This is a bit like the “what is the smallest uninteresting number?” paradox, but not paradoxical: we do not have to name it (and hence make it thought about/interesting) to reason about it.
I will first give a somewhat rough probabilistic bound, and then a much easier argument for the scale of this number. TL;DR: the number is likely smaller than .
Probabilistic bound
If we think about numbers with frequencies , approaches some probability distribution . To simplify things we assume is a decreasing function of ; this is not strictly true (see below) but likely good enough.
If we denote the cumulative distribution function we can use the k:th order statistics to calculate the distribution of the maximum of the numbers: . We are interested in the point where it becomes is likely that the number has not come up despite the trials, which is somewhere above the median of the maximum: .
What shape does have? (Dorogovtsev, Mendes, Oliveira 2005) investigated numbers online and found a complex, non-monotonic shape. Obviously dates close to the present are overrepresented, as are prices (ending in .99 or .95), postal codes and other patterns. Numbers in exponential notation stretch very far up. But mentions of explicit numbers generally tend to follow , a very flat power-law.
So if we have uses we should expect roughly since much larger x are unlikely to occur even once in the sample. We can hence normalize to get . This gives us , and hence . The median of the maximum becomes . We are hence not entirely bumping into the ceiling, but we are close – a more careful argument is needed to take care of this.
So, how large is $k$ today? Dorogovtsev et al. had on the order of , but that was just searchable WWW pages back in 2005. Still, even those numbers contain numbers that no human ever considered since many are auto-generated. So guessing is likely not too crazy. So by this argument, there are likely 24 digit numbers that nobody ever considered.
Consider a number…
Another approach is to assume each human considers a number about once a minute throughout their lifetime (clearly an overestimate given childhood, sleep, innumeracy etc. but we are mostly interested in orders of magnitude anyway and making an upper bound) which we happily assume to be about a century, giving a personal across a life as about . There has been about 100 billion people, so humanity has at most considered numbers. This would give an estimate using my above formula as .
But that assumes “random” numbers, and is a very loose upper bound, merely describing a “typical” small unconsidered number. Were we to systematically think through the numbers from 1 and onward we would have the much lower . Just 19 digits!
One can refine this a bit: if we have time and generate new numbers at a rate per second, then and we will at most get numbers. Hence the smallest number never considered has to be at most .
Seth Lloyd estimated that the observable universe cannot have performed more than operations on bits. If each of those operations was a consideration of a number we get a bound on the first unconsidered number as .
This can be used to consider the future too. Computation of our kind can continue until proton decay in years or so, giving a bound of if we use Lloyd’s formula. That one uses the entire observable universe; if we instead consider our own future light cone the number is going to be much smaller.
But the conclusion is clear: if you write a 173 digit number with no particular pattern of digits (a bit more than two standard lines of typing), it is very likely that this number would never have shown up across the history of the entire universe except for your action. And there is a smaller number that nobody – no human, no alien, no posthuman galaxy brain in the far future – will ever consider.
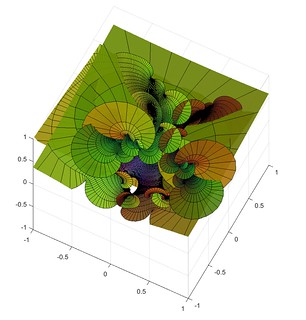
First, how do you make a Steiner chain? It is easy using inversion geometry. Just decide on the number of circles tangent to the inner circle (). Then the ratio of the radii of the inner and outer circle will be . The radii of the circles in the ring will be and their centres are located at distance from the origin. This produces a staid concentric arrangement. Now invert with relation to an arbitrary circle: all the circles are mapped to other circles, their tangencies preserved. Voila! A suitably eccentric Steiner chain to play with.
Since the original concentric chain obviously can be rotated continuously without losing touch with the inner and outer circle, this also generates a continuous family of circles after the inversion. This is why Steiner’s porism is true: if you can make the initial chain, you get an infinite number of other chains with the same number of circles.
Iterated function systems with circle maps
The fractal works by putting copies of the whole set of circles in the chain into each circle, recursively. I remap the circles so that the outer circle becomes the unit circle, and then it is easy to see that for a given small circle with (complex) centre and radius the map maps the interior of the unit circle to it. Use the ease of rotating the original concentric ring to produce an animation, and we can reconstruct the fractal.
Done.
Except… it feels a bit dry.
Ever since I first encountered iterated function systems in the 1980s I have felt they tend towards a geometric aesthetics that is not me, ferns notwithstanding. A lot has to do with the linearity of the transformations. One can of course add rotations, which cheers up the fractal a bit.
But still, I love the nonlinearity and harmony of conformal mappings.
Inversion makes things better!
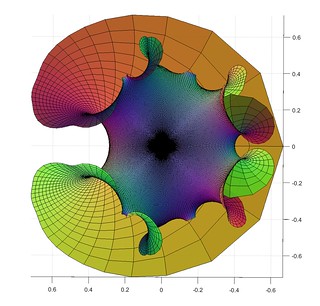
Enter the circle inversion fractals. They are the sets of the plane that map to themselves when being inverted in any and all of a set of generating circles (or, equivalently, the limit set of points under these inversions). As a rule of thumb, when the circles do not touch the fractal will be Cantor/Fatou-style fractal dust. When the circles are tangent the fractal will pass through the point of tangency. If three circles are tangent the fractal will contain a circle passing through these points. Since Steiner chains have lots of tangencies, we should get a lot of delicious fractals by using them as generators.
I use nearly the same code I used for the elliptic inversion fractals, mostly because I like the colours. The “real” fractal is hidden inside the nested circles, composed of an infinite Apollonian gasket of circles.
Note how the fractal extends outside the generators, forming a web of circles. Convergence is slow near tangent points, making it “fuzzy”. While it is easy to see the circles that belong to the invariant set that are empty, there are also circles going through the foci inside the coloured disks, touching the more obvious circles near those fuzzy tangent points. There is a lot going on here.
But we can complicate things by allowing the chain to slide and see how the fractal changes.
Here is a minimal surface based on the Weierstrass-Enneper representation. Written explicitly as a function from the complex number z to 3-space it is .
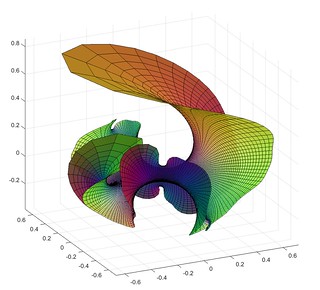
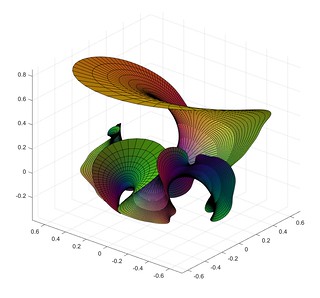
Håkan’s surface, a minimal surface with Weierstrass-Enneper representation f=1,g=tanh(z)^2.
It is based on my old tanh surface, but has a wilder style. It gets helped by the fact that my triangulation in the picture is pretty jagged. On one hand it has two flat ends, but also a infinite number of catenoid openings (only two shown here).
I call it Håkan’s surface, since I came up with it on my dear husband’s birthday. Happy birthday, Håkan!
I have a glass cube on my office windowsill containing a slice of a Calabi-Yau manifold, one of Bathsheba Grossman’s wonderful creations. It is an intricate, self-intersecting surface with lots of unexpected symmetries. A visiting friend got me into trying to make my own version of the surface.
First, what is the equation for it? Grossman-Hanson’s explanation is somewhat involved, but basically what we are seeing is a 2D slice through a 6-dimensional manifold in a projective space expressed as the 4D manifold , where the variables are complex. Hanson shows that this is a kind of complex superquadric in this paper. This leads to the formulae:
where the k’s run through . Each pair corresponds to one patch of what is essentially a complex catenoid. This is still a 4D object. To plot it, we plot the points
where is some suitable angle to tilt the projection into 3-space. Hanson’s explanation is very clear; I originally reverse-engineered the same formula from the code at Ziyi Zhang’s site.
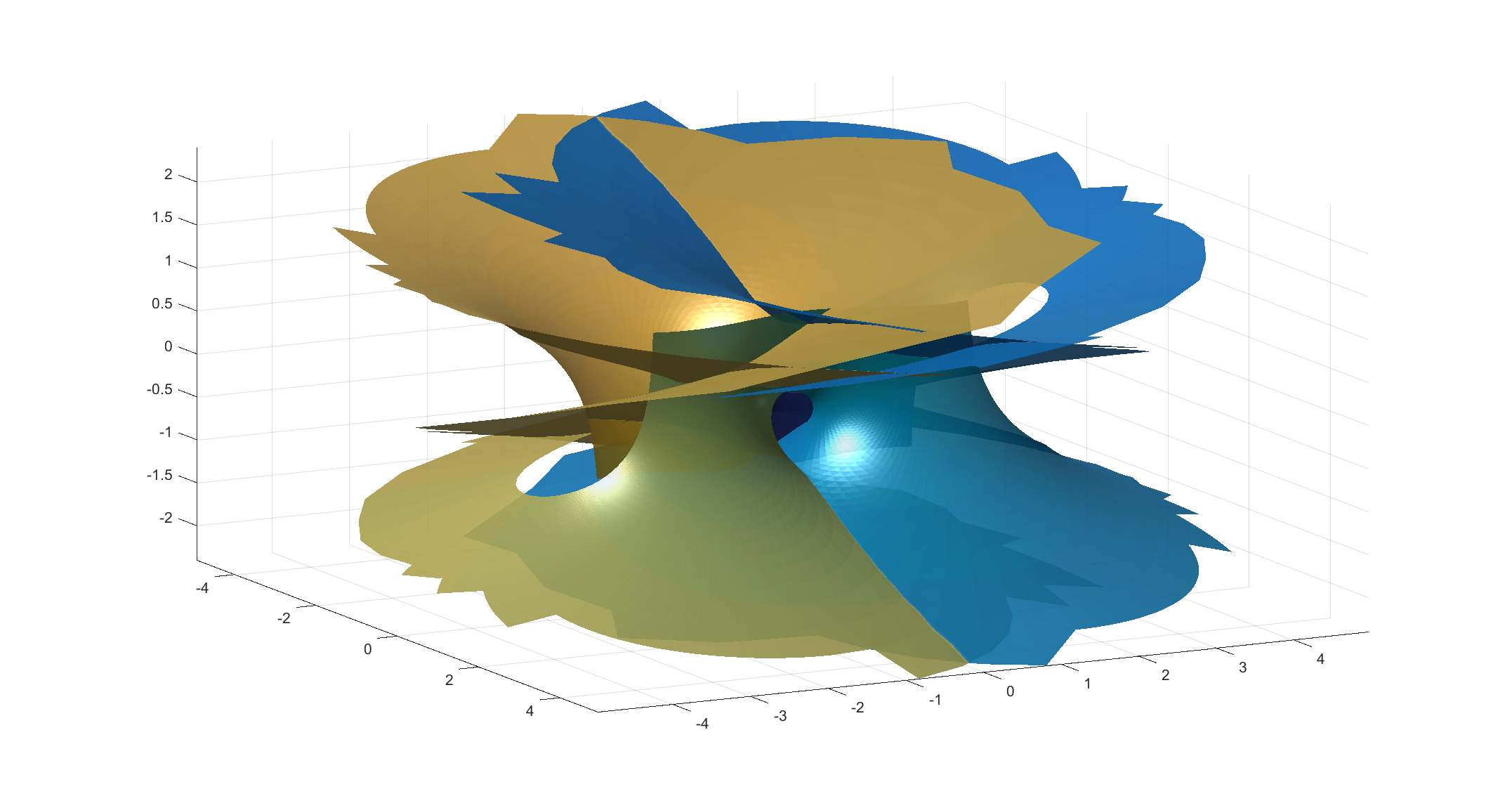
The Hanson n=4 Calabi-Yau manifold projected into 3-space.
The result is pretty nifty. It is tricky to see how it hangs together in 2D; rotating it in 3D helps a bit. It is composed of 16 identical patches:
The patches making up the Hanson Calabi-Yau surface.
The boundary of the patches meet other patches except along two open borders (corresponding to large or small values of ): these form the edges of the manifold and strictly speaking I ought to have rendered them to infinity. That would have made it unbounded and somewhat boring to look at: four disks meeting at an angle, with the interesting part hidden inside. By marking the edges we can see that the boundary are four linked wobbly circles:
Boundary of the piece of the Hanson Calabi-Yau manifold displayed.
A surface bounded by a knot or a link is called a Seifert surface. While these surfaces look a lot like minimal surfaces they are not exactly minimal when I estimate the mean curvature (it should be exactly zero); while this could be because of lack of numerical precision I think it is real: while minimal surfaces are Ricci-flat, the converse is not necessarily true.
