 The ever readable Scott Alexander stimulated a post on Practical Ethics about defaults, status quo, and disagreements about sex. The quick of it: our culture sets defaults on who is reasonable or unreasonable when couples disagree, and these become particularly troubling when dealing with biomedical enhancements of love and sex. The defaults combine with status quo bias and our scepticism for biomedical interventions to cause biases that can block or push people towards certain interventions.
The ever readable Scott Alexander stimulated a post on Practical Ethics about defaults, status quo, and disagreements about sex. The quick of it: our culture sets defaults on who is reasonable or unreasonable when couples disagree, and these become particularly troubling when dealing with biomedical enhancements of love and sex. The defaults combine with status quo bias and our scepticism for biomedical interventions to cause biases that can block or push people towards certain interventions.
Author: admin
Packing my circles
One of the first fractals I ever saw was the Apollonian gasket, the shape that emerges if you draw the circle internally tangent to three other tangent circles. It is somewhat similar to the Sierpinski triangle, but has a more organic flair. I can still remember opening my copy of Mandelbrot’s The Fractal Geometry of Nature and encountering this amazing shape. There is a lot of interesting things going on here.
Here is a simple algorithm for generating related circle packings, trading recursion for flexibility:
- Start with a domain and calculate the distance to the border for all interior points.
- Place a circle of radius
at the point with maximal distance
from the border.
- Recalculate the distances, treating the new circle as a part of the border.
- Repeat (2-3) until the radius becomes smaller than some tolerance.
This is easily implemented in Matlab if we discretize the domain and use an array of distances ")
 \leftarrow \min(d(x,y), D(x,y))")
")



It is interesting to note that the topology is Apollonian nearly everywhere: as soon as three circles form a curvilinear triangle the interior will be a standard gasket if 
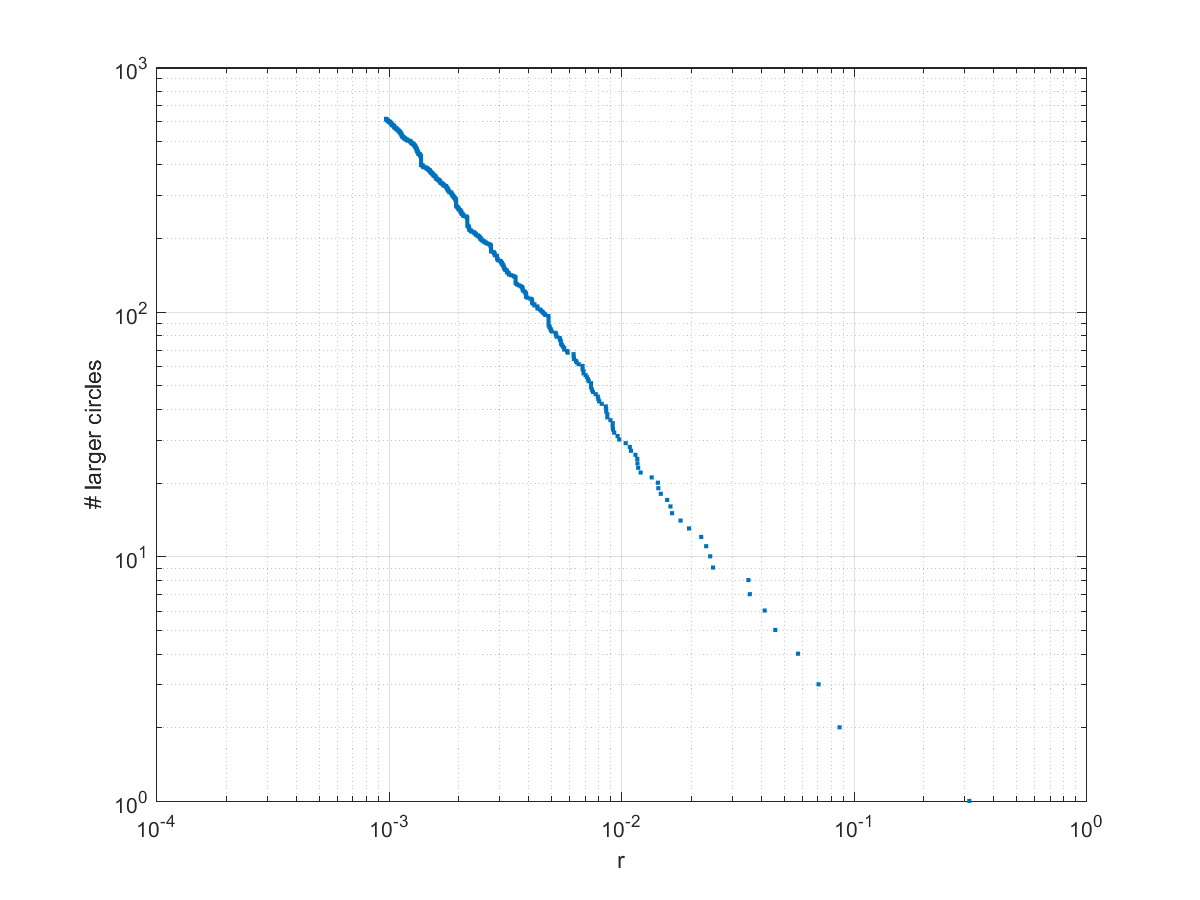
In the above pictures the first circle tends to dominate. In fact, the size distribution of circles is a power law: the number of circles larger than r grows as \propto r^-\delta")


Anyway, to make the first circle less dominant we can either place a non-optimal circle somewhere, or use lower 

If we place a circle in the centre of a square with a radius smaller than the distance to the edge, it gets surrounded by larger circles.

If the circle is misaligned, it is no problem for the tiling: any discrepancy can be filled with sufficiently small circles. There is however room for arbitrariness: when a bow-tie-shaped region shows up there are often two possible ways of placing a maximal circle in it, and whichever gets selected breaks the symmetry, typically producing more arbitrary bow-ties. For “neat” arrangements with the right relationships between circle curvatures and positions this does not happen (they have circle chains corresponding to various integer curvature relationships), but the generic case is a mess. If we move the seed circle around, the rest of the arrangement both show random jitter and occasional large-scale reorganizations.
When we let 

That these images have an organic look is not surprising. Vascular systems likely grow by finding the locations furthest away from existing vascularization, then filling in the gaps recursively (OK, things are a bit more complex).


How small is the wiki?
Recently I encountered a specialist Wiki. I pressed “random page” a few times, and got a repeat page after 5 tries. How many pages should I expect this small wiki to have?
We can compare this to the German tank problem. Note that it is different; in the tank problem we have a maximum sample (maybe like the web pages on the site were numbered), while here we have number of samples before repetition.
We can of course use Bayes theorem for this. If I get a repeat after 

 = P(k|N)P(N)/P(k)")
If I randomly sample from 

=(k-1)/N")


=0")

The prior ")
 = N^{-\alpha}/\zeta(\alpha)")
We can calculate ")
=\sum_{N=1}^\infty P(k|N)P(N) = \frac{k-1}{\zeta(\alpha)}\sum_{N=k-1}^\infty N^{-(\alpha+1)}")
}(\zeta(\alpha+1)-\sum_{i=1}^{k-2}i^{-(\alpha+1)})")
Putting it all together we get =N^{-(\alpha+1)}/(\zeta(\alpha+1) -\sum_{i=1}^{k-2}i^{-(\alpha+1)})")

What about the expected number of pages in the wiki? =\sum_{N=1}^\infty N P(N|k) = \sum_{N=k-1}^\infty N^{-\alpha}/(\zeta(\alpha+1) -\sum_{i=1}^{k-2}i^{-(\alpha+1)})")
-\sum_{i=1}^{k-2} i^{-\alpha}}{\zeta(\alpha+1)-\sum_{i=1}^{k-2}i^{-(\alpha+1)}}")


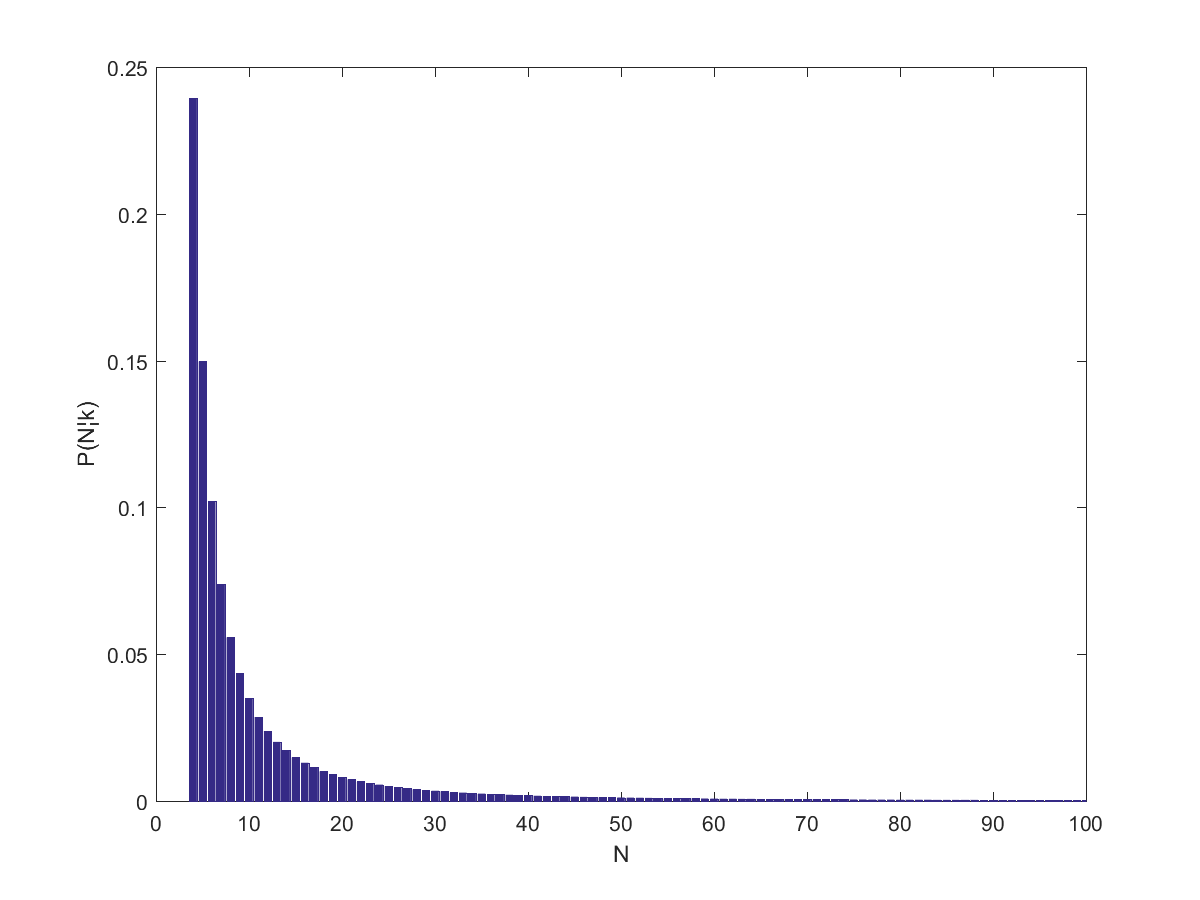
So, what does this tell us about the wiki I started with? Assuming 
\approx 21.28")

