(Based on this Twitter thread. Epistemic status: fairly plausible, I would teach this to kids)

A simple, and hardly unique economic observation: when you are poor, money is additive. As you get more, it becomes multiplicative. And eventually exponential.
To a kid or a very poor person every coin is a treasure, worth something just by being itself.
When you get a few coins they instead sum into fungible numbers. These are additive – you add or subtract to your wallet or account, and if the inflow is larger than the outflow your number will get bigger. You dream of finding the big pile of gold. Saving makes sense.
Then loans, investment, and interest show up. You can buy something and sell it for more, and the more you can buy and resell it the more profit. You can use existing money as security to borrow more. Good quality things you can now afford save money. It is multiplicative.
Eventually you get into the exponential domain where the money keeps on growing since it is being invested and the time horizon is long. A short horizon means that compound interest or reinvestment has little effect, a long one leads to a fairly predictable growth.
Obvious complications from things like risk and uncertainty. Many people move between these thoughts depending on context, saving cents on coffee filters while losing time and money driving across town to get them on a sale… while having massive invested savings.
There can also be “boots theory” that being poor increases your expenses and this acts as a trap. As you get richer you get easier or free access to a lot of things (airport lounges, better service), not necessarily making up for the higher price goods you buy but reducing some forms of friction. The nature of difficulties shift from finding money to maintaining an income stream to managing a system of growth.
I think this division maps roughly to mindset and social class. Additive thinking is about getting more input or paying less, mercantilism, and avoiding going to zero. Everything is a zero-sum game. Very much a precariat situation.
Multiplicative thinking is about finding big multipliers – the realm of the smart business idea, the good investment, removing bottlenecks and improving efficiency. This is where win-win trades begin to make sense. Classical rising middle class.
Exponential thinking is all about maximizing growth rates (or their growth), long time horizons, boosting GDP growth. Modern upper class. (Premodern feudal upper classes were far closer to multiplicative or even additive modes – they were poor by our standards!)
Could there be a realm beyond this, an economic world of tetration? It might be about creating entirely new opportunities. This is the from zero to one VC/entrepreneur world, although in practice it often descends into the previous ones most of the time. The cryptocurrency people think they are here, of course.
Note that in fiction and games the creators often want to keep things simple and understandable. Many (board and computer) games start out in the clear additive world and you are gathering coins and optimizing what to buy. The treasure is added to your wealth, not increasing it by a percentage. Often they eventually move into the multiplicative world (better equipped RPG characters can buy +1 longsword of monster killing, giving higher revenues; in Saint Petersburg your workers leverage into buildings leveraging into nobles), where computer games typically lose interest (unless they are trading games) and it acts as an endgame in the boardgame since the exponential state usually doesn’t make for an interesting competitive dynamics. Still, MMoRPGs often show heavyish tails of wealthy player characters.
What kind of “rich get richer” phenomena do the different domains produce? Obviously, exponential growth amplifies differences enormously: the growth rate of the wealthiest will be highest. But even in the additive domain wealth tends to accumulate. If people randomly meet and exchange random amounts, wealth tends to accumulate into an exponential distribution. It seems that the power-law tails one gets in real economies are due to non-conservation of money: there is new wealth flowing in.
Are there limiting factors to economic growth in general, or individually? In the additive world it is all set by the amount of resources – and your ability to grab them and hold on to them. Typically diminishing returns emerge soon. In the multiplicative world you want to boost productivity, and this goes even further in the exponential world. Considering an endogenous growth model, you start out by using more labour to get higher yields, then use capital, and eventually might boost the knowledge/tech… and typically this last step makes the model blow up to infinity if you can reinvest the yield. What actually happens is that there is a limited absorptive capacity of the economy and diminishing returns or delays set in. Whether this always holds is an important question, but for practical everyday economics it is worth keeping in mind.
