Lawrence Krauss is not worried about AI risk (ht to Luke Muelhauser); while much of his complacency is based on a particular view of the trustworthiness and level of common sense exhibited by possible future AI that is pretty impossible to criticise, he makes a particular claim:
First, let’s make one thing clear. Even with the exponential growth in computer storage and processing power over the past 40 years, thinking computers will require a digital architecture that bears little resemblance to current computers, nor are they likely to become competitive with consciousness in the near term. A simple physics thought experiment supports this claim:
Given current power consumption by electronic computers, a computer with the storage and processing capability of the human mind would require in excess of 10 Terawatts of power, within a factor of two of the current power consumption of all of humanity. However, the human brain uses about 10 watts of power. This means a mismatch of a factor of 1012, or a million million. Over the past decade the doubling time for Megaflops/watt has been about 3 years. Even assuming Moore’s Law continues unabated, this means it will take about 40 doubling times, or about 120 years, to reach a comparable power dissipation. Moreover, each doubling in efficiency requires a relatively radical change in technology, and it is extremely unlikely that 40 such doublings could be achieved without essentially changing the way computers compute.
This claim has several problems. First, there are few, if any, AI developers who think that we must stay with current architectures. Second, more importantly, the community concerned with superintelligence risk is generally agnostic about how soon smart AI could be developed: it doesn’t have to happen soon for us to have a tough problem in need of a solution, given how hard AI value alignment seems to be. And third, consciousness is likely irrelevant for instrumental intelligence; maybe the word is just used as a stand-in for some equally messy term like “mind”, “common sense” or “human intelligence”.
The interesting issue is however what energy requirements and computational power tells us about human and machine intelligence, and vice versa.
Computer and brain emulation energy use
 I have earlier on this blog looked at the energy requirements of the Singularity. To sum up, current computers are energy hogs requiring 2.5 TW of power globally, with an average cost around 25 nJ per operation. More efficient processors are certainly possible (a lot of the current ones are old and suboptimal). For example, current GPUs consume about a hundred Watts and have
I have earlier on this blog looked at the energy requirements of the Singularity. To sum up, current computers are energy hogs requiring 2.5 TW of power globally, with an average cost around 25 nJ per operation. More efficient processors are certainly possible (a lot of the current ones are old and suboptimal). For example, current GPUs consume about a hundred Watts and have  transistors, reaching performance in the 100 Gflops range, one nJ per flop. Koomey’s law states that the energy cost per operation halves every 1.57 years (not 3 years as Krauss says). So far the growth of computing capacity has grown at about the same pace as energy efficiency, making the two trends cancel each other. In the end, Landauer’s principle gives a lower bound of
transistors, reaching performance in the 100 Gflops range, one nJ per flop. Koomey’s law states that the energy cost per operation halves every 1.57 years (not 3 years as Krauss says). So far the growth of computing capacity has grown at about the same pace as energy efficiency, making the two trends cancel each other. In the end, Landauer’s principle gives a lower bound of ") J per irreversible operation; one can circumvent this by using reversible or quantum computation, but there are costs to error correction – unless we use extremely slow and cold systems in the current era computation will be energy-intensive.
J per irreversible operation; one can circumvent this by using reversible or quantum computation, but there are costs to error correction – unless we use extremely slow and cold systems in the current era computation will be energy-intensive.
I am not sure what brain model Krauss bases his estimate on, but 10 TW/25 nJ =  operations per second (using slightly more efficient GPUs ups it to
operations per second (using slightly more efficient GPUs ups it to  flops). Looking at the estimates of brain computational capacity in appendix A of my old roadmap, this is higher than most. The only estimate that seem to be in the same ballpark is (Thagard 2002), which argues that the number of computational elements in the brain are far greater than the number of neurons (possibly even individual protein molecules). This is a fairly strong claim, to say the least. Especially since current GPUs can do a somewhat credible job of end-to-end speech recognition and transcription: while that corresponds to a small part of a brain, it is hardly
flops). Looking at the estimates of brain computational capacity in appendix A of my old roadmap, this is higher than most. The only estimate that seem to be in the same ballpark is (Thagard 2002), which argues that the number of computational elements in the brain are far greater than the number of neurons (possibly even individual protein molecules). This is a fairly strong claim, to say the least. Especially since current GPUs can do a somewhat credible job of end-to-end speech recognition and transcription: while that corresponds to a small part of a brain, it is hardly  of a brain.
of a brain.