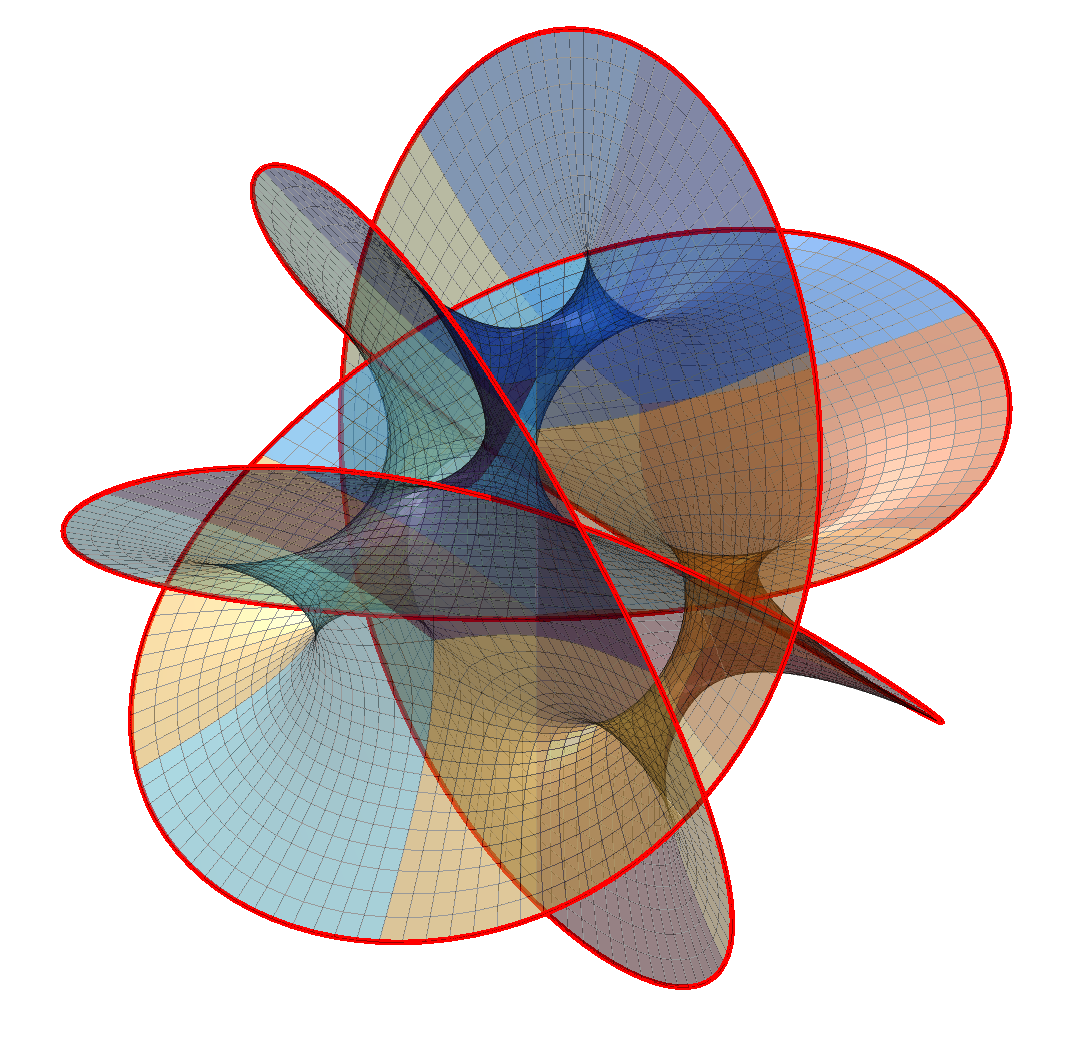
Changing N produces other surfaces. N=2 is basically a catenoid (tilted and self-intersecting). As N increases it becomes more like a barrel or a pufferfish, with one direction dominated by circular saddle regions, one showing a meshwork of spaces reminiscent of spacefilling minimal surfaces, and one a lot of overlapping “barbs”.
Hanson’s Calabi-Yau surface for N=2, N=3, N=5 and N=8.
Note that just like for minimal surfaces one can multiply by to get another surface in an associate family. In this case it circulates the patches along their circles without changing the surface much.
Hanson also notes that by changing the formula to we can get boundaries that are torus-knot-like. This leads to the formulae:
Knotted surface for n1=4, n2=3.
Appendix: Matlab code
%% Initialization
edge=0; % Mark edge?
coloring=1; % Patch coloring type
n=4;
s=0.1; % Gridsize
alp=1; ca=cos(alp); sa=sin(alp); % Projection
[theta,xi]=meshgrid(-1.5:s:1.5,1*(pi/2)*(0:1:16)/16);
z=theta+xi*i;
% Color scheme
tt=2*pi*(1:200)'/200; co=.5+.5*[cos(tt) cos(tt+1) cos(tt+2)];
colormap(co)
%% Plot
clf
hold on
for k1=0:(n-1)
for k2=0:(n-1)
z1=exp(k1*2*pi*i/n)*cosh(z).^(2/n);
z2=exp(k2*2*pi*i/n)*(1/i)*sinh(z).^(2/n);
X=real(z1);
Y=real(z2);
Z=ca*imag(z1)+sa*imag(z2);
if (coloring==0)
surf(X,Y,Z);
else
switch (coloring)
case 1
C=z1*0+(k1+k2*n); % Color by patch
case 2
C=abs(z1);
case 3
C=theta;
case 4
C=xi;
case 5
C=angle(z1);
case 6
C=z1*0+1;
end
h=surf(X,Y,Z,C);
set(h,'EdgeAlpha',0.4)
end
if (edge>0)
plot3(X(:,end),Y(:,end),Z(:,end),'r','LineWidth',2)
plot3(X(:,1),Y(:,1),Z(:,1),'r','LineWidth',2)
end
end
end
view([2 3 1])
camlight
h=camlight('left');
set(h,'Color',[1 1 1]*.5)
axis equal
axis vis3d
axis off
Apropos Newton’s method in the complex plane, what happens when the degree of the polynomial goes to infinity?
Towards infinity
Obviously there will be more zeros, so there will be more attractors and we should expect the boundaries of the basins of attraction to become messier. But it is not entirely clear where the action will be, so it would be useful to compress the entire complex plane into a convenient square.
How do you depict the entire complex plane? While I have always liked the Riemann sphere here I tried mapping to . The origin is unchanged, and infinity becomes the edges of the square . This is not a conformal map, so things will get squished near the edges.
For color, I used to map complex coordinates to RGB. This makes the color depend on the distance to 1, -1 and i, making infinity white and zero some drab color (the -1 terms at the end determines the overall color range).
Here is the animated result:
What is going on? As I scale up the size of the leading term from zero, the root created by adding that term moves in from infinity towards the center, making the new basin of attraction grow. This behavior has been described in this post on dancing zeros. The zeros also tend to cluster towards the unit circle, crowding together and distributing themselves evenly. That distribution is the reason for the the colorful “flowers” that surround white spots (poles of the Newton formula, corresponding to zeros of the derivative of the polynomial). The central blob is just the attractor of the most “solid” zero, corresponding to the linear and constant terms of the polynomial.
The jostling is amusing: it looks like the roots do repel each other. This is presumably because close roots require a sharp turn of the function, but the “turning radius” is set by the coefficients that tend to be of order unity. Getting degenerate roots requires coefficients to be in a set of measure zero, so it is rare. Near-degenerate roots exist in a positive measure set surrounding that set, but it is still “small” compared to the general case.
At infinity
So what happens if we let the degree go to infinity? As I previously mentioned, the generic behaviour of where is independent random numbers is a lacunary function. So we should not expect anything outside the unit circle. Inside the circle there will be poles, so there will be copies of the undefined outside region (because of Great Picard’s Theorem (meromorphic version)). Since the function is analytic these copies will be conformal mappings of the exterior and hence roughly circular. There will also be zeros, and these will have their own basins of attraction. A few of the central ones dominate, but there is an infinite number of attractors as we approach the circular border which is crammed with poles and zeros.
Since we now know we will only deal with the unit disk, we can avoid transforming the entire plane and enjoy the results:
Attractors for random 10,000-degree polynomial.Attractors for random 10,000-degree polynomial.
What happens here is that the white regions represents places where points get mapped onto the undefined outside, while the colored fractal regions are the attraction basins for the zeros. And between them there is a truly wild boundary. In the vanilla fractal every point on the boundary is a meeting point of the three basins, a tri-point. Here there is an infinite number of attractors: the boundary consists of points where an infinite number of different attractors meet.
In Scott Alexander’s kabbalistic sf story Unsong, the archangel Uriel works on a problem while other things are going on in heaven:
All the angels listened in rapt attention except Uriel, who was sort of half-paying attention while trying to balance several twelve-dimensional shapes on top of each other.
…
There was utter silence throughout the halls of Heaven, except a brief curse as Uriel’s hyperdimensional tower collapsed on itself and he picked up the pieces to try to rebuild it.
…
A great clamor arose from all the heavenly hosts, save Uriel, who took advantage of the brief lapse to conjure a parchment and pen and start working on a proof about the optimal configuration of twelve-dimensional shapes.
This got me thinking about the stability of stacking polytopes. That seemed complicated (I am no archangel) so I started toying with the stability of polytopes on a flat surface.
(Terminology note: I will consistently use “face” to denote the D-1 dimensional elements that bound the polytope, although “facet” is in some use.)
A face of a 3D polyhedron is stable if the polyhedron can rest on it without tipping over. This means that the projection of the center of mass onto the plane containing the face is inside the polygon. The platonic polyhedra are stable on all faces, but it is not hard to make a few faces unstable by moving a vertex far away from the center. A polyhedron has at least one stable face (if it did not, it would be a perpetual motion device: every tip will move the center of mass downwards, but there is a bound on how low it can go. A uni-stable or monostatic polyhedron has just one stable face. It is an unsolved problem what the simplest uni-stable 3D polyhedron is, with the current record 14 faces. Also, it seems unclear whether there are monostatic simplices in dimension 9 (they exist in 10 or more dimensions, but not in 8 or fewer).
So, how many faces of a polytope will typically be unstable?
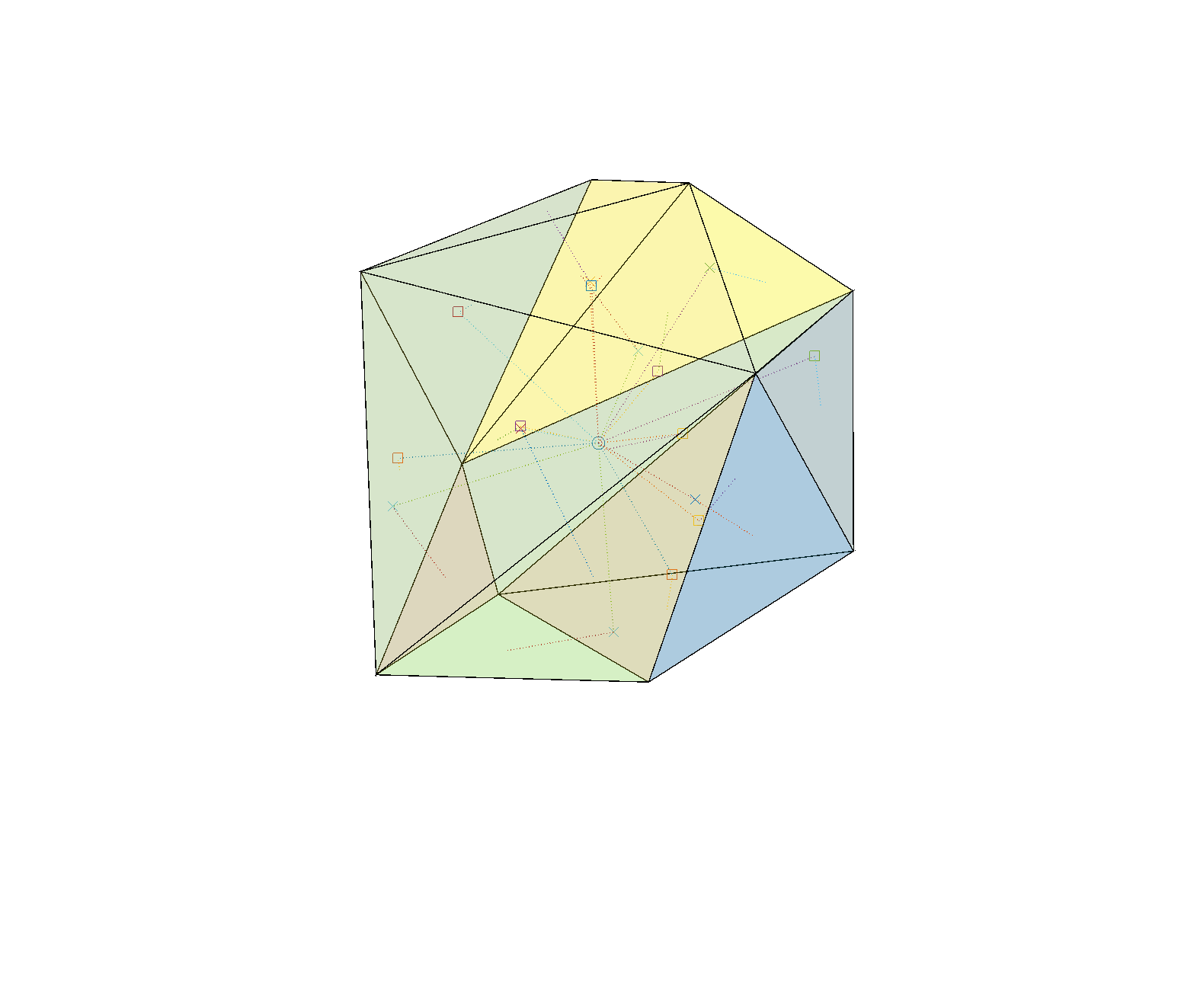
I wrote a Matlab script to generate random convex polytopes by selecting N points randomly on the surface of a D-dimensional sphere and calculating their convex hull. Using a Delaunay decomposition I can split them into simplices, which allow me to calculate the center of mass. The center of mass of a simplex is just the average of the corners , and the center of mass of the polyhedron is just the sum of the simplex centers of mass weighted by their volumes: . The volume of a simplex is where , the matrix made by sticking together the coordinate vectors of a simplex. Once we know this we can project the center of mass onto the plane of a face by finding its nullspace (the higher dimensional counterpart to a normal) . Finally, to check whether the projection is inside the face, we can look at the matrix A where each column is the coordinates of one of the faces minus and the final row just ones, and solve for Ax=b where b is zero except for a one in the last row (I found this neat algorithm due to elisbben on stack overflow). If the answer vector is all positive, then the point is inside the face. Repeat for all the faces.
Whew. This math is of course really simple to do in Matlab.
