 The Cyborg Bill of Rights 1.0 is out. Rich MacKinnon suggests the following rights:
The Cyborg Bill of Rights 1.0 is out. Rich MacKinnon suggests the following rights:
FREEDOM FROM DISASSEMBLY
A person shall enjoy the sanctity of bodily integrity and be free from unnecessary search, seizure, suspension or interruption of function, detachment, dismantling, or disassembly without due process.
FREEDOM OF MORPHOLOGY
A person shall be free (speech clause) to express themselves through temporary or permanent adaptions, alterations, modifications, or augmentations to the shape or form of their bodies. Similarly, a person shall be free from coerced or otherwise involuntary morphological changes.
RIGHT TO ORGANIC NATURALIZATION
A person shall be free from exploitive or injurious 3rd party ownerships of vital and supporting bodily systems. A person is entitled to the reasonable accrual of ownership interest in 3rd party properties affixed, attached, embedded, implanted, injected, infused, or otherwise permanently integrated with a person’s body for a long-term purpose.
RIGHT TO BODILY SOVEREIGNTY
A person is entitled to dominion over intelligences and agents, and their activities, whether they are acting as permanent residents, visitors, registered aliens, trespassers, insurgents, or invaders within the person’s body and its domain.
EQUALITY FOR MUTANTS
A legally recognized mutant shall enjoy all the rights, benefits, and responsibilities extended to natural persons.
As a sometime philosopher with a bit of history of talking about rights regarding bodily modification, I of course feel compelled to comment.
What are rights?
 First, what is a right? Clearly anybody can state that we have a right to X, but only some agents and X-rights make sense or have staying power.
First, what is a right? Clearly anybody can state that we have a right to X, but only some agents and X-rights make sense or have staying power.
One kind of rights are legal rights of various kinds. This can be international law, national law, or even informal national codes (for example the Swedish allemansrätten, which is actually not a moral/human right and actually fairly recent). Here the agent has to be some legitimate law- or rule-maker. The US Bill of Rights is an example: the result of a political process that produced legal rights, with relatively little if any moral content. Legal rights need to be enforceable somehow.
Then there are normative moral principles such as fundamental rights (applicable to a person since they are a person), natural rights (applicable because of facts of the world) or divine rights (imposed by God). These are universal and egalitarian: applicable everywhere, everywhen, and the same for everybody. Bentham famously dismissed the idea of natural rights as “nonsense on stilts” and there is a general skepticism today about rights being fundamental norms. But insofar they do exist, anybody can discover and state them. Moral rights need to be doable.
While there may be doubts about the metaphysical nature of rights, if a society agrees on a right it will shape action, rules and thinking in an important way. It is like money: it only gets value by the implicit agreement that it has value and can be exchanged for goods. Socially constructed rights can be proposed by anybody, but they only become real if enough people buy into the construction. They might be unenforceable and impossible to perform (which may over time doom them).
What about the cyborg rights? There is no clear reference to moral principles, and only the last one refers to law. In fact, the preamble states:
Our process begins with a draft of proposed rights that are discussed thoroughly, adopted by convention, and then published to serve as model language for adoption and incorporation by NGOs, governments, and rights organizations.
That is, these rights are at present a proposal for social construction (quite literally) that hopefully will be turned into a convention (a weak international treaty) that eventually may become national law. This also fits with the proposal coming from MacKinnon rather than the General Secretary of the UN – we can all propose social constructions and urge the creation of conventions, treaties and laws.
But a key challenge is to come up with something that can become enforceable at some point. Cyborg bodies might be more finely divisible and transparent than human bodies, so that it becomes hard to regulate these rights. How do you enforce sovereignty against spyware?
Justification
 Why is a right a right? There has to be a reason for a right (typically hinted at in preambles full of “whereas…”)
Why is a right a right? There has to be a reason for a right (typically hinted at in preambles full of “whereas…”)
I have mostly been interested in moral rights. Patrick D. Hopkins wrote an excellent overview “Is enhancement worthy of being a right?” in 2008 where he looks at how you could motivate morphological freedom. He argues that there are three main strategies to show that a right is fundamental or natural:
- That the right conforms to human nature. This requires showing that it fits a natural end. That is, there are certain things humans should aim for, and rights help us live such lives. This is also the approach of natural law accounts.