Generally, assuming a certain number of operations per second in a brain and then calculating an energy cost will give you any answer you want. There are people who argue that what really matters is the tiny conscious bandwidth (maybe 40 bits/s or less) and that over a lifetime we may only learn a gigabit. I used to  flops just to be on the safe side in one post. AIimpacts.org has collected several estimates, getting the median estimate
flops just to be on the safe side in one post. AIimpacts.org has collected several estimates, getting the median estimate  . They have also argued in favor of using TEPS (traversed edges per second) rather than flops, suggesting around
. They have also argued in favor of using TEPS (traversed edges per second) rather than flops, suggesting around  TEPS for a human brain – a level that is soon within reach of some systems.
TEPS for a human brain – a level that is soon within reach of some systems.
(Lots of apples-to-oranges comparisions here, of course. A single processor operation may or may not correspond to a floating point operation, let alone to what a GPU does or a TEPS. But we are in the land of order-of-magnitude estimates.)
Brain energy use
 We can turn things around: what does the energy use of human brains tell us about their computational capacity?
We can turn things around: what does the energy use of human brains tell us about their computational capacity?
Ralph Merkle calculated back in 1989 that given 10 Watts of usable energy per human brain, and that the cost of each jump past a node of Ranvier cost  J, producing
J, producing  such operations. He estimated this was about equal to the number of synaptic operations, ending up with
such operations. He estimated this was about equal to the number of synaptic operations, ending up with  –
– operations per second.
operations per second.
A calculation I overheard at a seminar by Karlheinz Meier argued the brain uses 20 W power, has 100 billion neurons firing per second, uses  J per action potential, plus it has
J per action potential, plus it has  synapses receiving signals at about 1 Hz, and uses
synapses receiving signals at about 1 Hz, and uses  J per synaptic transmission. One can also do it from the bottom to the top: there are
J per synaptic transmission. One can also do it from the bottom to the top: there are  ATP molecules per action potential,
ATP molecules per action potential,  are needed for synaptic transmission.
are needed for synaptic transmission.  J per ATP gives J per action potential and J per synaptic transmission. Both these converge on the same rough numbers, used to argue that we need much better hardware scaling if we ever want to get to this level of detail.
J per ATP gives J per action potential and J per synaptic transmission. Both these converge on the same rough numbers, used to argue that we need much better hardware scaling if we ever want to get to this level of detail.
Digging deeper into neural energetics, maintaining resting potentials in neurons and glia account for 28% and 10% of the total brain metabolic cost, respectively, while the actual spiking activity is about 13% and transmitter release/recycling plus calcium movement is about 1%. Note how this is not too far from the equipartition in Meier’s estimate. Looking at total brain metabolism this constrains the neural firing rate: more than 3.1 spikes per second per neuron would consume more energy than the brain normally consumes (and this is likely an optimistic estimate). The brain simply cannot afford firing more than 1% of neurons at the same time, so it likely relies on rather sparse representations.
Unmyelinated axons require about 5 nJ/cm to transmit action potentials. In general, the brain gets around it through some current optimization, myelinisation (which also speeds up transmission at the price of increased error rate), and likely many clever coding strategies. Biology is clearly strongly energy constrained. In addition, cooling 20 W through a bloodflow of 750-1000 ml/min is relatively tight given that the arterial blood is already at body temperature.
20 W divided by  J (the Landauer limit at body temperature) suggests a limit of no more than
J (the Landauer limit at body temperature) suggests a limit of no more than  irreversible operations per second. While a huge number, it is just a few orders higher than many of the estimates we have been juggling so far. If we say these operations are distributed across 100 billion neurons (which is at least within an order of magnitude of the real number) we get 160 billion operations per second per neuron; if we instead treat synapses (about 8000 per neuron) as the loci we get 20 million operations per second per synapse.
irreversible operations per second. While a huge number, it is just a few orders higher than many of the estimates we have been juggling so far. If we say these operations are distributed across 100 billion neurons (which is at least within an order of magnitude of the real number) we get 160 billion operations per second per neuron; if we instead treat synapses (about 8000 per neuron) as the loci we get 20 million operations per second per synapse.
