 Introduction
Introduction
Robin Hanson’s The Age of Em is bound to be a classic.
It might seem odd, given that it is both awkward to define what kind of book it is – economics textbook, future studies, speculative sociology, science fiction without any characters? – and that most readers will disagree with large parts of it. Indeed, one of the main reasons it will become classic is that there is so much to disagree with and those disagreements are bound to stimulate a crop of blogs, essays, papers and maybe other books.
This is a very rich synthesis of many ideas with a high density of fascinating arguments and claims per page just begging for deeper analysis and response. It is in many ways like an author’s first science fiction novel (Zindell’s Neverness, Rajaniemi’s The Quantum Thief, and Egan’s Quarantine come to mind) – lots of concepts and throwaway realizations has been built up in the background of the author’s mind and are now out to play. Later novels are often better written, but first novels have the freshest ideas.
The second reason it will become classic is that even if mainstream economics or futurism pass it by, it is going to profoundly change how science fiction treats the concept of mind uploading. Sure, the concept has been around for ages, but this is the first through treatment of what it means to a society. Any science fiction treatment henceforth will partially define itself by how it relates to the Age of Em scenario.
Plausibility
The Age of Em is all about the implications of a particular kind of software intelligence, one based on scanning human brains to produce intelligent software entities. I suspect much of the debate about the book will be more about the feasibility of brain emulations. To many people the whole concept sparks incredulity and outright rejection. The arguments against brain emulation range from pure arguments of incredulity (“don’t these people know how complex the brain is?”) over various more or less well-considered philosophical positions (“don’t these people read Heidegger?” to questioning the inherent functionalist reductionism of the concept) to arguments about technological feasibility. Given that the notion is one many people will find hard to swallow I think Robin spent too little effort bolstering the plausibility, making the book look a bit too much like what Nordmann called if-then ethics: assume some outrageous assumption, then work out the conclusion (which Nordmann finds a waste of intellectual resources). I think one can make fairly strong arguments for the plausibility, but Robin is more interested in working out the consequences. I have a feeling there is a need now for a good defense of the plausibility (this and this might be a weak start, but much more needs to be done).
Scenarios
In this book, I will set defining assumptions, collect many plausible arguments about the correlations we should expect from these assumptions, and then try to combine these many correlation clues into a self-consistent scenario describing relevant variables.
What I find more interesting is Robin’s approach to future studies. He is describing a self-consistent scenario. The aim is not to describe the most likely future of all, nor to push some particular trend the furthest it can go. Rather, he is trying to describe what, given some assumptions, is likely to occur based on our best knowledge and fits with the other parts of the scenario into an organic whole.
The baseline scenario I generate in this book is detailed and self-consistent, as scenarios should be. It is also often a likely baseline, in the sense that I pick the most likely option when such an option stands out clearly. However, when several options seem similarly likely, or when it is hard to say which is more likely, I tend instead to choose a “simple” option that seems easier to analyze.
This baseline scenario is a starting point for considering variations such as intervening events, policy options or alternatives, intended as the center of a cluster of similar scenarios. It typically is based on the status quo and consensus model: unless there is a compelling reason elsewhere in the scenario, things will behave like they have done historically or according to the mainstream models.
As he notes, this is different from normal scenario planning where scenarios are generated to cover much of the outcome space and tell stories of possible unfoldings of events that may give the reader a useful understanding of the process leading to the futures. He notes that the self-consistent scenario seems to be taboo among futurists.
Part of that I think is the realization that making one forecast will usually just ensure one is wrong. Scenario analysis aims at understanding the space of possibility better: hence they make several scenarios. But as critics of scenario analysis have stated, there is a risk of the conjunction fallacy coming into play: the more details you add to the story of a scenario the more compelling the story becomes, but the less likely the individual scenario. The scenario analyst respond by claiming individual scenarios should not be taken as separate things: they only make real sense as part of the bigger structure. The details are to draw the reader into the space of possibility, not to convince them that a particular scenario is the true one.
Robin’s maximal consistent scenario is not directly trying to map out an entire possibility space but rather to create a vivid prototype residing somewhere in the middle of it. But if it is not a forecast, and not a scenario planning exercise, what is it? Robin suggest it is a tool for thinking about useful action:
The chance that the exact particular scenario I describe in this book will actually happen just as I describe it is much less than one in a thousand. But scenarios that are similar to true scenarios, even if not exactly the same, can still be a relevant guide to action and inference. I expect my analysis to be relevant for a large cloud of different but similar scenarios. In particular, conditional on my key assumptions, I expect at least 30% of future situations to be usefully informed by my analysis. Unconditionally, I expect at least 10%.
To some degree this is all a rejection of how we usually think of the future in “far mode” as a neat utopia or dystopia with little detail. Forcing the reader into “near mode” changes the way we consider the realities of the scenario (compare to construal level theory). It makes responding to the scenario far more urgent than responding to a mere possibility. The closest example I know is Eric Drexler’s worked example of nanotechnology in Nanosystems and Engines of Creation.
Again, I expect much criticism quibbling about whether the status quo and mainstream positions actually fit Robin’s assumptions. I have a feeling there is much room for disagreement, and many elements presented as uncontroversial will be highly controversial – sometimes to people outside the relevant field, but quite often to people inside the field too (I am wondering about the generalizations about farmers and foragers). Much of this just means that the baseline scenario can be expanded or modified to include the altered positions, which could provide useful perturbation analysis.
It may be more useful to start from the baseline scenario and ask what the smallest changes are to the assumptions that radically changes the outcome (what would it take to make lives precious? What would it take to make change slow?) However, a good approach is likely to start by investigating robustness vis-à-vis plausible “parameter changes” and use that experience to get a sense of the overall robustness properties of the baseline scenario.
Beyond the Age of Em
But is this important? We could work out endlessly detailed scenarios of other possible futures: why this one? As Robin argued in his original paper, while it is hard to say anything about a world with de novo engineered artificial intelligence, the constraints of neuroscience and economics make this scenario somewhat more predictable: it is a gap in the mist clouds covering the future, even if it is a small one. But more importantly, the economic arguments seem fairly robust regardless of sociological details: copyable human/machine capital is economic plutonium (c.f. this and this paper). Since capital can almost directly be converted into labor, the economy will likely grow radically. This seems to be true regardless of whether we talk about ems or AI, and is clearly a big deal if we think things like the industrial revolution matter – especially a future disruption of our current order.