- That the right is grounded in interests. Rights help us get the kinds of experiences or states of the world that we (rightly) care about. That is, there are certain things that are good for us (e.g. “the preservation of life, health, bodily integrity, play, friendship, classic autonomy, religion, aesthetics, and the pursuit of knowledge”) and the right helps us achieve this. Why those things are good for us is another matter of justification, but if we agree on the laundry list then the right follows if it helps achieve them.
- That the right is grounded in our autonomy. The key thing is not what we choose but that we get to choose: without freedom of choice we are not moral agents. Much of rights by this account will be about preventing others from restricting our choices and not interfering with their choices. If something can be chosen freely and does not harm others, it has a good chance to be a right. However, this is a pretty shallow approach to autonomy; there are more rigorous and demanding ideas of autonomy in ethics (see SEP and IEP for more). This is typically how many fundamental rights get argued (I have a right to my body since if somebody can interfere with my body, they can essentially control me and prevent my autonomy).
One can do this in many ways. For example, David Miller writes on grounding human rights that one approach is to allow people from different cultures to live together as equals, or basing rights on human needs (very similar to interest accounts), or the instrumental use of them to safeguard other (need-based) rights. Many like to include human dignity, another tricky concept.
Social constructions can have a lot of reasons. Somebody wanted something, and this was recognized by others for some reason. Certain reasons are cultural universals, and that make it more likely that society will recognize a right. For example, property seems to be universal, and hence a right to one’s property is easier to argue than a right to paid holidays (but what property is, and what rules surround it, can be very different).
Legal rights are easier. They exist because there is a law or treaty, and the reasons for that are typically a political agreement on something.
It should be noted that many declarations of rights do not give any reasons. Often because we would disagree on the reasons, even if we agree on the rights. The UN declaration of human rights give no hint of where these rights come from (compare to the US declaration of independence, where it is “self-evident” that the creator has provided certain rights to all men). Still, this is somewhat unsatisfactory and leaves many questions unanswered.
So, how do we justify cyborg rights?
In the liberal rights framework I used for morphological freedom we could derive things rather straightforwardly: we have a fundamental right to life, and from this follows freedom from disassembly. We have a fundamental right to liberty, and together with the right to life this leads to a right to our own bodies, bodily sovereignty, freedom of morphology and the first half of the right to organic naturalization. We have a right to our property (typically derived from fundamental rights to seek our happiness and have liberty), and from this the second half of the organic naturalization right follows (we are literally mixing ourselves rather than our work with the value produced by the implants). Equality for mutants follow from having the same fundamental rights as humans (note that the bill talks about “persons”, and most ethical arguments try to be valid for whatever entities count as persons – this tends to be more than general enough to cover cyborg bodies). We still need some justification of the fundamental rights of life, liberty and happiness, but that is outside the scope of this exercise. Just use your favorite justifications.
The human nature approach would say that cyborg nature is such that these rights fit with it. This might be tricky to use as long as we do not have many cyborgs to study the nature of. In fact, since cyborgs are imagined as self-creating (or at least self-modifying) beings it might be hard to find any shared nature… except maybe the self-creation part. As I often like to argue, this is close to Mirandola’s idea of human dignity deriving from our ability to change ourselves.
The interest approach would ask how the cyborg interests are furthered by these rights. That seems pretty straightforward for most reasonably human-like interests. In fact, the above liberal rights framework is to a large extent an interest-based account.
The autonomy account is also pretty straightforward. All cyborg rights except the last are about autonomy.
Could we skip the ethics and these possibly empty constructions? Perhaps: we could see the cyborg bill of rights as a way of making a cyborg-human society possible to live in. We need to tolerate each other and set boundaries on allowed messing around with each other’s bodies. Universals of property lead to the naturalization right, territoriality the sovereignty right universal that actions under self-control are distinguished from those not under control might be taken as the root for autonomy-like motivations that then support the rest.