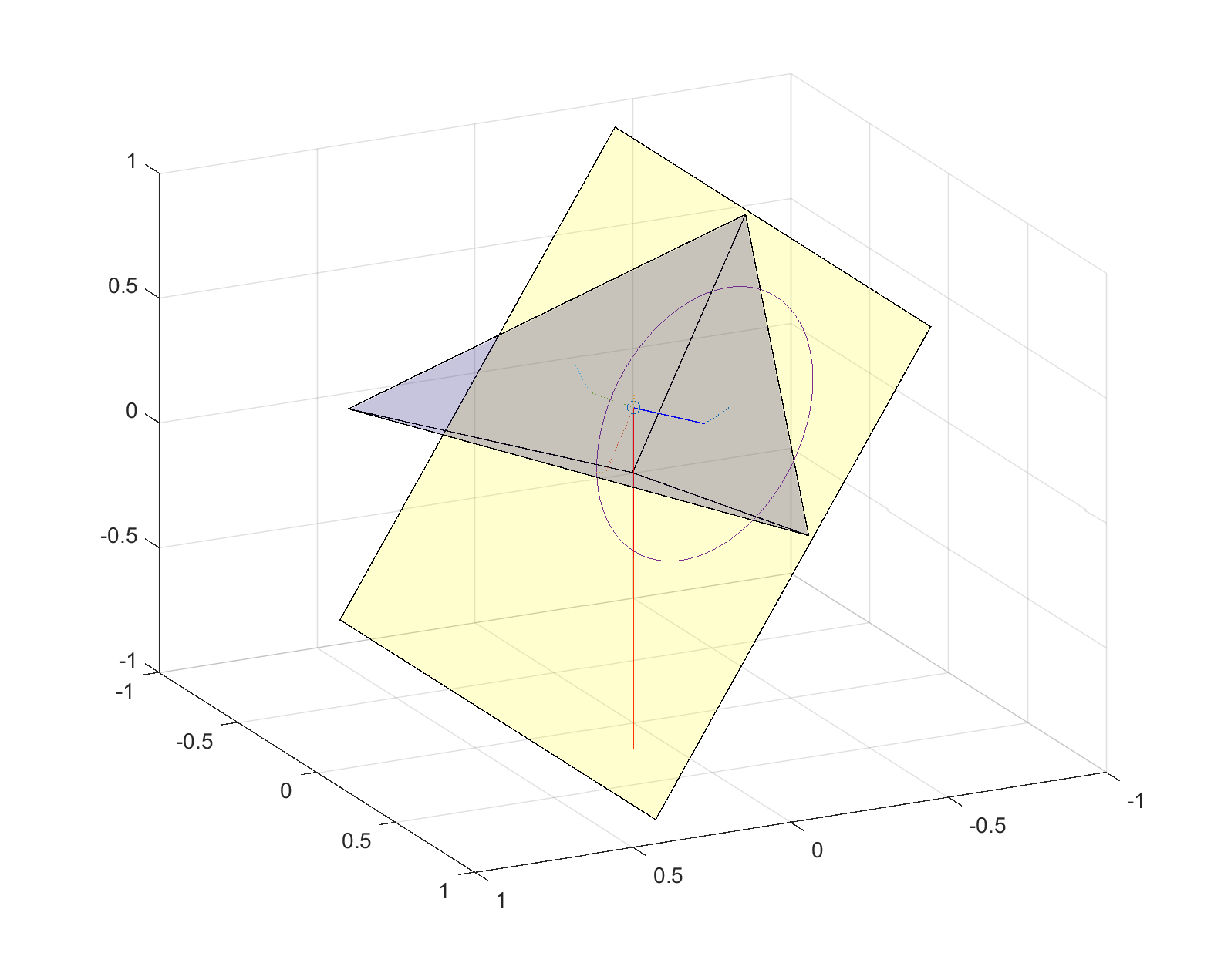
Stable (yellow) and unstable (blue) faces of random polyhedron.Stability of random polyhedron. The center of mass is marked by a circle. It is projected along the dotted lines into the plane of each face, marked with a square (if inside the face and hence a stable face) or a cross (if outside the face, which is hence unstable). A dotted line connects the projection points to the center of their face.
The 12 dimensional case is a bit messier:
Projection of a 12D polytope with 20 vertices. Each of the 2777 faces is a 11 dimensional simplex.
So, what is the average fraction of stable faces on a 3D polyhedron?
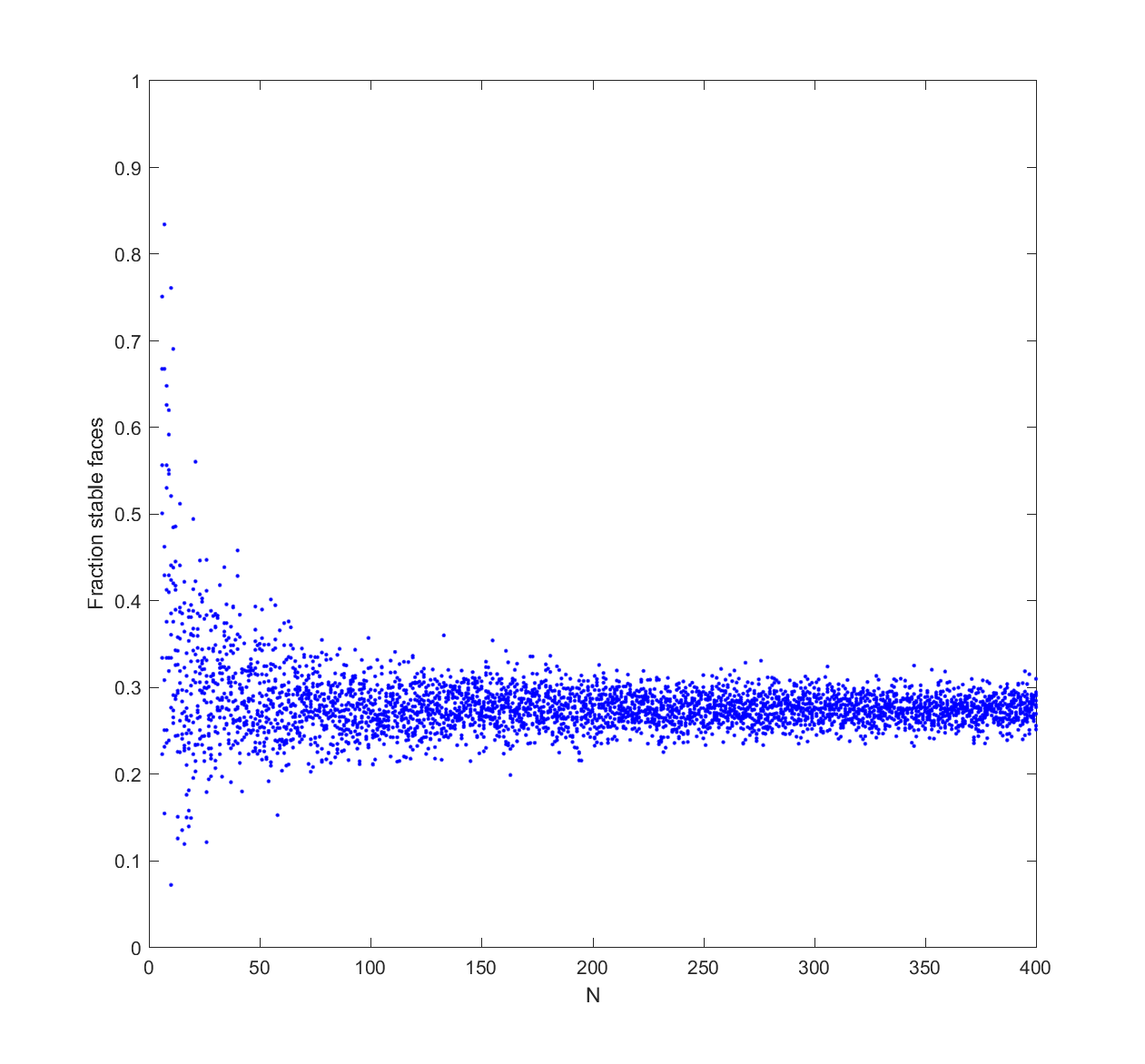
Fraction stable faces on 3D convex hulls of N points on a sphere.
It tends to converge to 50%. Doing this in higher dimensions shows the same kind of convergence, although to lower fractions.
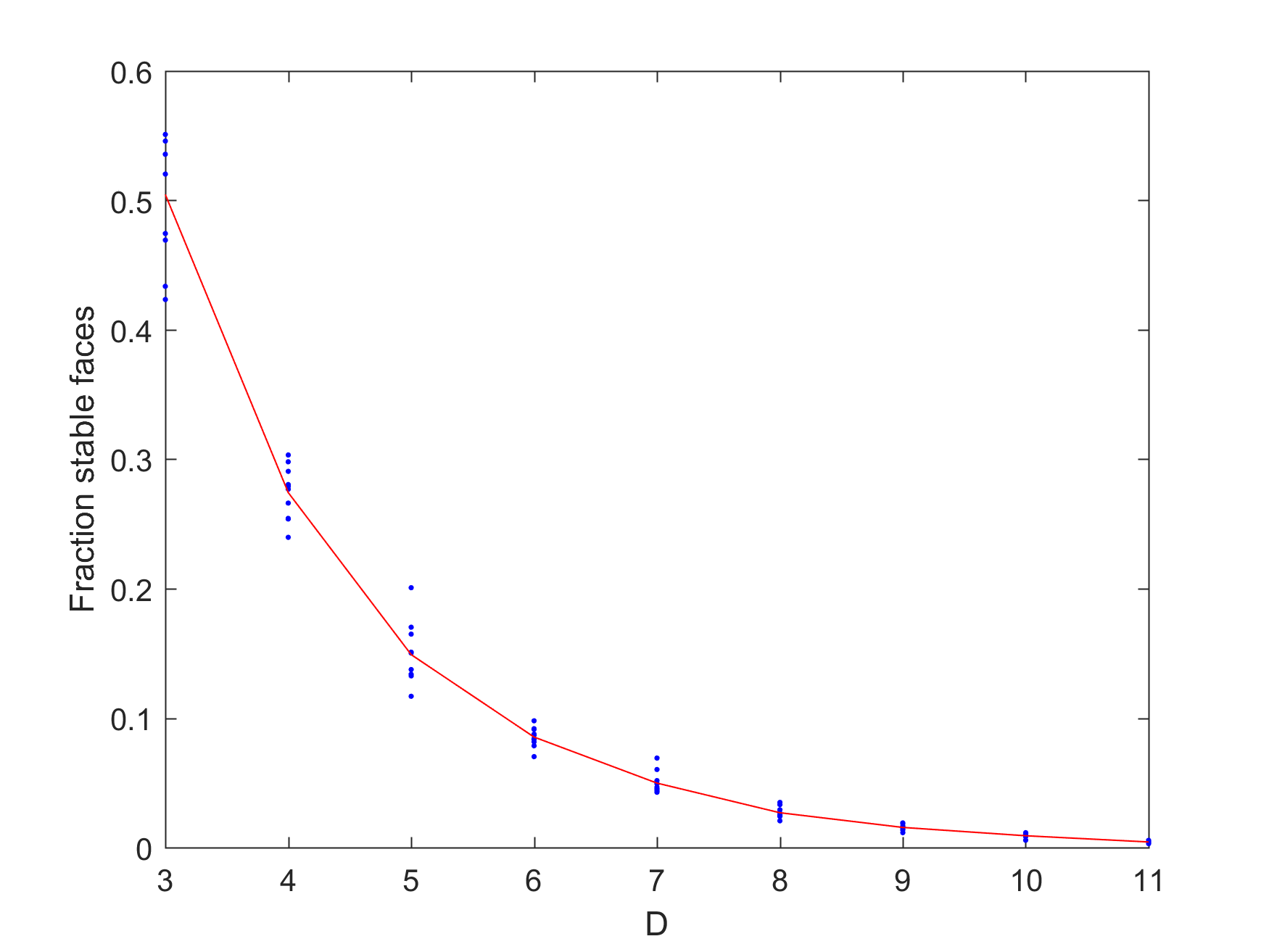
Fraction stable faces on 4D convex hulls of N points on a sphere.Fraction stable faces of N=100 convex hulls in different dimensions. Red line exponential fit.
It looks like the fraction of stable faces declines exponentially with dimensionality.
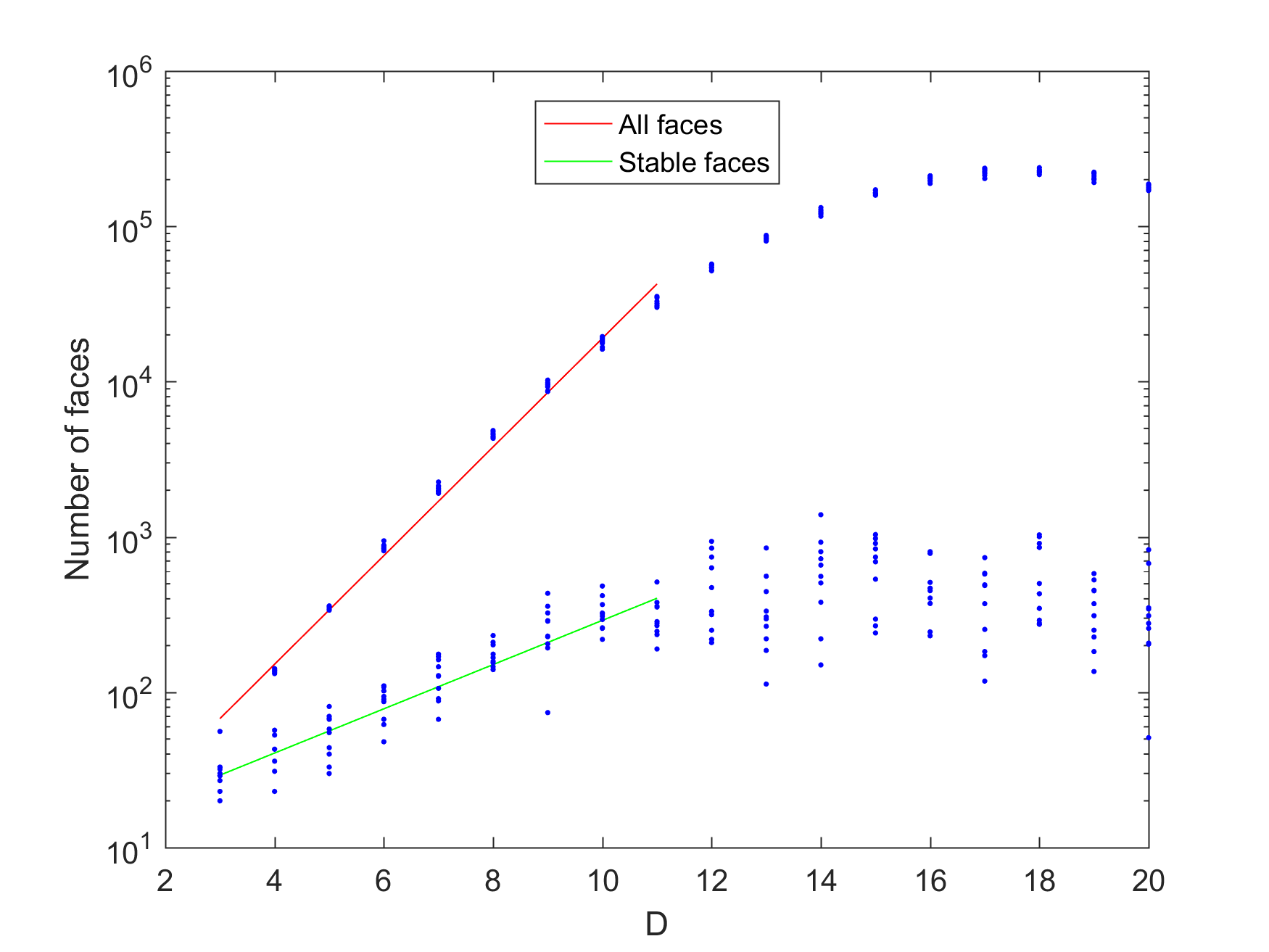
Does this mean that for a sufficiently high dimension it is likely that a random polytope is unistable? The answer is no: the number of faces increases pretty exponentially (as ), but the number of stable faces also increases exponentially with D (as $latex 2^{0.9273 D}$).
