with power-laws, I am used to this and indeed find it practically important. It is no longer weird.
The first “weird” distribution I encountered was the Chauchy distribution. It has a nice algebraic form, a suggestive normalization constant… and no mean, variance or higher order moments. I remember being very surprised as a student when I saw that. It was there on the paper, with a very obvious centre point, yet that centre was not the mean. Like most “pathological examples” it was of course a representative of the majority: having a mean is actually quite “rare”. These days, playing with power-laws, I am used to this and indeed find it practically important. It is no longer weird.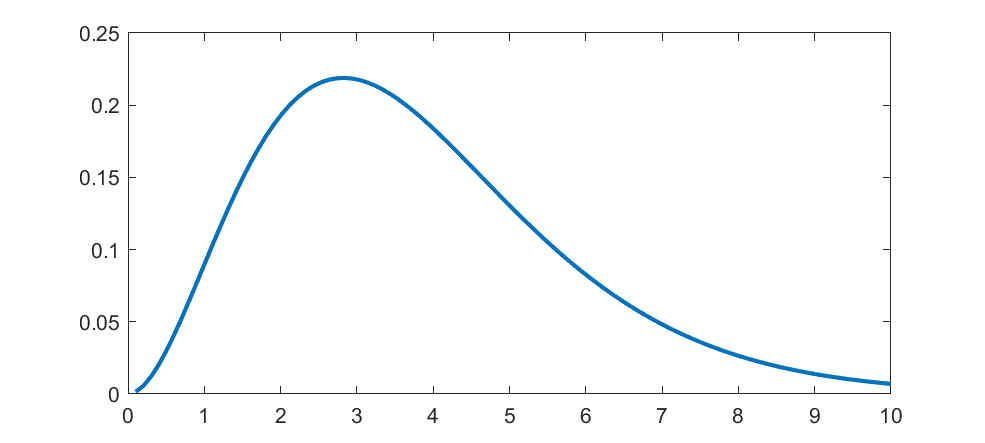 The Planck distribution isn’t too unusual, but has links to many cool special functions and is of course deeply important in physics. It is still surprisingly obscure as a mathematical probability distribution.
The Planck distribution isn’t too unusual, but has links to many cool special functions and is of course deeply important in physics. It is still surprisingly obscure as a mathematical probability distribution.=k w(t) \pm 1, (0<k<1).")
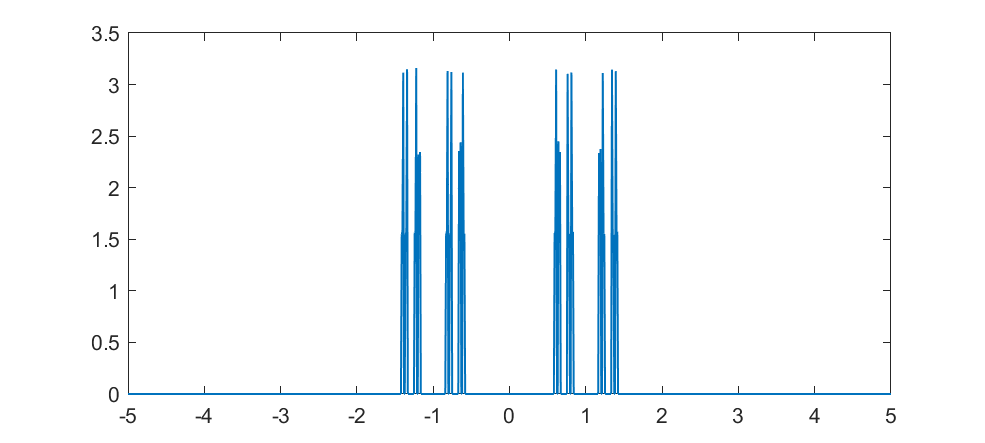
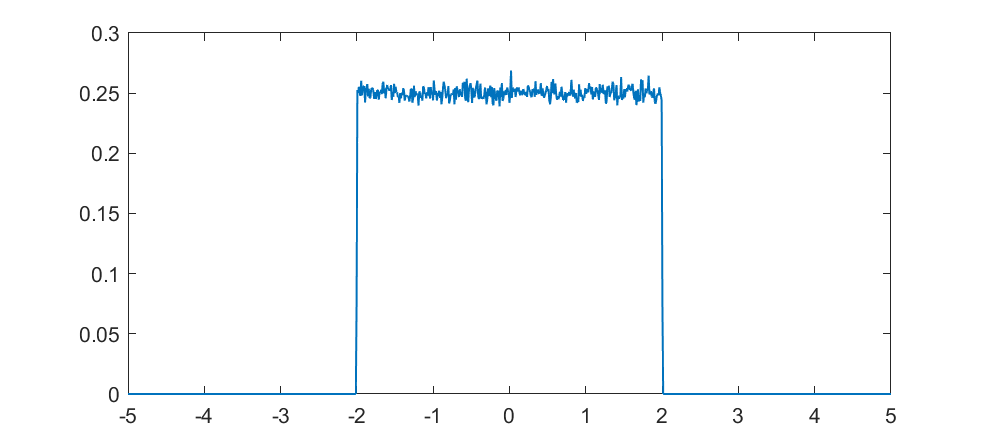
")

 triangular faces. Each face has 3 vertices, shared between 6 faces, so the total number of vertices is 65536, and they become faces of my die.
triangular faces. Each face has 3 vertices, shared between 6 faces, so the total number of vertices is 65536, and they become faces of my die. Since each face on the subdivided d8 has three edges, shared by two sides
Since each face on the subdivided d8 has three edges, shared by two sides F") . So
. So  . With
. With  I get
I get  … two vertices too much, which means that after dualization I end up with a d65538 intead of a d65536!