In fact, people have already criticized Robin for not going far enough. The age described may not last long in real-time before it evolves into something far more radical. As Scott Alexander pointed out in his review and subsequent post, an “ascended economy” where automation and on-demand software labor function together can be a far more powerful and terrifying force than merely a posthuman Malthusian world. It could produce some of the dystopian posthuman scenarios envisioned in Nick Bostrom’s “The future of human evolution“, essentially axiological existential threats where what gives humanity value disappears.
We do not yet have good tools for analyzing this kind of scenarios. Mainstream economics is busy with analyzing the economy we have, not future models. Given that the expertise to reason about the future of a domain is often fundamentally different from the expertise needed in the domain, we should not even assume economists or other social scientists to be able to say much useful about this except insofar they have found reliable universal rules that can be applied. As Robin likes to point out, there are far more results of that kind in the “soft sciences” than outsiders believe. But they might still not be enough to constrain the possibilities.
Yet it would be remiss not to try. The future is important: that is where we will spend the rest of our lives.
If the future matters more than the past, because we can influence it, why do we have far more historians than futurists? Many say that this is because we just can’t know the future. While we can project social trends, disruptive technologies will change those trends, and no one can say where that will take us. In this book, I’ve tried to prove that conventional wisdom wrong.


 may not be the whole story. Hence figuring out the typical size of patches (i.e. the autocorrelation distance) may tell us something relevant.
may not be the whole story. Hence figuring out the typical size of patches (i.e. the autocorrelation distance) may tell us something relevant. factor is
factor is  and grow to radius
and grow to radius  . The rate of intelligence emergence outside panspermias is set to 1 per unit volume (this sets a space scale), and inside a panspermia (since there is more life) it will be
. The rate of intelligence emergence outside panspermias is set to 1 per unit volume (this sets a space scale), and inside a panspermia (since there is more life) it will be  per unit volume. The probability that a given point will be outside a panspermia is
per unit volume. The probability that a given point will be outside a panspermia is r^3 \rho}") .
.} = \frac{1}{1+A(e^{(4 \pi/3)r^3 \rho}-1)}") .
.![d \approx 0.55/\sqrt[3]{\lambda}](http://s0.wp.com/latex.php?latex=d+%5Capprox+0.55%2F%5Csqrt%5B3%5D%7B%5Clambda%7D&bg=ffffff&fg=000000&s=0 "d \approx 0.55/\sqrt[3]{\lambda}") where
where  is the density of civilizations. For the outside panspermia case this is
is the density of civilizations. For the outside panspermia case this is  , while inside it is
, while inside it is ![d_{inside}=0.55/\sqrt[3]{A}](http://s0.wp.com/latex.php?latex=d_%7Binside%7D%3D0.55%2F%5Csqrt%5B3%5D%7BA%7D&bg=ffffff&fg=000000&s=0 "d_{inside}=0.55/\sqrt[3]{A}") . Note that these distances are not dependent on the panspermia sizes, since they come from an independent process (emergence of intelligence given a life-bearing planet rather than how well life spreads from system to system).
. Note that these distances are not dependent on the panspermia sizes, since they come from an independent process (emergence of intelligence given a life-bearing planet rather than how well life spreads from system to system). then there will be no panspermia-induced correlation between civilization locations, since there is less than one civilization per panspermia. For
then there will be no panspermia-induced correlation between civilization locations, since there is less than one civilization per panspermia. For  there will be clustering with a typical autocorrelation distance corresponding to the panspermia size. For even larger panspermias they tend to dominate space (if
there will be clustering with a typical autocorrelation distance corresponding to the panspermia size. For even larger panspermias they tend to dominate space (if ![0.55/\sqrt[3]{A}<r<0.55](http://s0.wp.com/latex.php?latex=0.55%2F%5Csqrt%5B3%5D%7BA%7D%3Cr%3C0.55&bg=ffffff&fg=000000&s=0 "0.55/\sqrt[3]{A}<r<0.55") , the actual distance to the nearest neighbour will be smaller than what one would have predicted from the average values of the parameters of the drake equation.
, the actual distance to the nearest neighbour will be smaller than what one would have predicted from the average values of the parameters of the drake equation.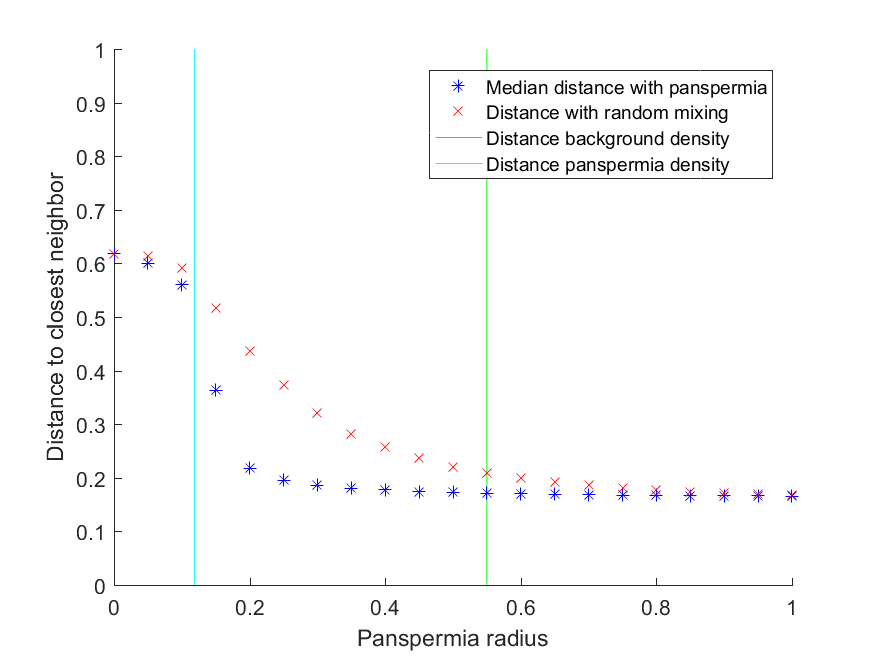
 – the number of panspermias will be Poisson(1) distributed. The background rate of civilizations appearing is 1/10,000, but in panspermias it is 1/100. As I make panspermias larger civilizations become more common and the median distance from a civilization to the next closest civilization falls (blue stars). If I re-sample so the number of civilizations are the same but their locations are uncorrelated I get the red crosses: the distances decline, but they can be more than a factor of 2 larger.