Combined plot of number of faces (points with red line) and stable faces (points with green line) as a function of dimension for N=100.
This was based on runs with N=100. Obviously things go much faster if you select a lower N, such as 30. However, as you approach N=D the polytopes become more and more simplex-like, and simplices tend to both have fewer faces and be less stable in high dimensions, so the exponential growth stops. This actually happens far below D; for N=30 the effect is felt already in 11 dimensions. The face growth rates were also lower, with coefficients 1.1621 and 0.4730.
Number of faces and stable faces for N=30 random convex hulls in different dimensions.
(There are some asymptotic formulas known for the growth of the number of faces for random convex hulls; they grow linearly with N but at an accelerating rate with D.)
Stuart Armstrong gave me a very heuristic argument for why there would be so many unstable faces. Consider building up the polytope vertex by vertex, essentially just adding together the simplices from the Delaunay decomposition. If you start from a stable state, eventually you will likely end up with an unstable face. Adding the next vertex will add a simplex to the polyhedron, and the center of mass will move in the direction of the new simplex. To have the face become stable again the shift in center of mass needs to be large enough along the directions parallel to the face to bring the projection back inside the face. But in high dimensional spaces there are many directions you can move in: the probability of a random vector being nearly parallel to another vector is very low. Hence, the next step and the following are likely to preserve the instability. So high dimensional polytopes are likely to have many unstable faces even if they are nicely inscribed in spheres.
The number of steps the polytope rolls over until finding a stable face is also limited: the “drainage basin” of a stable face is a tree, with a branching degree set by D-1 (if faces are D-simplexes). So the number of steps will scale as . Even high-dimensional polytopes will stop flipping quickly in general. (A unistable polytope on the other hand can run through at least half of its faces, so there are some very slow ones too).
The expected minimum distance between two points on this kind of random polytope scales as (if they were optimally distributed it would be ). At the same time, if N is relatively small compared to D (the polytope is simplex-like), the average diameter (the longest edge) of each face seems to approach . Why? I think this is because , the mean of a flipped k=2 Weibull distribution that shows up because of extreme value theory. Meanwhile the average and median cord length between random points on hyperspheres tends towards . Faces hence tends to be fairly wide unless N is large compared to D, but there will typically always be a few very narrow ones that are tricky to balance on.
Stacking no-slip polytopes
What about stacking polytopes?
If you put a polytope on top of another one (assuming no slipping) at first it seems you need to use a stable face of the top polytope, but this is not enough nor necessary.
Since the underlying face is likely tilted from the horizontal, the vertical projection of the center of mass has to be within the top face. The upper polytope can be rotated, moving the projection point. The tilt angle (or rather, tilt angles – we are doing this in higher dimensions, remember?) generates a hypersphere of radius around the normal projection point (which is at distance d from the center of mass) where the vertical projection can intersect the face. Only parts of the hypersphere surface that are inside the face represent orientations that are stable. Even an unstable face can (sometimes) be stabilized if you turn it so that the tilted projection is inside, but for sufficiently high angles the hypersphere will be bigger than the face and it cannot be stable.
Stability of polyhedron on tilted surface. The line of gravity from the center of mass intersects the inside the bottom face, so the polyhedron is resting stably. Turning the polyhedron will move the line to some point on the circle, but since all points on the circle are inside the face all orientations are stable.Stability of polyhedron on tilted surface. The line of gravity from the center of mass intersects the outside the bottom face, so the polyhedron is unstable and will flip over. Turning the polyhedron will move the line to some other point on the circle: since some points on the circle are inside the face there are some orientations that are stable.
Having the top polytope stay in place is the first requirement. The second is that the bottom polytope should not become unstable. The new center of mass is moved to a point somewhere along the connecting line between the individual centers of mass of the polytopes, with exact position dependent on their volume ratio (note that turning the top polytope can move the center of mass too). This moves the projection point along the plane of the bottom face, and if it gets outside that face the assembly will tip over.
One can imagine this as adding random (D-1)-dimensional vectors of length 1/N until they reach the edge of the face. I am a bit uncertain about the properties of such random walks (all works on decreasing step size walks I have seen have been in 1D). The harmonic random walk in 1D apparently converges with probability 1, so I think the (D-1)-dimensional one also does it since the distance from the origin to the walker will be smaller than if the walker just kept to a 1D line. Since the expected distance traversed in 1D is $latex E[|X|] \approx 1.0761$ this is actually not a very extreme shift. Given the surprisingly large diameters of the faces if the first condition might be tougher to meet than the second, but this is just a guess.
The no slipping constraint is important. If the polytopes are frictionless, then any transverse force will move them. Hence only polytopes that have some parallel top and bottom stable faces can be stacked, and the problem becomes simpler. There are still surprises there, though: even stacks of rectangular blocks can do surprising things. The block stacking problem also demonstrates that one can have 1/N overhangs (counting downwards), enabling arbitrarily large total overhangs without tipping over. With polytopes with shapes that act as counterweights the overhangs can be even larger.
Uriel’s stacking problems
This leads to what we might call “Uriel’s stacking problem”: given a collection of no-slip convex D-dimensional polytopes, what is the tallest tower that can be constructed from them?
I suspect that this problem is NP-hard. It sounds very much like a knapsack problem, but there is a dependency on previous steps when you add a new polytope that seem to make it harder. It seems that it would not be too difficult to fool a greedy algorithm just trying to put the next polytope on the most topmost face into adding one that makes subsequent steps too unstable, forcing backtracking.
Another related problem: if the polytopes are random convex hulls of N points, what is the distribution of maximum tower heights? What if we just try random stacking?
And finally, what is the maximum overhang that can be done by stacking polytopes from a given set?
As a side effect of a chat about dynamical systems models of metabolic syndrome, I came up with the following nice little toy model showing two kinds of instability: instability because of insufficient dampening, and instability because of too slow dampening.
Where is a N-dimensional vector, A is a matrix with Gaussian random numbers, and constants. The last term should strictly speaking be written as but I am lazy.
The first term causes chaos, as we will see below. The 1/N factor is just to compensate for the N terms. The middle term represents dampening trying to force the system to the origin, but acting with a delay . The final term keeps the dynamics bounded: as becomes large this term will dominate and bring back the trajectory to the vicinity of the origin. However, it is a soft spring that has little effect close to the origin.
Chaos
Let us consider the obvious fixed point . Is it stable? If we calculate the Jacobian matrix there it becomes . First, consider the case where . The eigenvalues of J will be the ones of a random Gaussian matrix with no symmetry conditions. If it had been symmetric, then Wigner’s semicircle rule implies that they would tend to be distributed as as . However, it turns out that this is true for the non-symmetric Gaussian case too. (and might be true for any i.i.d. random numbers). This means that about half of them will have a positive real part, and that implies that the fixed point is unstable: for the system will be orbiting the origin in some fashion, and generically this means a chaotic attractor.
Stability
If grows the diagonal elements of J will become more and more negative. If they are really negative then we essentially have a matrix with a negative diagonal and some tiny off-diagonal terms: the eigenvalues will almost be the diagonal ones, and they are all negative. The origin is a stable attractive fixed point in this limit.
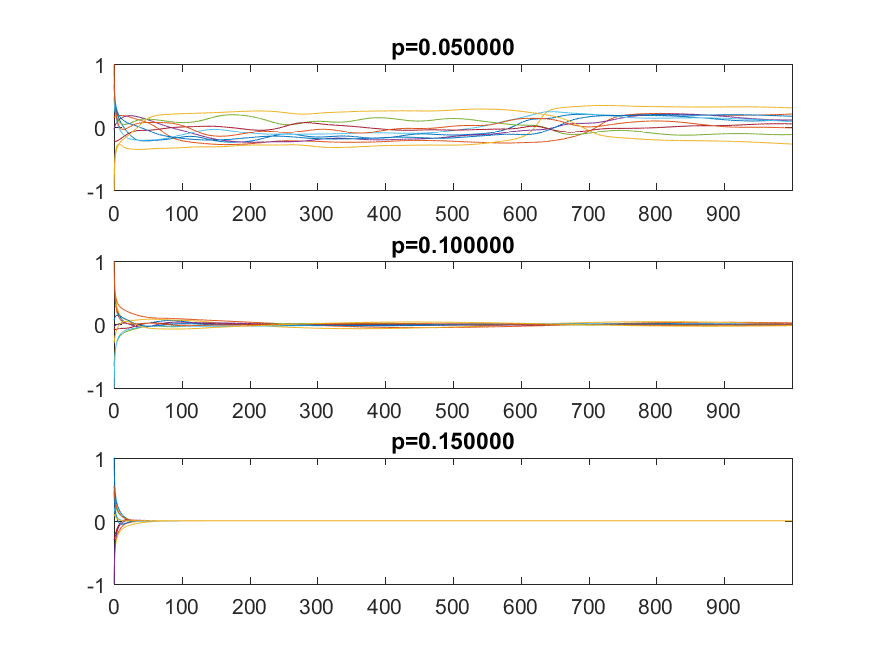
Distribution of real part of the eigenvalues of J=A-pI as the restoring forcing becomes stronger. At p=0.1 all eigenvalues have negative real part.
In between, if we plot the eigenvalues as a function of , we see that the semicircle just linearly moves towards the negative side and when all of it passes over, we shift from the chaotic dynamics to the fixed point. Exactly when this happens depends on the particular A we are looking at and its largest eigenvalue (which is distributed as the Tracy-Widom distribution), but it is generally pretty sharp for large N.
Plots of some x_i over time depending on p. The delay is=1. The top case is chaotic, the middle case is at the crossover point where the eigenvalues become negative, and the lower is beyond it.
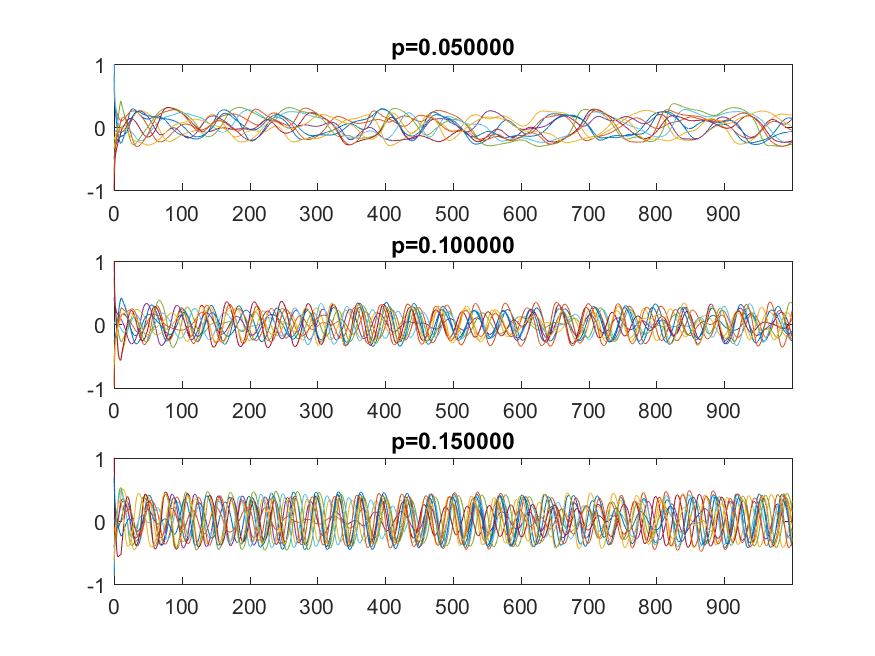
Delay
Plots of x over time depending on p, for delay=100. The top case is chaotic, becoming increasingly periodic as p increases.
But what if becomes large? In this case the force moving the trajectory towards the origin will no longer be based on where it is right now, but on where it was seconds earlier. If is small, then this is just minor noise/bias (and the dynamics is chaotic anyway). If it is large, then the trajectory will be pushed in some essentially random direction: we get instability again.
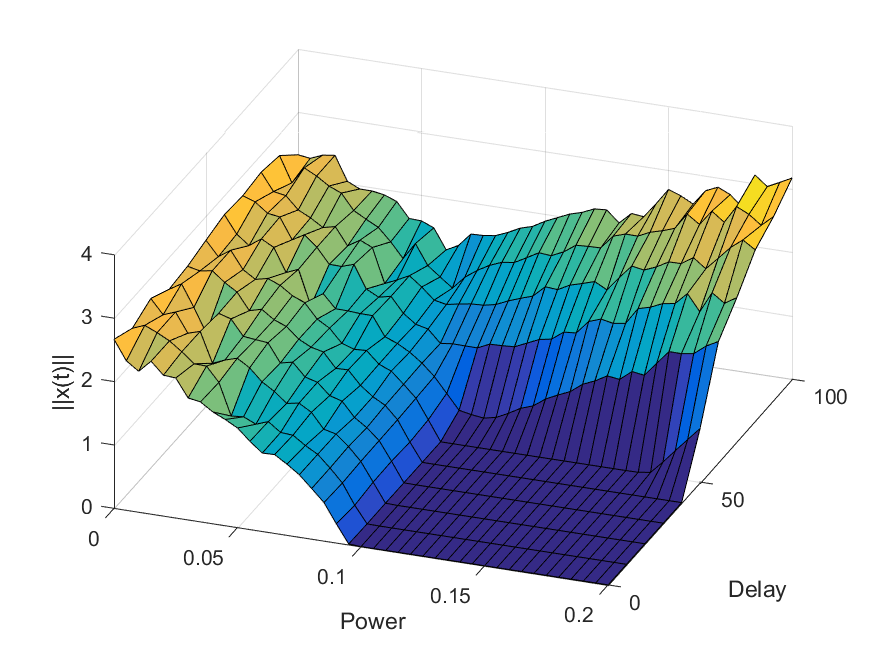
Plot of the average norm |x(t)| for some late value of t as a function of the power and delay. The dark blue square is convergence to zero, the left curved surface is chaotic motion, and the right/back surface is the delay-driven oscillations.
A (very slightly) more stringent way of thinking of it is to plug in into the equation. To simplify, let’s throw away the cubic term since we want to look at behavior close to zero, and let’s use a coordinate system where the matrix is a diagonal matrix . Then for we get , that is, the origin is a fixed point that repels or attracts trajectories depending on its eigenvalues (and we know from above that we can be pretty confident some are positive, so it is unstable overall). For we get . Taylor expansion to the first order and rearranging gives us . The numerator means that as grows, each eigenvalue will eventually get a negative real part: that particular direction of dynamics becomes stable and attracted to the origin. But the denominator can sabotage this: it gets large enough it can move the eigenvalue anywhere, causing instability.