… two vertices too much, which means that after dualization I end up with a d65538 intead of a d65536!
 . If
. If  the probability of landing on one of the end polygons
the probability of landing on one of the end polygons  while for each of the sides it is
while for each of the sides it is  (and by symmetry they are all equal). If
(and by symmetry they are all equal). If  then the probability instead approaches 1 and the side probability approaches 0. So by continuity, in between there must be a
then the probability instead approaches 1 and the side probability approaches 0. So by continuity, in between there must be a  where the probability of landing on one of the ends equals the probability of landing on one of the sides. There is no reason for the areas to be equal.
where the probability of landing on one of the ends equals the probability of landing on one of the sides. There is no reason for the areas to be equal. sides.
sides. ") where
where  is the second largest eigenvalue of the transition matrix. In our case of subdividing the d4, the
is the second largest eigenvalue of the transition matrix. In our case of subdividing the d4, the  quite fast as we subdivide, making the effect of a big die of this type rapidly mixing. We likely only need a handful of rolls of the d(65536!) to scramble the d65536 enough to regard it as essentially fair.
quite fast as we subdivide, making the effect of a big die of this type rapidly mixing. We likely only need a handful of rolls of the d(65536!) to scramble the d65536 enough to regard it as essentially fair.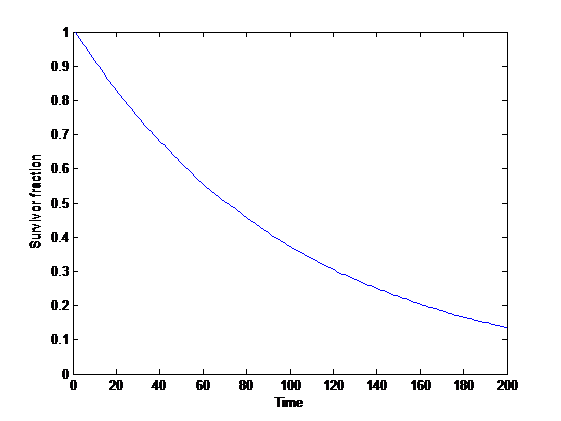
 and the probability of extinction
and the probability of extinction  = p") , then the curve is
, then the curve is  = \exp(-p \lambda t).")
