The basic problem is that opiates seem to be unusually harmful (rather nasty dependency, social withdrawal and risky methods of administration), yet restricting access looks hard in the long run. I don’t subscribe to the view that mere exposure will turn all people into addicts (it looks like it is a subset of people who are vulnerable), but there is a fair bit of harm here that likely is not outweighed by cheapness and better quality. Yet proposed methods restricting access to the modified yeast are unlikely to work in the long run, and may some bad effects on their own.
My own solution is to recognize that in 10-20 years it will be possible to brew many strong drugs discreetly at home, and that we need to reduce the harm from this by developing other technologies that make them less problematic. It might sound wussy and complex compared to the more easily actionable targets suggested in the article, but I think it has a greater chance of actually reducing harms in the long run than policies that merely delay the broad arrival of microbrew drugs.
Basically, we analyse the ethics of cryopreserving fetuses, especially as an alternative to abortion. While technologically we do not have any means to bring a separated (yet alone cryopreserved) fetus to term yet, it is not inconceivable that advances in ectogenesis (artificial wombs) or biotechnological production of artificial placentas allowing reinplantation could be achieved. And a cryopreserved fetus would have all the time in the world, just like an adult cryonics patient.
It is interesting to see how many of the standard ethical arguments against abortion fare when dealing with cryopreservation. There is no killing, personhood is not affected, there is no loss of value of the future – just a long delay. One might be concerned that fetuses will not be reinplanted but just left in limbo forever, but clearly this is a better state than being irreversibly aborted: cryopreservation can (eventually) be reversed. I think our paper shows that (regardless of what one thinks of cryonics) the irreversibility is the key ethical issue in abortion.
In the end, it will likely take a long time before this is a viable option. But it seems that there are good reasons to consider cryopreservation and reinplantation of fetuses: animal husbandry, space colonisation, various medical treatments (consider “interrupting” an ongoing pregnancy because the mother needs cytostatic treament), and now this family planning reason.
If I have one piece of advice to give to people, it is that they typically have way more time now than they will ever have in the future. Do not procrastinate, take chances when you see them – you might never have the time to do it later.
One reason is the gradual speeding up of subjective time as we age: one day is less time for a 40 year old than for a 20 year old, and way less than the eon it is to a 5 year old. Another is that there is a finite risk that opportunities will go away (including our own finite lifespans). The main reason is of course the planning fallacy: since we underestimate how long our tasks will take, our lives tend to crowd up. Accepting to give a paper in several months time is easy, since there seems to be a lot of time to do it in between… which mysteriously disappears until you sit there doing an all-nighter. There is also the likely effect that as you grow in skill, reputation and career there will be more demands on your time. All in all, expect your time to grow in preciousness!
Mining my calendar
I recently noted that my calendar had filled up several weeks in advance, something I think did not happen to this extent a few years back. A sign of a career taking off, worsening time management, or just bad memory? I decided to do some self-quantification using my Google calendar. I exported the calendar as an .ics file and made a simple parser in Matlab.
Histogram of time distance between scheduling time and actual event.
It is pretty clear from a scatter plot that most entries are for the near future – a few days or weeks ahead. Looking at a histogram shows that most are within a month (a few are in the past – I sometimes use my calendar to note when I have done something like an interview that I may want to remember later).
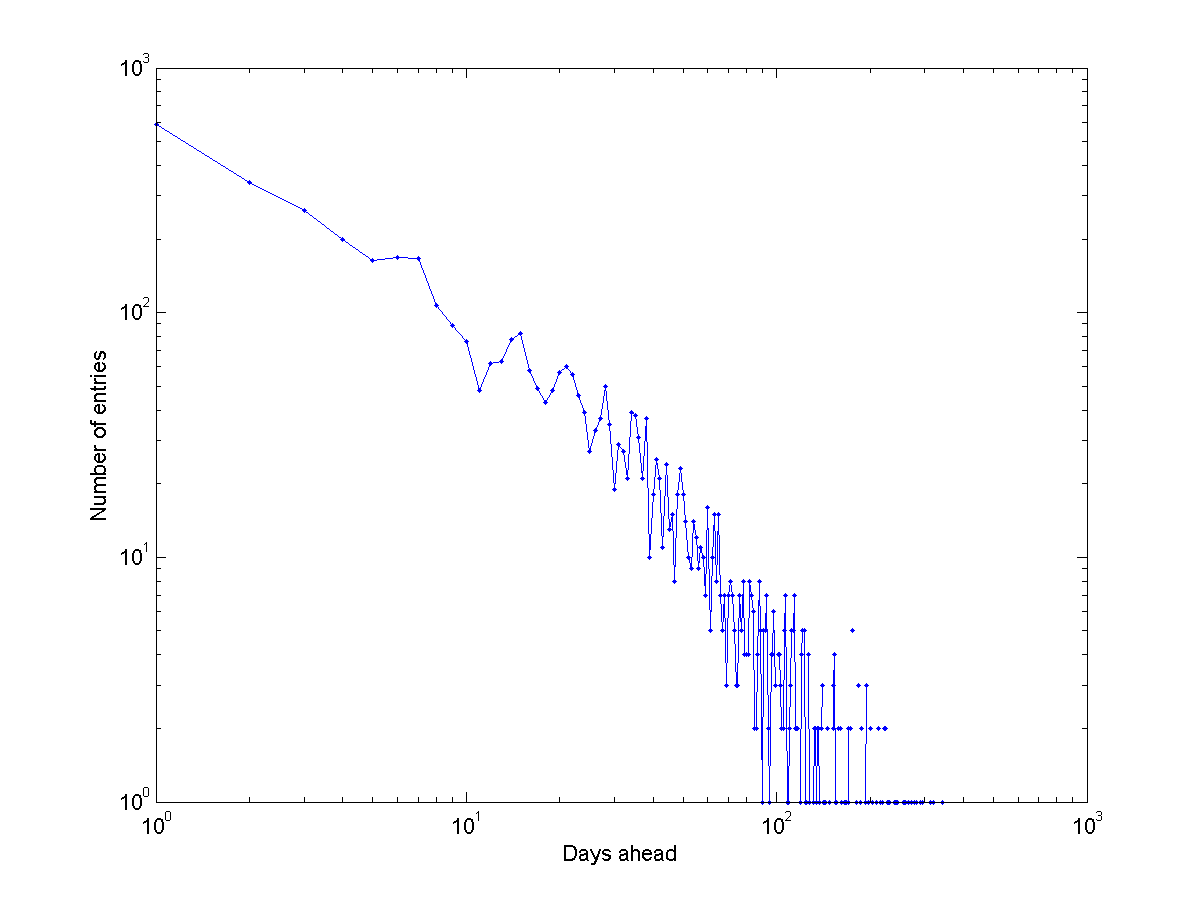
Log-log plot of the histogram of event scheduling intervals.