– the number of panspermias will be Poisson(1) distributed. The background rate of civilizations appearing is 1/10,000, but in panspermias it is 1/100. As I make panspermias larger civilizations become more common and the median distance from a civilization to the next closest civilization falls (blue stars). If I re-sample so the number of civilizations are the same but their locations are uncorrelated I get the red crosses: the distances decline, but they can be more than a factor of 2 larger. and
and  can also show spatial patterns, if civilizations spread out from their origin.
can also show spatial patterns, if civilizations spread out from their origin. if we count inhabited systems. If we include
if we count inhabited systems. If we include  where
where  is the expansion speed; if there is a recovery parameter
is the expansion speed; if there is a recovery parameter  corresponding to the time before new waves can emerge we should hence expect spatial correlation length of order
corresponding to the time before new waves can emerge we should hence expect spatial correlation length of order v") . For light-speed expansion and a megayear recovery (typical ecology and fast evolutionary timescale) we would get a length of a million light-years.
. For light-speed expansion and a megayear recovery (typical ecology and fast evolutionary timescale) we would get a length of a million light-years. is low, civilizations will only spread to a small nearby region. When it increases larger and larger networks are colonized (
is low, civilizations will only spread to a small nearby region. When it increases larger and larger networks are colonized ( where the network explodes and reaches nearly anywhere. However, even above this transition there are voids of uncolonized worlds. The correlation length famously scales as
where the network explodes and reaches nearly anywhere. However, even above this transition there are voids of uncolonized worlds. The correlation length famously scales as  , where
, where 
 scales as
scales as  \propto |p-p_c|^\beta") (
( ) and the mean cluster size (excluding the infinite cluster) scales as
) and the mean cluster size (excluding the infinite cluster) scales as  (
( ).
). = 1-(1-\lambda)^{N|p-p_c|^\gamma}")
 . Above the threshold it is essentially 1; there is a small probability
. Above the threshold it is essentially 1; there is a small probability ") of being inside a small cluster, but it tends to be minuscule. Given the silence in the sky, were a percolation model the situation we should conclude either an extremely low
of being inside a small cluster, but it tends to be minuscule. Given the silence in the sky, were a percolation model the situation we should conclude either an extremely low  , and at the right the rate gets multiplied by the longevity term for civilizations
, and at the right the rate gets multiplied by the longevity term for civilizations  years.
years.}{dt}=N_*(t)f_p(t)n_e(t)f_l(t)f_i(t)f_c(t)-(1/L)N")
") corresponding to the first term, we get an expression for the current state:
corresponding to the first term, we get an expression for the current state: = \int_{t_{bigbang}}^{t_{now}} \beta(t) e^{-(1/L) (t_{now}-t)} dt") .
.![d \approx 0.55 [N_* f_p n_e f_l f_i f_c L / V]^{-1/3}](http://s0.wp.com/latex.php?latex=d+%5Capprox+0.55+%5BN_%2A+f_p+n_e+f_l+f_i+f_c+L+%2F+V%5D%5E%7B-1%2F3%7D&bg=ffffff&fg=000000&s=0 "d \approx 0.55 [N_* f_p n_e f_l f_i f_c L / V]^{-1/3}") , where
, where  is the galactic volume. If we are considering parameters such that the number of civilizations per galaxy are low V needs to be increased and the density will go down significantly (by a factor of about 100), leading to a modest jump in expected distance.
is the galactic volume. If we are considering parameters such that the number of civilizations per galaxy are low V needs to be increased and the density will go down significantly (by a factor of about 100), leading to a modest jump in expected distance. being smaller than the panspermia, presumably at least in the parsec range. This is also the scale of close clusters of stars in percolation models.
being smaller than the panspermia, presumably at least in the parsec range. This is also the scale of close clusters of stars in percolation models.

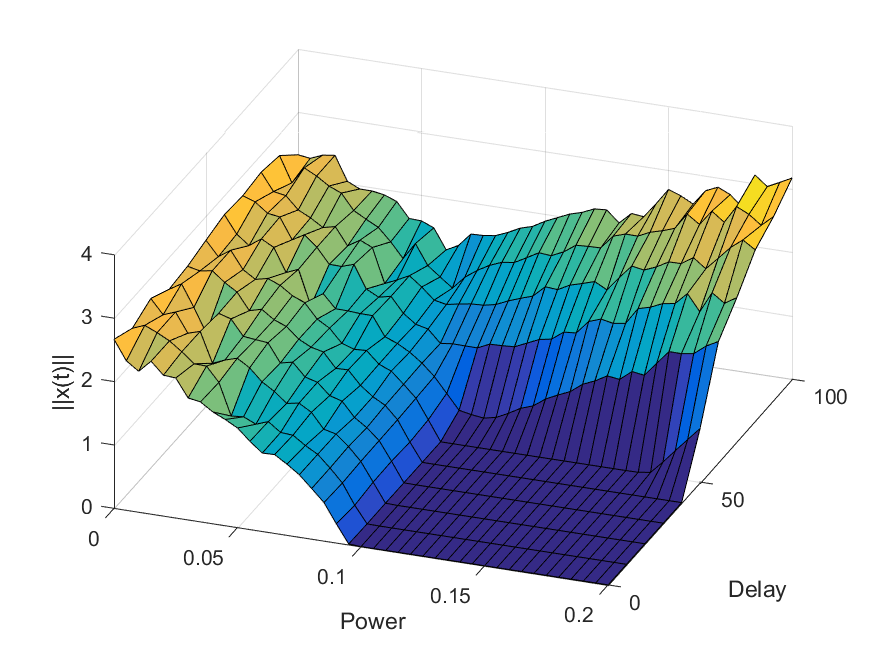
 = Ax(t)/N - px(t-\tau) -x(t)^3")
 is a N-dimensional vector, A is a
is a N-dimensional vector, A is a  matrix with Gaussian random numbers, and
matrix with Gaussian random numbers, and  constants. The last term should strictly speaking be written as
constants. The last term should strictly speaking be written as ||^2 x(t)") but I am lazy.
but I am lazy. . The final term keeps the dynamics bounded: as
. The final term keeps the dynamics bounded: as  becomes large this term will dominate and bring back the trajectory to the vicinity of the origin. However, it is a soft spring that has little effect close to the origin.