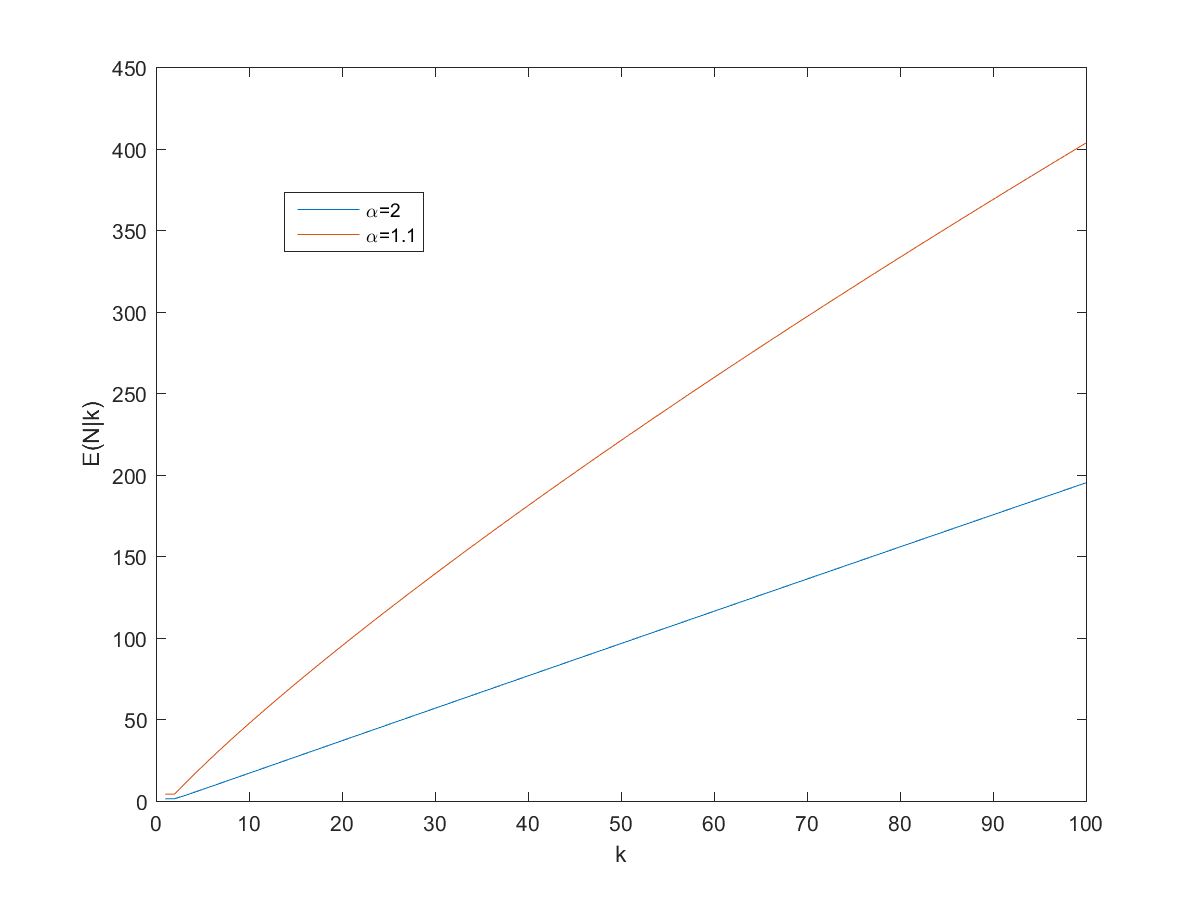
So, can we derive a useful rule of thumb for the expected number of pages? Dividing by ")
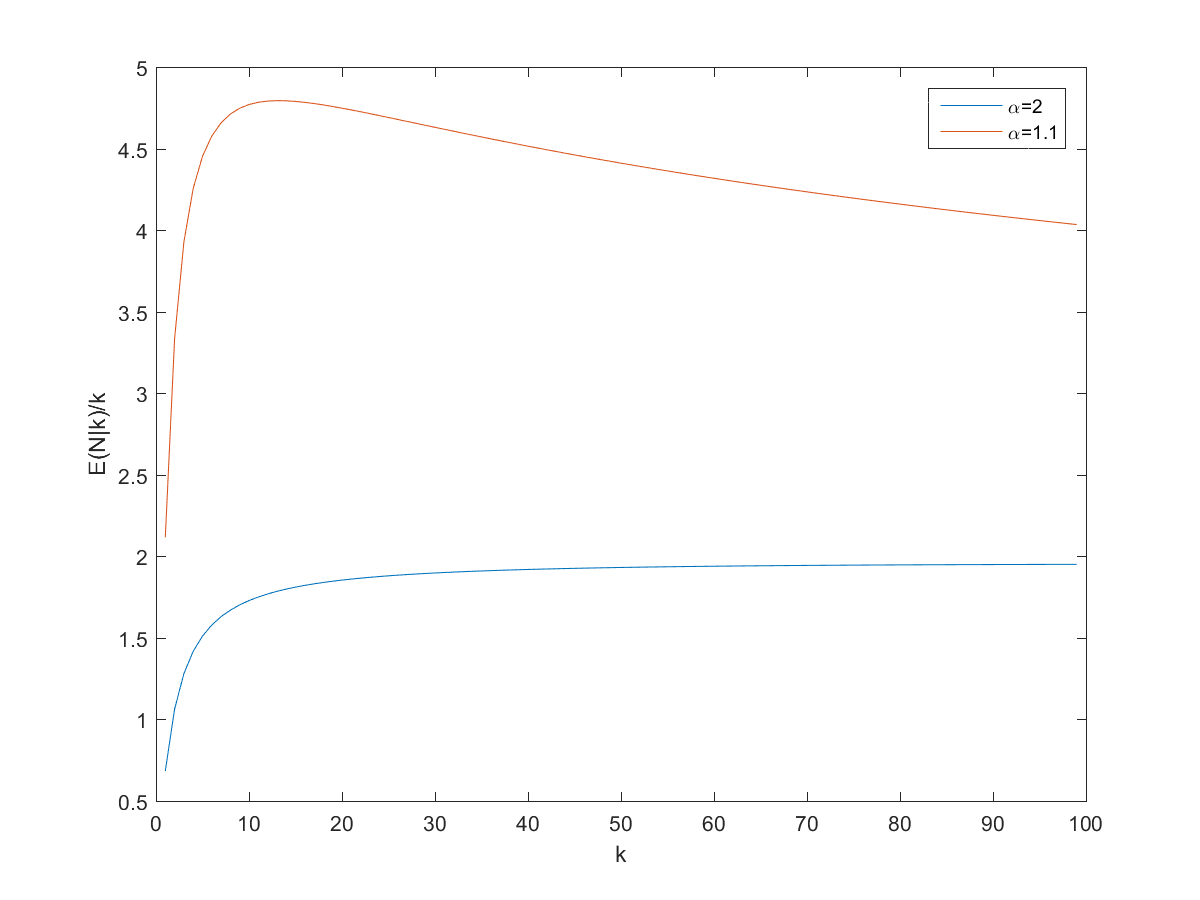
So a good rule of thumb is that if you get 

Bayes’ Broadsword
Yesterday I gave a talk at the joint Bloomberg-London Futurist meeting “The state of the future” about the future of decisionmaking. Parts were updates on my policymaking 2.0 talk (turned into this chapter), but I added a bit more about individual decisionmaking, rationality and forecasting.
The big idea of the talk: ensemble methods really work in a lot of cases. Not always, not perfectly, but they should be among the first tools to consider when trying to make a robust forecast or decision. They are Bayes’ broadsword:

Forecasting
One of my favourite experts on forecasting is J Scott Armstrong. He has stressed the importance of evidence based forecasting, including checking how well different methods work. The general answer is: not very well, yet people keep on using them. He has been pointing this out since the 70s. It also turns out that expertise only gets you so far: expert forecasts are not very reliable either, and the accuracy levels out quickly with increasing level of expertise. One implication is that one should at least get cheap experts since they are about as good as the pricey ones. It is also known that simple models for forecasting tends to be more accurate than complex ones, especially in complex and uncertain situations (see also Haldane’s “The Dog and the Frisbee”). Another important insight is that it is often better to combine different methods than try to select the one best method.
Another classic look at prediction accuracy is Philip Tetlock’s Expert Political Judgment (2005) where he looked at policy expert predictions. They were only slightly more accurate than chance, worse than basic extrapolation algorithms, and there was a negative link to fame: high profile experts have an incentive to be interesting and dramatic, but not right. However, he noticed some difference between “hedgehogs” (people with One Big Theory) and “foxes” (people using multiple theories), with the foxes outperforming hedgehogs.
OK, so in forecasting it looks like using multiple methods, theories and data sources (including experts) is a way to get better results.
Statistical machine learning
A standard problem in machine learning is to classify something into the right category from data, given a set of training examples. For example, given medical data such as age, sex, and blood test results, diagnose what a particular disease a patient might suffer from. The key problem is that it is non-trivial to construct a classifier that works well on data different from the training data. It can work badly on new data, even if it works perfectly on the training examples. Two classifiers that perform equally well during training may perform very differently in real life, or even for different data.
The obvious solution is to combine several classifiers and average (or vote about) their decisions: ensemble based systems. This reduces the risk of making a poor choice, and can in fact improve overall performance if they can specialize for different parts of the data. This also has other advantages: very large datasets can be split into manageable chunks that are used to train different components of the ensemble, tiny datasets can be “stretched” by random resampling to make an ensemble trained on subsets, outliers can be managed by “specialists”, in data fusion different types of data can be combined, and so on. Multiple weak classifiers can be combined into a strong classifier this way.
The method benefits from having diverse classifiers that are combined: if they are too similar in their judgements, there is no advantage. Estimating the right weights to give to them is also important, otherwise a truly bad classifier may influence the output.
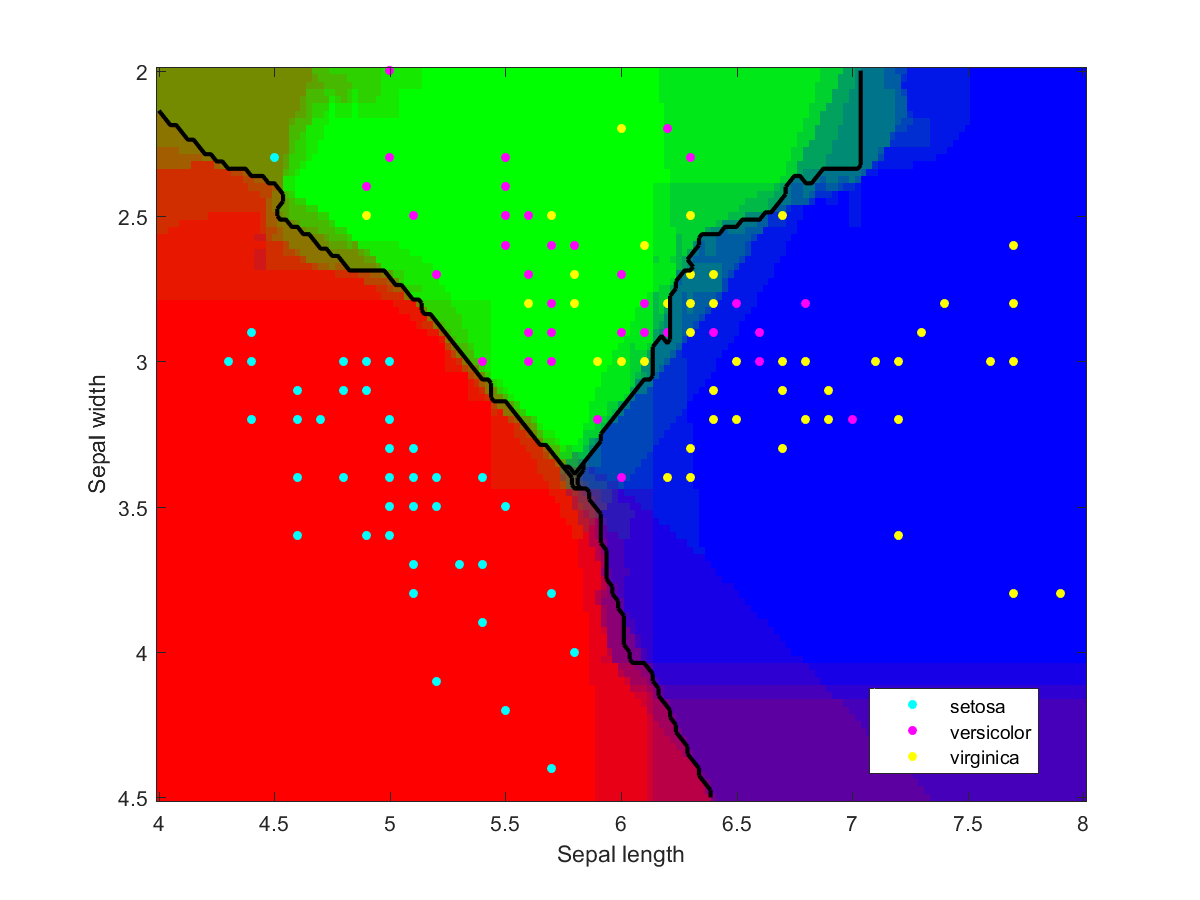
The iconic demonstration of the power of this approach was the Netflix Prize, where different teams competed to make algorithms that predicted user ratings of films from previous ratings. As part of the rules the algorithms were made public, spurring innovation. When the competition concluded in 2009, the leading teams all consisted of ensemble methods where component algorithms were from past teams. The two big lessons were (1) that a combination of not just the best algorithms, but also less accurate algorithms, were the key to winning, and (2) that organic organization allows the emergence of far better performance than having strictly isolated teams.
Group cognition
Condorcet’s jury theorem is perhaps the classic result in group problem solving: if a group of people hold a majority vote, and each has a probability p>1/2 of voting for the correct choice, then the probability the group will vote correctly is higher than p and will tend to approach 1 as the size of the group increases. This presupposes that votes are independent, although stronger forms of the theorem have been proven. (In reality people may have different preferences so there is no clear “right answer”)
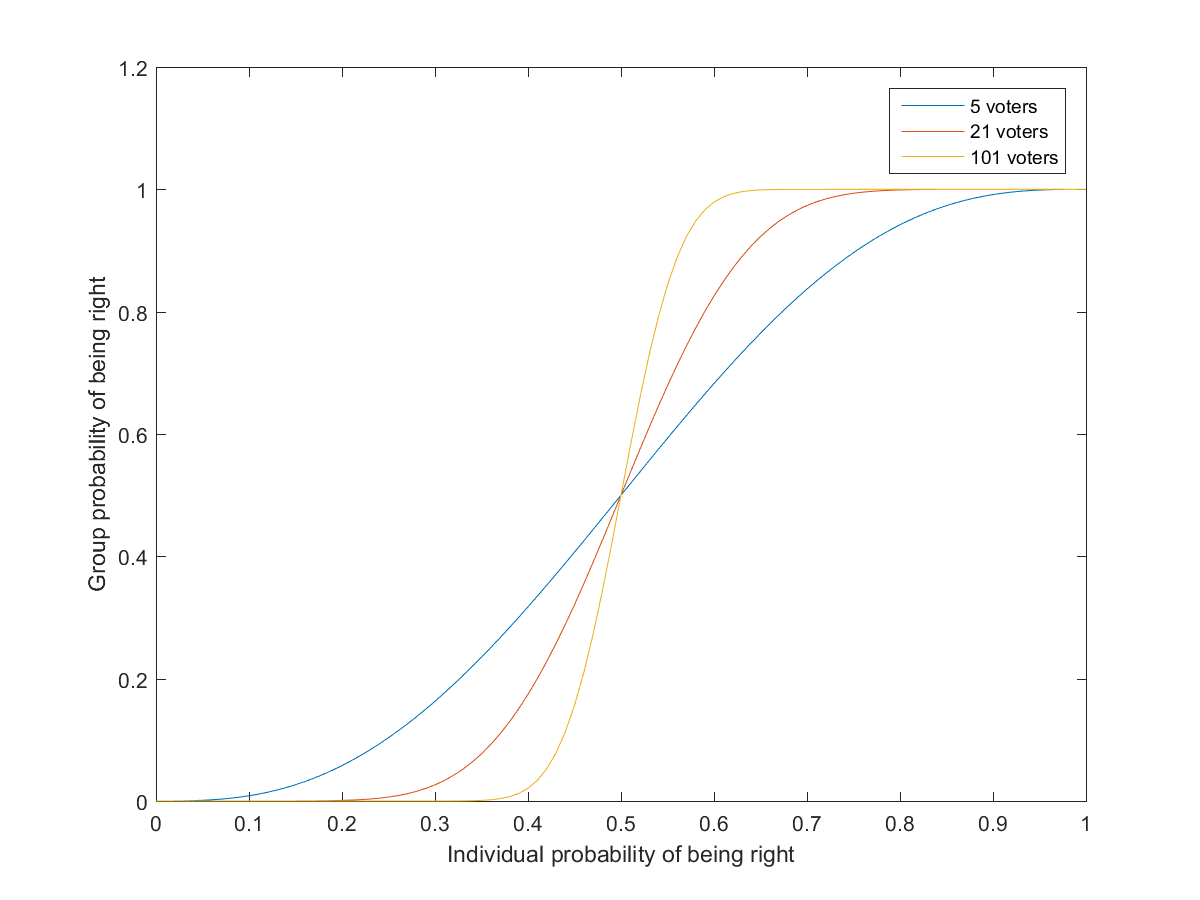
By now the pattern is likely pretty obvious. Weak decision-makers (the voters) are combined through a simple procedure (the vote) into better decision-makers.
Group problem solving is known to be pretty good at smoothing out individual biases and errors. In The Wisdom of Crowds Surowiecki suggests that the ideal crowd for answering a question in a distributed fashion has diversity of opinion, independence (each member has an opinion not determined by the other’s), decentralization (members can draw conclusions based on local knowledge), and the existence of a good aggregation process turning private judgements into a collective decision or answer.