Plotting it as a log-log diagram suggests it is lighter-tailed than a power-law: there is a characteristic scale. And there are a few wobbles suggesting 1-week, 2-week and 3-week periodicities.
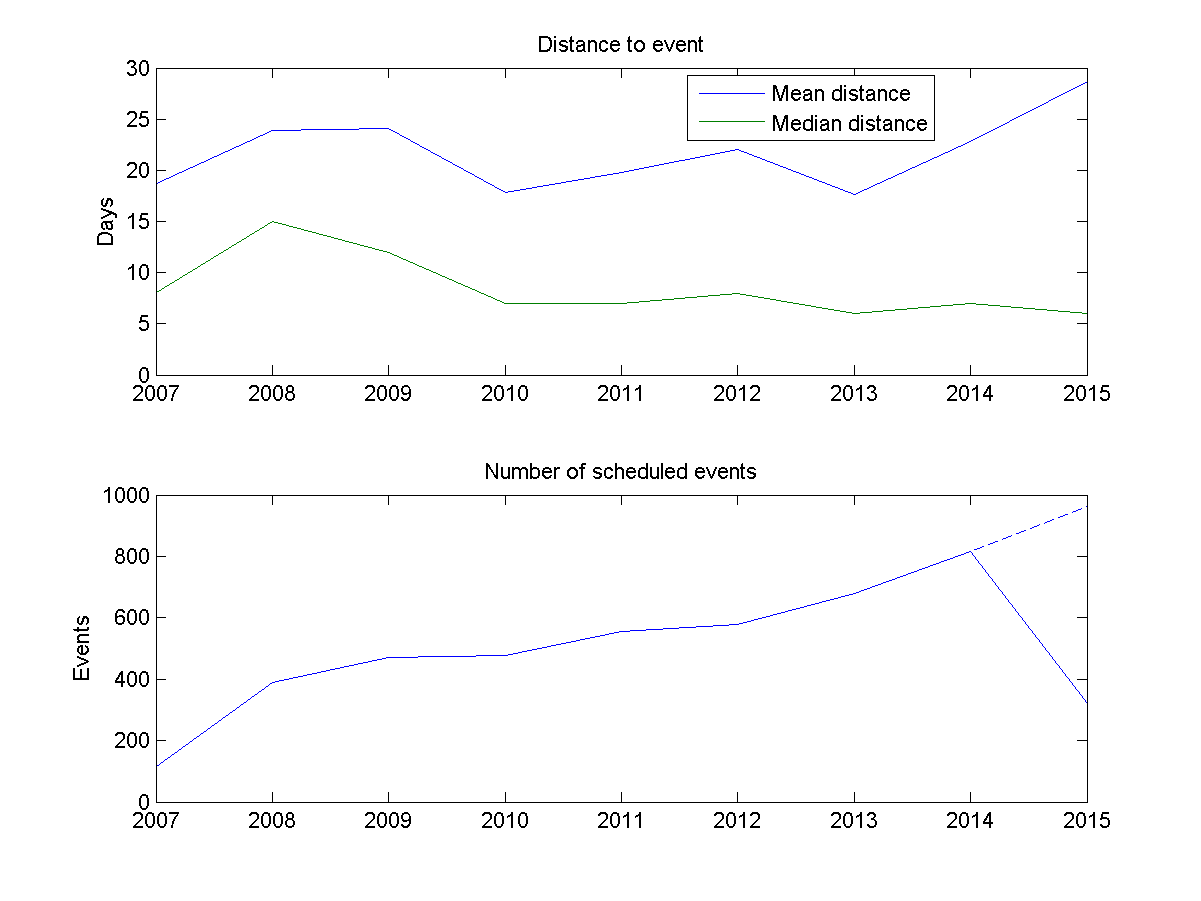
Mean and median distance to newly scheduled events (top), annual number of events scheduled (bottom). The eventual 2015 annual number has been estimated (dashed line).
Am I getting busier? Plotting the mean and median distance to scheduled events, and the number of events per year, suggests yes. The median distance to the things I schedule seems to be creeping downwards, while the number of events per year has clearly doubled from about 400 in 2008 to 800 in 2014 (and extrapolating 2015 suggests about 1000 scheduled events).
Number of calendar events per 14 day period. Red line marks present.
Plotting the number of events I had per 14-day period also suggests that I have way more going on now than a few years ago. The peaks are getting higher and the mean period is more intense.
When am I free?
A good measure of busyness would be the time horizon: how far ahead should you ask me for a meeting if you want to have a high chance of getting it?
One approach would be to look for the probability that a day days ahead is entirely empty. If the probability that I will fill in something days ahead is , then the chance for an empty day is . We can estimate by doing a curve-fit (a second degree curve works well), but we can of course just estimate from the histogram counts: .