So there you are: if you try to keep a system stable, make sure the force used is up to the task so the inherent recalcitrance cannot overwhelm it, and make sure the direction actually corresponds to the current state of the system.
Playing with Matlab, I plotted the location of the zeros of a polynomial with normally distributed coefficients in the complex plane. It was nearly a circle:
Zeros of a 100-degree polynomial with normally distributed random coefficients.
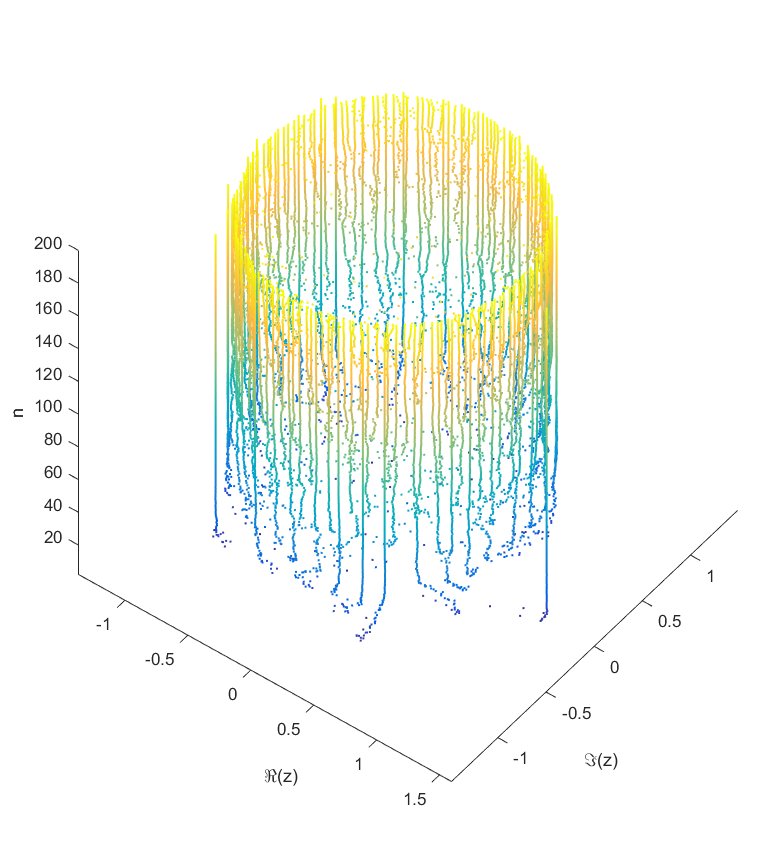
Locations of the zeros of a polynomial with a given sequence of normally distributed coefficients, as a function of degree.
As you add more and more terms to the polynomial the zeros approach the unit circle. Each new term perturbs them a bit: at first they move around a lot as the degree goes up, but they soon stabilize into robust positions (“young” zeros move more than “old” zeros). This seems to be true regardless of whether the coefficients set in “little-endian” or “big-endian” fashion.
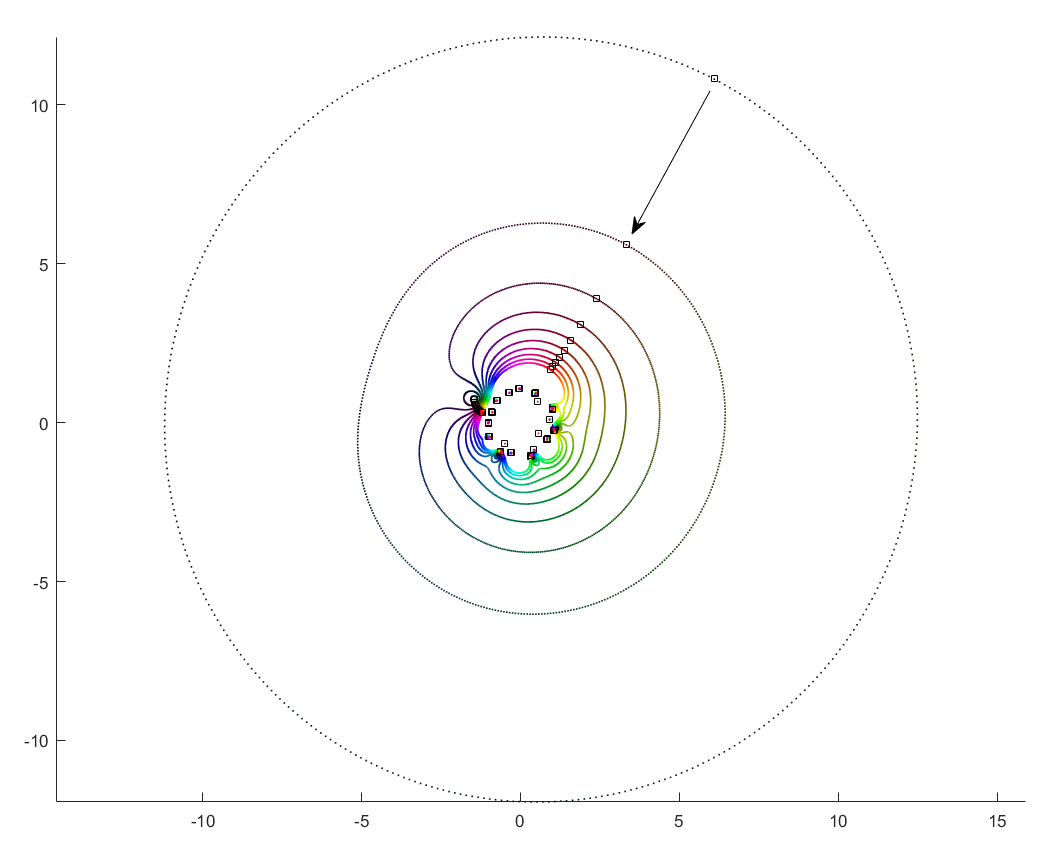
But then I decided to move things around: what if the coefficient on the leading term changed? How would the zeros move? I looked at the polynomial where were from some suitable random sequence and could run around . Since the leading coefficient would start and end up back at 1, I knew all zeros would return to their starting position. But in between, would they jump around discontinuously or follow orderly paths?
Continuity is actually guaranteed, as shown by (Harris & Martin 1987). As you change the coefficients continuously, the zeros vary continuously too. In fact, for polynomials without multiple zeros, the zeros vary analytically with the coefficients.
As runs from 0 to the roots move along different orbits. Some end up permuted with each other.
Movement of the zeros of polynomials with random coefficients as the leading coefficient traverses the unit circle. Colour denotes phase, zeros marked by squares.
For low degrees, most zeros participate in a large cycle. Then more and more zeros emerge inside the unit circle and stay mostly fixed as the polynomial changes. As the degree increases they congregate towards the unit circle, while at least one large cycle wraps most of them, often making snaking detours into the zeros near the unit circle and then broad bows outside it.
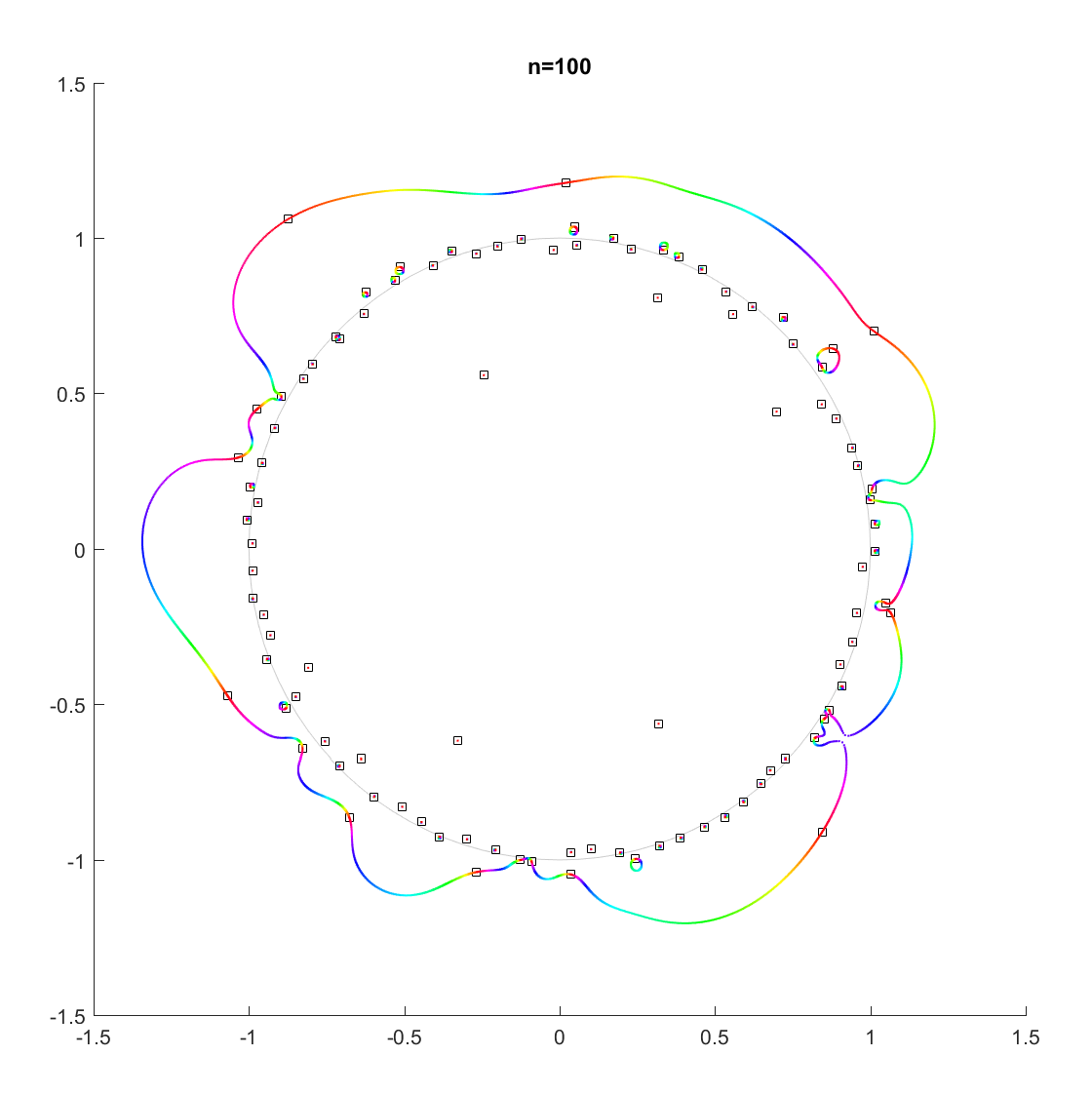
Movement of the zeros of a random degree 100 polynomial.
In the above example, there is a 21-cycle, as well as a 2-cycle around 2 o’clock. The other zeros stay mostly put.
The real question is what determines the cycles? To understand that, we need to change not just the argument but the magnitude of .
Orbits of roots as the magnitude of the leading coefficient increases from zero to one.
What happens if we slowly increase the magnitude of the leading term, letting for a r that increases from zero? It turns out that a new zero of the function zooms in from infinity towards the unit circle. A way of seeing this is to look at the polynomial as : the second term is nonzero and large in most places, so if is small the factor must be large (and opposite) to outweigh it and cause a zero. The exception is of course close to the zeros of , where the perturbation just moves them a tiny bit: there is a counterpart for each of the zeros of among the zeros of . While the new root is approaching from outside, if we play with it will make a turn around the other zeros: it is alone in its orbit, which also encapsulates all the other zeros. Eventually it will start interacting with them, though.
Orbits of roots as the magnitude of the leading coefficient decreases from 100 to one.
If you instead start out with a large leading term, , then the polynomial is essentially and the zeros the n-th roots of . All zeros belong to the same roughly circular orbit, moving together as makes a rotation. But as decreases the shared orbit develops bulges and dents, and some zeros pinch off from it into their own small circles. When does the pinching off happen? That corresponds to when two zeros coincide during the orbit: one continues on the big orbit, the other one settles down to be local. This is the one case where the analyticity of how they move depending on breaks down. They still move continuously, but there is a sharp turn in their movement direction. Eventually we end up in the small term case, with a single zero on a large radius orbit as .
This pinching off scenario also suggests why it is rare to find shared orbits in general: they occur if two zeros coincide but with others in between them (e.g. if we number them along the orbit, , with to separate). That requires a large pinch in the orbit, but since it is overall pretty convex and circle-like this is unlikely.
Allowing to run from to 0 and over would cover the entire complex plane (except maybe the origin): for each z, there is some where . This is fairly obviously . This function has a central pole, surrounded by zeros corresponding to the zeros of . The orbits we have drawn above correspond to level sets , and the pinching off to saddle points of this surface. To get a multi-zero orbit several zeros need to be close together enough to cause a broad valley.
Graph of the log-magnitude of f(z), the function mapping a point in the plane to the value of [latex]c_n[/latex] that causes a zero to appear there for [latex]P_n(z)[/latex].
There you have it, a rough theory of dancing zeros.
I was not first with this idea. In fact, F.F. de Brito used this back in 1992 to demonstrate that there exist complete embedded minimal surfaces in 3-space that are contained between two planes.
Here is the surface defined by the function , the Taylor series that only includes all prime powers, combined with .
Close to zero, the surface is flat. Away from zero it begins to wobble as increasingly high powers in the series begin to dominate. It behaves very much like a higher-degree Enneper surface, but with a wobble that is composed of smaller wobbles. It is cool to consider that this apparently irregular pattern corresponds to the apparently irregular pattern of all primes.
Recently I chatted with a mathematician friend about generating functions in combinatorics. Normally they are treated as a neat symbolic trick: you have a sequence (typically how many there are of some kind of object of size ), you formally define a function , you derive some constraints on the function, and from this you get a formula for the or other useful data. Convergence does not matter, since this is purely symbolic. We used this in our paper counting tie knots. It is a delightful way of solving recurrence relations or bundle up moments of probability distributions.
I innocently wondered if the function (especially its zeroes and poles) held any interesting information. My friend told me that there was analytic combinatorics: you can actually take seriously as a (complex) function and use the powerful machinery of complex analysis to calculate asymptotic behavior for the from the location and type of the “dominant” singularities. He pointed me at the excellent course notes from a course at Princeton linked to the textbook by Philippe Flajolet and Robert Sedgewick. They show a procedure for taking combinatorial objects, converting them symbolically into generating functions, and then get their asymptotic behavior from the properties of the functions. This is extraordinarily neat, both in terms of efficiency and in linking different branches of math.