Running the full Hodgkin-Huxley neural model at 1 ms resolution requires about 1200 flops, or 1.2 million flops per second of simulation. If we treat a synapse as a compartment (very reasonable IMHO) that is just 16.6 times the Landauer limit: if the neural simulation had multiple digit precision and erased a few of them per operation we would bump into the Landauer limit straight away. Synapses are actually fairly computationally efficient! At least at body temperature: cryogenically cooled computers could of course do way better. And as Izikievich, the originator of the 1200 flops estimate, loves to point out, his model requires just 13 flops: maybe we do not need to model the ion currents like HH to get the right behavior, and can suddenly shave off two orders of magnitude.
Information dissipation in neural networks
Just how much information is lost in neural processing?
A brain is a dynamical system changing internal state in a complicated way (let us ignore sensory inputs for the time being). If we start in a state somewhere within some predefined volume of state-space, over time the state will move to other states – and the initial uncertainty will grow. Eventually the possible volume we can find the state in will have doubled, and we will have lost one bit of information.
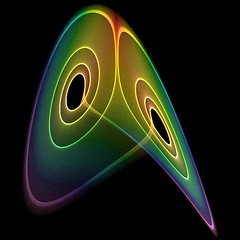 Things are a bit more complicated, since the dynamics can contract along some dimensions and diverge along others: this is described by the Lyapunov exponents. If the trajectory has exponent
Things are a bit more complicated, since the dynamics can contract along some dimensions and diverge along others: this is described by the Lyapunov exponents. If the trajectory has exponent  in some direction nearby trajectories diverge like
in some direction nearby trajectories diverge like -x_b(t)| \propto |x_a(0)-x_b(0)| e^{\lambda t}") in that direction. In a dissipative dynamical system the sum of the exponents is negative: in total, trajectories move towards some attractor set. However, if at least one of the exponents is positive, then this can be a strange attractor that the trajectories endlessly approach, yet they locally diverge from each other and gradually mix. So if you can only measure with a fixed precision at some point in time, you can not certainly tell where the trajectory was before (because of the contraction due to negative exponents has thrown away starting location information), nor exactly where it will be on the attractor in the future (because the positive exponents are amplifying your current uncertainty).
in that direction. In a dissipative dynamical system the sum of the exponents is negative: in total, trajectories move towards some attractor set. However, if at least one of the exponents is positive, then this can be a strange attractor that the trajectories endlessly approach, yet they locally diverge from each other and gradually mix. So if you can only measure with a fixed precision at some point in time, you can not certainly tell where the trajectory was before (because of the contraction due to negative exponents has thrown away starting location information), nor exactly where it will be on the attractor in the future (because the positive exponents are amplifying your current uncertainty).
A measure of the information loss is the Kolmogorov-Sinai entropy, which is bounded by  , the positive Lyapunov exponents (equality holds for Axiom A attractors). So if we calculate the KS-entropy of a neural system, we can estimate how much information is being thrown away per unit of time.
, the positive Lyapunov exponents (equality holds for Axiom A attractors). So if we calculate the KS-entropy of a neural system, we can estimate how much information is being thrown away per unit of time.
Monteforte and Wolf looked at one simple neural model, the theta-neuron (presentation). They found a KS-entropy of roughly 1 bit per neuron and spike over a fairly large range of parameters. Given the above estimates of about one spike per second per neuron, this gives us an overall information loss of  bits/s in the brain, which is
bits/s in the brain, which is  W at the Landauer limit – by this account, we are some 11 orders of magnitude away from thermodynamic perfection. In this picture we should regard each action potential corresponding to roughly one irreversible yes/no decision: a not too unreasonable claim.
W at the Landauer limit – by this account, we are some 11 orders of magnitude away from thermodynamic perfection. In this picture we should regard each action potential corresponding to roughly one irreversible yes/no decision: a not too unreasonable claim.