 and is reduced by disasters, then initially some instances will be wiped out, but many realizations achieve takeoff where they grow essentially forever. As the population becomes larger, risk declines as
and is reduced by disasters, then initially some instances will be wiped out, but many realizations achieve takeoff where they grow essentially forever. As the population becomes larger, risk declines as .")
 of time, we get a Weibull distribution of time to extinction, which has a “stretched exponential” survival curve:
of time, we get a Weibull distribution of time to extinction, which has a “stretched exponential” survival curve: ^k.")
 at a certain time
at a certain time  , in which case it just reduces the survival curve so
, in which case it just reduces the survival curve so }{S(\mathrm{before }t)}=w") . If
. If 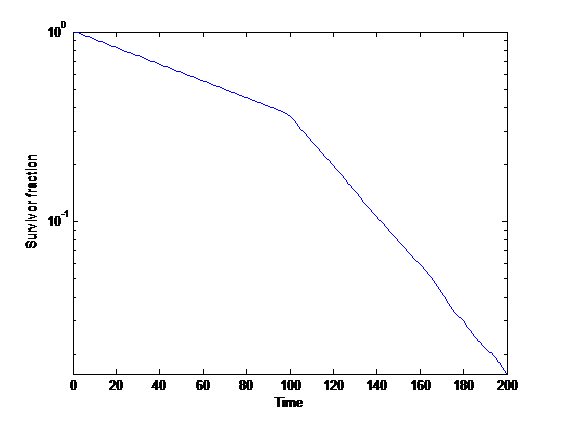
=\Pr(T>t)") where
where  is a random variable denoting the time of death. In engineering it is commonly called reliability function. It is declining over time, and will approach zero unless indefinite survival is possible with a finite probability.
is a random variable denoting the time of death. In engineering it is commonly called reliability function. It is declining over time, and will approach zero unless indefinite survival is possible with a finite probability.=\frac{d}{dt}(1-S(t))") denotes the rate of death per unit time.
denotes the rate of death per unit time.") is the event rate at time
is the event rate at time  = - S'(t)/S(t)") . Note that unlike the event density function this does not have to decline as the number of survivors gets low: this is the overall force of mortality at a given time.
. Note that unlike the event density function this does not have to decline as the number of survivors gets low: this is the overall force of mortality at a given time. is
is }\int_{t_0}^\infty S(t)dt.") Note that for exponential survival curves (i.e. constant hazard) it remains constant.
Note that for exponential survival curves (i.e. constant hazard) it remains constant. possible scenarios, one of which (
possible scenarios, one of which ( ) will come about. They have probability
) will come about. They have probability  . We allocate a unit budget of effort to the scenarios:
. We allocate a unit budget of effort to the scenarios:  . For the scenario that comes about, we get utility
. For the scenario that comes about, we get utility  (diminishing returns).
(diminishing returns). .
.  corresponds to even allocation, 1 proportional to the likelihood, >1 to favoring the most likely scenarios. In the following I will run Monte Carlo simulations where the probabilities are randomly generated each instantiation. The outer bluish envelope represents the 95% of the outcomes, the inner ranges from the lower to the upper quartile of the utility gained, and the red line is the expected utility.