Plot of z/(1-z-z^2), the generating function of the Fibonacci numbers. It has poles at (1+sqrt(5))/2 (the dominant pole giving the overall asymptotic growth of Fibonacci numbers) and (1-sqrt(5))/2, which does not contribute much to the asymptotic behavior.
In our case, one can show nearly by inspection that the number of Fink-Mao tie knots grow with the number of moves as , while single tuck tie knots grow as .
Analytic functions behaving badly
The second piece of math I found this weekend was about random Taylor series and lacunary functions.
If where are independent random numbers, what kind of functions do we get? Trying it with complex Gaussian produces a disk of convergence with some nondescript function on the inside.
Plot of function with a Gaussian Taylor series. Color corresponds to stereographic mapping of the complex plane to a sphere, with infinity being white and zeros black. The domain of convergence is the unit circle.
Replacing the complex Gaussian with a real one, or uniform random numbers, or even power-law numbers gives the same behavior. They all seem to have radius 1. This is not just a vanilla disk of convergence (where an analytic function reaches a pole or singularity somewhere on the boundary but is otherwise fine and continuable), but a natural boundary – that is, a boundary so dense with poles or singularities that continuation beyond it is not possible at all.
The locus classicus about random Taylor series is apparently Kahane, J.-P. (1985), Some Random Series of Functions. 2nd ed., Cambridge University Press, Cambridge.
A naive handwave argument is that for we have an exponentially decaying sequence of , so if the have some finite average size and not too divergent variance we should expect convergence, while outside the unit circle any nonzero will allow it to diverge. We can even invoke the Markov inequality to argue that a series would converge if converges. However, this is not correct enough for proper mathematics. One entirely possible Gaussian outcome is or worse. We need to speak of probabilistic convergence.
Andrés E. Caicedo has a good post about how to approach it properly. The “trick” is the awesome Kolmogorov zero-one law that implies that since the radius of convergence depends on the entire series X_n rather than any finite subset (and they are all independent) it will be a constant.
This kind of natural boundary disk of convergence may look odd to beginning students of complex analysis: after all, none of the functions we normally encounter behave like this. Except that this is of course selection bias. If you look at the example series for lacunary functions they all look like fairly reasonable sparse Taylor series like $z+z^4+z^8+z^16+^32+\lddots$. In calculus we are used to worrying that the coefficients in front of the z-terms of a series don’t diminish fast enough: having fewer nonzero terms seems entirely innocuous. But as Hadamard showed, it is enough that the size of the gaps grow geometrically for the function to get a natural boundary (in fact, even denser series do this – for example having just prime powers). The same is true for Fourier series. Weierstrass’ famous continuous but nowhere differentiable function is lacunary (in his 1880 paper on analytic continuation he gives the example of an uncontinuable function). In fact, as Emile Borel found and Steinhardt eventually proved in a stricter sense, in general (“almost surely”) a Taylor series isn’t continuable because of boundaries.
The function [latex]sum_p z^p[/latex], where [latex]p[/latex] runs over the primes.
One could of course try to combine the analytic combinatorics with the lacunary stuff. In a sense a lacunary generating function is a worst case scenario for the singularity-measuring methods used in analytical combinatorics since you get an infinite number of them at a finite and equal distance, and now have to average them together somehow. Intuitively this case seems to correspond to counting something that becomes rarer at a geometric rate or faster. But the Borel-Steinhardt results suggest that even objects that do not become rare could have nasty natural boundaries – if the number were due to something close enough to random we should expect estimating asymptotics to be hard. The funniest example I can think of is the number of roots of Chaitin-style Diophantine equations where for each it is an independent arithmetic fact whether there are any: this is hardcore random, and presumably the exact asymptotic growth rate will be uncomputable both practically and theoretically.


")
")

![P(x)=\Pr[X<x]](http://s0.wp.com/latex.php?latex=P%28x%29%3D%5CPr%5BX%3Cx%5D&bg=ffffff&fg=000000&s=0 "P(x)=\Pr[X<x]")
![F_{(k)}(x) = [P(x)]^{k}](http://s0.wp.com/latex.php?latex=F_%7B%28k%29%7D%28x%29+%3D+%5BP%28x%29%5D%5E%7Bk%7D&bg=ffffff&fg=000000&s=0 "F_{(k)}(x) = [P(x)]^{k}")
}(x^*)=1/2")
\sim 1/\sqrt{x}")

=\frac{1}{2(k-1)}\frac{1}{\sqrt{x}}")
=(\sqrt{x}-1)/(k-1)")
![F_{(k)}(x)=[(\sqrt{x}-1)/(k-1)]^k](http://s0.wp.com/latex.php?latex=F_%7B%28k%29%7D%28x%29%3D%5B%28%5Csqrt%7Bx%7D-1%29%2F%28k-1%29%5D%5Ek&bg=ffffff&fg=000000&s=0 "F_{(k)}(x)=[(\sqrt{x}-1)/(k-1)]^k")
2^{-1/k}+1)^2 \approx k^2 - 2k \ln(2)")















 ). Then the ratio of the radii of the inner and outer circle will be
). Then the ratio of the radii of the inner and outer circle will be )/(1+\sin(\pi/n))") . The radii of the circles in the ring will be
. The radii of the circles in the ring will be /2") and their centres are located at distance
and their centres are located at distance /2") from the origin. This produces a staid concentric arrangement. Now invert with relation to an arbitrary circle: all the circles are mapped to other circles, their tangencies preserved. Voila! A suitably eccentric Steiner chain to play with.
from the origin. This produces a staid concentric arrangement. Now invert with relation to an arbitrary circle: all the circles are mapped to other circles, their tangencies preserved. Voila! A suitably eccentric Steiner chain to play with. and radius
and radius =(w+z)r") maps the interior of the unit circle to it. Use the ease of rotating the original concentric ring to produce an animation, and we can reconstruct the fractal.
maps the interior of the unit circle to it. Use the ease of rotating the original concentric ring to produce an animation, and we can reconstruct the fractal.






=1, g(z)=\tanh^2(z)") . Written explicitly as a function from the complex number z to 3-space it is
. Written explicitly as a function from the complex number z to 3-space it is ![\Re([-\tanh(z)(\mathrm{sech}^2(z)-4)/6,i(6z+\tanh(z)(\mathrm{sech}^2(z)-4))/6,z-\tanh(z)])](http://s0.wp.com/latex.php?latex=%5CRe%28%5B-%5Ctanh%28z%29%28%5Cmathrm%7Bsech%7D%5E2%28z%29-4%29%2F6%2Ci%286z%2B%5Ctanh%28z%29%28%5Cmathrm%7Bsech%7D%5E2%28z%29-4%29%29%2F6%2Cz-%5Ctanh%28z%29%5D%29&bg=ffffff&fg=000000&s=0 "\Re([-\tanh(z)(\mathrm{sech}^2(z)-4)/6,i(6z+\tanh(z)(\mathrm{sech}^2(z)-4))/6,z-\tanh(z)])") .
.
 , where the variables are complex. Hanson shows that this is a kind of complex
, where the variables are complex. Hanson shows that this is a kind of complex =e^{2\pi i k_1 / n}\cosh(\theta+\xi i)^{2/n}")
=e^{2 \pi i k_2 / n}\sinh(\theta+\xi i)^{2/n}/i")
") . Each pair
. Each pair  corresponds to one patch of what is essentially a complex catenoid. This is still a 4D object. To plot it, we plot the points
corresponds to one patch of what is essentially a complex catenoid. This is still a 4D object. To plot it, we plot the points,\Re(z_2),\cos(\alpha)\Im(z_1)+\sin(\alpha)\Im(z_2))")
 is some suitable angle to tilt the projection into 3-space. Hanson’s explanation is very clear; I originally reverse-engineered the same formula from
is some suitable angle to tilt the projection into 3-space. Hanson’s explanation is very clear; I originally reverse-engineered the same formula from 

 ): these form the edges of the manifold and strictly speaking I ought to have rendered them to infinity. That would have made it unbounded and somewhat boring to look at: four disks meeting at an angle, with the interesting part hidden inside. By marking the edges we can see that the boundary are four linked wobbly circles:
): these form the edges of the manifold and strictly speaking I ought to have rendered them to infinity. That would have made it unbounded and somewhat boring to look at: four disks meeting at an angle, with the interesting part hidden inside. By marking the edges we can see that the boundary are four linked wobbly circles: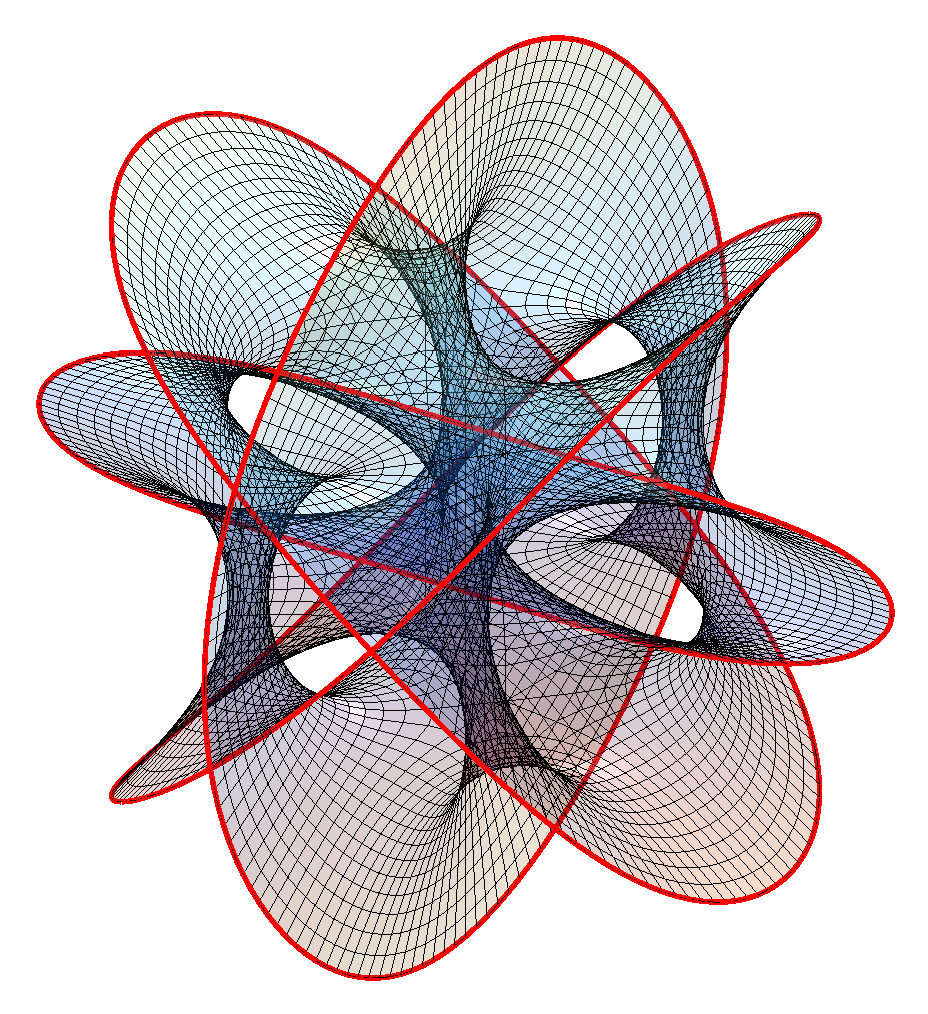

 by
by  to get another surface in an
to get another surface in an  we can get boundaries that are torus-knot-like. This leads to the formulae:
we can get boundaries that are torus-knot-like. This leads to the formulae:=e^{2\pi i k_1 / n_1}\cosh(\theta+\xi i)^{2/n_1}")
=e^{2 \pi i k_2 / n_2}\sinh(\theta+\xi i)^{2/n_2}/i")
 to
to ![[\tanh(x),\tanh(y)]](http://s0.wp.com/latex.php?latex=%5B%5Ctanh%28x%29%2C%5Ctanh%28y%29%5D&bg=ffffff&fg=000000&s=0 "[\tanh(x),\tanh(y)]") . The origin is unchanged, and infinity becomes the edges of the square
. The origin is unchanged, and infinity becomes the edges of the square ![[-1,1]\times [-1,1]](http://s0.wp.com/latex.php?latex=%5B-1%2C1%5D%5Ctimes+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0 "[-1,1]\times [-1,1]") . This is not a conformal map, so things will get squished near the edges.
. This is not a conformal map, so things will get squished near the edges.![(1/2)+(1/2)[\tanh(|z-1|-1), \tanh(|z+1|-1), \tanh(|z-i|-1)]](http://s0.wp.com/latex.php?latex=%281%2F2%29%2B%281%2F2%29%5B%5Ctanh%28%7Cz-1%7C-1%29%2C+%5Ctanh%28%7Cz%2B1%7C-1%29%2C+%5Ctanh%28%7Cz-i%7C-1%29%5D&bg=ffffff&fg=000000&s=0 "(1/2)+(1/2)[\tanh(|z-1|-1), \tanh(|z+1|-1), \tanh(|z-i|-1)]") to map complex coordinates to RGB. This makes the color depend on the distance to 1, -1 and i, making infinity white and zero some drab color (the -1 terms at the end determines the overall color range).
to map complex coordinates to RGB. This makes the color depend on the distance to 1, -1 and i, making infinity white and zero some drab color (the -1 terms at the end determines the overall color range). where
where  is independent random numbers is a
is independent random numbers is a 

 fractal every point on the boundary is a meeting point of the three basins, a
fractal every point on the boundary is a meeting point of the three basins, a 
 , and the center of mass of the polyhedron is just the sum of the simplex centers of mass weighted by their volumes:
, and the center of mass of the polyhedron is just the sum of the simplex centers of mass weighted by their volumes:  . The volume of a simplex is
. The volume of a simplex is \mathrm{det}(X_j)") where
where ![X_j=[x_{1j};x_{2j};\ldots;x_{Dj}]](http://s0.wp.com/latex.php?latex=X_j%3D%5Bx_%7B1j%7D%3Bx_%7B2j%7D%3B%5Cldots%3Bx_%7BDj%7D%5D&bg=ffffff&fg=000000&s=0 "X_j=[x_{1j};x_{2j};\ldots;x_{Dj}]") , the matrix made by sticking together the coordinate vectors of a simplex. Once we know this we can project the center of mass onto the plane of a face by finding its nullspace (the higher dimensional counterpart to a normal)
, the matrix made by sticking together the coordinate vectors of a simplex. Once we know this we can project the center of mass onto the plane of a face by finding its nullspace (the higher dimensional counterpart to a normal) \vec{n}") . Finally, to check whether the projection is inside the face, we can look at the matrix A where each column is the coordinates of one of the faces minus
. Finally, to check whether the projection is inside the face, we can look at the matrix A where each column is the coordinates of one of the faces minus  and the final row just ones, and solve for Ax=b where b is zero except for a one in the last row (
and the final row just ones, and solve for Ax=b where b is zero except for a one in the last row (


 ), but the number of stable faces also increases exponentially with D (as $latex 2^{0.9273 D}$).