Which one is best? That depends. The liberal rights/interest system produces nice modular rules, although there will be much arguments on what has precedence. The human nature approach might be deep and poetic, but potentially easy to disagree on. Autonomy is very straightforward (except when the cyborg starts messing with their brain). Social constructivism allows us to bring in issues of what actually works in a real society, not just what perfect isolated cyborgs (on a frictionless infinite plane) should do.
Parts of rights
 One of the cool properties of rights is that they have parts – “the Hohfeldian incidents“, after Wesley Hohfeld (1879–1918) who discovered them. He was thinking of legal rights, but this applies to moral rights too. His system is descriptive – this is how rights work – rather than explaining why the came about or whether this is a good thing. The four parts are:
One of the cool properties of rights is that they have parts – “the Hohfeldian incidents“, after Wesley Hohfeld (1879–1918) who discovered them. He was thinking of legal rights, but this applies to moral rights too. His system is descriptive – this is how rights work – rather than explaining why the came about or whether this is a good thing. The four parts are:
Privileges (alias liberties): I have a right to eat what I want. Someone with a driver’s licence has the privilege to drive. If you have a duty not do do something, then you have no privilege about it.
Claims: I have a claim on my employer to pay my salary. Children have a claim vis-a-vis every adult not to be abused. My employer is morally and legally dutybound to pay, since they agreed to do so. We are dutybound to refrain from abusing children since it is wrong and illegal.
These two are what most talk about rights deal. In the bill, the freedom from disassembly and freedom of morphology are about privileges and claims. The next two are a bit meta, dealing with rights over the first two:
Powers: My boss has the power to order me to research a certain topic, and then I have a duty to do it. I can invite somebody to my home, and then they have the privilege of being there as long as I give it to them. Powers allow us to change privileges and claims, and sometimes powers (an admiral can relieve a captain of the power to command a ship).
Immunities: My boss cannot order me to eat meat. The US government cannot impose religious duties on citizens. These are immunities: certain people or institutions cannot change other incidents.
These parts are then combined into full rights. For example, my property rights to this computer involve the privilege to use the computer, a claim against others to not use the computer, the power to allow others to use it or to sell it to them (giving them the entire rights bundle), and an immunity of others altering these rights. Sure, in practice the software inside is of doubtful loyalty and there are law-enforcement and emergency situation exceptions, but the basic system is pretty clear. Licence agreements typically give you a far
Sometimes we speak about positive and negative rights: if I have a negative right I am entitled to non-interference from others, while a positive right entitles me to some help or goods. My right to my body is a negative right in the sense that others may not prevent me from using or changing my body as I wish, but I do not have a positive right to demand that they help me with some weird bodymorphing. However, in practice there is a lot of blending going on: public healthcare systems give us positive rights to some (but not all) treatment, policing gives us a positive right of protection (whether we want it or not). If you are a libertarian you will tend to emphasize the negative rights as being the most important, while social democrats tend to emphasize state-supported positive rights.
The cyborg bill of rights starts by talking about privileges and claims. Freedom of morphology clearly expresses an immunity to forced bodily change. The naturalization right is about immunity from unwilling change of the rights of parts, and an expression of a kind of power over parts being integrated into the body. Sovereignty is all about power over entities getting into the body.
The right of bodily sovereignty seems to imply odd things about consensual sex – once there is penetration, there is dominion. And what about entities that are partially inside the body? I think this is because it is trying to reinvent some of the above incidents. The aim is presumably to cover pregnancy/abortion, what doctors may do, and other interventions at the same time. The doctor case is easy, since it is roughly what we agree on today: we have the power to allow doctors to work on our bodies, but we can also withdraw this whenever we want
Some other thoughts
 The recent case where the police subpoenad the pacemaker data of a suspected arsonist brings some of these rights into relief. The subpoena occurred with due process, so it was allowed by the freedom from disassembly. In fact, since it is only information and that it is copied one can argue that there was no real “disassembly”. There have been cases where police wanted bullets lodged in people in order to do ballistics on them, but US courts have generally found that bodily integrity trumps the need for evidence. Maybe one could argue for a derived right to bodily privacy, but social needs can presumably trump this just as it trumps normal privacy. Right now views on bodily integrity and privacy are still based on the assumption that bodies are integral and opaque. In a cyborg world this is no longer true, and the law may well move in a more invasive direction.