corresponds to even allocation, 1 proportional to the likelihood, >1 to favoring the most likely scenarios. In the following I will run Monte Carlo simulations where the probabilities are randomly generated each instantiation. The outer bluish envelope represents the 95% of the outcomes, the inner ranges from the lower to the upper quartile of the utility gained, and the red line is the expected utility.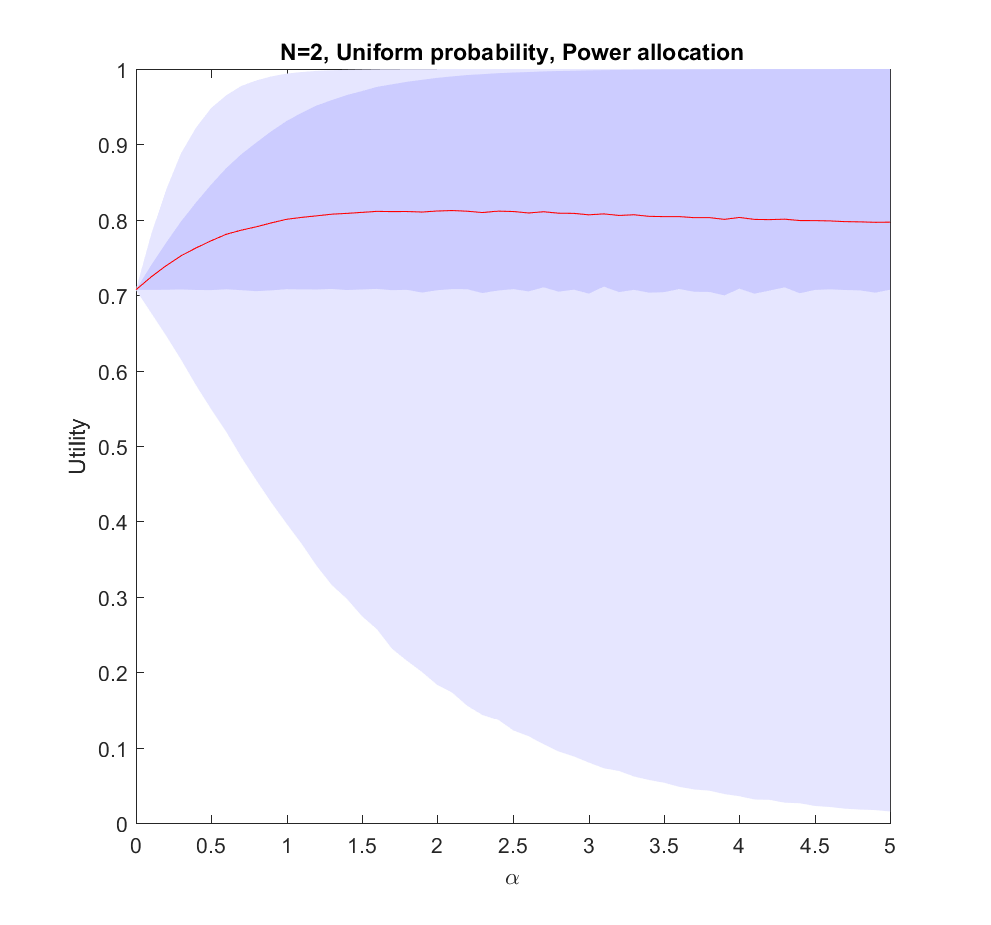
 case: we have two possible scenarios with probability
case: we have two possible scenarios with probability  and
and  (where
(where  utility on average, but if we put in more effort on the more likely case we will get up to 0.8 utility. As we focus more and more on the likely case there is a corresponding increase in variance, since we may guess wrong and lose out. But 75% of the time we will do better than if we just allocated evenly. Still, allocating nearly everything to the most likely case means that one does lose out on a bit of hedging, so the expected utility declines slowly for large
utility on average, but if we put in more effort on the more likely case we will get up to 0.8 utility. As we focus more and more on the likely case there is a corresponding increase in variance, since we may guess wrong and lose out. But 75% of the time we will do better than if we just allocated evenly. Still, allocating nearly everything to the most likely case means that one does lose out on a bit of hedging, so the expected utility declines slowly for large  .
.
 case (where the probabilities are allocated based on a flat
case (where the probabilities are allocated based on a flat  ), but we are not able to allocate perfectly. A more plausible model would give us probability estimates instead of the actual probabilities.