), but the number of stable faces also increases exponentially with D (as $latex 2^{0.9273 D}$).
D})=0.8407 D \ln(2) / \ln(D-1) \propto D/\ln(D)") . Even high-dimensional polytopes will stop flipping quickly in general. (A unistable polytope on the other hand can run through at least half of its faces, so there are some very slow ones too).
. Even high-dimensional polytopes will stop flipping quickly in general. (A unistable polytope on the other hand can run through at least half of its faces, so there are some very slow ones too). (if they were optimally distributed it would be
(if they were optimally distributed it would be  ). At the same time, if N is relatively small compared to D (the polytope is simplex-like), the average diameter (the longest edge) of each face seems to approach
). At the same time, if N is relatively small compared to D (the polytope is simplex-like), the average diameter (the longest edge) of each face seems to approach  . Why? I think this is because
. Why? I think this is because ") , the mean of a flipped k=2 Weibull distribution that shows up because of
, the mean of a flipped k=2 Weibull distribution that shows up because of  . Faces hence tends to be fairly wide unless N is large compared to D, but there will typically always be a few very narrow ones that are tricky to balance on.
. Faces hence tends to be fairly wide unless N is large compared to D, but there will typically always be a few very narrow ones that are tricky to balance on.") around the normal projection point (which is at distance d from the center of mass) where the vertical projection can intersect the face. Only parts of the hypersphere surface that are inside the face represent orientations that are stable. Even an unstable face can (sometimes) be stabilized if you turn it so that the tilted projection is inside, but for sufficiently high angles the hypersphere will be bigger than the face and it cannot be stable.
around the normal projection point (which is at distance d from the center of mass) where the vertical projection can intersect the face. Only parts of the hypersphere surface that are inside the face represent orientations that are stable. Even an unstable face can (sometimes) be stabilized if you turn it so that the tilted projection is inside, but for sufficiently high angles the hypersphere will be bigger than the face and it cannot be stable.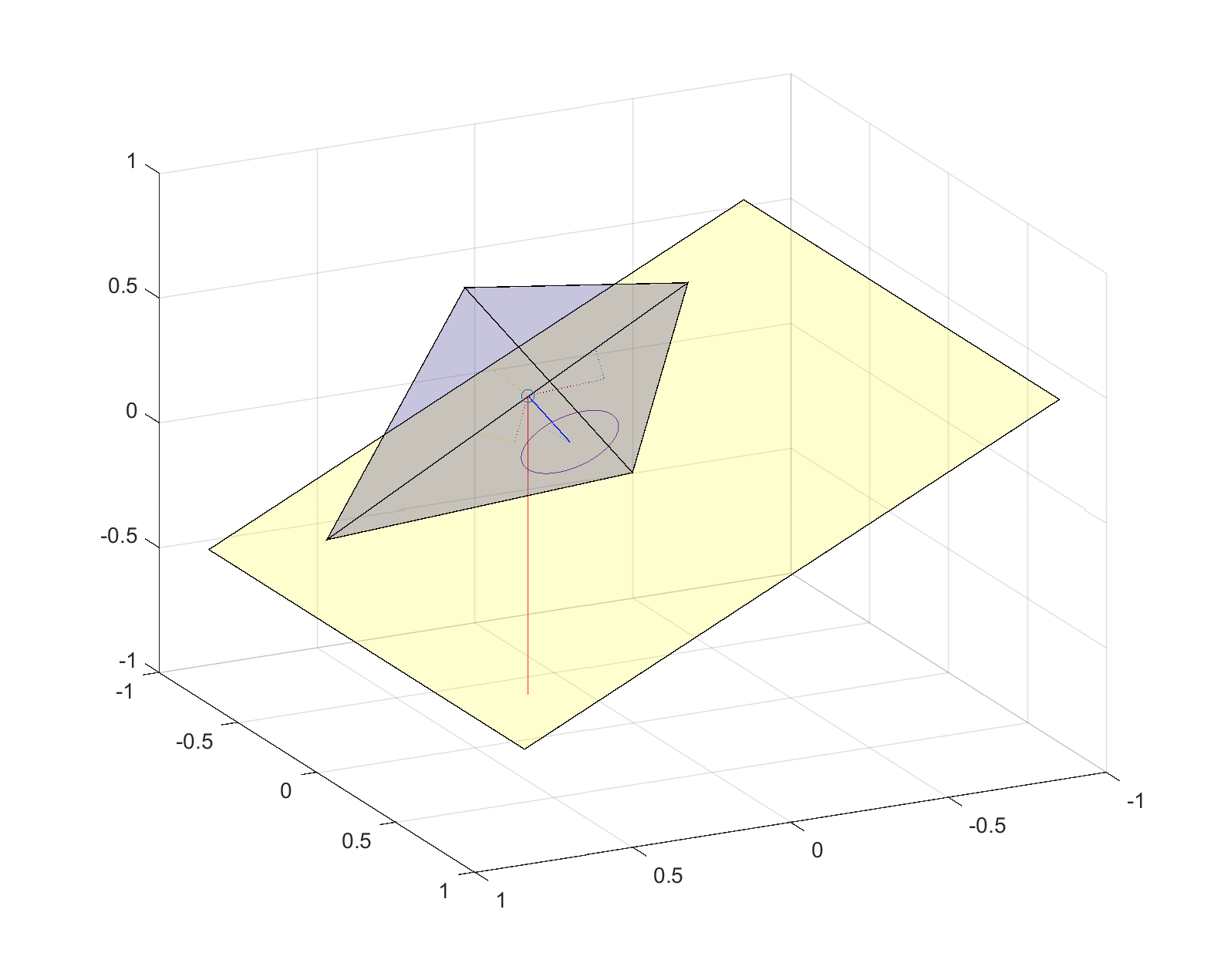
 the first condition might be tougher to meet than the second, but this is just a guess.
the first condition might be tougher to meet than the second, but this is just a guess.
 = Ax(t)/N - px(t-\tau) -x(t)^3")
 matrix with Gaussian random numbers, and
matrix with Gaussian random numbers, and  constants. The last term should strictly speaking be written as
constants. The last term should strictly speaking be written as ||^2 x(t)") but I am lazy.
but I am lazy. . The final term keeps the dynamics bounded: as
. The final term keeps the dynamics bounded: as  becomes large this term will dominate and bring back the trajectory to the vicinity of the origin. However, it is a soft spring that has little effect close to the origin.
becomes large this term will dominate and bring back the trajectory to the vicinity of the origin. However, it is a soft spring that has little effect close to the origin. . Is it stable? If we calculate the Jacobian matrix there it becomes
. Is it stable? If we calculate the Jacobian matrix there it becomes  . First, consider the case where
. First, consider the case where  . The eigenvalues of J will be the ones of a random Gaussian matrix with no symmetry conditions. If it had been symmetric, then
. The eigenvalues of J will be the ones of a random Gaussian matrix with no symmetry conditions. If it had been symmetric, then =(2/\pi)\sqrt{1-\lambda^2}") as
as  . However,
. However,  grows the diagonal elements of J will become more and more negative. If they are really negative then we essentially have a matrix with a negative diagonal and some tiny off-diagonal terms: the eigenvalues will almost be the diagonal ones, and they are all negative. The origin is a stable attractive fixed point in this limit.
grows the diagonal elements of J will become more and more negative. If they are really negative then we essentially have a matrix with a negative diagonal and some tiny off-diagonal terms: the eigenvalues will almost be the diagonal ones, and they are all negative. The origin is a stable attractive fixed point in this limit.
=c_j e^{i\lambda_j t}") into the equation. To simplify, let’s throw away the cubic term since we want to look at behavior close to zero, and let’s use a coordinate system where the matrix is a diagonal matrix
into the equation. To simplify, let’s throw away the cubic term since we want to look at behavior close to zero, and let’s use a coordinate system where the matrix is a diagonal matrix  . Then for
. Then for  , that is, the origin is a fixed point that repels or attracts trajectories depending on its eigenvalues (and we know from above that we can be pretty confident some are positive, so it is unstable overall). For
, that is, the origin is a fixed point that repels or attracts trajectories depending on its eigenvalues (and we know from above that we can be pretty confident some are positive, so it is unstable overall). For  we get
we get  . Taylor expansion to the first order and rearranging gives us
. Taylor expansion to the first order and rearranging gives us /(1 - i p \tau)") . The numerator means that as
. The numerator means that as  gets large enough it can move the eigenvalue anywhere, causing instability.
gets large enough it can move the eigenvalue anywhere, causing instability.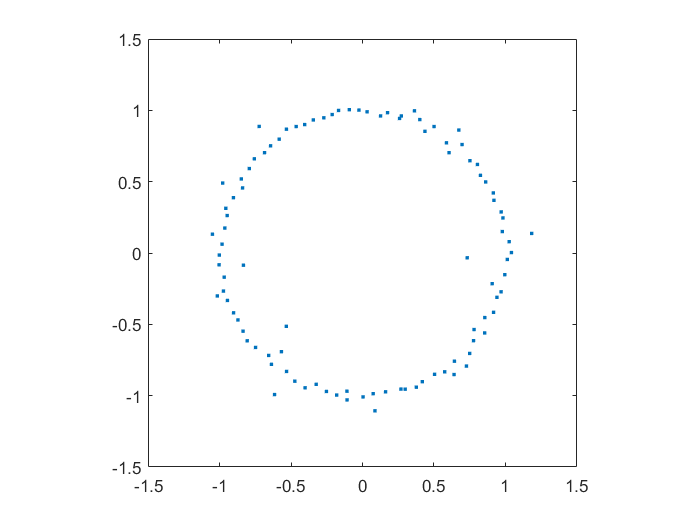
=e^{i\theta} z^n + c_{n-1}z^{n-1}+\ldots+c_1 z + c_0") where
where  were from some suitable random sequence and
were from some suitable random sequence and ![[0,2\pi]](http://s0.wp.com/latex.php?latex=%5B0%2C2%5Cpi%5D&bg=ffffff&fg=000000&s=0 "[0,2\pi]") . Since the leading coefficient would start and end up back at 1, I knew all zeros would return to their starting position. But in between, would they jump around discontinuously or follow orderly paths?
. Since the leading coefficient would start and end up back at 1, I knew all zeros would return to their starting position. But in between, would they jump around discontinuously or follow orderly paths? the roots move along different orbits. Some end up permuted with each other.
the roots move along different orbits. Some end up permuted with each other.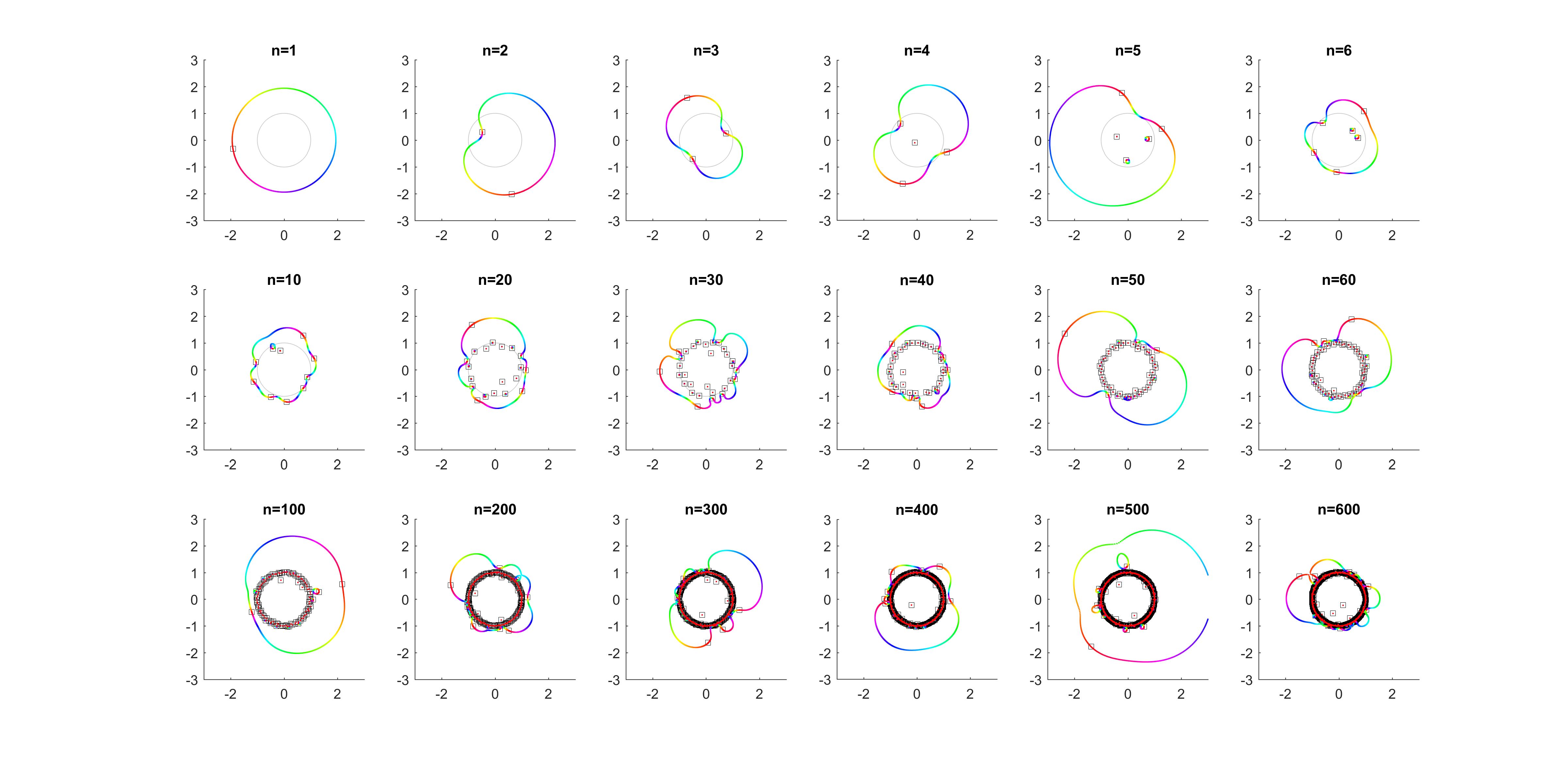
 .