The recent case where the police subpoenad the pacemaker data of a suspected arsonist brings some of these rights into relief. The subpoena occurred with due process, so it was allowed by the freedom from disassembly. In fact, since it is only information and that it is copied one can argue that there was no real “disassembly”. There have been cases where police wanted bullets lodged in people in order to do ballistics on them, but US courts have generally found that bodily integrity trumps the need for evidence. Maybe one could argue for a derived right to bodily privacy, but social needs can presumably trump this just as it trumps normal privacy. Right now views on bodily integrity and privacy are still based on the assumption that bodies are integral and opaque. In a cyborg world this is no longer true, and the law may well move in a more invasive direction.
“Legally recognized mutant”? What about mutants denied legal recognition? Legal recognition makes sense for things that the law must differentiate between, not for things the law is blind to. Legally recognized mutants (whatever they are) would be a group that needs to be treated in some special way. If they are just like natural humans they do not need special recognition. We may have laws making it illegal to discriminate against mutants, but this is a law about a certain kind of behavior rather than the recipient. If I racially discriminate against somebody but happens to be wrong about their race, I am still guilty. So the legal recognition part does not do any work in this right.
And why just mutants? Presumably the aim here is to cover cyborgs, transhumans and other prefix-humans so they are recognized as legal and moral agents with the same standing. The issue is whether this is achieved by arguing that they were human and “mutated”, or are descended from humans, and hence should have the same standing, or whether this is due to them having the right kind of mental states to be persons. The first approach is really problematic: anencephalic infants are mutants but hardly persons, and basing rights on lineage seems ripe for abuse. The second is much simpler, and allows us to generalize to other beings like brain emulations, aliens, hypothetical intelligent moral animals, or the Swampman.
This links to a question that might deserve a section on its own: who are the rightsholders? Normal human rights typically deal with persons, which at least includes adults capable of moral thinking and acting (they are moral agents). Someone who is incapable, for example due to insanity or being a child, have reduced rights but are still a moral patient (someone we have duties towards). A child may not have full privileges and powers, but they do have claims and immunities. I like to argue that once you can comprehend and make use of a right you deserve to have it, since you have capacity relative to the right. Some people also think prepersons like fertilized eggs are persons and have rights; I think this does not make much sense since they lack any form of mind, but others think that having the potential for a future mind is enough to grant immunity. Tricky border cases like persistent vegetative states, cryonics patients, great apes and weird neurological states keep bioethicists busy.
In the cyborg case the issue is what properties make something a potential rightsholder and how to delineate the border of the being. I would argue that if you have a moral agent system it is a rightsholder no matter what it is made of. That is fine, except that cyborgs might have interchangeable parts: if cyborg A gives her arm to cyborg B, have anything changed? I would argue that the arm switched from being a part of/property of A to being a part of/property of B, but the individuals did not change since the parts that make them moral agents are unchanged (this is just how transplants don’t change identity). But what if A gave part of her brain to B? A turns into A’, B turns into B’, and these may be new agents. Or what if A has outsourced a lot of her mind to external systems running in the cloud or in B’s brain? We may still argue that rights adhere to being a moral agent and person rather than being the same person or a person that can easily be separated from other persons or infrastructure. But clearly we can make things really complicated through overlapping bodies and minds.
