Recently I encountered a specialist Wiki. I pressed “random page” a few times, and got a repeat page after 5 tries. How many pages should I expect this small wiki to have?
We can compare this to the German tank problem. Note that it is different; in the tank problem we have a maximum sample (maybe like the web pages on the site were numbered), while here we have number of samples before repetition.
We can of course use Bayes theorem for this. If I get a repeat after random samples, the posterior distribution of , the number of pages, is .
If I randomly sample from pages, the probability of getting a repeat on my second try is , on my third try , and so on: . Of course, there has to be more pages than , otherwise a repeat must have happened before step , so this is valid for . Otherwise, for .
The prior needs to be decided. One approach is to assume that websites have a power-law distributed number of pages. The majority are tiny, and then there are huge ones like Wikipedia; the exponent is close to 1. This gives us . Note the appearance of the Riemann zeta function as a normalisation factor.
We can calculate by summing over the different possible : .
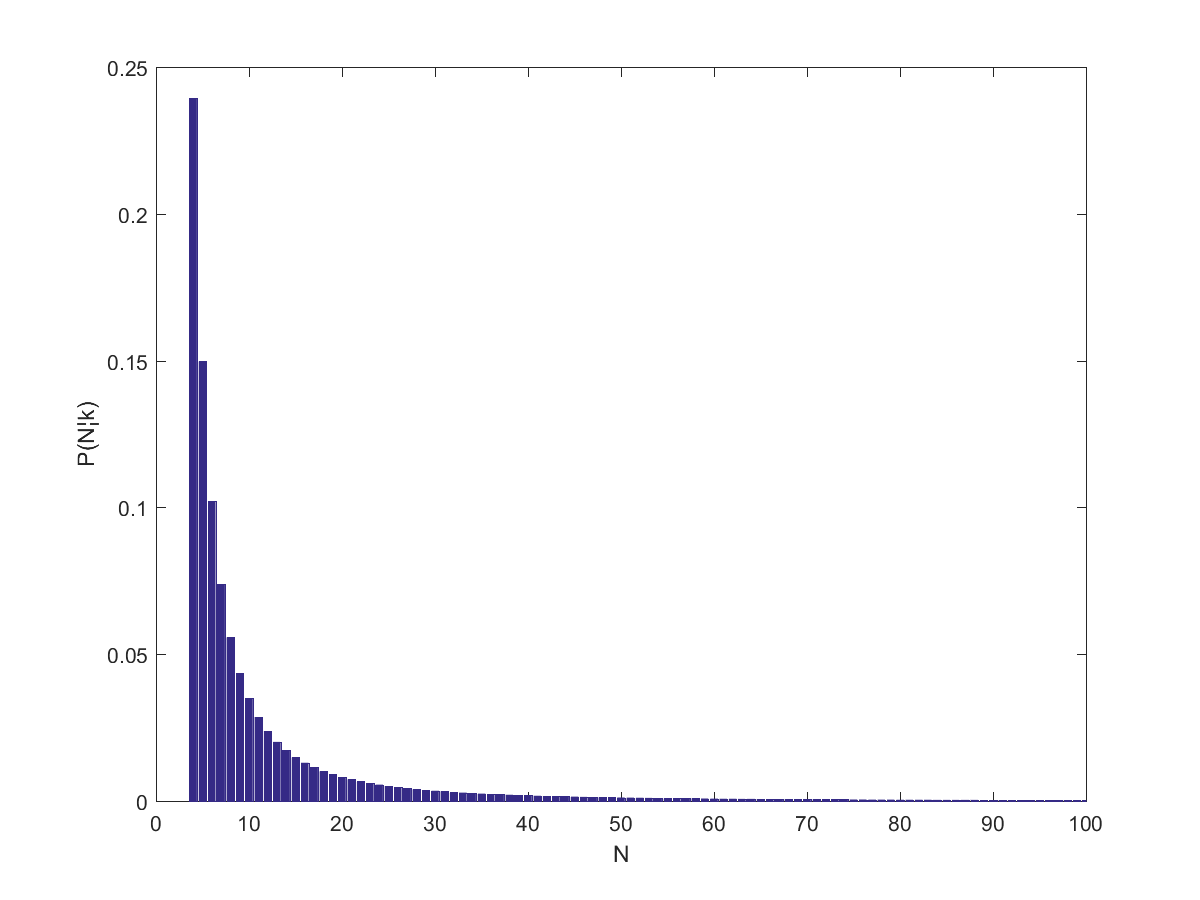
Putting it all together we get for . The posterior distribution of number of pages is another power-law. Note that the dependency on is rather subtle: it is in the support of the distribution, and the upper limit of the partial sum.
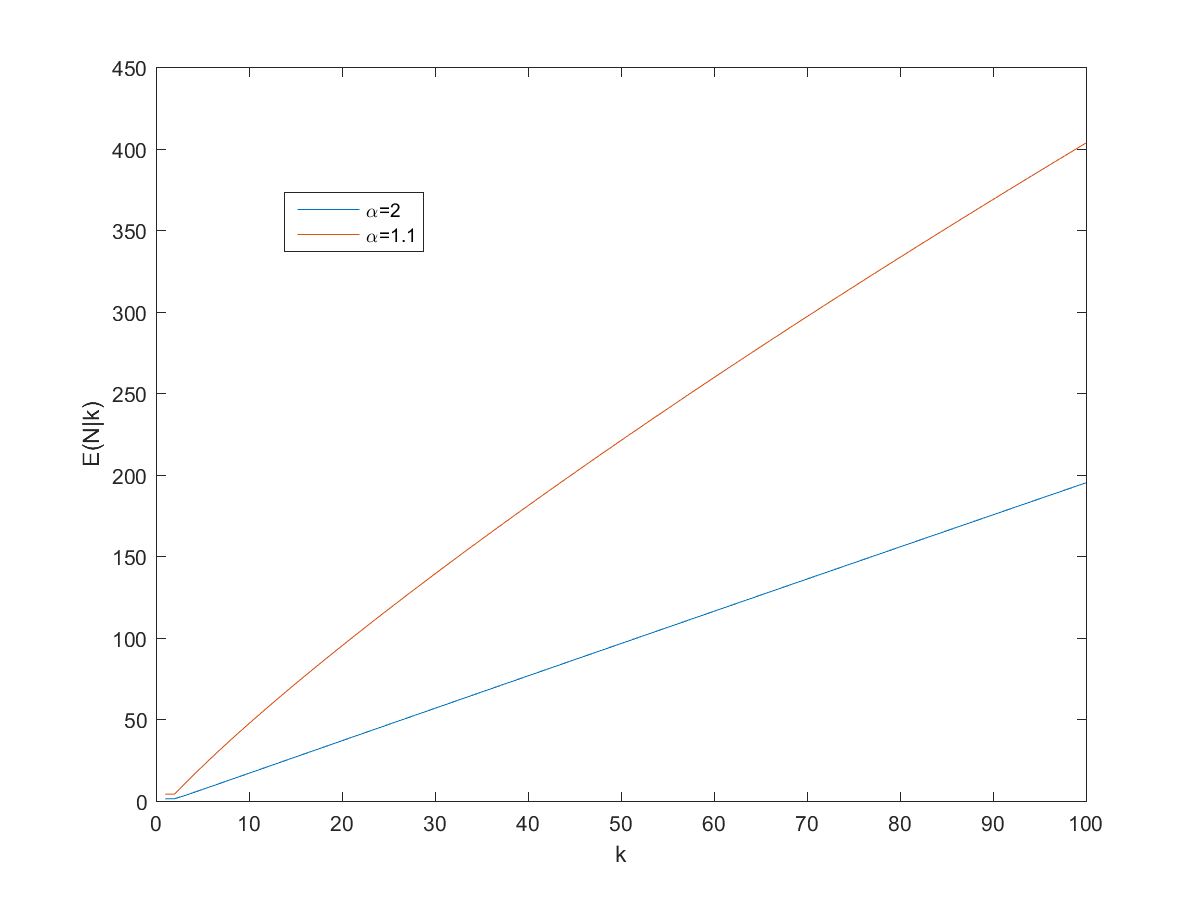
What about the expected number of pages in the wiki? . The expectation is the ratio of the zeta functions of and , minus the first terms of their series.