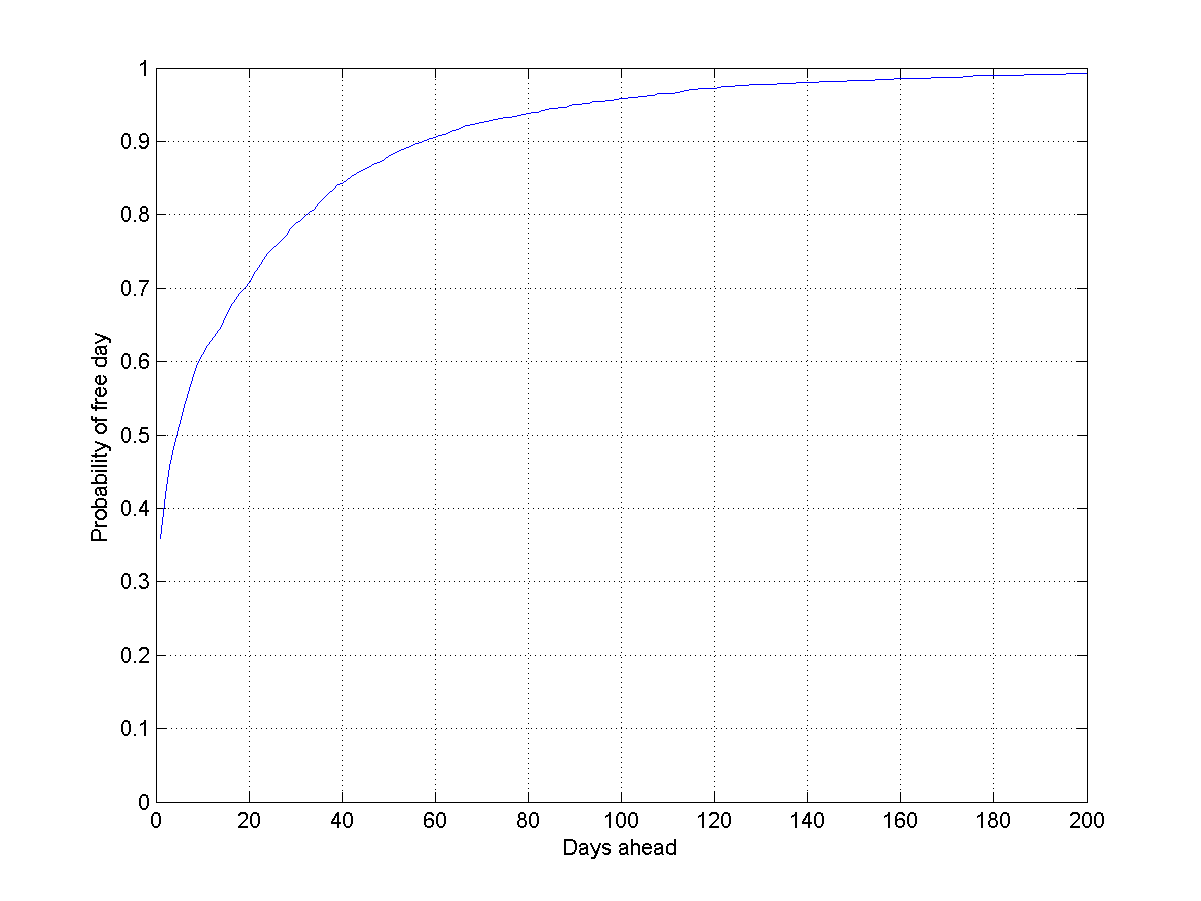
Probability that I will have an entirely free day a certain number of days ahead.
However, this method is slightly wrong. Some days are free, others have many different events. If I schedule twice as many events the chance of a free day should be lower. A better way of estimating is to think in terms of the rate of scheduling. We can view this as a Poisson process, where the rate of scheduling tells us how often I schedule something days ahead. An approximation is , where is the time interval we base our estimate on. This way .
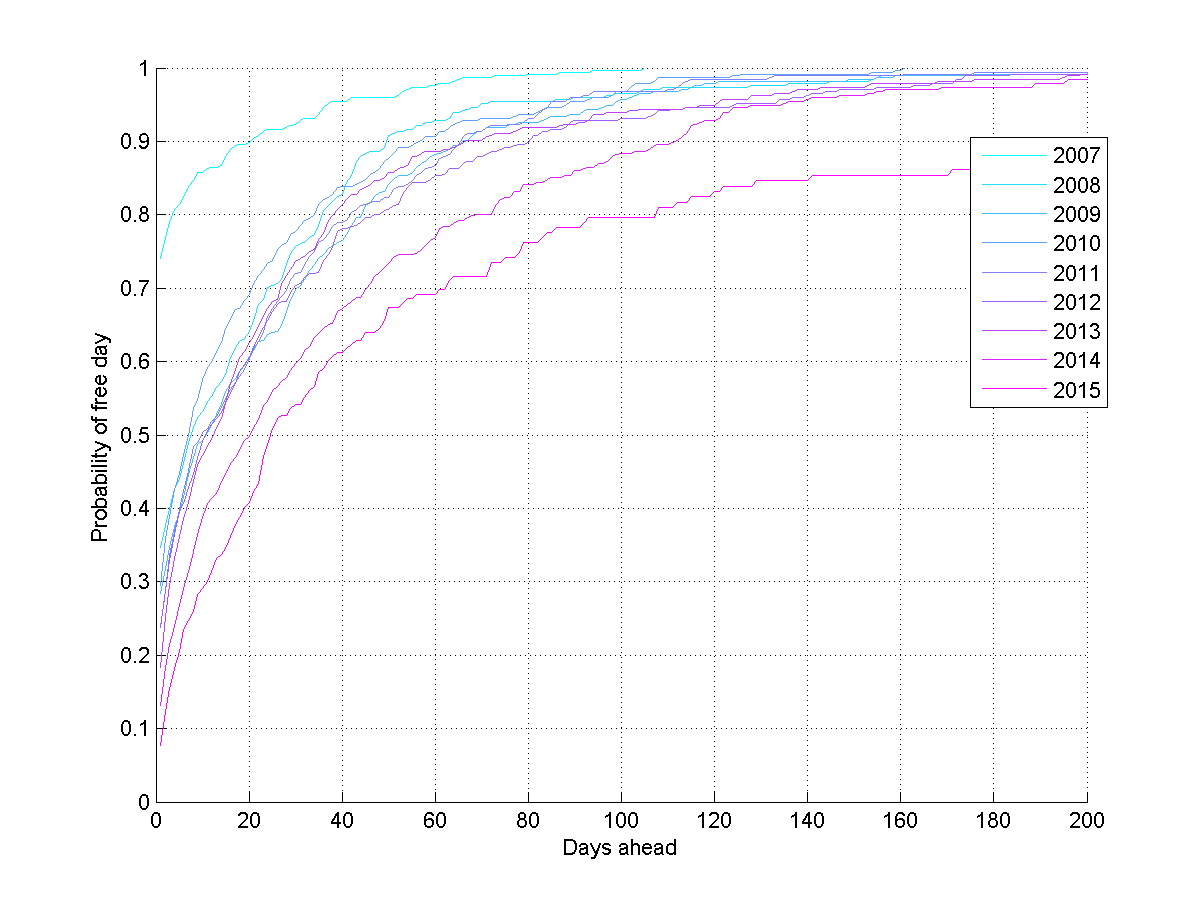
Probability that I will be free a certain number of days ahead for different years of my calender, estimated using a Poisson rate model.