Perhaps the grandest example of group problem solving is the scientific process, where peer review, replication, cumulative arguments, and other tools make error-prone and biased scientists produce a body of findings that over time robustly (if sometimes slowly) tends towards truth. This is anything but independent: sometimes a clever structure can improve performance. However, it can also induce all sorts of nontrivial pathologies – just consider the detrimental effects status games have on accuracy or focus on the important topics in science.
Small group problem solving on the other hand is known to be great for verifiable solutions (everybody can see that a proposal solves the problem), but unfortunately suffers when dealing with “wicked problems” lacking good problem or solution formulation. Groups also have scaling issues: a team of N people need to transmit information between all N(N-1)/2 pairs, which quickly becomes cumbersome.
One way of fixing these problems is using software and formal methods.
The Good Judgement Project (partially run by Tetlock and with Armstrong on the board of advisers) participated in the IARPA ACE program to try to improve intelligence forecasts. They used volunteers and checked their forecast accuracy (not just if they got things right, but if claims that something was 75% likely actually came true 75% of the time). This led to a plethora of fascinating results. First, accuracy scores based on the first 25 questions in the tournament predicted subsequent accuracy well: some people were consistently better than others, and it tended to remain constant. Training (such a debiasing techniques) and forming teams also improved performance. Most impressively, using the top 2% “superforecasters” in teams really outperformed the other variants. The superforecasters were a diverse group, smart but by no means geniuses, updating their beliefs frequently but in small steps.
The key to this success was that a computer- and statistics-aided process found the good forecasters and harnessed them properly (plus, the forecasts were on a shorter time horizon than the policy ones Tetlock analysed in his previous book: this both enables better forecasting, plus the all-important feedback on whether they worked).
Another good example is the Galaxy Zoo, an early crowd-sourcing project in galaxy classification (which in turn led to the Zooniverse citizen science project). It is not just that participants can act as weak classifiers and combined through a majority vote to become reliable classifiers of galaxy type. Since the type of some galaxies is agreed on by domain experts they can used to test the reliability of participants, producing better weightings. But it is possible to go further, and classify the biases of participants to create combinations that maximize the benefit, for example by using overly “trigger happy” participants to find possible rare things of interest, and then check them using both conservative and neutral participants to become certain. Even better, this can be done dynamically as people slowly gain skill or change preferences.
The right kind of software and on-line “institutions” can shape people’s behavior so that they form more effective joint cognition than they ever could individually.
Conclusions
The big idea here is that it does not matter that individual experts, forecasting methods, classifiers or team members are fallible or biased, if their contributions can be combined in such a way that the overall output is robust and less biased. Ensemble methods are examples of this.
While just voting or weighing everybody equally is a decent start, performance can be significantly improved by linking it to how well the participants perform. Humans can easily be motivated by scoring (but look out for disalignment of incentives: the score must accurately reflect real performance and must not be gameable).
In any case, actual performance must be measured. If we cannot tell if some method is more accurate than something else, then either accuracy does not matter (because it cannot be distinguished or we do not really care), or we will not get the necessary feedback to improve it. It is known from the expertise literature that one of the key factors for it to be possible to become an expert on a task is feedback.
Having a flexible structure that can change is a good approach to handling a changing world. If people have disincentives to change their mind or change teams, they will not update beliefs accurately.
I got a good question after the talk: if we are supposed to keep our models simple, how can we use these complicated ensembles? The answer is of course that there is a difference between using a complex and a complicated approach. The methods that tend to be fragile are the ones with too many free parameters, too much theoretical burden: they are the complex “hedgehogs”. But stringing together a lot of methods and weighting them appropriately merely produces a complicated model, a “fox”. Component hedgehogs are fine as long as they are weighed according to how well they actually perform.
(In fact, adding together many complex things can make the whole simpler. My favourite example is the fact that the Kolmogorov complexity of integers grows boundlessly on average, yet the complexity of the set of all integers is small – and actually smaller than some integers we can easily name. The whole can be simpler than its parts.)
In the end, we are trading Occam’s razor for a more robust tool: Bayes’ Broadsword. It might require far more strength (computing power/human interaction) to wield, but it has longer reach. And it hits hard.