Summary
I have looked at the cyborg bill of rights and how it fits with rights in law, society and ethics. Overall it is a first stab at establishing social conventions for enhanced, modular people. It likely needs a lot of tightening up to work, and people need to actually understand and care about its contents for it to have any chance of becoming something legally or socially “real”. From an ethical standpoint one can motivate the bill in a lot of ways; for maximum acceptance one needs to use a wide and general set of motivations, but these will lead to trouble when we try to implement things practically since they give no way of trading one off against another one in a principled way. There is a fair bit of work needed to refine the incidences of the rights, not to mention who is a rightsholder (and why). That will be fun.
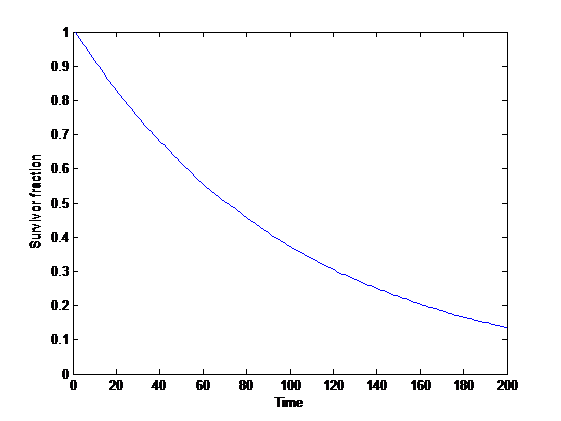

 = p")
 = \exp(-p \lambda t).")
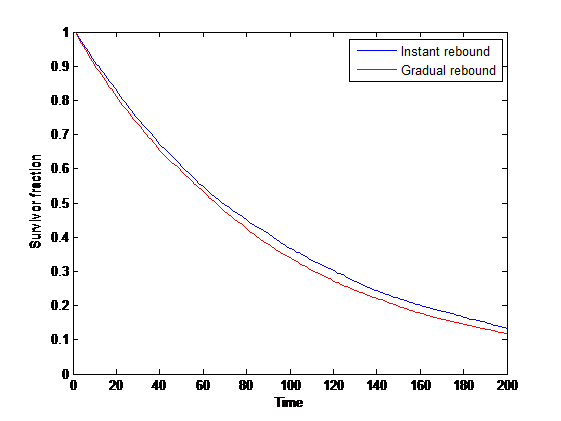

.")

^k.")
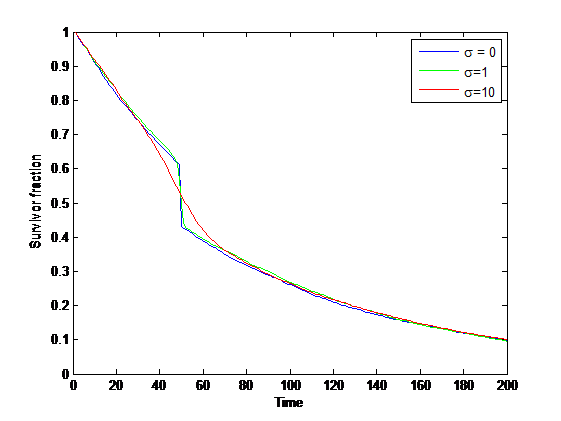


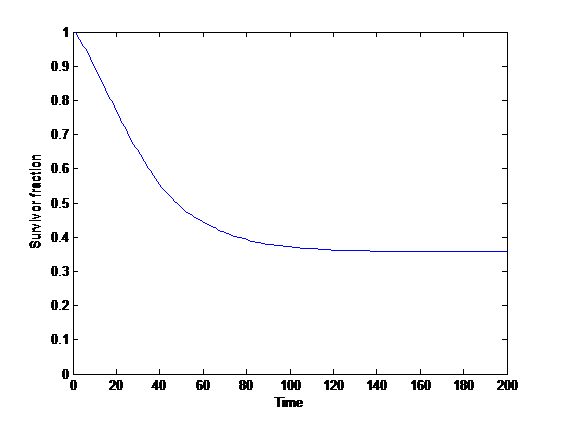
}{S(\mathrm{before }t)}=w")
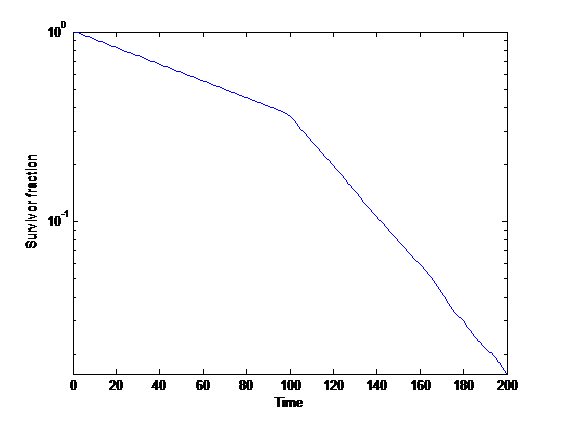
=\Pr(T>t)")

=\frac{d}{dt}(1-S(t))")
")
 = - S'(t)/S(t)")

}\int_{t_0}^\infty S(t)dt.")