becomes large this term will dominate and bring back the trajectory to the vicinity of the origin. However, it is a soft spring that has little effect close to the origin. . Is it stable? If we calculate the Jacobian matrix there it becomes
. Is it stable? If we calculate the Jacobian matrix there it becomes  . First, consider the case where
. First, consider the case where  . The eigenvalues of J will be the ones of a random Gaussian matrix with no symmetry conditions. If it had been symmetric, then
. The eigenvalues of J will be the ones of a random Gaussian matrix with no symmetry conditions. If it had been symmetric, then =(2/\pi)\sqrt{1-\lambda^2}") as
as  . However,
. However, 
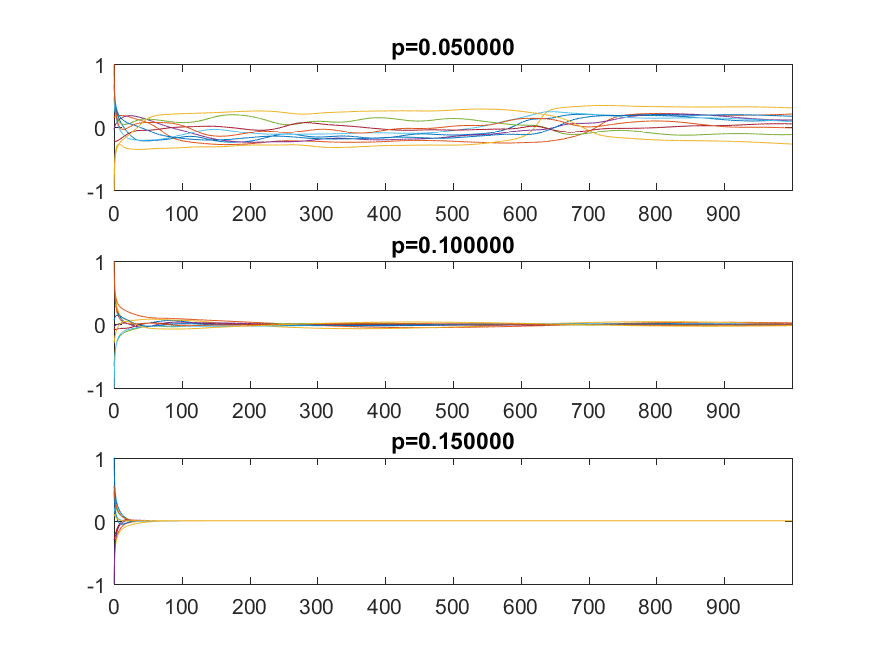
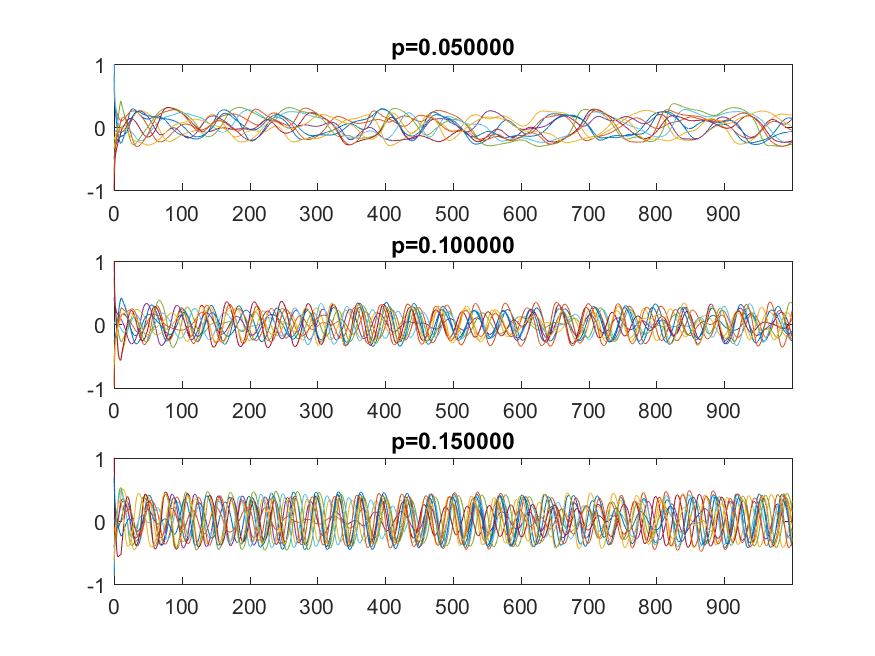
=c_j e^{i\lambda_j t}") into the equation. To simplify, let’s throw away the cubic term since we want to look at behavior close to zero, and let’s use a coordinate system where the matrix is a diagonal matrix
into the equation. To simplify, let’s throw away the cubic term since we want to look at behavior close to zero, and let’s use a coordinate system where the matrix is a diagonal matrix  . Then for
. Then for  , that is, the origin is a fixed point that repels or attracts trajectories depending on its eigenvalues (and we know from above that we can be pretty confident some are positive, so it is unstable overall). For
, that is, the origin is a fixed point that repels or attracts trajectories depending on its eigenvalues (and we know from above that we can be pretty confident some are positive, so it is unstable overall). For  we get
we get  . Taylor expansion to the first order and rearranging gives us
. Taylor expansion to the first order and rearranging gives us /(1 - i p \tau)") . The numerator means that as
. The numerator means that as  gets large enough it can move the eigenvalue anywhere, causing instability.
gets large enough it can move the eigenvalue anywhere, causing instability.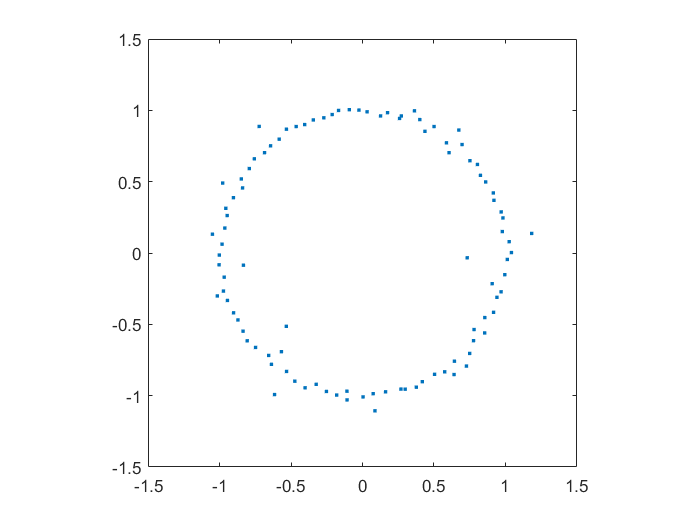
=e^{i\theta} z^n + c_{n-1}z^{n-1}+\ldots+c_1 z + c_0") where
where  were from some suitable random sequence and
were from some suitable random sequence and  could run around
could run around ![[0,2\pi]](http://s0.wp.com/latex.php?latex=%5B0%2C2%5Cpi%5D&bg=ffffff&fg=000000&s=0 "[0,2\pi]") . Since the leading coefficient would start and end up back at 1, I knew all zeros would return to their starting position. But in between, would they jump around discontinuously or follow orderly paths?