Appendix: individual classifiers
I used Matlab to make the illustration of the ensemble classification. Here are some of the component classifiers. They are all based on the examples in the Matlab documentation. My ensemble classifier is merely a maximum vote between the component classifiers that assign a class to each point.
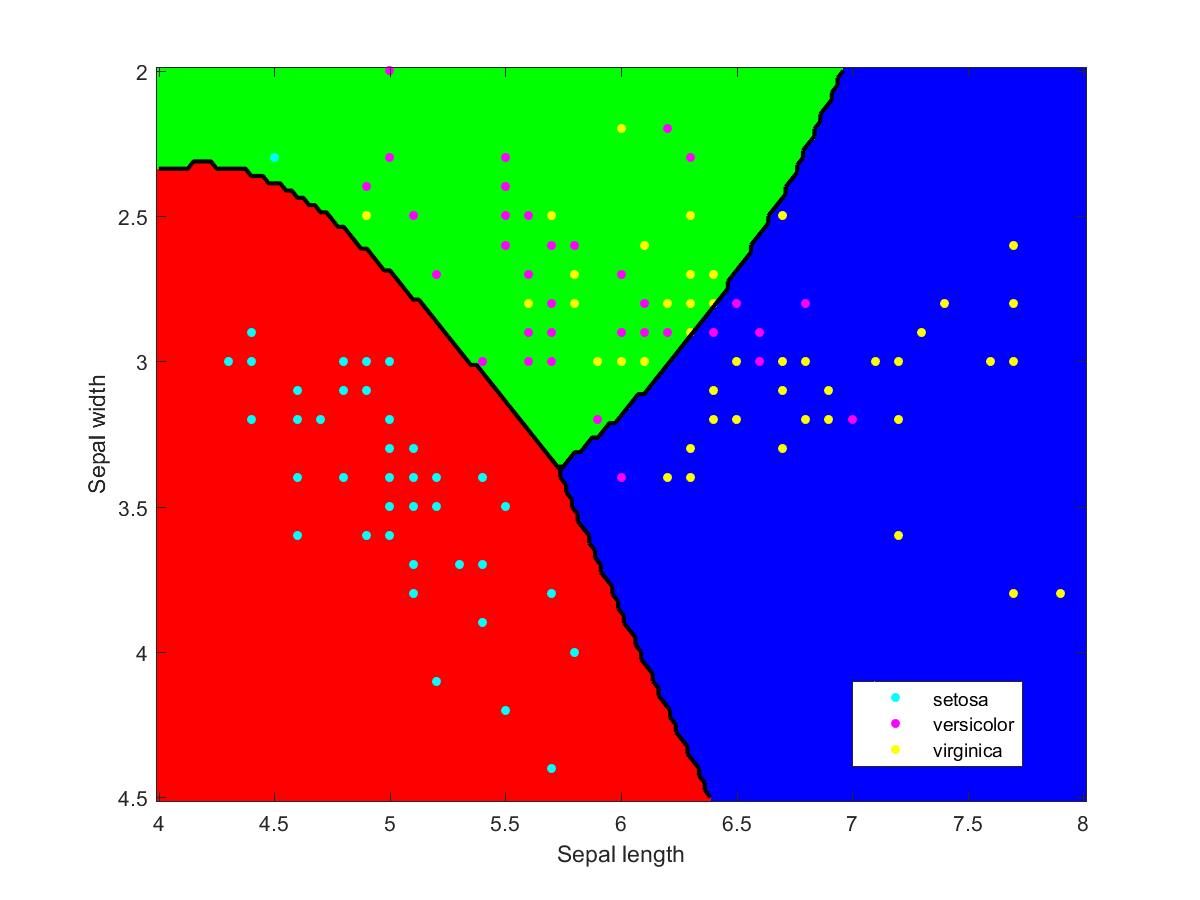
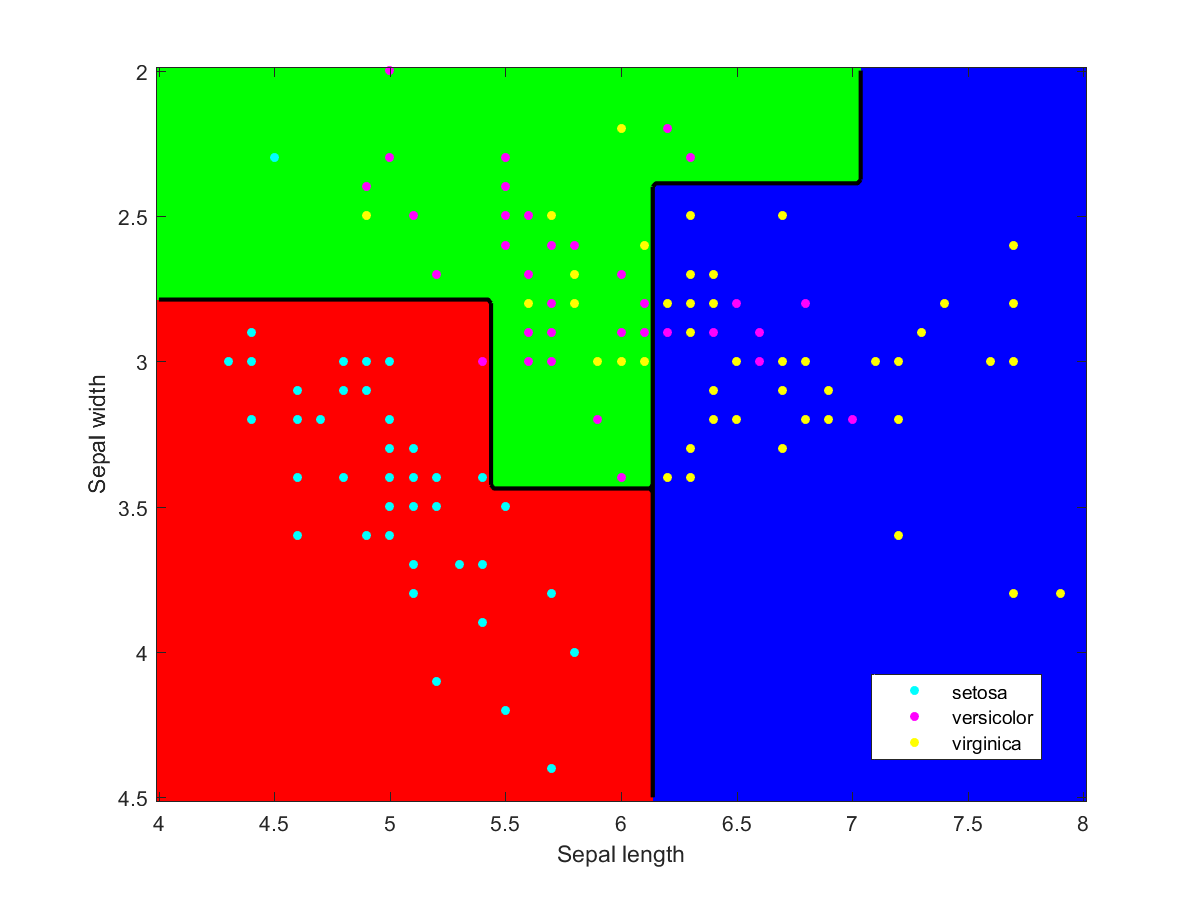
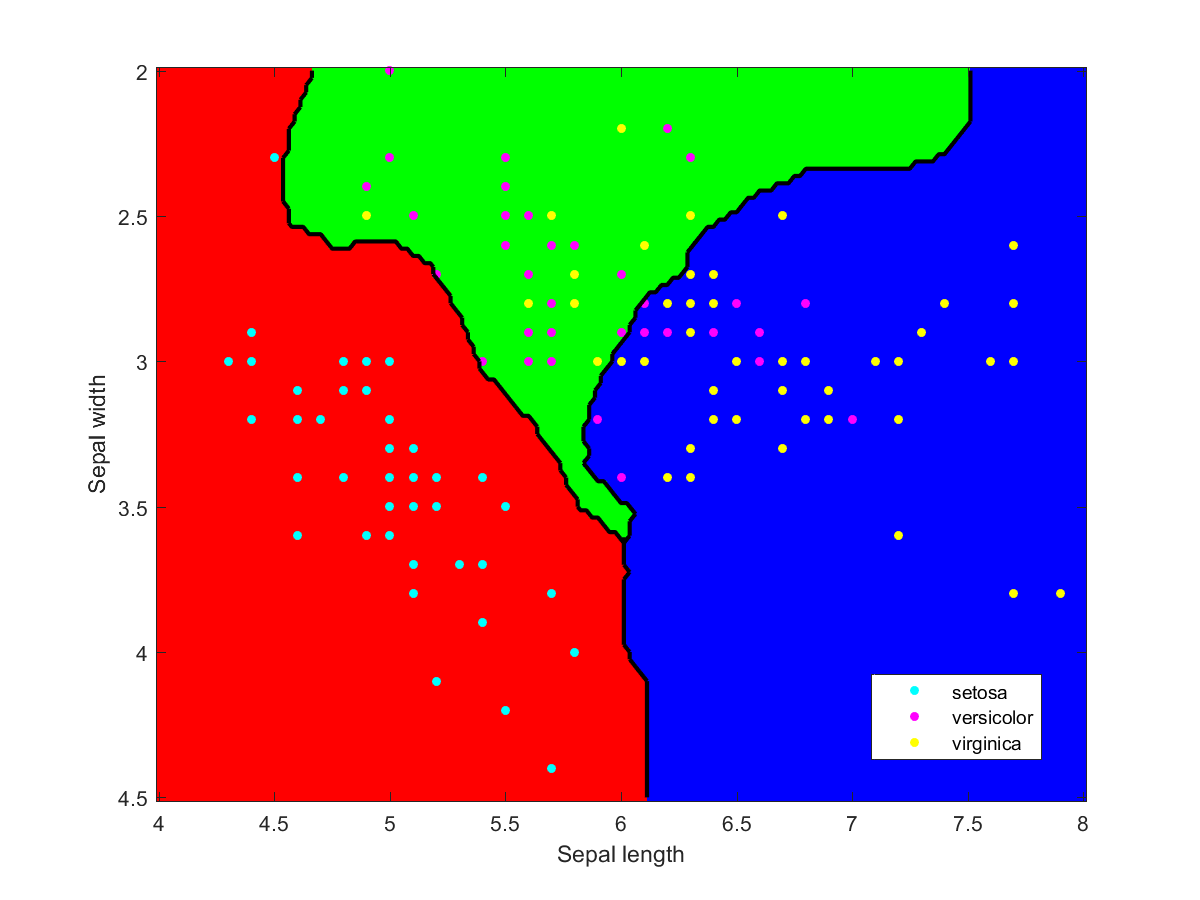
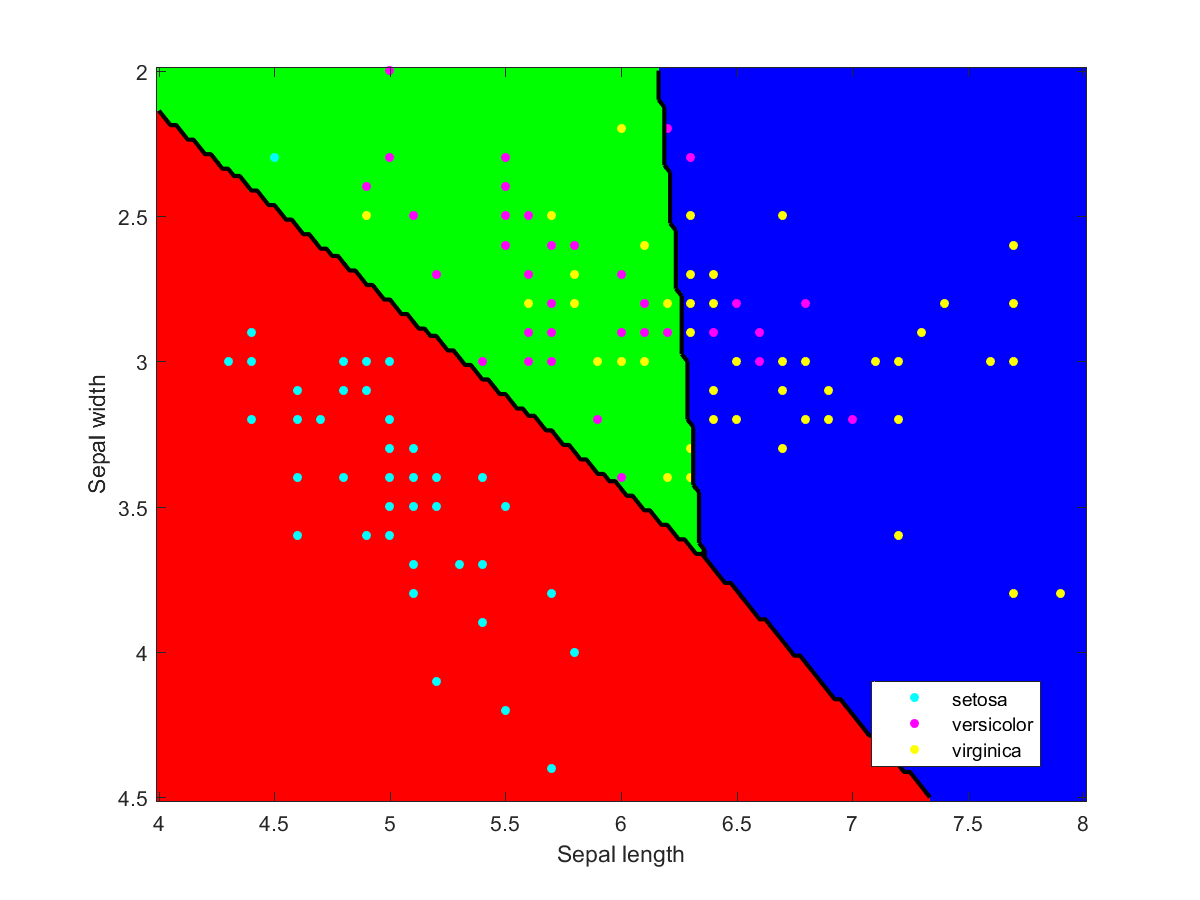
All models are wrong, some are useful – but how can you tell?
 Our whitepaper about the systemic risk of risk modelling is now out. The topic is how the risk modelling process can make things worse – and ways of improving things. Cognitive bias meets model risk and social epistemology.
Our whitepaper about the systemic risk of risk modelling is now out. The topic is how the risk modelling process can make things worse – and ways of improving things. Cognitive bias meets model risk and social epistemology.
The basic story is that in insurance (and many other domains) people use statistical models to estimate risk, and then use these estimates plus human insight to come up with prices and decisions. It is well known (at least in insurance) that there is a measure of model risk due to the models not being perfect images of reality; ideally the users will take this into account. However, in reality (1) people tend to be swayed by models, (2) they suffer from various individual and collective cognitive biases making their model usage imperfect and correlates their errors, (3) the markets for models, industrial competition and regulation leads to fewer models being used than there could be. Together this creates a systemic risk: everybody makes correlated mistakes and decisions, which means that when a bad surprise happens – a big exogenous shock like a natural disaster or a burst of hyperinflation, or some endogenous trouble like a reinsurance spiral or financial bubble – the joint risk of a large chunk of the industry failing is much higher than it would have been if everybody had had independent, uncorrelated models. Cue bailouts or skyscrapers for sale.
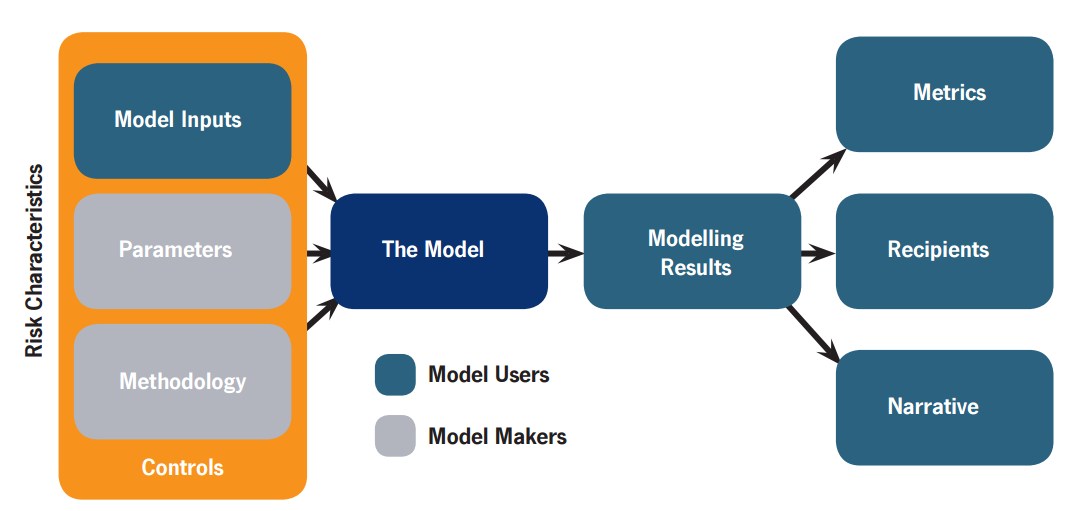 Note that this is a generic problem. Insurance is just unusually self-aware about its limitations (a side effect of convincing everybody else that Bad Things Happen, not to mention seeing the rest of the financial industry running into major trouble). When we use models the model itself (the statistics and software) is just one part: the data fed into the model, the processes of building and tuning the model, how people use it in their everyday work, how the output leads to decisions, and how the eventual outcomes become feedback to the people involved – all of these factors are important parts in making model use useful. If there is no or too slow feedback people will not learn what behaviours are correct or not. If there are weak incentives to check errors of one type, but strong incentives for other errors, expect the system to become biased towards one side. It applies to climate models and military war-games too.
Note that this is a generic problem. Insurance is just unusually self-aware about its limitations (a side effect of convincing everybody else that Bad Things Happen, not to mention seeing the rest of the financial industry running into major trouble). When we use models the model itself (the statistics and software) is just one part: the data fed into the model, the processes of building and tuning the model, how people use it in their everyday work, how the output leads to decisions, and how the eventual outcomes become feedback to the people involved – all of these factors are important parts in making model use useful. If there is no or too slow feedback people will not learn what behaviours are correct or not. If there are weak incentives to check errors of one type, but strong incentives for other errors, expect the system to become biased towards one side. It applies to climate models and military war-games too.
The key thing is to recognize that model usefulness is not something that is directly apparent: it requires a fair bit of expertise to evaluate, and that expertise is also not trivial to recognize or gain. We often compare models to other models rather than reality, and a successful career in predicting risk may actually be nothing more than good luck in avoiding rare but disastrous events.
What can we do about it? We suggest a scorecard as a first step: comparing oneself to some ideal modelling process is a good way of noticing where one could find room for improvement. The score does not matter as much as digging into one’s processes and seeing whether they have cruft that needs to be fixed – whether it is following standards mindlessly, employees not speaking up, basing decisions on single models rather than more broad views of risk, or having regulators push one into the same direction as everybody else. Fixing it may of course be tricky: just telling people to be less biased or to do extra error checking will not work, it has to be integrated into the organisation. But recognizing that there may be a problem and getting people on board is a great start.
In the end, systemic risk is everybody’s problem.