If we slice the data by year, then there seems to be a fairly clear trend towards the planning horizon growing – I have more and more events far into future, and I have more to do. Oh, those halcyon days in 2007 when I presumably just lazed around…
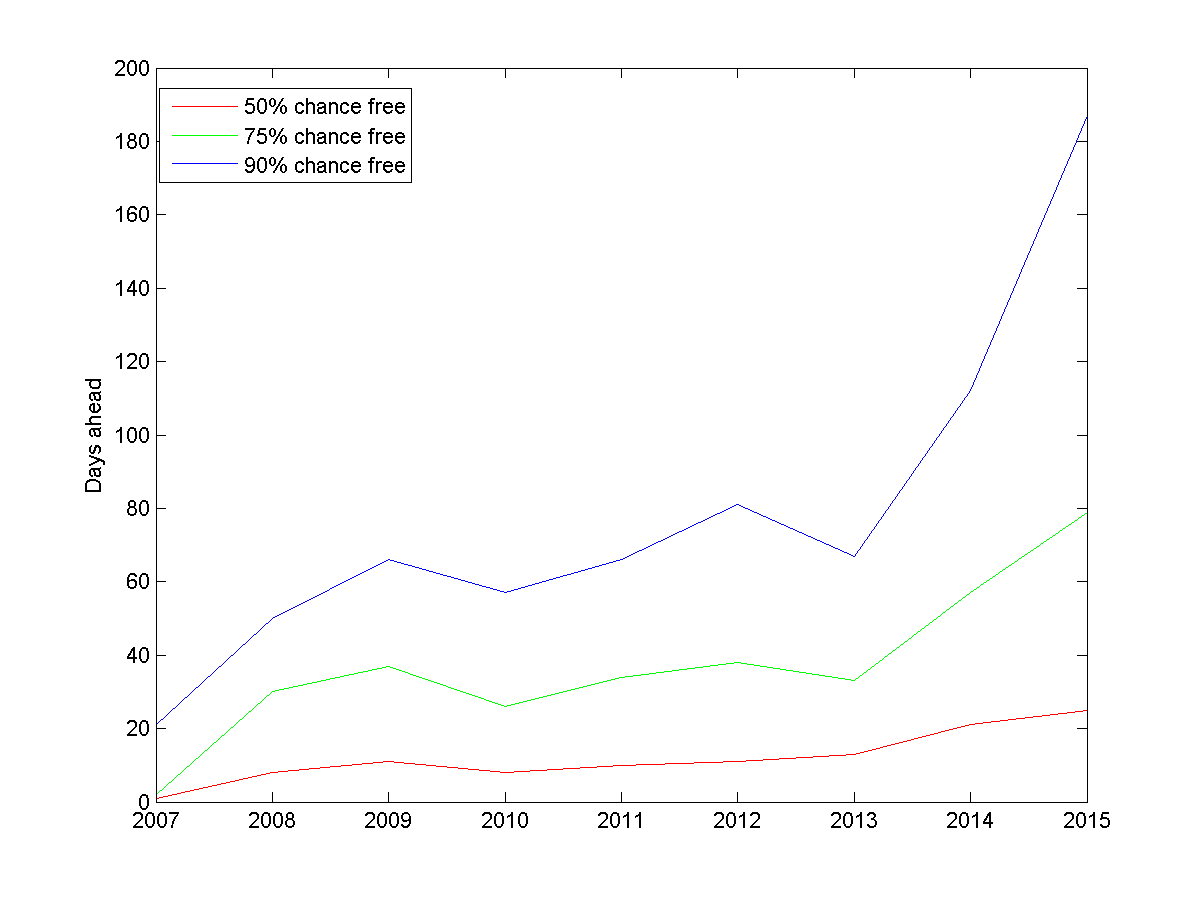
Distance to first day where I have 50%, 75% or 90% chance of being entirely unscheduled.
If we plot when I have 50%, 75% and 90% chance of being free, the trend is even clearer. At present you need to ask about three weeks in advance to have a 50% chance of grabbing me, and 187 days in advance to be 90% certain (if you want an entire working week with 50% chance, this is close to where you should go). Back in 2008 the 50% point was about a week and the 90% point 1.5 months ahead. I have become around 3 times busier.
Conclusions
So, I have become busier. This is of course no evidence of getting more done – a lot of events are pointless meetings, and who knows if I am doing anything helpful at the other events. Plus, I might actually be wasting my time doing statistics and blogging instead of working.
But the exercise shows that it is possible to automatically estimate necessary planning horizons. Maybe we should add this to calendar apps to help scheduling: my contact page or virtual secretary might give you an automatically updated estimate of how far ahead you need to schedule things to have a good chance of getting me. It doesn’t have to tell you my detailed schedule (in principle one could do a privacy attack on the schedule by asking for very specific dates and seeing if they were blocked).
We can also use this method to look at levels of busyness across organisations. Who have flexibility in their schedules, who are so overloaded that they cannot be effectively involved in projects? In the past, tasks tended to be simple and the issue was just the amount of time people had. But today we work individually yet as part of teams, and coordination (meetings, seminars, lectures) are the key links: figuring out how to schedule them right is important for effectivity.
If team member has scheduling rates and they are are uncorrelated (yeah, right), then . The most important lesson is that the chance of everybody being able to make it to any given meeting day declines exponentially with the number of people. If the decline exponentially with time (plausible in at least my case) then scheduling a meeting requires the time ahead to be proportional to the number of people involved: double the meeting size, at least double the planning horizon. So if you want nimble meetings, make them tiny.
In the end, I prefer to live by the advice my German teacher Ulla Landvik once gave me, glancing at the school clock: “I see we have 30 seconds left of the lesson. Let’s do this excercise – we have plenty of time!” Time not only flies, it can be stretched too.
Addendum 2015-05-01
Some further explorations.
Days until next completely free day as a function of time. Grey shows data day-by-day, blue averaged over 7 days, green 30 days and red one year.
Owen Cotton-Barratt pointed out that another measure of busyness might be the distance to the next free day. Plotting it shows a very bursty pattern, with noisy peaks. The mean time was about 2-3 days: even though a lot of time the horizon is far away, often an empty day slips through too. It is just that it cannot be relied on.
Histogram of the timing of events by weekday.
Are there periodicities? The most obvious is the weekly dynamics: Thursdays are busiest, weekend least busy. I tend to do scheduling in a roughly similar manner, with Tuesdays as the top scheduling day.