Plus the very important issue of what you want the money for. Money is instrumentally useful, but not a final value. When you start treating it as the goal, Goodhart bites you.
 key ideas needed to produce some important goal (like AI), there is a constant probability per researcher-year to come up with an idea, and the researcher works for
key ideas needed to produce some important goal (like AI), there is a constant probability per researcher-year to come up with an idea, and the researcher works for  years, what is the the probability of success? And how does it change if we add more researchers to the team?
years, what is the the probability of success? And how does it change if we add more researchers to the team?=\binom{y}{n}p^n(1-p)^{y-n}") . Unfortunately, then the actual answer to the question will be
. Unfortunately, then the actual answer to the question will be  = \sum_{n=k}^y \binom{y}{n}p^n(1-p)^{y-n}") which is a real mess…
which is a real mess… of good ideas arriving to a researcher, but they can happen at any time. The time between two ideas will be exponentially distributed with parameter
of good ideas arriving to a researcher, but they can happen at any time. The time between two ideas will be exponentially distributed with parameter  until a researcher has
until a researcher has =\lambda^k t^{k-1} e^{-\lambda t} / (k-1)!") .
. (or
(or  ) we will have a good chance of reaching the goal. Unfortunately the variance scales as
) we will have a good chance of reaching the goal. Unfortunately the variance scales as  – if the problems are hard, there is a significant risk of being unlucky for a long time. We have to consider the entire distribution.
– if the problems are hard, there is a significant risk of being unlucky for a long time. We have to consider the entire distribution.=1-\sum_{n=0}^{k-1} e^{-\lambda y} (\lambda y)^n / n!") which is again not very nice for algebraic manipulation. Still, we can plot it easily.
which is again not very nice for algebraic manipulation. Still, we can plot it easily. researchers, equally good, contributing to the idea generation, what is the new rate of ideas per year? Since we have assumed independence and a Poisson process, it just multiplies the rate by a factor of
researchers, equally good, contributing to the idea generation, what is the new rate of ideas per year? Since we have assumed independence and a Poisson process, it just multiplies the rate by a factor of  everywhere and get the desired answer.
everywhere and get the desired answer.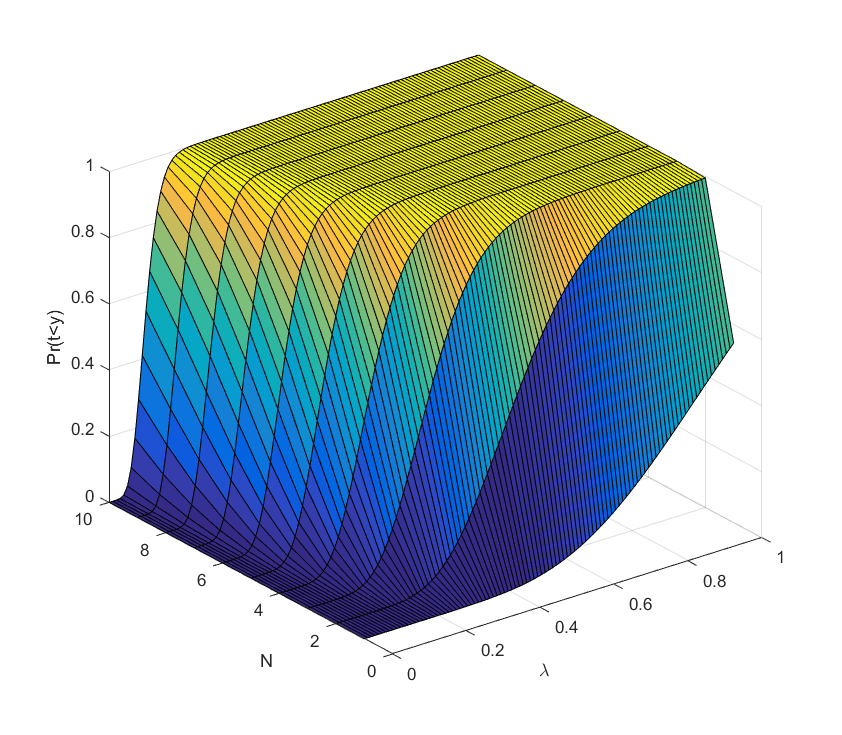
 .