Halloween explanation of Fermi question

John Harris proposed a radical solution to the KIC 8462852 problem: it is a Halloween pumpkin.
A full Dyson sphere does not have to be 100% opaque. It consists of independently orbiting energy collectors, presumably big flat surfaces. But such collectors can turn their thin side towards the star, letting past starlight. So with the right program, your Dyson sphere could project any pattern of light like a lantern.
Of course, the real implication of this is that we should watch out for trick-or-treating alien super-civilizations. By using self-replicating Bracewell probes they could spread across the Milky way within a few million years: they ought to be here by now. And in this scenario they are… they are just hiding until KIC 8462852 suddenly turns into a skull, and suddenly the skies will swarming with their saucers demanding we give them treats – or suffer their tricks…
There is just one problem: when is galactic Halloween? A galactic year is 250 million years. We have a 1/365 chance of being in the galactic “day” corresponding to Halloween (itself 680,000 years long). We might be in for a long night…
Likely not even a microDyson
 Right now KIC 8462852 is really hot, and not just because it is a F3 V/IV type star: the light curve, as measured by Kepler, has irregular dips that looks like something (or rather, several somethings) are obscuring the star. The shapes of the dips are odd. The system is too old and IR-clean to have a remaining protoplanetary disk, dust clumps would coalesce, the aftermath of a giant planet impact is very unlikely (and hard to fit with the aperiodicity); maybe there is a storm of comets due to a recent stellar encounter, but comets are not very good at obscuring stars. So a lot of people on the net are quietly or not so quietly thinking that just maybe this is a Dyson sphere under construction.
Right now KIC 8462852 is really hot, and not just because it is a F3 V/IV type star: the light curve, as measured by Kepler, has irregular dips that looks like something (or rather, several somethings) are obscuring the star. The shapes of the dips are odd. The system is too old and IR-clean to have a remaining protoplanetary disk, dust clumps would coalesce, the aftermath of a giant planet impact is very unlikely (and hard to fit with the aperiodicity); maybe there is a storm of comets due to a recent stellar encounter, but comets are not very good at obscuring stars. So a lot of people on the net are quietly or not so quietly thinking that just maybe this is a Dyson sphere under construction.
I doubt it.
My basic argument is this: if a civilization builds a Dyson sphere it is unlikely to remain small for a long period of time. Just as planetary collisions are so rare that we should not expect to see any in the Kepler field, the time it takes to make a Dyson sphere is also very short: seeing it during construction is very unlikely.
Fast enshrouding
In my and Stuart Armstrong’s paper “Eternity in Six Hours” we calculated that disassembling Mercury to make a partial Dyson shell could be done in 31 years. We did not try to push things here: our aim was to show that using a small fraction of the resources in the solar system it is possible to harness enough energy to launch a massive space colonization effort (literally reaching every reachable galaxy, eventually each solar system). Using energy from already built solar captors more material is mined and launched, producing an exponential feedback loop. This was originally discussed by Robert Bradbury. The time to disassemble terrestrial planets is not much longer than for Mercury, while the gas giants would take a few centuries.
If we imagine the history of a F5 star 1,000 years is not much. Given the estimated mass of KIC 8462852 as 1.46 solar masses, it will have a main sequence lifespan of 4.1 billion years. The chance of seeing it while being enshrouded is one in 4.3 million. This is the same problem as the giant impact theory.
A ruin?
An abandoned Dyson shell would likely start clumping together; this might at first sound like a promising – if depressing – explanation of the observation. But the timescale is likely faster than planetary formation timescales of 

But it is indeed more likely to see the decay of the shell than the construction by several orders of magnitude. Just like normal ruins hang around far longer than the time it took to build the original building.
Laid-back aliens?
Maybe the aliens are not pushing things? Obviously one can build a Dyson shell very slowly – in a sense we are doing it (and disassembling Earth to a tiny extent!) by launching satellites one by one. So if an alien civilization wanted to grow at a leisurely rate or just needed a bit of Dyson shell they could of course do it.
However, if you need something like 
In order to get a reasonably high probability of seeing an incomplete shell we need to assume growth rates that are exceedingly small (on the order of less than a millionth per year). While it is not impossible, given how the trend seems to be towards more intense energy use in many systems and that entities with higher growth rates will tend to dominate a population, it seems rather unlikely. Of course, one can argue that we currently can more easily detect the rare laid-back civilizations than the ones that aggressively enshrouded their stars, but Dyson spheres do look pretty rare.
Other uses?
Dyson shells are not the only megastructures that could cause intriguing transits.
C. R. McInnes has a suite of fun papers looking at various kinds of light-related megastructures. One can sort asteroid material using light pressure, engineer climate, adjust planetary orbits, and of course travel using solar sails. Most of these are smallish compared to stars (and in many cases dust clouds), but they show some of the utility of obscuring objects.
Duncan Forgan has a paper on detecting stellar engines (Shkadov thrusters) using light curves; unfortunately the calculated curves do not fit KIC8462852 as far as I can tell.
Luc Arnold analysed the light curves produced by various shapes of artificial objects. He suggested that one could make a weirdly shaped mask for signalling one’s presence using transits. In principle one could make nearly any shape, but for signalling something unusual yet simple enough to be artificial would make most sense: I doubt the KIC transits fit this.
More research is needed (duh)
In the end, we need more data. I suspect we will find that it is yet another odd natural phenomenon or coincidence. But it makes sense to watch, just in case.
Were we to learn that there is (or was) a technological civilization acting on a grand scale it would be immensely reassuring: we would know intelligent life could survive for at least some sizeable time. This is the opposite side of the Great Filter argument for why we should hope not to see any extraterrestrial life: life without intelligence is evidence for intelligence either being rare or transient, but somewhat non-transient intelligence in our backyard (just 1,500 light-years away!) is evidence that it is neither rare nor transient. Which is good news, unless we fancy ourselves as unique and burdened by being stewards of the entire reachable universe.
But I think we will instead learn that the ordinary processes of astrophysics can produce weird transit curves, perhaps due to weird objects (remember when we thought hot jupiters were exotic?) The universe is full of strange things, which makes me happy I live in it.
[An edited version of this post can be found at The Conversation: What are the odds of an alien megastructure blocking light from a distant star? ]
Time travel system
By Stuart Armstrong
Introduction
I’ve been looking to develop a system of time travel in which it’s possible to actually have a proper time war. To make it consistent and interesting, I’ve listed some requirements here. I think I have a fun system that obeys them all.
Time travel/time war requirement:
- It’s possible to change the past (and the future). These changes don’t just vanish.
- It’s useful to travel both forwards and backwards in time.
- You can’t win by just rushing back to the Big Bang, or to the end of the universe.
- There’s no “orthogonal time” that time travellers follow; I can’t be leaving 2015 to go to 1502 “while” you’re leaving 3015 to arrive at the same place.
- You can learn about the rules of time travel while doing it; however, time travel must be dangerous to the ignorant (and not just because machines could blow up, or locals could kill you).
- No restrictions that make no physical sense, or that could be got round by a human or a robot with half a brain. Eg: “you can’t make a second time jump from the arrival point of a first.” However, a robot could build a second copy of a time machine and of itself, and that could then jump back; therefore that initial restriction doesn’t make any particular sense.
- Similarly, no restrictions that are unphysical or purely narrative.
- It must be useful to, for instance, leave arrays of computers calculating things for you then jumping to the end to get the answer.
- Ideally, there would be only one timeline. If there are parallel universes, they must be simply describable, and allow time-travellers to interact with each other in ways they would care about.
- A variety of different strategies must be possible for fighting the war.
Consistent time travel
Earlier, I listed some requirements for a system of time travel – mainly that it be both scientifically consistent and open to interesting conflicts that aren’t trivially one-sided. Here is my proposal for such a thing, within the general relativity format.
So, suppose you build a time machine, and want to go back in time to kill Hitler, as one does. Your time machine is a 10m diameter sphere, which exchanges place with a similarly-size sphere in 1930. What happens then? The graph here shows the time jump, and the “light-cones” for the departure (blue) and arrival (red) points; under the normal rules of causality, the blue point can only affect things in the grey cone, the red point can only affect things in the black cone.
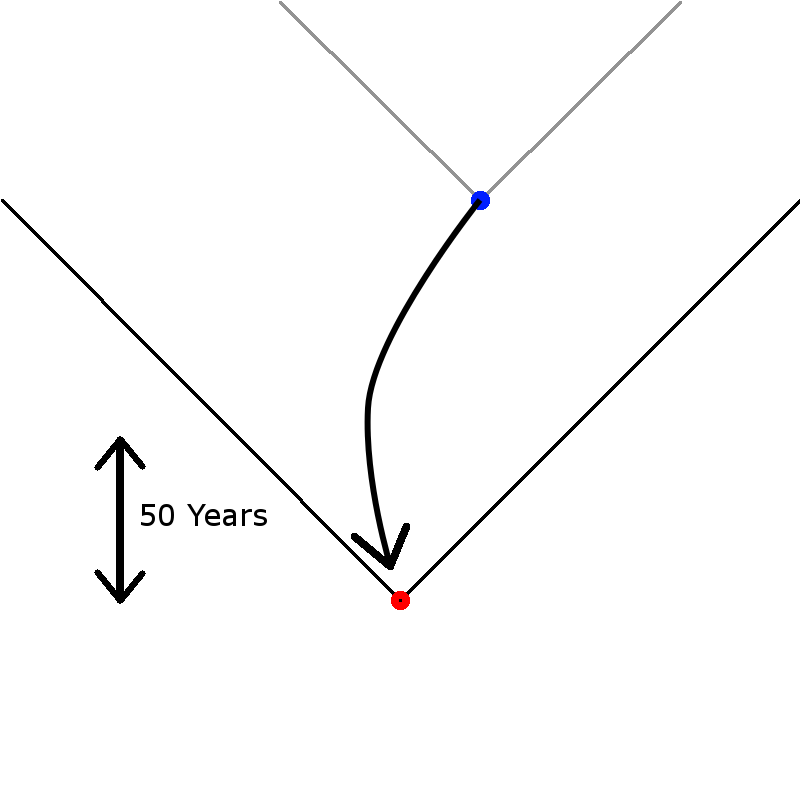 The basic idea is that when you do a time jump like this, then you “fix” your points of departure and arrival. Hence the blue and red points cannot be changed, and the universe rearranges itself to ensure this. The big bang itself is also a fixed point.
The basic idea is that when you do a time jump like this, then you “fix” your points of departure and arrival. Hence the blue and red points cannot be changed, and the universe rearranges itself to ensure this. The big bang itself is also a fixed point.
All this “fixed point” idea is connected to entropy. Basically, we feel that time advances in one direction rather than the other. Many have argued that this is because entropy (roughly, disorder) increases in one direction, and that this direction points from the past to the future. Since most laws of physics are symmetric in the past and the future, I prefer to think of this as “every law of physics is time-symmetric, but the big bang is a fixed point of low entropy, hence the entropy increase as we go away from it.”
But here I’m introducing two other fixed points. What will that do?
Well, initially, not much. You go back into time, and kill Hitler, and the second world war doesn’t happen (or maybe there’s a big war of most of Europe against the USSR, see configuration 2 in “A Landscape Theory of Aggregation”). Yay! That’s because, close to the red point, causality works pretty much as you’d expect.
However, close to the blue point, things are different.