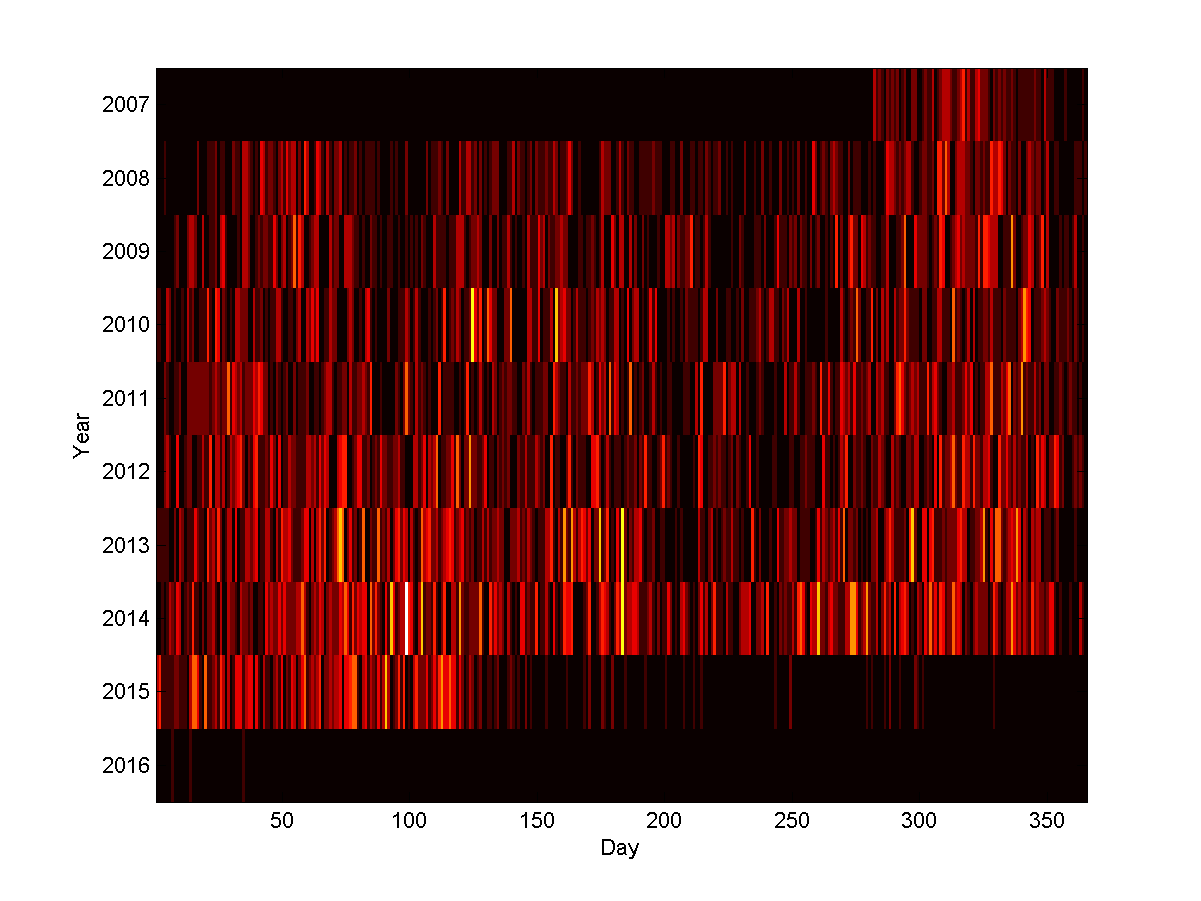
Number of events scheduled per day, plotted across my calendar.
Over the years, plotting the number of events per day (“event intensity”) it is also clear that there is a loose pattern. Back in 2008-2011 one can see a lower rate around day 75 – that is the break between Hilary and Trinity term here in Oxford. There is another trough around day 200-250, the summer break and the time before the Michaelmas term. However, this is getting filled up over time.
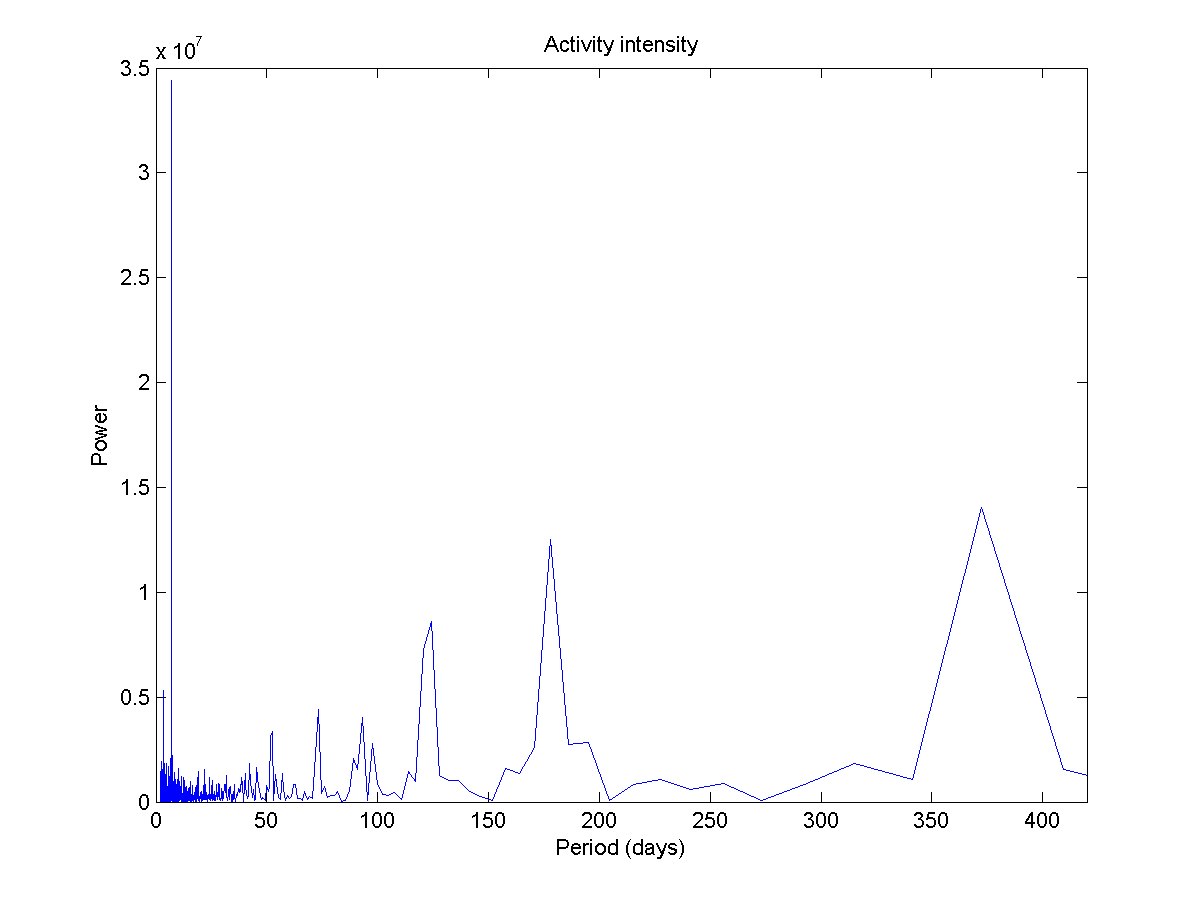
Periodogram of event intensity, showing periodicities in my schedule. Note the weekly and yearly peaks.