), but we are not able to allocate perfectly. A more plausible model would give us probability estimates instead of the actual probabilities.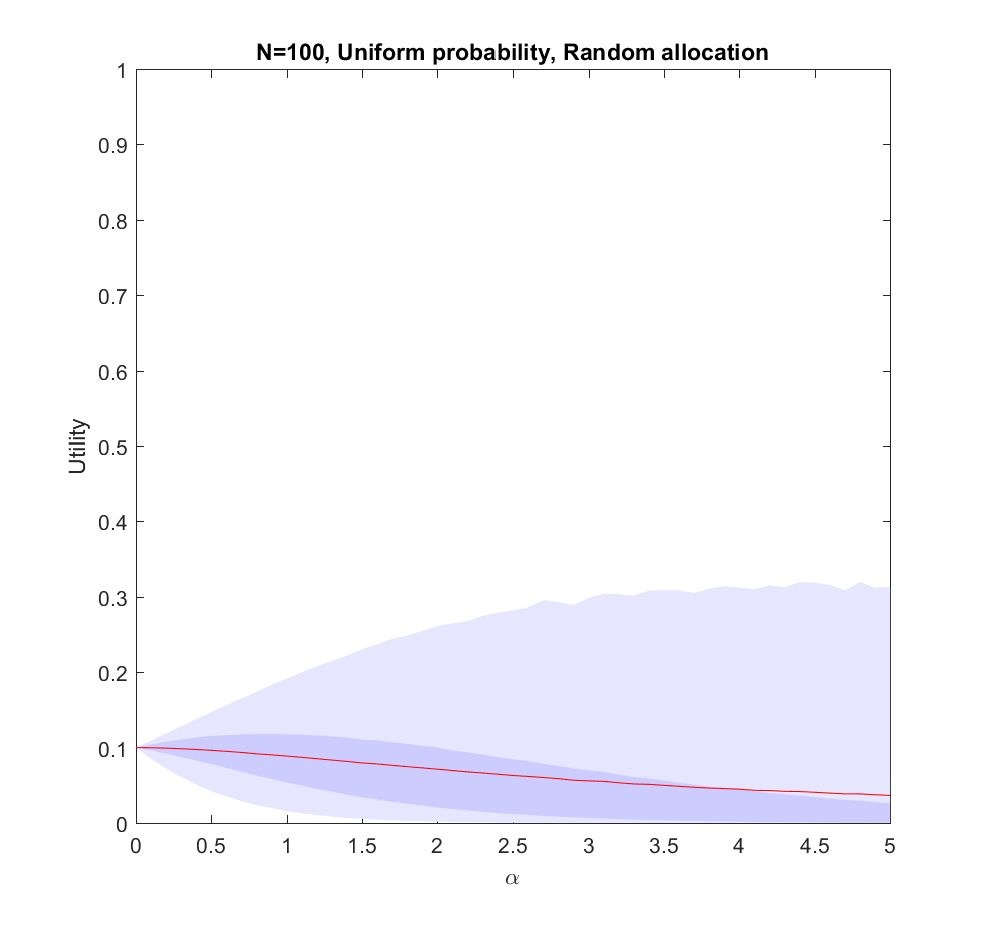
 ). The larger N is, the less likely it is that we focus on the right scenario since we know nothing. The rationality of ignoring irrelevant information is pretty obvious.