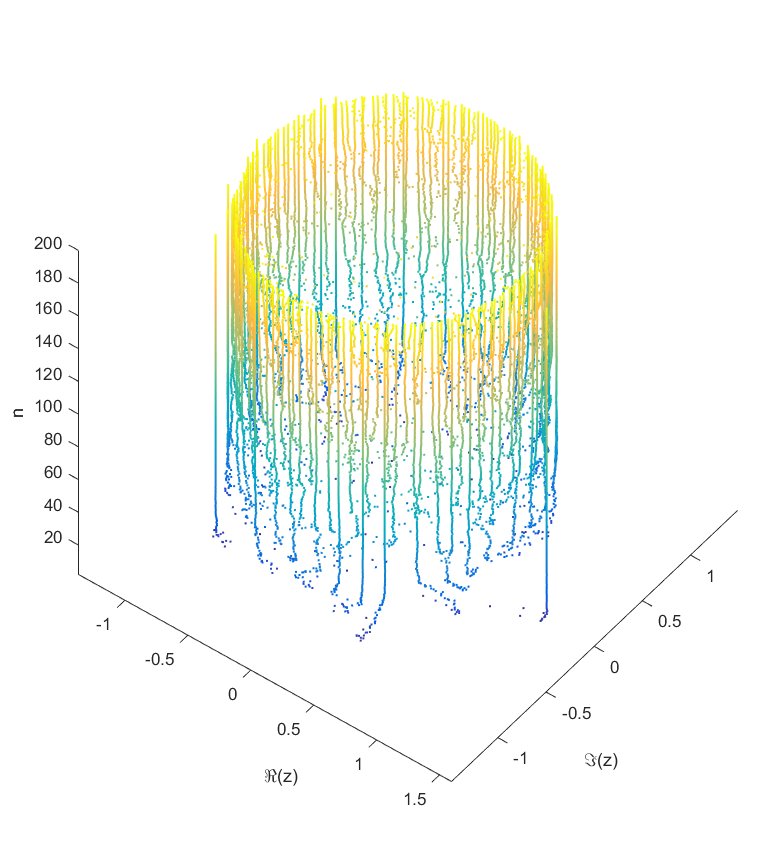
. Since the leading coefficient would start and end up back at 1, I knew all zeros would return to their starting position. But in between, would they jump around discontinuously or follow orderly paths? the roots move along different orbits. Some end up permuted with each other.
the roots move along different orbits. Some end up permuted with each other.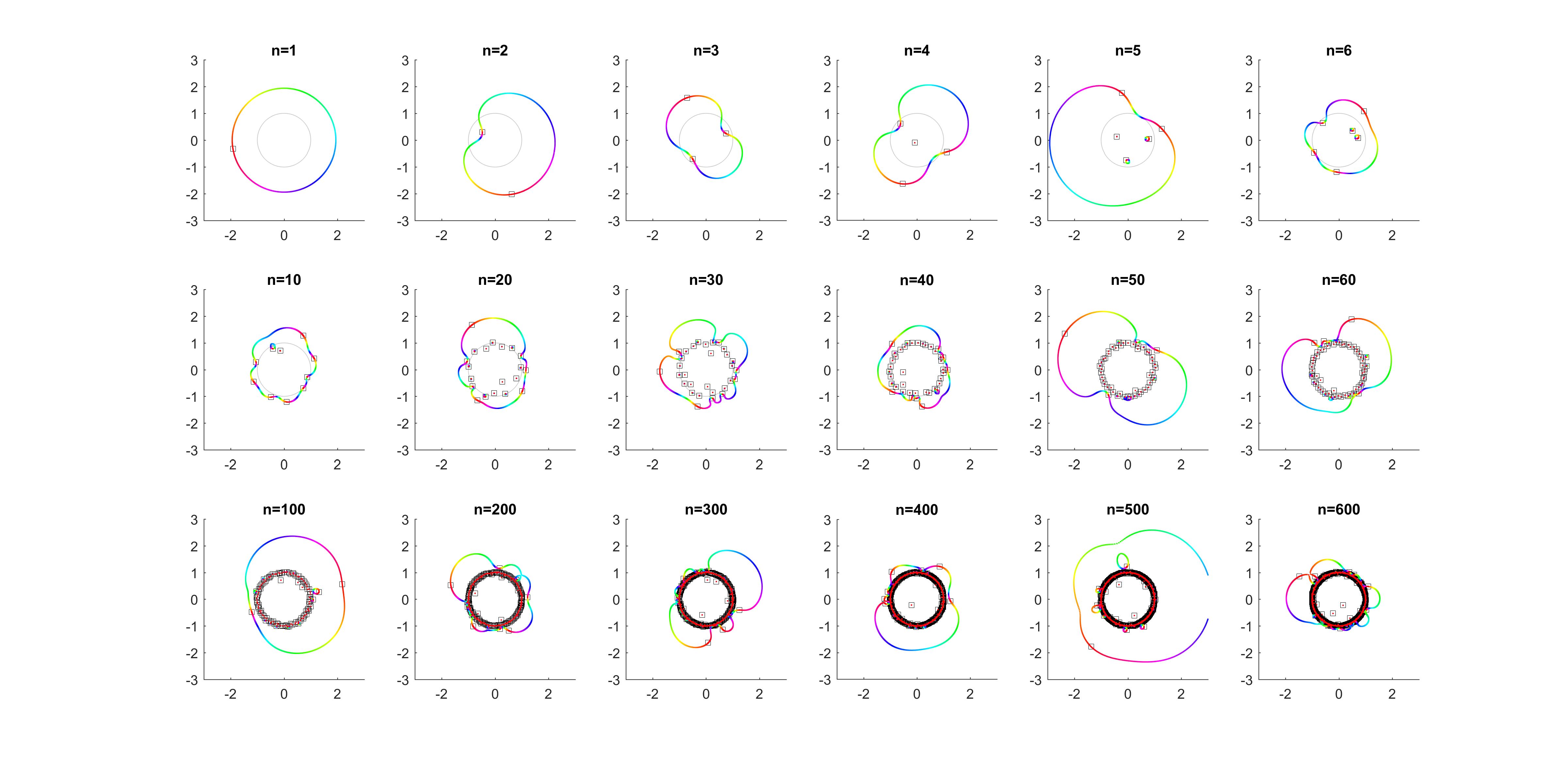
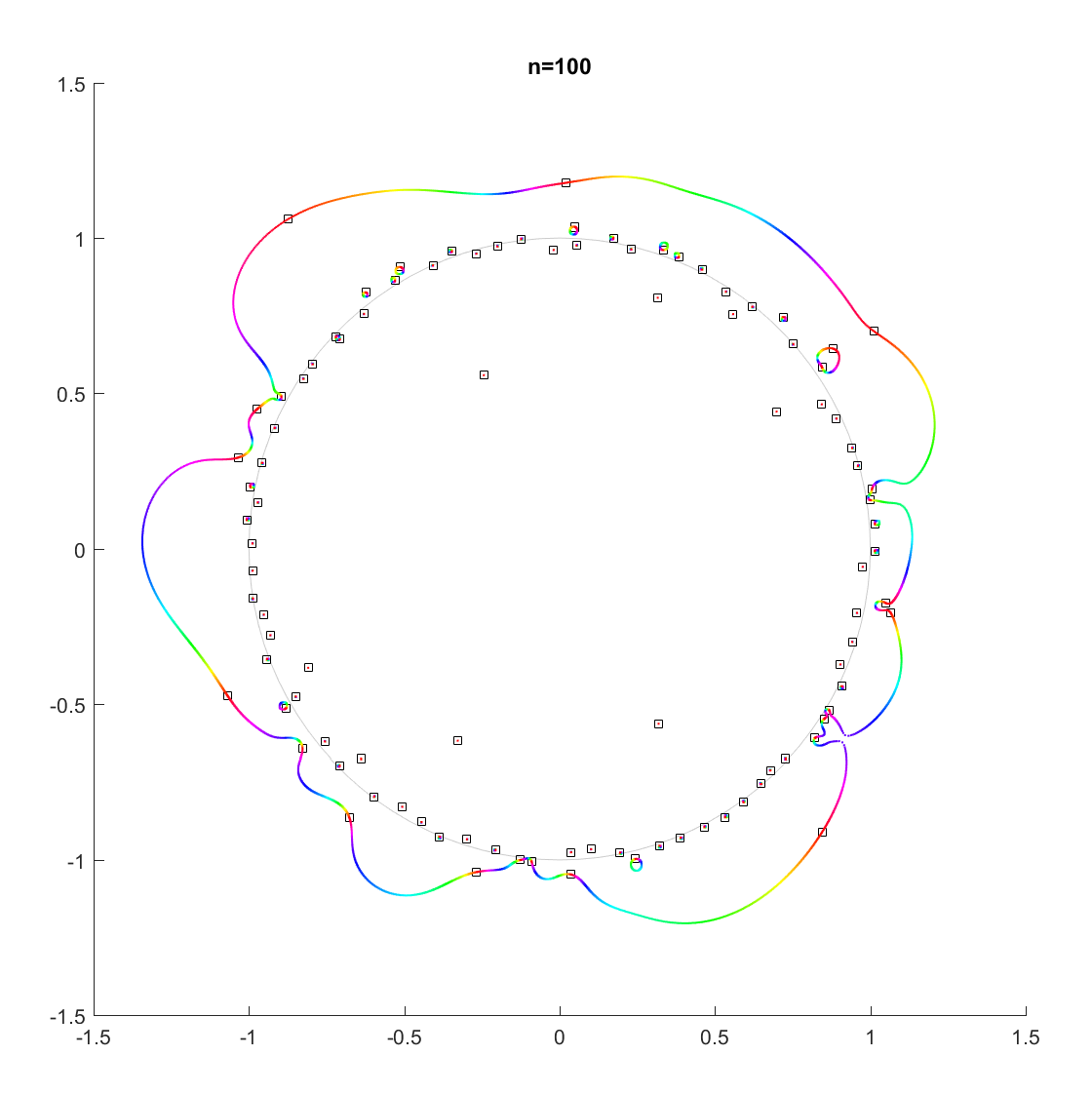
 .
.
 for a r that increases from zero? It turns out that a new zero of the function zooms in from infinity towards the unit circle. A way of seeing this is to look at the polynomial as
for a r that increases from zero? It turns out that a new zero of the function zooms in from infinity towards the unit circle. A way of seeing this is to look at the polynomial as  = c_n z^n + P_{n-1}(z)") : the second term is nonzero and large in most places, so if
: the second term is nonzero and large in most places, so if  factor must be large (and opposite) to outweigh it and cause a zero. The exception is of course close to the zeros of
factor must be large (and opposite) to outweigh it and cause a zero. The exception is of course close to the zeros of ") , where the perturbation just moves them a tiny bit: there is a counterpart for each of the
, where the perturbation just moves them a tiny bit: there is a counterpart for each of the  zeros of
zeros of ") . While the new root is approaching from outside, if we play with
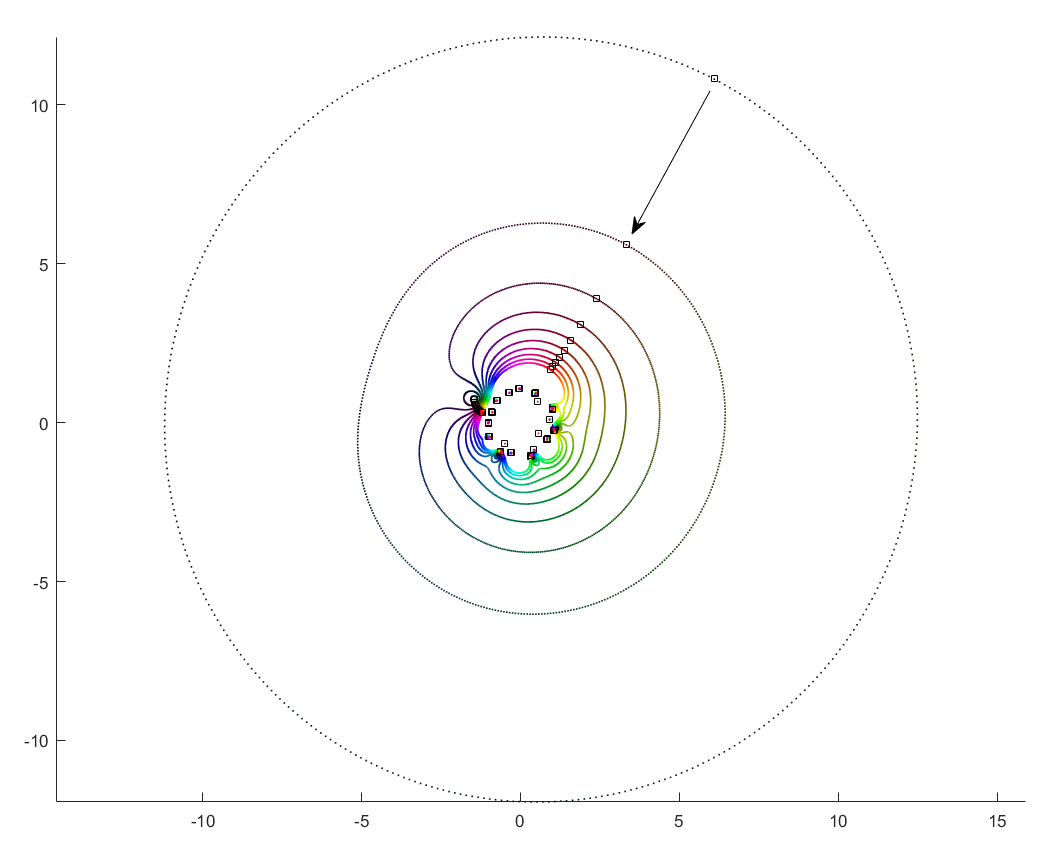