Here, the universe starts to rearrange things so that the blue point is unchanged. Causality isn’t exactly going backwards, but it is being funnelled in a particular direction. People who descended from others who “should have died” in WW2 start suddenly dying off. Memories shift; records change. By the time you’re very close to the blue point, the world is essentially identical to what it would have been had there been no time travelling.
Does this mean that you time jump made no difference? Not at all. The blue fixed point only constrains what happens in the light cone behind it (hence the red-to-blue rectangle in the picture). Things outside the rectangle are unconstrained – in particular, the future of that rectangle. Now, close to the blue point, the events are “blue” (ie similar to the standard history), so the future of those events are also pretty blue (similar to what would have been without the time jump) – see the blue arrows. At the edge of the rectangle, however, the events are pretty red (the alternative timeline), so the future is also pretty red (ie changed) – see the red arrows. If the influence of the red areas converges back in to the centre, the future will be radically different.
(some people might wonder why there aren’t “changing arrows” extending form the rectangle into the past as well as the future. There might be, but remember we have a fixed point at the big bang, which reduces the impact of these backward changes – and the red point is also fixed, exerting a strong stabilising influence for events in its own backwards light-cone).
So by time travelling, you can change the past, and you can change part of the future – but you can’t change the present.
But what would happen if you stayed alive from 1930, waiting and witnessing history up to the blue point again? This would be very dangerous; to illustrate, let’s change the scale, and assume we’ve only jumped a few minutes into the past.
 Maybe there you meet your past self, have a conversation about how wise you are, try and have sex with yourself, or whatever time travellers do with past copies of themselves. But this is highly dangerous! Within a few minutes, all trace of future you’s presesence will be gone; you past self will have no memory of it, there will be no physical or mental evidence remaining.
Maybe there you meet your past self, have a conversation about how wise you are, try and have sex with yourself, or whatever time travellers do with past copies of themselves. But this is highly dangerous! Within a few minutes, all trace of future you’s presesence will be gone; you past self will have no memory of it, there will be no physical or mental evidence remaining.
Obviously this is very dangerous for you! The easiest way for there to remain no evidence of you, is for there to be no you. You might say “but what if I do this, or try and do that, or…” But all your plans will fail. You are fighting against causality itself. As you get closer to the blue dot, it’s as if time itself was running backwards, erasing your new timeline, to restore the old one. Cleverness can’t protect you against an inversion of causality.
Your only real chance of survival (unless you do a second time jump to get out of there) is to rush away from the red point at near light-speed, getting yourself to the edge of the rectangle and ejecting yourself from the past of the blue point.
Right, that’s the basic idea!
Multiple time travellers
Ok, the previous section looked at a single time traveller. What happens when there are several? Say two time travellers (blue and green) are both trying to get to the red point (or places close to it). Who gets there “first”?
 Here is where I define the second important concept for time-travel, that of “priority”. Quite simply, a point with higher priority is fixed relative to the other. For instance, imagine that the blue and green time travellers appear in close proximity to each other:
Here is where I define the second important concept for time-travel, that of “priority”. Quite simply, a point with higher priority is fixed relative to the other. For instance, imagine that the blue and green time travellers appear in close proximity to each other:
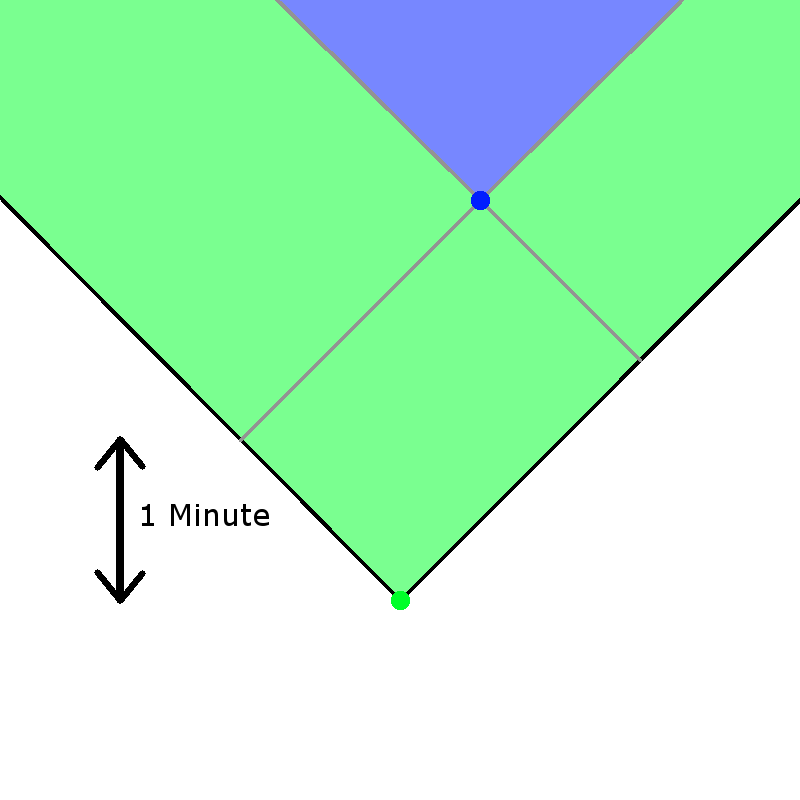
This is a picture where the green time traveller has a higher priority than the blue one. The green arrival changes the timeline (the green cone) and the blue time traveller fits themselves into this new timeline.
If instead the blue traveller had higher priority, we get the following scenario:
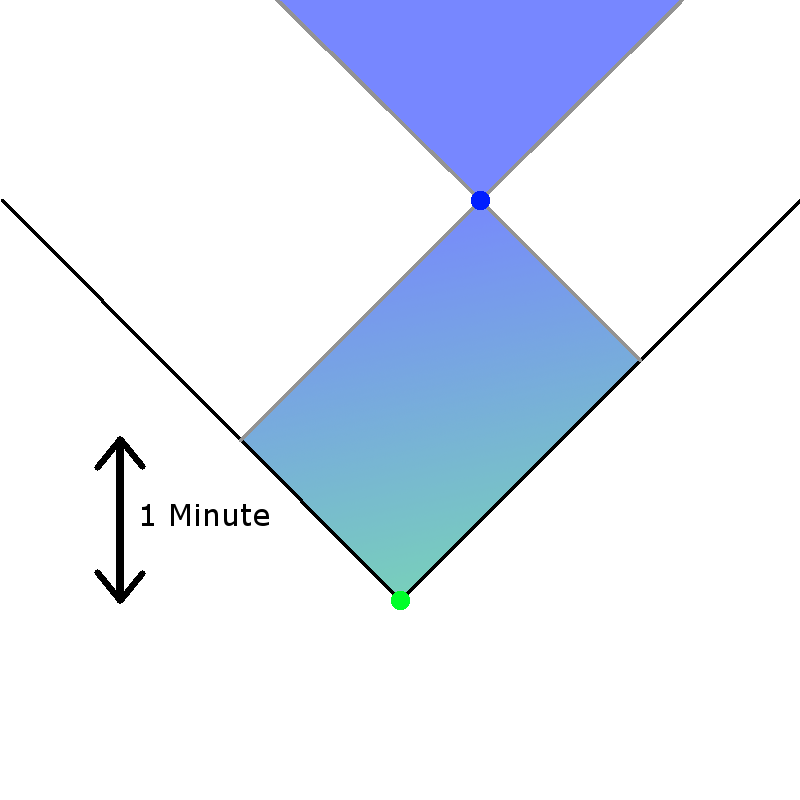
Here the blue traveller arrives in the original (white) timeline, fixing their arrival point. The green time traveller arrives, and generates their own future – but this has to be put back into the first white timeline for the arrival of the blue time traveller.
Being close to a time traveller with a high priority is thus very dangerous! The green time traveller may get erased if they don’t flee-at-almost-light-speed.
Even arriving after a higher-priority time traveller is very dangerous – suppose that the green one has higher priority, and the blue one arrives after. Then suppose the green one realises they’re not exactly at the right place, and jump forwards a bit; then you get:
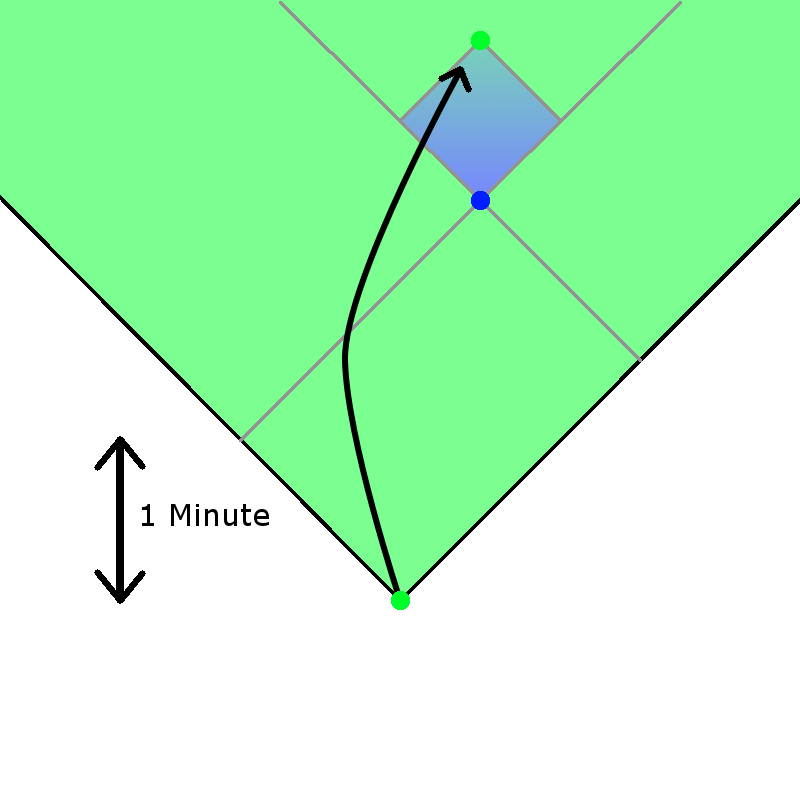 (there’s another reason arriving after a higher priority time traveller is dangerous, as we’ll see).
(there’s another reason arriving after a higher priority time traveller is dangerous, as we’ll see).
So how do we determine priority? The simplest seems time-space distance. You start with a priority of zero, and this priority goes down proportional to how far your jump goes.
What about doing a lot of short jumps? You don’t want to allow green to get higher priority by doing a series of jumps: This picture suggests how to proceed. Your first jump brings you a priority of -70. Then the second adds a second penalty of -70, bringing the priority penalty to -140 (the yellow point is another time traveller, who will be relevant soon)
This picture suggests how to proceed. Your first jump brings you a priority of -70. Then the second adds a second penalty of -70, bringing the priority penalty to -140 (the yellow point is another time traveller, who will be relevant soon)
How can we formalise this? Well, a second jump is a time jump that would not happen if the first jump hadn’t. So for each arrival in a time jump, you can trace it back to the original jump-point. Then your priority score is the (negative) of the volume of the time-space cone determined by the arrival and original jump-point. Since this volume is the point where your influence is strongest, this makes sense (note for those who study special relativity: using this volume means that you can’t jump “left along a light-beam”, then “right along a light-beam” and arrive with a priority of 0, which you could do if we used distance travelled rather than volume).
Let’s look at that yellow time traveller again. If there was no other time traveller, they would jump from that place. But because of the arrival of the green traveller (at -70), the ripples cause them to leave from a different point in space time, the purple one (the red arrow shows that the arrival there prevents the green time jump, and cause the purple time jump): So what happens? Well, the yellow time jump will still happen. It has a priority of 0 (it happened without any influence of any time traveller), so the green arrival at -70 priority can’t change this fixed point. The purple time jump will also happen, but it will happen with a lower priority of -30, since it was caused by time jumps that can ultimately be traced back to the green 0 point. (note: I’m unsure whether there’s any problem with allowing priority to rise as you get back closer to your point of origin; you might prefer to use the smallest cone that includes all jump points that affected you, so the purple point would have priority -70, just like the green point that brought it into existence).
So what happens? Well, the yellow time jump will still happen. It has a priority of 0 (it happened without any influence of any time traveller), so the green arrival at -70 priority can’t change this fixed point. The purple time jump will also happen, but it will happen with a lower priority of -30, since it was caused by time jumps that can ultimately be traced back to the green 0 point. (note: I’m unsure whether there’s any problem with allowing priority to rise as you get back closer to your point of origin; you might prefer to use the smallest cone that includes all jump points that affected you, so the purple point would have priority -70, just like the green point that brought it into existence).
What other differences could there be between the yellow and the purple version? Well, for one, the yellow has no time jumps in their subjective pasts, while the purple has one – the green -70. So as time travellers wiz around, they create (potential) duplicate copies of themselves and other time travellers – but those with the highest priority, and hence the highest power, are those who have no evidence that time jumps work, and do short jumps. As your knowledge of time travel goes up, and as you explore more, your priority sinks, and you become more vulnerable.