). The larger N is, the less likely it is that we focus on the right scenario since we know nothing. The rationality of ignoring irrelevant information is pretty obvious.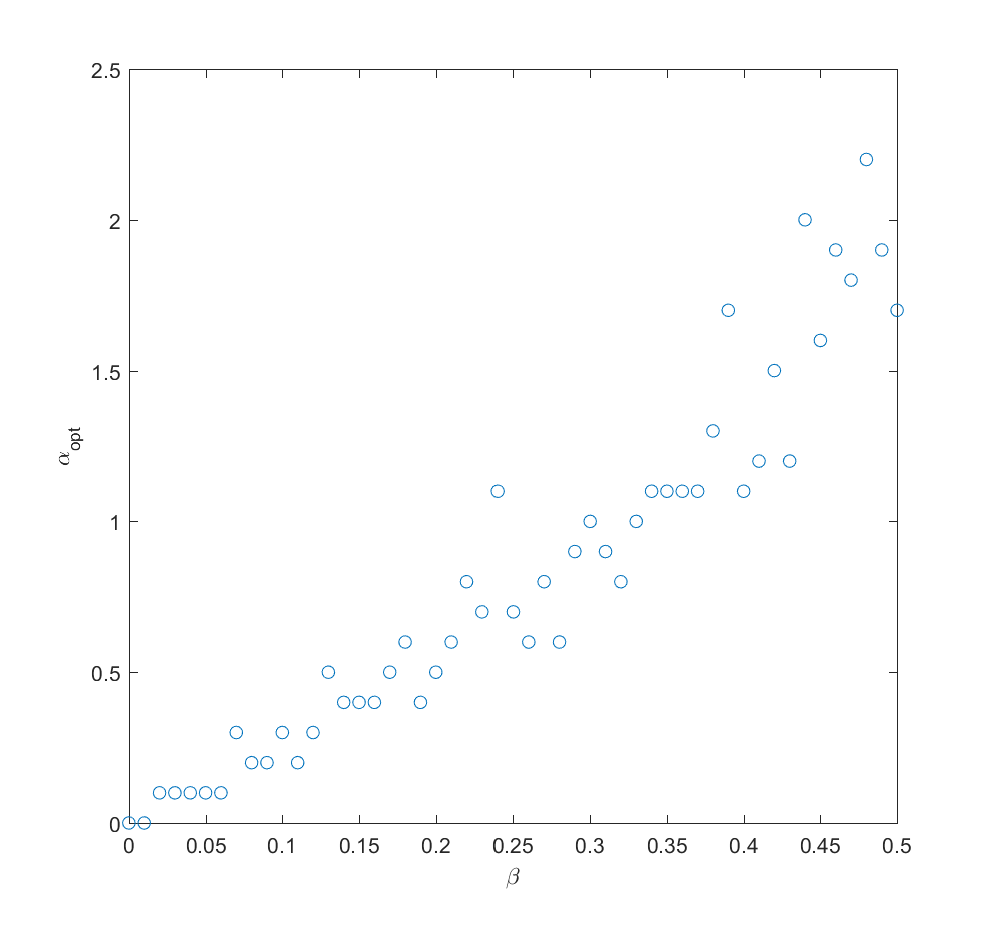
 . In fact, we can mix in just a bit (
. In fact, we can mix in just a bit ( ) of the true probability and get a fairly good guess where to allocate effort (i.e. we allocate effort as
) of the true probability and get a fairly good guess where to allocate effort (i.e. we allocate effort as Q_i)^\alpha") where
where  is uncorrelated noise probabilities). The optimal alpha grows roughly linearly with
is uncorrelated noise probabilities). The optimal alpha grows roughly linearly with  in this case.
in this case. to the different scenarios we get better information about the probabilities, and can now reallocate. A simple model may be that the standard deviation of noise behaves as
to the different scenarios we get better information about the probabilities, and can now reallocate. A simple model may be that the standard deviation of noise behaves as  where
where  is the effort placed in exploring the probability of scenario
is the effort placed in exploring the probability of scenario  . So if we begin by allocating uniformly we will have noise at reallocation of the order of
. So if we begin by allocating uniformly we will have noise at reallocation of the order of  . We can set
. We can set =\sqrt{\gamma/N}/C") , where
, where  is some constant denoting how tough it is to get information. Putting this together with the above result we get
is some constant denoting how tough it is to get information. Putting this together with the above result we get =\sqrt{2\gamma/NC^2}") . After this exploration, now we use the remaining
. After this exploration, now we use the remaining  effort to work on the actual scenarios.