.
 for a r that increases from zero? It turns out that a new zero of the function zooms in from infinity towards the unit circle. A way of seeing this is to look at the polynomial as
for a r that increases from zero? It turns out that a new zero of the function zooms in from infinity towards the unit circle. A way of seeing this is to look at the polynomial as  = c_n z^n + P_{n-1}(z)") : the second term is nonzero and large in most places, so if
: the second term is nonzero and large in most places, so if  factor must be large (and opposite) to outweigh it and cause a zero. The exception is of course close to the zeros of
factor must be large (and opposite) to outweigh it and cause a zero. The exception is of course close to the zeros of ") , where the perturbation just moves them a tiny bit: there is a counterpart for each of the
, where the perturbation just moves them a tiny bit: there is a counterpart for each of the  zeros of
zeros of ") . While the new root is approaching from outside, if we play with
. While the new root is approaching from outside, if we play with 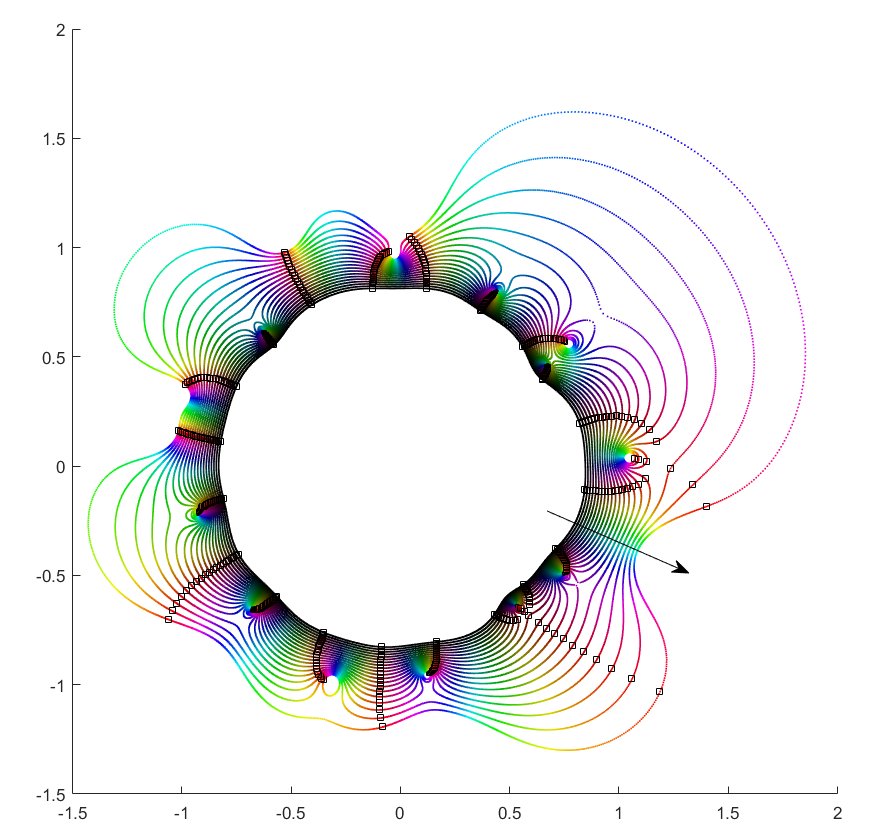
 , then the polynomial is essentially
, then the polynomial is essentially ![P_n(z)=c_nz^n+[\mathrm{small stuff}]](http://s0.wp.com/latex.php?latex=P_n%28z%29%3Dc_nz%5En%2B%5B%5Cmathrm%7Bsmall+stuff%7D%5D&bg=ffffff&fg=000000&s=0 "P_n(z)=c_nz^n+[\mathrm{small stuff}]") and the zeros the n-th roots of
and the zeros the n-th roots of ![-[\mathrm{small stuff}]/c_n](http://s0.wp.com/latex.php?latex=-%5B%5Cmathrm%7Bsmall+stuff%7D%5D%2Fc_n&bg=ffffff&fg=000000&s=0 "-[\mathrm{small stuff}]/c_n") . All zeros belong to the same roughly circular orbit, moving together as
. All zeros belong to the same roughly circular orbit, moving together as  decreases the shared orbit develops bulges and dents, and some zeros pinch off from it into their own small circles. When does the pinching off happen? That corresponds to when two zeros coincide during the orbit: one continues on the big orbit, the other one settles down to be local. This is the one case where the analyticity of how they move depending on
decreases the shared orbit develops bulges and dents, and some zeros pinch off from it into their own small circles. When does the pinching off happen? That corresponds to when two zeros coincide during the orbit: one continues on the big orbit, the other one settles down to be local. This is the one case where the analyticity of how they move depending on  .
. , with
, with  to
to  separate). That requires a large pinch in the orbit, but since it is overall pretty convex and circle-like this is unlikely.
separate). That requires a large pinch in the orbit, but since it is overall pretty convex and circle-like this is unlikely. to 0 and
to 0 and  . This is fairly obviously
. This is fairly obviously  = -P_{n-1}(z)/z^n") . This function has a central pole, surrounded by zeros corresponding to the zeros of
. This function has a central pole, surrounded by zeros corresponding to the zeros of |=\mathrm{const}") , and the pinching off to saddle points of this surface. To get a multi-zero orbit several zeros need to be close together enough to cause a broad valley.
, and the pinching off to saddle points of this surface. To get a multi-zero orbit several zeros need to be close together enough to cause a broad valley.
=\sum_{p \mathrm{is prime}} z^p") , the Taylor series that only includes all prime powers, combined with
, the Taylor series that only includes all prime powers, combined with =1") .
.
=\sum_{n=0}^\infty a_n z^n") , you derive some constraints on the function, and from this you get a formula for the
, you derive some constraints on the function, and from this you get a formula for the ") seriously as a (complex) function and use the powerful machinery of complex analysis to calculate asymptotic behavior for the
seriously as a (complex) function and use the powerful machinery of complex analysis to calculate asymptotic behavior for the 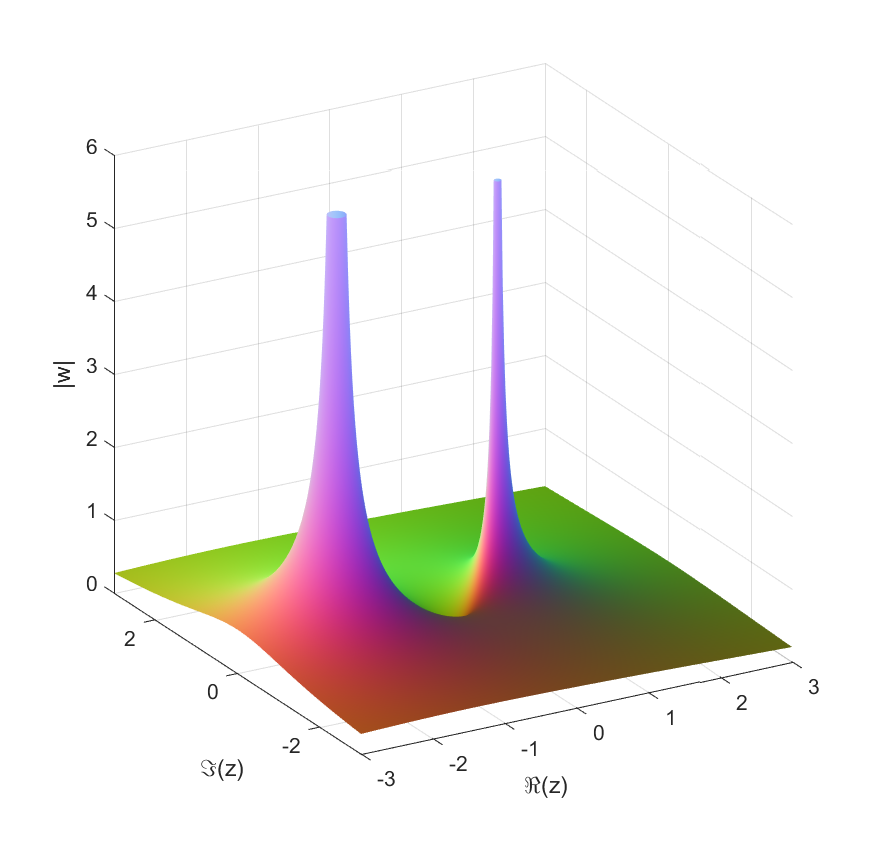
 , while single tuck tie knots grow as
, while single tuck tie knots grow as  .
.=\sum_{n=0}^\infty X_n z^n") where
where  are independent random numbers, what kind of functions do we get? Trying it with complex Gaussian
are independent random numbers, what kind of functions do we get? Trying it with complex Gaussian 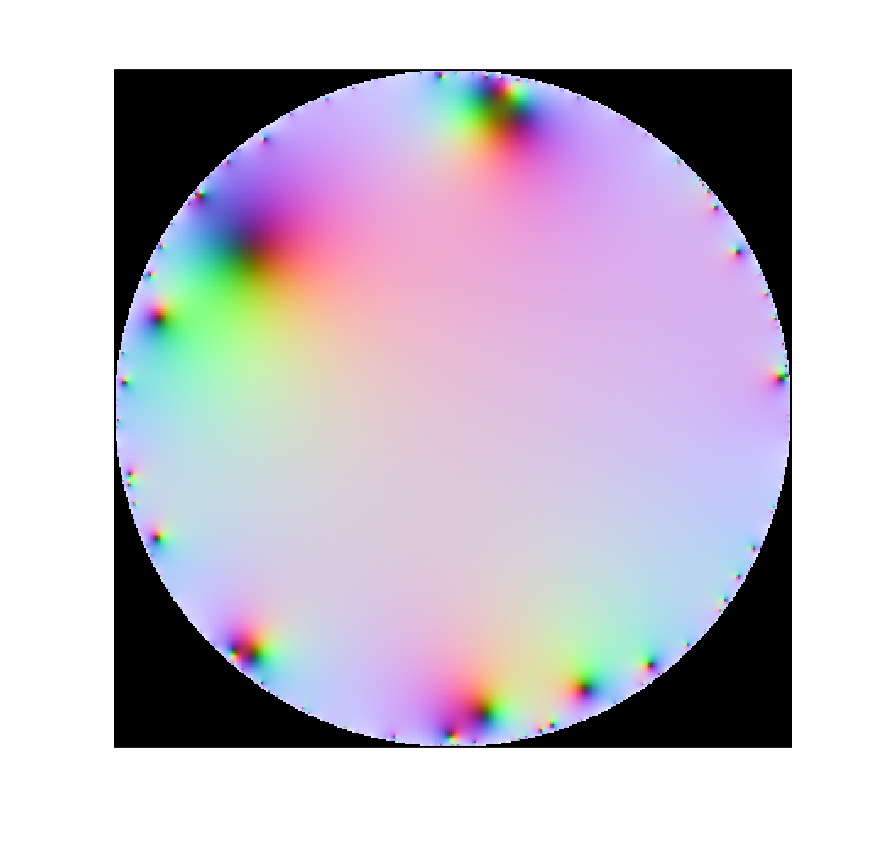
 we have an exponentially decaying sequence of
we have an exponentially decaying sequence of ") and not too divergent variance we should expect convergence, while outside the unit circle any nonzero
and not too divergent variance we should expect convergence, while outside the unit circle any nonzero  \leq E(X)/t") to argue that a series
to argue that a series ") would converge if
would converge if /n") converges. However, this is not correct enough for proper mathematics. One entirely possible Gaussian outcome is
converges. However, this is not correct enough for proper mathematics. One entirely possible Gaussian outcome is  or worse. We need to speak of probabilistic convergence.
or worse. We need to speak of probabilistic convergence. of an uncontinuable function). In fact,
of an uncontinuable function). In fact, 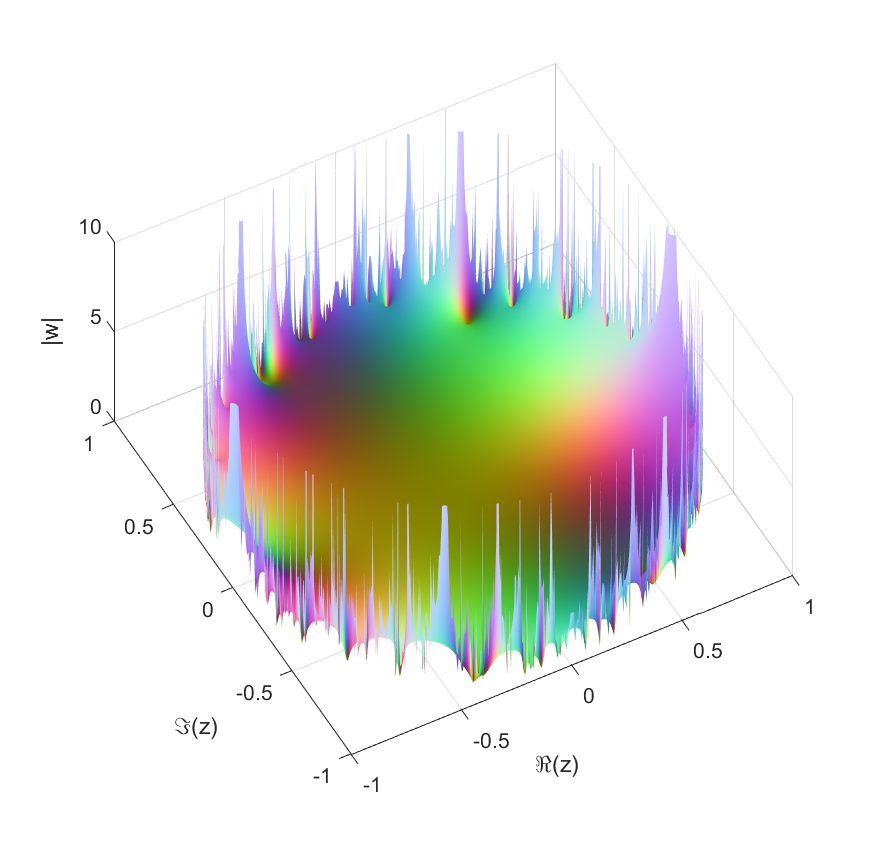
{kind=link}