Distribution of P(N|5) for [latex]\alpha=1.1[/latex].
So, what does this tell us about the wiki I started with? Assuming (close to the behavior of big websites), it predicts . If one assumes a higher the number of pages would be 7 (which was close to the size of the wiki when I looked at it last night – it has grown enough today for k to equal 13 when I tried it today).
Expected number of pages given k random views before a repeat.
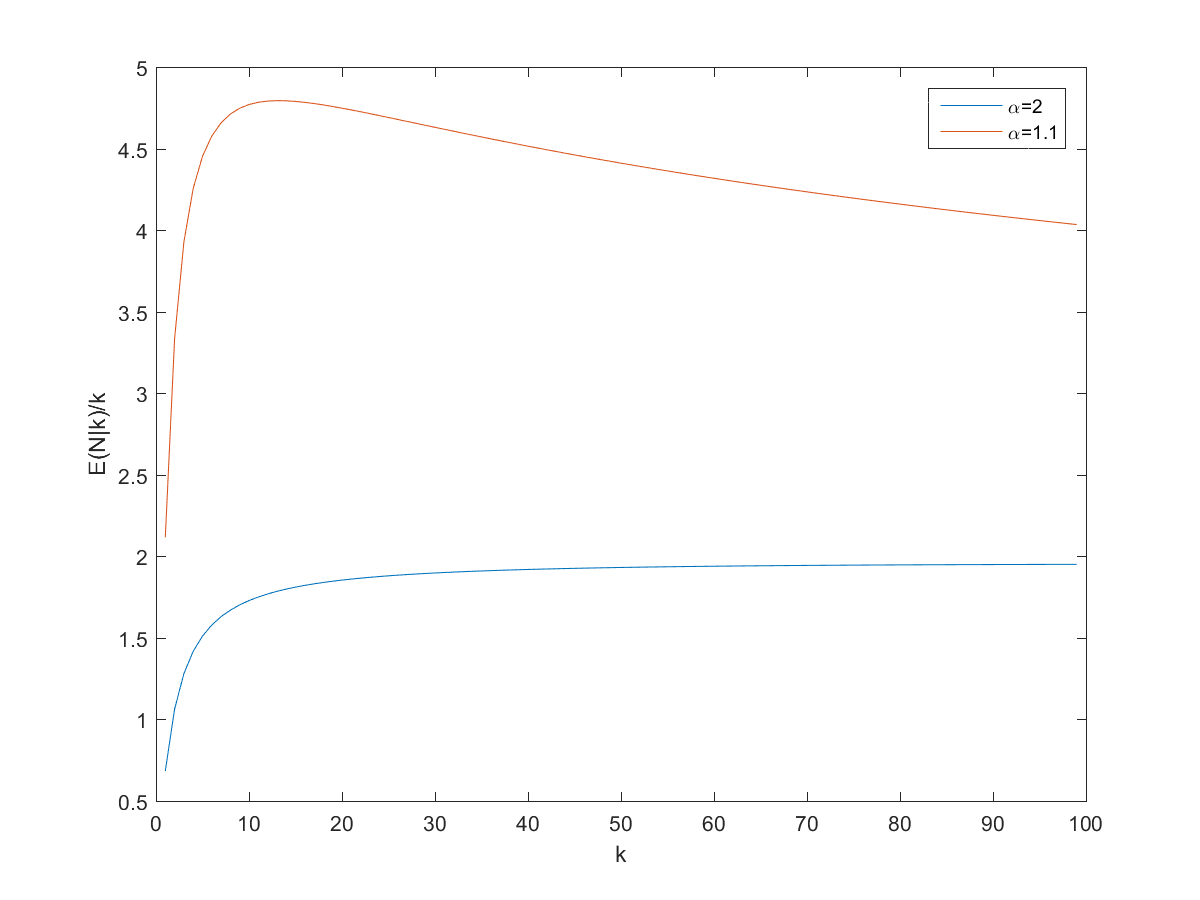
So, can we derive a useful rule of thumb for the expected number of pages? Dividing by shows that approaches proportionality, especially for larger :
E(N|k)/k as a function of k.
So a good rule of thumb is that if you get pages before a repeat, expect between and pages on the site. However, remember that we are dealing with power-laws, so the variance can be surprisingly high.
2 thoughts on “How small is the wiki?”
Taking the prior according to distribution of websites seems to assume that you drew your wiki randomly from the set of wikis. But larger wikis are probably linked to much more, so you’re disproportionately likely to find yourself on one.
I’m not sure exactly how to integrate this into the prior, but I expect the effect will be to reduce the effect of the prior, and move you closer to quadratic dependence on k.
But I think this is the *conditional* probability of getting a repeat at step k *given* no earlier repeats. To get the probability of a first repeat at step k, you need to multiply by the probability of not getting any repeats until then. That is:


 = P(k|N)P(N)/P(k)")


=(k-1)/N")


=0")

")
 = N^{-\alpha}/\zeta(\alpha)")
")
=\sum_{N=1}^\infty P(k|N)P(N) = \frac{k-1}{\zeta(\alpha)}\sum_{N=k-1}^\infty N^{-(\alpha+1)}")
}(\zeta(\alpha+1)-\sum_{i=1}^{k-2}i^{-(\alpha+1)})")
=N^{-(\alpha+1)}/(\zeta(\alpha+1) -\sum_{i=1}^{k-2}i^{-(\alpha+1)})")

=\sum_{N=1}^\infty N P(N|k) = \sum_{N=k-1}^\infty N^{-\alpha}/(\zeta(\alpha+1) -\sum_{i=1}^{k-2}i^{-(\alpha+1)})")
-\sum_{i=1}^{k-2} i^{-\alpha}}{\zeta(\alpha+1)-\sum_{i=1}^{k-2}i^{-(\alpha+1)}}")




\approx 21.28")

")


Taking the prior according to distribution of websites seems to assume that you drew your wiki randomly from the set of wikis. But larger wikis are probably linked to much more, so you’re disproportionately likely to find yourself on one.
I’m not sure exactly how to integrate this into the prior, but I expect the effect will be to reduce the effect of the prior, and move you closer to quadratic dependence on k.
Ah, you say:
P(k|N) = (k – 1)/N
But I think this is the *conditional* probability of getting a repeat at step k *given* no earlier repeats. To get the probability of a first repeat at step k, you need to multiply by the probability of not getting any repeats until then. That is:
P(k|N) = (k-1)*(N)*(N-1)*(N-2)*…*(N-k+2)/N^k