Making a periodogram produces an obvious peak for 7 days, and a loose yearly periodicity. Between them there is a bunch of harmonics. The funny thing is that the week periodicity is very strong but hard to see in the map above.
That germline engineering can have unpredictable consequences for future generations is as true for normal reproduction. More strongly, somebody making the case that (say) race mixing should be hindred because of unknown future effects would be condemned as a racist: we have overarching reasons to allow people live and procreate freely that morally overrule worries about their genetic endowment – even if there actually were genetic issues (as far as I know all branches of the human family are equally interfertile, but this might just be a historical contingency). For a possible future effect to matter morally it needs to be pretty serious and we need to have some real reason to think it is more likely to happen because of the actions we take now. A vague unease or a mere possibility is not enough.
However, the paper actually gives a pretty good argument for why we should not try this method in humans. They found that the efficiency of the repair was about 50%, but more worryingly that there was off-target mutations and that a similar gene was accidentally modified. These are good reasons not to try it. Not unexpected, but very helpful in that we can actually make informed decisions both about whether to use it (clearly not until the problems have been fixed) and what needs to be investigated (how can it be done well? why does it work worse here than advertised?).
The interesting thing with the paper is that the fairly negative results which would reduce interest in human germline changes is anyway hailed as being unethical. It is hard to make this claim stick, unless one buys into the view that germline changes of human embryos is intrinsically bad. The embryos could not develop into persons and would have been discarded from the fertility clinic, so there was no possible future person being harmed (if one thinks fertilized but non-viable embryos deserve moral protection one has other big problems). The main fear seems to be that if the technology is demonstrated many others will follow, but an early negative result would seem to reduce this slippery slope argument.
I think the real reason people think there is an ethical problem is the association of germline engineering with “designer babies”, and the conditioning that designer babies are wrong. But they can’t be wrong for no reason: there has to be an ethics argument for their badness. There is no shortage of such arguments in the literature, ranging from ideas of the natural order, human dignity, accepting the given, the importance of an open-ended life to issues of equality, just to mention a few. But none of these are widely accepted as slam-dunk arguments that conclusively show designer babies are wrong: each of them also have vigorous criticisms. One can believe one or more of them to be true, but it would be rather premature to claim that settles the debate. And even then, most of these designer baby arguments are irrelevant for the case at hand.
All in all, it was a useful result that probably will reduce both risky and pointless research and focus on what matters. I think that makes it quite ethical.
George Dvorsky has a piece on Io9 about ways we could wreck the solar system, where he cites me in a few places. This is mostly for fun, but I think it links to an important existential risk issue: what conceivable threats have big enough spatial reach to threaten a interplanetary or even star-faring civilization?
This matters, since most existential risks we worry about today (like nuclear war, bioweapons, global ecological/societal crashes) only affect one planet. But if existential risk is the answer to the Fermi question, then the peril has to strike reliably. If it is one of the local ones it has to strike early: a multi-planet civilization is largely immune to the local risks. It will not just be distributed, but it will almost by necessity have fairly self-sufficient habitats that could act as seeds for a new civilization if they survive. Since it is entirely conceivable that we could have invented rockets and spaceflight long before discovering anything odd about uranium or how genetics work it seems unlikely that any of these local risks are “it”. That means that the risks have to be spatially bigger (or, of course, that xrisk is not the answer to the Fermi question).
Of the risks mentioned by George physics disasters are intriguing, since they might irradiate solar systems efficiently. But the reliability of them being triggered before interstellar spread seems problematic. Stellar engineering, stellification and orbit manipulation may be issues, but they hardly happen early – lots of time to escape. Warp drives and wormholes are also likely late activities, and do not seem to be reliable as extinctors. These are all still relatively localized: while able to irradiate a largish volume, they are not fine-tuned to cause damage and does not follow fleeing people. Dangers from self-replicating or self-improving machines seems to be a plausible, spatially unbound risk that could pursue (but also problematic for the Fermi question since now the machines are the aliens). Attracting malevolent aliens may actually be a relevant risk: assuming von Neumann probes one can set up global warning systems or “police probes” that maintain whatever rules the original programmers desire, and it is not too hard to imagine ruthless or uncaring systems that could enforce the great silence. Since early civilizations have the chance to spread to enormous volumes given a certain level of technology, this might matter more than one might a priori believe.
So, in the end, it seems that anything releasing a dangerous energy effect will only affect a fixed volume. If it has energy and one can survive it below a deposited energy , if it just radiates in all directions the safe range is – one needs to get into supernova ranges to sterilize interstellar volumes. If it is directional the range goes up, but smaller volumes are affected: if a fraction of the sky is affected, the range increases as but the total volume affected scales as .
Self-sustaining effects are worse, but they need to cross space: if their space range is smaller than interplanetary distances they may destroy a planet but not anything more. For example, a black hole merely absorbs a planet or star (releasing a nasty energy blast) but does not continue sucking up stuff. Vacuum decay on the other hand has indefinite range in space and moves at lightspeed. Accidental self-replication is unlikely to be spaceworthy unless is starts among space-moving machinery; here deliberate design is a more serious problem.