So it’s very dangerous even having a conversation with someone of higher priority than yourself! Suppose Mr X talks with Mrs Y, who has higher priority than him. Any decision that Y does subsequently has been affected by that conversation, so her priority sinks to X’s level (call her Y’). But now imagine that, if she wouldn’t have had that conversation, she would have done another time jump anyway. The Y who didn’t have the conversation is not affected by X, so retains her higher priority.
So, imagine that Y would have done another time jump a few minutes after arrival. X arrives and convinces her not to do so (maybe there’s a good reason for that). But the “time jump in an hour” will still happen, because the unaffected Y has higher priority, and X can’t change that. So if the X and Y’ talk or linger too long, they run the risk of getting erased as they get close to the “point where Y would have jumped if X hadn’t been there”. In graphical form, the blue-to-green square is the area in which X and Y’ can operate in, unless they can escape into the white bands: So the greatest challenge for a low priority time-traveller is to use their knowledge to evade erasure by higher priority ones. They have a much better understanding of what’s going on, they may know where other time jumps likely end up at or start, they might have experience at “rushing at light speed to get out of cone of danger while preserving most of their personality and memories” (or technology that helps them do so), but they are ever vulnerable. They can kill or influence higher priority time-travellers, but this will only work “until” the point where they would have done a time jump otherwise (and the cone before that point).
So the greatest challenge for a low priority time-traveller is to use their knowledge to evade erasure by higher priority ones. They have a much better understanding of what’s going on, they may know where other time jumps likely end up at or start, they might have experience at “rushing at light speed to get out of cone of danger while preserving most of their personality and memories” (or technology that helps them do so), but they are ever vulnerable. They can kill or influence higher priority time-travellers, but this will only work “until” the point where they would have done a time jump otherwise (and the cone before that point).
So, have I succeeded in creating an interesting time-travel design? Is it broken in any obvious way? Can you imagine interesting stories and conflicts being fought there?
The Biosphere Code
 Yesterday I contributed to a piece of manifesto writing, producing the Biosphere Code Manifesto. The Guardian has a version on its blog. Not quite as dramatic as Marinetti’s Futurist Manifesto but perhaps more constructive:
Yesterday I contributed to a piece of manifesto writing, producing the Biosphere Code Manifesto. The Guardian has a version on its blog. Not quite as dramatic as Marinetti’s Futurist Manifesto but perhaps more constructive:
Principle 1. With great algorithmic powers come great responsibilities
Those implementing and using algorithms should consider the impacts of their algorithms.
Principle 2. Algorithms should serve humanity and the biosphere at large.
Algorithms should be considerate of human needs and the biosphere, and facilitate transformations towards sustainability by supporting ecologically responsible innovation.
Principle 3. The benefits and risks of algorithms should be distributed fairly
Algorithm developers should consider issues relating to the distribution of risks and opportunities more seriously. Developing algorithms that provide benefits to the few and present risks to the many are both unjust and unfair.
Principle 4. Algorithms should be flexible, adaptive and context-aware
Algorithms should be open, malleable and easy to reprogram if serious repercussions or unexpected results emerge. Algorithms should be aware of their external effects and be able to adapt to unforeseen changes.
Principle 5. Algorithms should help us expect the unexpected
Algorithms should be used in such a way that they enhance our shared capacity to deal with shocks and surprises – including problems caused by errors or misbehaviors in other algorithms.
Principle 6. Algorithmic data collection should be open and meaningful
Data collection should be transparent and respectful of public privacy. In order to avoid hidden biases, the datasets which feed into algorithms should be validated.
Principle 7. Algorithms should be inspiring, playful and beautiful
Algorithms should be used to enhance human creativity and playfulness, and to create new kinds of art. We should encourage algorithms that facilitate human collaboration, interaction and engagement – with each other, with society, and with nature.
The algorithmic world
 The basic insight is that the geosphere, ecosphere, anthroposphere and technosphere are getting deeply entwined, and algorithms are becoming a key force in regulating this global system.
The basic insight is that the geosphere, ecosphere, anthroposphere and technosphere are getting deeply entwined, and algorithms are becoming a key force in regulating this global system.
Some algorithms enable new activities (multimedia is impossible without FFT and CRC), change how activities are done (data centres happen because virtualization and MapReduce make them scale well), or enable faster algorithmic development (compilers and libraries). Algorithms used for decision support are particularly important. Logistics algorithms (routing, linear programming, scheduling, and optimization) affect the scope and efficiency of the material economy. Financial algorithms the scope and efficiency of the economy itself. Intelligence algorithms (data collection, warehousing, mining, network analysis but also human expert judgement combination methods), statistics gathering and risk models affect government policy. Recommender systems (“You May Also Enjoy…”) and advertising influence consumer demand.
Since these algorithms are shared, their properties will affect a multitude of decisions and individuals in the same way even if they think they are acting independently. There are spillover effects from the groups that use algorithms to other stakeholders from the algorithm-caused actions. And algorithms have a multitude of non-trivial failure modes: machine learning can create opaque bias or sudden emergent misbehaviour, human over-reliance on algorithms can cause accidents or large-scale misallocation of resources, some algorithms produce systemic risks, and others embody malicious behaviours. In short, code – whether in computers or as a formal praxis in an organisation – matters morally.
What is the point?
 Could a code like the Biosphere Code actually do anything useful? Isn’t this yet another splashy “wouldn’t it be nice if everybody were moral and rational in engineering/politics/international relations?”
Could a code like the Biosphere Code actually do anything useful? Isn’t this yet another splashy “wouldn’t it be nice if everybody were moral and rational in engineering/politics/international relations?”
I think it is a first step towards something useful.
There are engineering ethics codes, even for software engineers. But algorithms are created in many domains, including by non-engineers. We can not and should not prevent people from thinking, proposing, and trying new algorithms: that would be like attempts to regulate science, art, and thought. But we can as societies create incentives to do constructive things and avoid known destructive things. In order to do so, we should recognize that we need to work on the incentives and start gathering information.
Algorithms and their large-scale results must be studied and measured: we cannot rely on theory, despite its seductive power since there are profound theoretical limitations about our predictive abilities in the world of algorithms, as well as obvious practical limitations. Algorithms also do not exist in a vacuum: the human or biosphere context is an active part of what is going on. An algorithm can be totally correct and yet be misused in a harmful way because of its framing.
But even in the small, if we can make one programmer think a bit more about what they are doing and choosing a better algorithm than they otherwise would have done, the world is better off. In fact, a single programmer can have surprisingly large impact.
I am more optimistic than that. Recognizing algorithms as the key building blocks that they are for our civilization, what peculiarities they have, and learning better ways of designing and using them has transformative power. There are disciplines dealing with parts of this, but the whole requires considering interdisciplinary interactions that are currently rarely explored.
Let’s get started!