I begun to try to estimate the entropy and Lyapunov exponents of the Izikievich network to check for myself, but decided to leave this for another post. The reason is that calculating the Lyapunov exponents from time series is a pretty delicate thing, especially when there is noise. And the KS-dimension is even more noise-sensitive. In research on EEG data (where people have looked at the dimension of chaotic attractors and their entropies to distinguish different mental states and epilepsy) an approximate entropy measure is used instead.
It is worth noticing that one can look at cognition as a system with a large-scale dynamics that has one entropy (corresponding to shifting between different high-level mental states) and microscale dynamics with different entropy (corresponding to the neural information processing). It is a safe bet that the biggest entropy costs are on the microscale (fast, numerous simple states) than the macroscale (slow, few but complex states).
Energy of AI
 Where does this leave us in regards to the energy requirements of artificial intelligence?
Where does this leave us in regards to the energy requirements of artificial intelligence?
Assuming the same amount of energy is needed for a human and machine to do a cognitive task is a mistake.
First, as the Izikievich neuron demonstrates, it might be that judicious abstraction easily saves two orders of magnitude of computation/energy.
Special purpose hardware can also save one or two orders of magnitude; using general purpose processors for fixed computations is very inefficient. This is of course why GPUs are so useful for many things: in many cases you just want to perform the same action on many pieces of data rather than different actions on the same piece.
But more importantly, on what level the task is implemented matters. Sorting or summing a list of a thousand elements is a fast computer operation that can be done in memory, but a hour-long task for a human: because of our mental architecture we need to represent the information in a far more redundant and slow way, not to mention perform individual actions on the seconds time-scale. A computer sort uses a tight representation more like our low-level neural circuitry. I have no doubt one could string together biological neurons to perform a sort or sum operation quickly, but cognition happens on a higher, more general level of the system (intriguing speculations about idiot savants aside).
While we have reason to admire brains, they are also unable to perform certain very useful computations. In artificial neural networks we often employ non-local matrix operations like inversion to calculate optimal weights: these computations are not possible to perform locally in a distributed manner. Gradient descent algorithms such as backpropagation are unrealistic in a biological sense, but clearly very successful in deep learning. There is no shortage of papers describing various clever approximations that would allow a more biologically realistic system to perform similar operations – in fact, the brains may well be doing it – but artificial systems can perform them directly, and by using low-level hardware intended for it, very efficiently.
When a deep learning system learns object recognition in an afternoon it beats a human baby by many months. When it learns to do analogies from 1.6 billion text snippets it beats human children by years. Yes, these are small domains, yet they are domains that are very important for humans and would presumably develop as quickly as possible in us.
Biology has many advantages in robustness and versatility, not to mention energy efficiency. But it is also fundamentally limited by what can be built out of cells with a particular kind of metabolism, that organisms need to build themselves from the inside, and the need of solving problems that exist in a particular biospheric environment.
Conclusion
Unless one thinks the human way of thinking is the most optimal or most easily implementable way, we should expect de novo AI to make use of different, potentially very compressed and fast, processes. (Brain emulation makes sense if one either cannot figure out how else to do AI, or one wants to copy extant brains for their properties.) Hence, the costs of brain computation is merely a proof of existence that there are systems that effective – the same mental tasks could well be done by far less or far more efficient systems.
In the end, we may try to estimate fundamental energy costs of cognition to bound AI energy use. If human-like cognition takes a certain number of bit erasures per second, we would get some bound using Landauer (ignoring reversible computing, of course). But as the above discussion has showed, it may be that the actual computational cost needed is just some of the higher level representations rather than billions of neural firings: until we actually understand intelligence we cannot say. And by that point the question is moot anyway.
Many people have the intuition that the cautious approach is always to state “thing’s won’t work”. But this mixes up cautious with conservative (or even reactionary). A better cautious approach is to recognize that “things may work”, and then start checking the possible consequences. If we want a reassuring constraint on why certain things cannot happen it need to be tighter than energy estimates.
 I got challenged on the extropian list, which is a fun reason to make a mini-lecture.
I got challenged on the extropian list, which is a fun reason to make a mini-lecture.