. While the new root is approaching from outside, if we play with 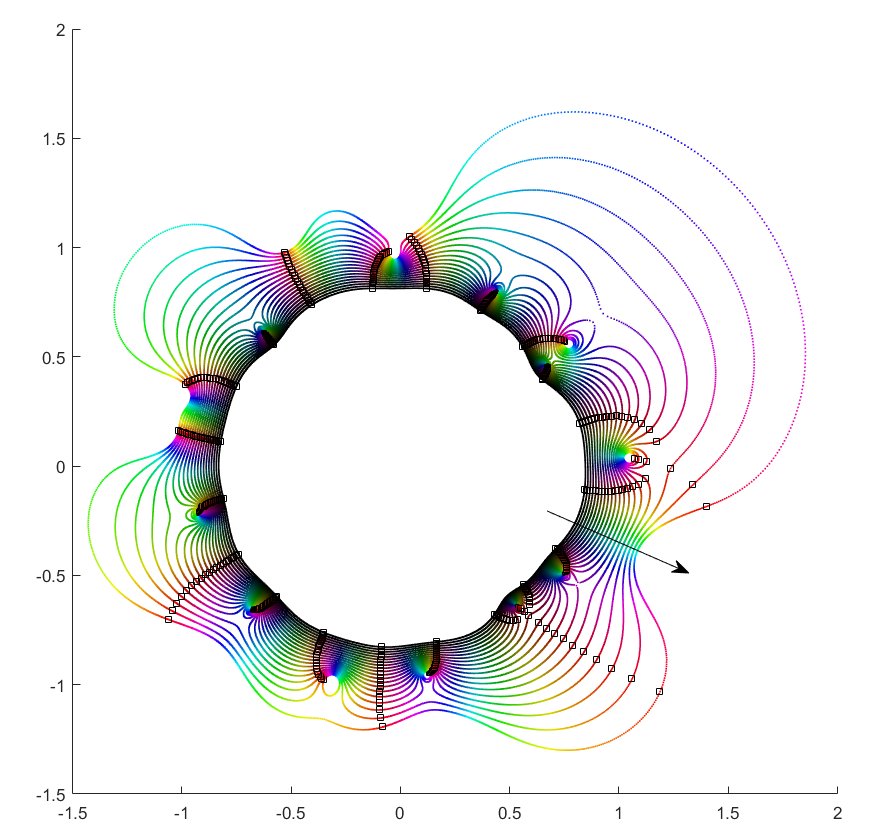
 , then the polynomial is essentially
, then the polynomial is essentially ![P_n(z)=c_nz^n+[\mathrm{small stuff}]](http://s0.wp.com/latex.php?latex=P_n%28z%29%3Dc_nz%5En%2B%5B%5Cmathrm%7Bsmall+stuff%7D%5D&bg=ffffff&fg=000000&s=0 "P_n(z)=c_nz^n+[\mathrm{small stuff}]") and the zeros the n-th roots of
and the zeros the n-th roots of ![-[\mathrm{small stuff}]/c_n](http://s0.wp.com/latex.php?latex=-%5B%5Cmathrm%7Bsmall+stuff%7D%5D%2Fc_n&bg=ffffff&fg=000000&s=0 "-[\mathrm{small stuff}]/c_n") . All zeros belong to the same roughly circular orbit, moving together as
. All zeros belong to the same roughly circular orbit, moving together as  decreases the shared orbit develops bulges and dents, and some zeros pinch off from it into their own small circles. When does the pinching off happen? That corresponds to when two zeros coincide during the orbit: one continues on the big orbit, the other one settles down to be local. This is the one case where the analyticity of how they move depending on
decreases the shared orbit develops bulges and dents, and some zeros pinch off from it into their own small circles. When does the pinching off happen? That corresponds to when two zeros coincide during the orbit: one continues on the big orbit, the other one settles down to be local. This is the one case where the analyticity of how they move depending on  .
. , with
, with  to
to  separate). That requires a large pinch in the orbit, but since it is overall pretty convex and circle-like this is unlikely.