effort to work on the actual scenarios.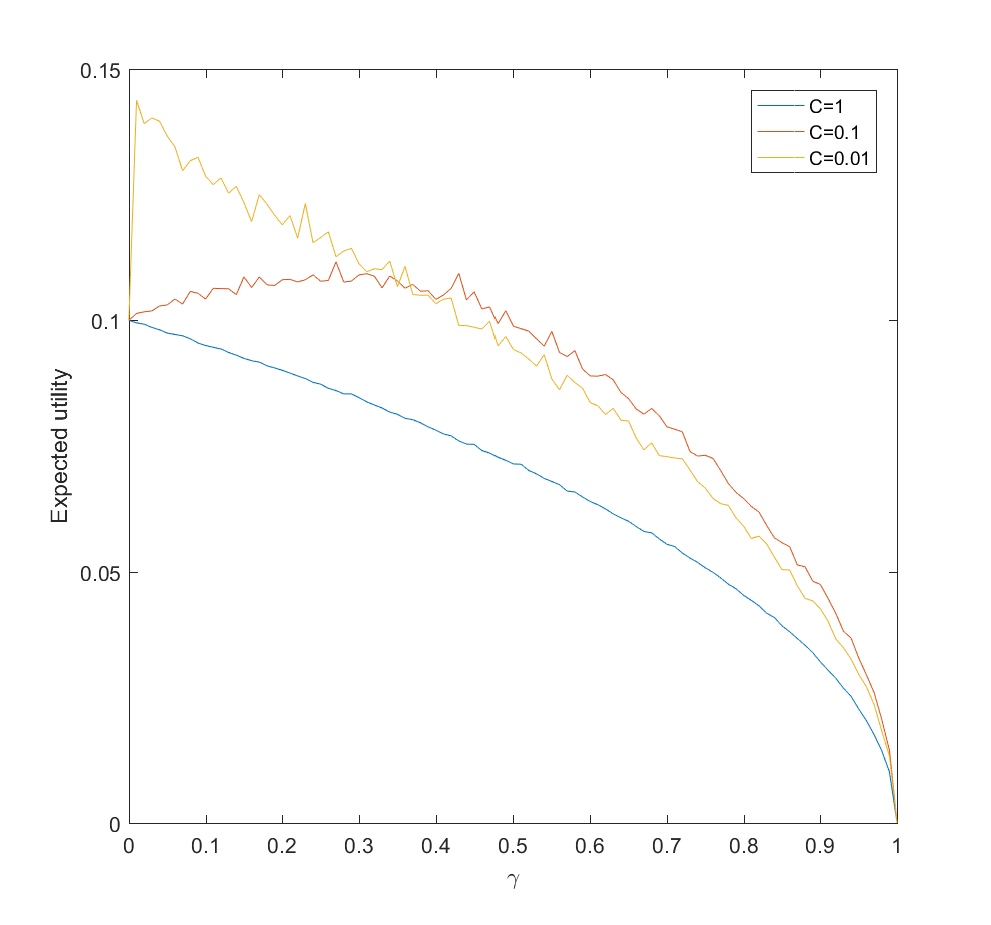
 and the gain is just the utility difference between the uniform case
and the gain is just the utility difference between the uniform case  , which we know is pretty small. If C is small (i.e. a small amount of effort is enough to figure out the scenario probabilities) there is an optimal nonzero
, which we know is pretty small. If C is small (i.e. a small amount of effort is enough to figure out the scenario probabilities) there is an optimal nonzero 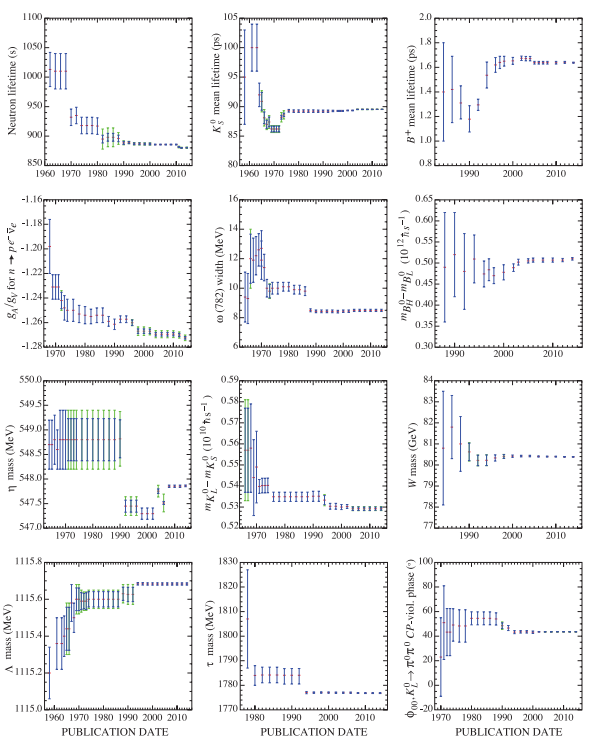
 big surprises (remember that the first data point counts as one!), then the probability of a new surprise for your next data point is
big surprises (remember that the first data point counts as one!), then the probability of a new surprise for your next data point is  . So if you expect
. So if you expect  data points in total, when
data points in total, when /N \ll 1") you can start to trust the estimates… assuming surprises are uncorrelated etc. Which you will not be certain about. The progression towards greater precision may be anything but dull.