The more information you have about a target, the better you can in general harm it. If you have no information, merely randomizing it with enough energy/entropy is the only option (and if you have no information of where it is, you need to radiate in all directions). As you learn more, you can focus resources to make more harm per unit expended, up to the extreme limits of solving the optimization problem of finding the informational/environmental inputs that cause desired harm (=hacking). This suggests that mindless threats will nearly always have shorter range and smaller harms than threats designed by (or constituted by) intelligent minds.
In the end, the most likely type of actual civilization-ending threat for an interplanetary civilization looks like it needs to be self-replicating/self-sustaining, able to spread through space, and have at least a tropism towards escaping entities. The smarter, the more effective it can be. This includes both nasty AI and replicators, but also predecessor civilizations that have infrastructure in place. Civilizations cannot be expected to reliably do foolish things with planetary orbits or risky physics.
My basic argument is that enhancing the capabilities of military forces (or any other form of state power) is risky if the probability that they can be misused (or the amount of expected/maximal damage in such cases) does not decrease more strongly. This would likely correspond to some form of moral enhancement, but even the morally enhanced army may act in a bad manner because the values guiding it or the state commanding it are bad: moral enhancement as we normally think about it is all about coordination, the ability to act according to given values and to reflect on these values. But since moral enhancement itself is agnostic about the right values those values will be provided by the state or society. So we need to ensure that states/societies have good values, and that they are able to make their forces implement them. A malicious or stupid head commanding a genius army is truly dangerous. As is tails wagging dogs, or keeping the head unaware (in the name of national security) of what is going on.
>> If you want to reduce death tolls, focus on self-driving cars.
> Instead of answering terror attacks, just mend you cars?
Sounds eminently sensible. Charlie makes a good point: if we want to make the world better, it might be worth prioritizing fixing the stuff that makes it worse according to the damage it actually makes. Toby Ord and me have been chatting quite a bit about this.
Death
In terms of death (~57 million people per year), the big causes are cardiovascular disease (29%), infectious and parasitic diseases (23%) and cancer (12%). At least the first and last are to a sizeable degree caused or worsened by ageing, which is a massive hidden problem. It has been argued that malnutrition is similarly indirectly involved in 15-60% of the total number of deaths: often not the direct cause, but weakening people so they become vulnerable to other risks. Anything that makes a dent in these saves lives on a scale that is simply staggering; any threat to our ability to treat them (like resistance to antibiotics or anthelmintics) is correspondingly bad.
Unintentional injuries are responsible for 6% of deaths, just behind respiratory diseases 6.5%. Road traffic alone is responsible for 2% of all deaths: even 1% safer cars would save 11,400 lives per year. If everybody reached Swedish safety (2.9 deaths per 100,000 people per year) it would save around 460,000 lives per year – one Antwerp per year.
Now, intentional injuries are responsible for 2.8% of all deaths. Of these suicide is responsible for 1.53% of total death rate, violence 0.98% and war 0.3%. Yes, all wars killed about the same number of people as were killed by meningitis, and slightly more than the people who died of syphilis. In terms of absolute numbers we might be much better off improving antibiotic treatments and suicide hotlines than trying to stop the wars. And terrorism is so small that it doesn’t really show up: even the highest estimates put the median fatalities per year in the low thousands.
So in terms of deaths, fixing (or even denting) ageing, malnutrition, infectious diseases and lifestyle causes is a far more important activity than winning wars or stopping terrorists. Hypertension, tobacco, STDs, alcohol, indoor air pollution and sanitation are all far, far more pressing in terms of saving lives. If we had a choice between ending all wars in the world and fixing indoor air pollution the rational choice would be to fix those smoky stoves: they kill nine times more people.
Existential risk
There is of course more to improving the world than just saving lives. First there is the issue of outbreak distributions: most wars are local and small affairs, but some become global. Same thing for pandemic respiratory disease. We actually do need to worry about them more than their median sizes suggest (and again the influenza totally dominates all wars). Incidentally, the exponent for the power law distribution of terrorism is safely strongly negative at -2.5, so it is less of a problem than ordinary wars with exponent -1.41 (where the expectation diverges: wait long enough and you get a war larger than any stated size).
There are reasons to think that existential risk should be weighed extremely strongly: even a tiny risk that we loose all our future is much worse than many standard risks (since the future could be inconceivably grand and involve very large numbers of people). This has convinced me that fixing the safety of governments needs to be boosted a lot: democides have been larger killers than wars in the 20th century and both seems to have most of the tail risk, especially when you start thinking nukes. It is likely a far more pressing problem than climate change, and quite possibly (depending on how you analyse xrisk weighting) beats disease.
How to analyse xrisk, especially future risks, in this kind of framework is a big part of our ongoing research at FHI.
Happiness
If instead of lives lost we look at the impact on human stress and happiness wars (and violence in general) look worse: they traumatize people, and terrorism by its nature is all about causing terror. But again, they happen to a small set of people. So in terms of happiness it might be more important to make the bulk of people happier. Life satisfaction correlates to 0.7 with health and 0.6 with wealth and basic education. Boost those a bit, and it outweighs the horrors of war.
In fact, when looking at the value of better lives, it looks like an enhancement in life quality might be worth much more than fixing a lot of the deaths discussed above: make everybody’s life 1% better, and it corresponds to more quality adjusted life years than is lost to death every year! So improving our wellbeing might actually matter far, far more than many diseases. Maybe we ought to spend more resources on applied hedonism research than trying to cure Alzheimers.
Morality
The real reason people focus so much about terrorism is of course the moral outrage. Somebody is responsible, people are angry and want revenge. Same thing for wars. And the horror tends to strike certain people: my kind of global calculations might make sense on the global scale, but most of us think that the people suffering the worst have a higher priority. While it might make more utilitarian sense to make everybody 1% happier rather than stop the carnage in Syria, I suspect most people would say morality is on the other side (exactly why is a matter of some interesting ethical debate, of course). Deontologists might think we have moral duties we must implement no matter what the cost. I disagree: burning villages in order to save them doesn’t make sense. It makes sense to risk lives in order to save lives, both directly and indirectly (by reducing future conflicts).
But this requires proportionality: going to war in order to avenge X deaths by causing 10X deaths is not going to be sustainable or moral. The total moral weight of one unjust death might be high, but it is finite. Given the typical civilian causality ratio of 10:1 any war will also almost certainly produce far more collateral unjust deaths than the justified deaths of enemy soldiers: avenging X deaths by killing exactly X enemies will still lead to around 10X unjust deaths. So achieving proportionality is very, very hard (and the Just War Doctrine is broken anyway, according to the war ethicists I talk to). This means that if you want to leave the straightforward utilitarian approach and add some moral/outrage weighting, you risk making the problem far worse by your own account. In many cases it might indeed be the moral thing to turn the other cheek… ideally armoured and barbed with suitable sanctions.