separate). That requires a large pinch in the orbit, but since it is overall pretty convex and circle-like this is unlikely. to 0 and
to 0 and  . This is fairly obviously
. This is fairly obviously  = -P_{n-1}(z)/z^n") . This function has a central pole, surrounded by zeros corresponding to the zeros of
. This function has a central pole, surrounded by zeros corresponding to the zeros of |=\mathrm{const}") , and the pinching off to saddle points of this surface. To get a multi-zero orbit several zeros need to be close together enough to cause a broad valley.
, and the pinching off to saddle points of this surface. To get a multi-zero orbit several zeros need to be close together enough to cause a broad valley.

 key ideas needed to produce some important goal (like AI), there is a constant probability per researcher-year to come up with an idea, and the researcher works for
key ideas needed to produce some important goal (like AI), there is a constant probability per researcher-year to come up with an idea, and the researcher works for  years, what is the the probability of success? And how does it change if we add more researchers to the team?
years, what is the the probability of success? And how does it change if we add more researchers to the team?=\binom{y}{n}p^n(1-p)^{y-n}") . Unfortunately, then the actual answer to the question will be
. Unfortunately, then the actual answer to the question will be  = \sum_{n=k}^y \binom{y}{n}p^n(1-p)^{y-n}") which is a real mess…
which is a real mess… until a researcher has
until a researcher has =\lambda^k t^{k-1} e^{-\lambda t} / (k-1)!") .