you can start to trust the estimates… assuming surprises are uncorrelated etc. Which you will not be certain about. The progression towards greater precision may be anything but dull.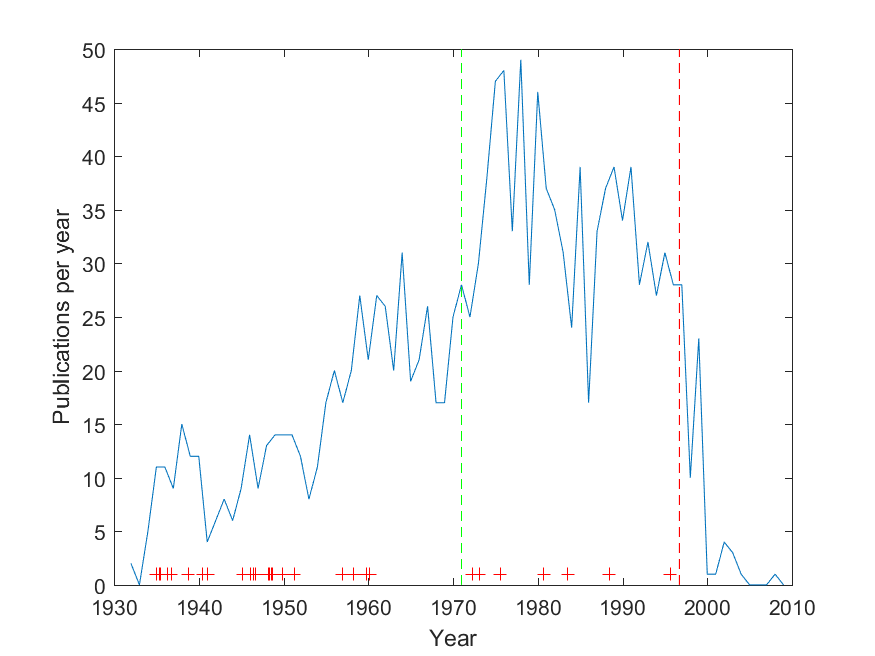


") that a day
that a day ") , then the chance for an empty day is
, then the chance for an empty day is  = \prod_{i=t}^\infty (1-P(i))") . We can estimate
. We can estimate =N(i)/N") .
.
") tells us how often I schedule something
tells us how often I schedule something =N(i)/T") , where
, where  = \prod_{i=t}^\infty e^{-\lambda(i)}") .
.
") and they are are uncorrelated (yeah, right), then
and they are are uncorrelated (yeah, right), then =\prod_{i=t}^\infty e^{-\sum_j\lambda_j(i)}") . The most important lesson is that the chance of everybody being able to make it to any given meeting day declines exponentially with the number of people. If the
. The most important lesson is that the chance of everybody being able to make it to any given meeting day declines exponentially with the number of people. If the