. it rises, and sufficiently above we can be almost certain the project will succeed (the yellow plateau). Conversely, adding extra researchers has decreasing marginal returns when approaching the plateau: they make an already almost certain project even more certain. But they do have increasing marginal returns close to the dark blue “floor”: here the chances of success are small, but extra minds increase them a lot.
it rises, and sufficiently above we can be almost certain the project will succeed (the yellow plateau). Conversely, adding extra researchers has decreasing marginal returns when approaching the plateau: they make an already almost certain project even more certain. But they do have increasing marginal returns close to the dark blue “floor”: here the chances of success are small, but extra minds increase them a lot. to the one researcher case as we add researchers:
to the one researcher case as we add researchers: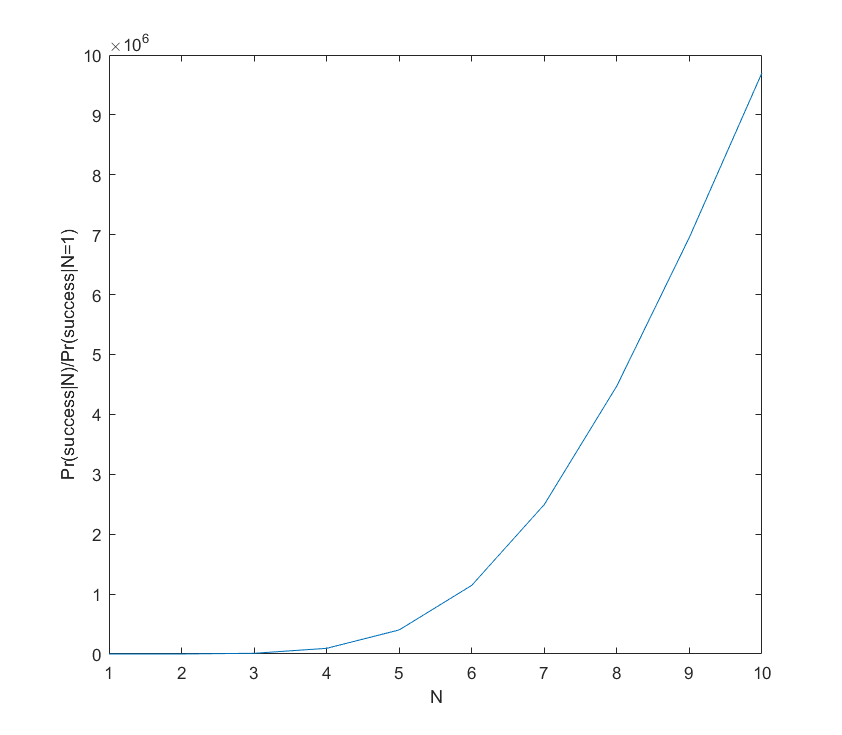
 and how it compares to
and how it compares to  of that idea distributed as an exponential plus the distribution of
of that idea distributed as an exponential plus the distribution of ") . If the first two ideas are independent and exponential with rates
. If the first two ideas are independent and exponential with rates  , then the minimum is distributed as an exponential with rate
, then the minimum is distributed as an exponential with rate  . If they instead require each other, we get a non-exponential distribution (the pdf is
. If they instead require each other, we get a non-exponential distribution (the pdf is e^{-(\lambda+\mu)t}") ). Some discoveries or bureaucratic scalings may change the rates. One can construct complex trees of intellectual pathways, unfortunately quickly making the distributions impossible to write out (but still easy to run Monte Carlo on). However, as long as the probabilities and the induced correlations small, I think we can linearise and keep the overall guess that extra minds are exponentially better.
). Some discoveries or bureaucratic scalings may change the rates. One can construct complex trees of intellectual pathways, unfortunately quickly making the distributions impossible to write out (but still easy to run Monte Carlo on). However, as long as the probabilities and the induced correlations small, I think we can linearise and keep the overall guess that extra minds are exponentially better.