. (or
(or  ) we will have a good chance of reaching the goal. Unfortunately the variance scales as
) we will have a good chance of reaching the goal. Unfortunately the variance scales as  – if the problems are hard, there is a significant risk of being unlucky for a long time. We have to consider the entire distribution.
– if the problems are hard, there is a significant risk of being unlucky for a long time. We have to consider the entire distribution.=1-\sum_{n=0}^{k-1} e^{-\lambda y} (\lambda y)^n / n!") which is again not very nice for algebraic manipulation. Still, we can plot it easily.
which is again not very nice for algebraic manipulation. Still, we can plot it easily. everywhere and get the desired answer.
everywhere and get the desired answer.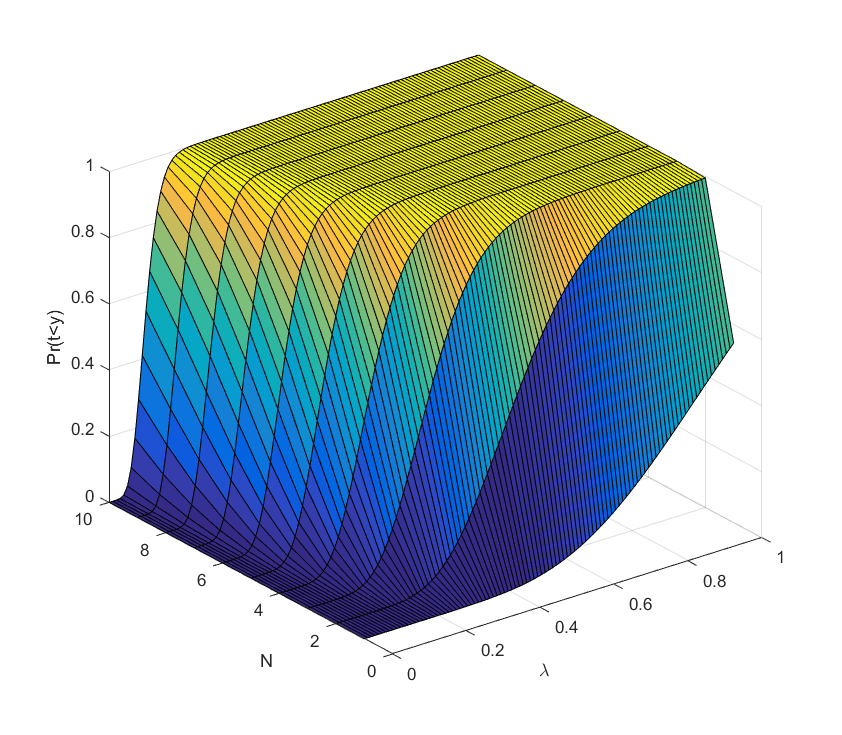
 .
. it rises, and sufficiently above we can be almost certain the project will succeed (the yellow plateau). Conversely, adding extra researchers has decreasing marginal returns when approaching the plateau: they make an already almost certain project even more certain. But they do have increasing marginal returns close to the dark blue “floor”: here the chances of success are small, but extra minds increase them a lot.
it rises, and sufficiently above we can be almost certain the project will succeed (the yellow plateau). Conversely, adding extra researchers has decreasing marginal returns when approaching the plateau: they make an already almost certain project even more certain. But they do have increasing marginal returns close to the dark blue “floor”: here the chances of success are small, but extra minds increase them a lot. to the one researcher case as we add researchers:
to the one researcher case as we add researchers: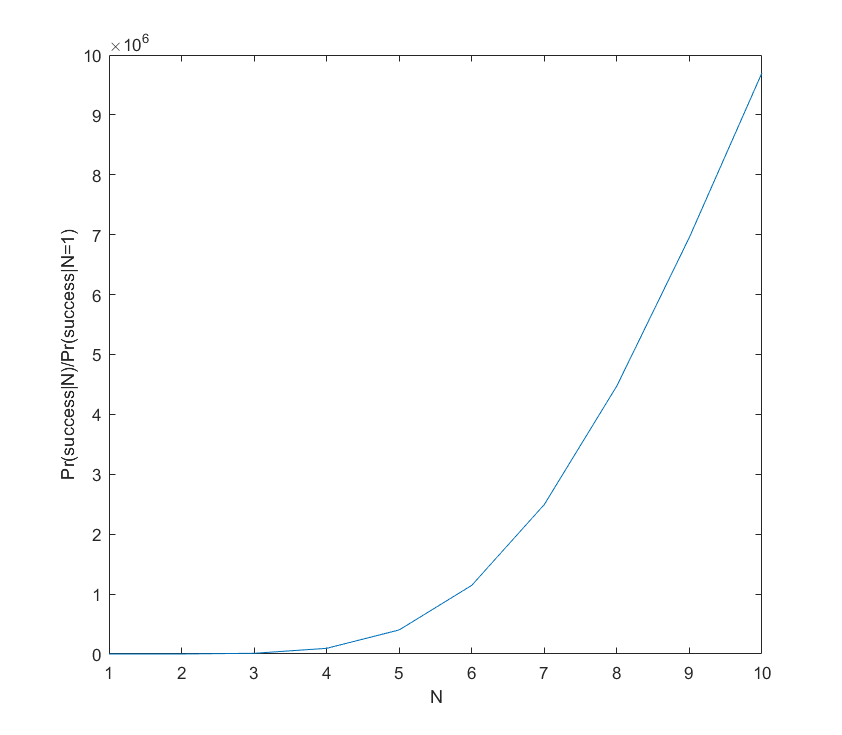
 and how it compares to
and how it compares to  of that idea distributed as an exponential plus the distribution of
of that idea distributed as an exponential plus the distribution of ") . If the first two ideas are independent and exponential with rates
. If the first two ideas are independent and exponential with rates  , then the minimum is distributed as an exponential with rate
, then the minimum is distributed as an exponential with rate  . If they instead require each other, we get a non-exponential distribution (the pdf is
. If they instead require each other, we get a non-exponential distribution (the pdf is e^{-(\lambda+\mu)t}") ). Some discoveries or bureaucratic scalings may change the rates. One can construct complex trees of intellectual pathways, unfortunately quickly making the distributions impossible to write out (but still easy to run Monte Carlo on). However, as long as the probabilities and the induced correlations small, I think we can linearise and keep the overall guess that extra minds are exponentially better.
). Some discoveries or bureaucratic scalings may change the rates. One can construct complex trees of intellectual pathways, unfortunately quickly making the distributions impossible to write out (but still easy to run Monte Carlo on). However, as long as the probabilities and the induced correlations small, I think we can linearise and keep the overall guess that extra minds are exponentially better.