 to
to ![[\tanh(x),\tanh(y)]](http://s0.wp.com/latex.php?latex=%5B%5Ctanh%28x%29%2C%5Ctanh%28y%29%5D&bg=ffffff&fg=000000&s=0 "[\tanh(x),\tanh(y)]") . The origin is unchanged, and infinity becomes the edges of the square
. The origin is unchanged, and infinity becomes the edges of the square ![[-1,1]\times [-1,1]](http://s0.wp.com/latex.php?latex=%5B-1%2C1%5D%5Ctimes+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0 "[-1,1]\times [-1,1]") . This is not a conformal map, so things will get squished near the edges.
. This is not a conformal map, so things will get squished near the edges.![(1/2)+(1/2)[\tanh(|z-1|-1), \tanh(|z+1|-1), \tanh(|z-i|-1)]](http://s0.wp.com/latex.php?latex=%281%2F2%29%2B%281%2F2%29%5B%5Ctanh%28%7Cz-1%7C-1%29%2C+%5Ctanh%28%7Cz%2B1%7C-1%29%2C+%5Ctanh%28%7Cz-i%7C-1%29%5D&bg=ffffff&fg=000000&s=0 "(1/2)+(1/2)[\tanh(|z-1|-1), \tanh(|z+1|-1), \tanh(|z-i|-1)]") to map complex coordinates to RGB. This makes the color depend on the distance to 1, -1 and i, making infinity white and zero some drab color (the -1 terms at the end determines the overall color range).
to map complex coordinates to RGB. This makes the color depend on the distance to 1, -1 and i, making infinity white and zero some drab color (the -1 terms at the end determines the overall color range). where
where  is independent random numbers is a
is independent random numbers is a 

 fractal every point on the boundary is a meeting point of the three basins, a
fractal every point on the boundary is a meeting point of the three basins, a 

") the zeros will typically form a curve in the plane. In order to get discrete zeros we typically need to have two functions to produce a zero set. We can think of it as a map from R2 to R2
the zeros will typically form a curve in the plane. In order to get discrete zeros we typically need to have two functions to produce a zero set. We can think of it as a map from R2 to R2 ![F(x)=[f_1(x_1,x_2), f_2(x_1,x_2)]](http://s0.wp.com/latex.php?latex=F%28x%29%3D%5Bf_1%28x_1%2Cx_2%29%2C+f_2%28x_1%2Cx_2%29%5D+&bg=ffffff&fg=000000&s=0 "F(x)=[f_1(x_1,x_2), f_2(x_1,x_2)]") where the x’es are 2D vectors. In this case Newton’s method turns into solving the linear equation system
where the x’es are 2D vectors. In this case Newton’s method turns into solving the linear equation system (x_{n+1}-x_n)=-F(x_n)") where
where ") is the Jacobian matrix (
is the Jacobian matrix ( ) and
) and  now denotes the n’th iterate.
now denotes the n’th iterate.![F=[x^3-x-y, y^3-x-y]](http://s0.wp.com/latex.php?latex=F%3D%5Bx%5E3-x-y%2C+y%5E3-x-y%5D&bg=ffffff&fg=000000&s=0 "F=[x^3-x-y, y^3-x-y]") . Below is a plot of the first and second components (red and green), as well as a blue plane for zero values. The zeros of the function are the three points where red, green and blue meet.