Conclusion
To sum up, this approach of just looking at consequences and ignoring who is who is of course a bit too cold for most people. Most people have Tetlockian sacred values and get very riled up if somebody thinks about cost-effectiveness in terrorism fighting (typical US bugaboo) or development (typical warmhearted donor bugaboo) or healthcare (typical European bugaboo). But if we did, we would make the world a far better place.
Recording of a fun panel we (Imre Bard, Caroline Edwards, Adam Roberts and me) had at the LSE 2015 literary festival about science fiction, human enhancement and cyborgs. Are cyborgs neoliberal, and what about collectivist libertarian solutions like information markets?
What about nested/continued integrals? Here is a simple one:
.
The way to see this is to recognize that the x in the first integral is going to integrate to , the x in the second will be integrated twice , and so on.
In general additive integrals of this kind turn into sums (assuming convergence, handwave, handwave…):
.
On the other hand, .
So if we insert we get the sum . For we end up with . The differential equation has solution . Setting the integral is clearly zero, so . Tying it together we get:
.
Things are trickier when the integrals are multiplicative, like . However, we can turn it into a differential equation: which has the well known solution . Same thing for , giving us . Since we are running indefinite integrals we get those pesky constants.
Plugging in gives . If we set we get the mildly amusing and in retrospect obvious formula
.
We can of course mess things up further, like , where the differential equation becomes with the solution . A surprisingly simple solution to a weird-looking integral. In a similar vein:
(that is, you get an implicit but well defined expression for the (x,I(x)) values. With Lambert, the x and y axes always tend to switch place).
[And yes, convergence is handwavy in this essay. I think the best way of approaching it is to view the values of these integrals as the functions invariant under the functional consisting of the integral and its repeated function: whether nearby functions are attracted to it (or not) under repeated application of the functional depends on the case. ]
 Over on Practical Ethics I blog about how to handle production of opiates from bioengineered yeast.
Over on Practical Ethics I blog about how to handle production of opiates from bioengineered yeast.


") that a day
that a day  days ahead is entirely empty. If the probability that I will fill in something
days ahead is entirely empty. If the probability that I will fill in something  days ahead is
days ahead is ") , then the chance for an empty day is
, then the chance for an empty day is  = \prod_{i=t}^\infty (1-P(i))") . We can estimate
. We can estimate =N(i)/N") .
.
") tells us how often I schedule something
tells us how often I schedule something =N(i)/T") , where
, where  is the time interval we base our estimate on. This way
is the time interval we base our estimate on. This way  = \prod_{i=t}^\infty e^{-\lambda(i)}") .
.
 has scheduling rates
has scheduling rates ") and they are are uncorrelated (yeah, right), then
and they are are uncorrelated (yeah, right), then =\prod_{i=t}^\infty e^{-\sum_j\lambda_j(i)}") . The most important lesson is that the chance of everybody being able to make it to any given meeting day declines exponentially with the number of people. If the
. The most important lesson is that the chance of everybody being able to make it to any given meeting day declines exponentially with the number of people. If the 



 and one can survive it below a deposited energy
and one can survive it below a deposited energy  , if it just radiates in all directions the safe range is
, if it just radiates in all directions the safe range is  – one needs to get into supernova ranges to sterilize interstellar volumes. If it is directional the range goes up, but smaller volumes are affected: if a fraction
– one needs to get into supernova ranges to sterilize interstellar volumes. If it is directional the range goes up, but smaller volumes are affected: if a fraction  of the sky is affected, the range increases as
of the sky is affected, the range increases as  but the total volume affected scales as
but the total volume affected scales as  .
.




 .
.dx\right)dx\right)dx") .
. , the x in the second will be integrated twice
, the x in the second will be integrated twice  , and so on.
, and so on.=\int f(x)+\left(\int f(x)+\left(\int f(x)+\left(\ldots\right)dx\right)dx\right)dx = \sum_{n=1}^\infty \int^n f(x) dx") .
.=f(x)+I(x)") .
.=\sin(kx)") we get the sum
we get the sum =-\cos(kx)/k-\sin(kx)/k^2+\cos(kx)/k^3+\sin(x)/k^4-\cos(kx)/k^5-\ldots") . For
. For  we end up with
we end up with =\sum_{n=0}^\infty 1/k^{4n+2} - \sum_{n=0}^\infty 2/k^{4n+1}") . The differential equation has solution
. The differential equation has solution =ce^x-\sin(kx)/(k^2+1) - k\cos(kx)/(k^2+1)") . Setting
. Setting  the integral is clearly zero, so
the integral is clearly zero, so  . Tying it together we get:
. Tying it together we get:") .
.=\int x \int x \int x \ldots dx dx dx") . However, we can turn it into a differential equation:
. However, we can turn it into a differential equation: =x I(x)") which has the well known solution
which has the well known solution =ce^{x^2/2}") . Same thing for
. Same thing for =ce^{-\cos(kx)/k}") . Since we are running indefinite integrals we get those pesky constants.
. Since we are running indefinite integrals we get those pesky constants.=1/x") gives
gives =cx") . If we set
. If we set  we get the mildly amusing and in retrospect obvious formula
we get the mildly amusing and in retrospect obvious formula .
.=\int\sqrt{\int\sqrt{\int\sqrt{\ldots} dx} dx} dx") , where the differential equation becomes
, where the differential equation becomes  with the solution
with the solution =(1/4)(c^2 + 2cx + x^2)") . A surprisingly simple solution to a weird-looking integral. In a similar vein:
. A surprisingly simple solution to a weird-looking integral. In a similar vein:=\int\sin\left(\int\sin\left(\int\sin\left(\ldots\right)dx\right) dx\right) dx")
=\int \exp\left(\int \exp\left(\int \exp\left(\ldots \right) dx \right) dx \right) dx")
=\int \left(\int \left(\int \left(\ldots \right)^2 dx \right)^2 dx \right)^2 dx")
=\int W\left(\int W\left(\int W\left(\ldots \right) dx \right) dx \right) dx") , then
, then }1/W(t) dt + c") .
.