. Below is a plot of the first and second components (red and green), as well as a blue plane for zero values. The zeros of the function are the three points where red, green and blue meet. , one at
, one at  , and one at
, and one at  The middle one has a region of troublesomely similar function values – the red and green surfaces are tangent there.
The middle one has a region of troublesomely similar function values – the red and green surfaces are tangent there.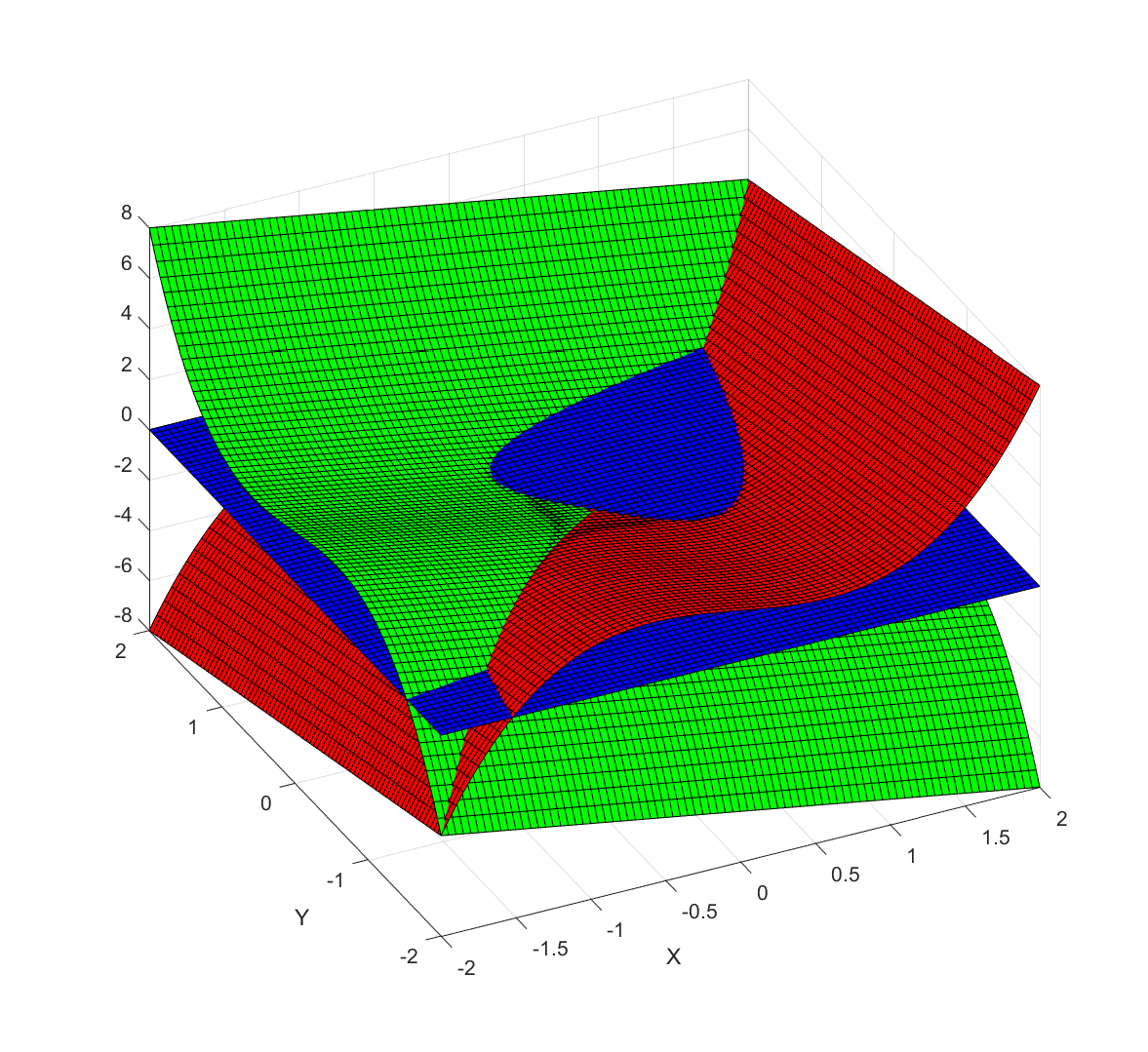
![Behavior of Newton's method in 2D for F=[x^3-x-y, y^3-x-y]. Color denotes value of x+y, with darkening for slow convergence.](http://aleph.se/andart2/wp-content/uploads/2016/12/newton2dp1.png)
 (where
(where  and
and  if the matrix has the usual
if the matrix has the usual ![[a b; c d]](http://s0.wp.com/latex.php?latex=%5Ba+b%3B+c+d%5D&bg=ffffff&fg=000000&s=0 "[a b; c d]") form). So if the trace and determinant are randomly chosen, we should expect a majority of cases to be non-rotational.
form). So if the trace and determinant are randomly chosen, we should expect a majority of cases to be non-rotational.![F=[x \cos(\theta) + y \sin(\theta), x\sin(\theta)+y\cos(\theta)]](http://s0.wp.com/latex.php?latex=F%3D%5Bx+%5Ccos%28%5Ctheta%29+%2B+y+%5Csin%28%5Ctheta%29%2C+x%5Csin%28%5Ctheta%29%2By%5Ccos%28%5Ctheta%29%5D&bg=ffffff&fg=000000&s=0 "F=[x \cos(\theta) + y \sin(\theta), x\sin(\theta)+y\cos(\theta)]") . This is of course just a rotation by the angle theta, and it does not have very interesting zeros.
. This is of course just a rotation by the angle theta, and it does not have very interesting zeros. \cos(\theta)")
 \sin(\theta),")
![(x^3-x-y) \sin(\theta)+(y^3-y-x) \cos(\theta) ]](http://s0.wp.com/latex.php?latex=%28x%5E3-x-y%29+%5Csin%28%5Ctheta%29%2B%28y%5E3-y-x%29+%5Ccos%28%5Ctheta%29+%5D&bg=ffffff&fg=000000&s=0 "(x^3-x-y) \sin(\theta)+(y^3-y-x) \cos(\theta) ]") . The result is fun, but still far from baroque:
. The result is fun, but still far from baroque:

 to make the dynamics even more complex:
to make the dynamics even more complex:
![F=[x^3-3xy^2-1, 3x^2y-y^3]](http://s0.wp.com/latex.php?latex=F%3D%5Bx%5E3-3xy%5E2-1%2C+3x%5E2y-y%5E3%5D&bg=ffffff&fg=000000&s=0 "F=[x^3-3xy^2-1, 3x^2y-y^3]") (which produces the archetypal
(which produces the archetypal =z^3-1") Newton fractal).
Newton fractal).![Newton fractal for F=[x^3-3xy^2-1, 3x^2y-y^3].](http://aleph.se/andart2/wp-content/uploads/2016/12/newtonpert0.png)
![F=[x^3-3xy^2-1 + \epsilon x, 3x^2y-y^3]](http://s0.wp.com/latex.php?latex=F%3D%5Bx%5E3-3xy%5E2-1+%2B+%5Cepsilon+x%2C+3x%5E2y-y%5E3%5D&bg=ffffff&fg=000000&s=0 "F=[x^3-3xy^2-1 + \epsilon x, 3x^2y-y^3]") , then for
, then for  we get:
we get:







") that maps states and action pairs to a probability of acting that way; this is set using a value function
that maps states and action pairs to a probability of acting that way; this is set using a value function ") where various states are assigned values. Morality in my sense is just the policy function and maybe the value function: they have been learned through interacting with the world in various ways.
where various states are assigned values. Morality in my sense is just the policy function and maybe the value function: they have been learned through interacting with the world in various ways.