In 1983 Swedish Television began an all-evening entertainment program named Razzel. It was centred around the state lottery draw, with music, sketch comedy, and television series interspersed between the blocks. Yes, this was back in the day when there was two TV channels to choose from and more or less everybody watched. The ice age had just about ended.
In 1983 Swedish Television began an all-evening entertainment program named Razzel. It was centred around the state lottery draw, with music, sketch comedy, and television series interspersed between the blocks. Yes, this was back in the day when there was two TV channels to choose from and more or less everybody watched. The ice age had just about ended.
One returning feature consisted of camera footage of a pedestrian crossing in Stockholm. A sports commenter well-known for his coverage of horse-racing narrated the performance of the unknowing pedestrians as if they were competing in a race. In some cases I even think he even showed up to deliver flowers to the “winner”. But you would get disqualified if you had a false start or went outside the stripes!
I suspect this feature noticeably improved traffic safety for a generation.
I was reminded of this childhood memory earlier today when discussing the use of face recognition in China to detect jaywalkers and display them on a billboard to shame them. The typical response in a western audience is fear of what looks like a totalitarian social engineering program. The glee with which many responded to the news that the system had been confused by a bus ad, putting a celebrity on the board of shame, is telling.
Is there a difference?
But compare the Chinese system to the TV program. In the China case the jaywalker may be publicly shamed from the billboard… but in the cheerful 80s TV program they were shamed in front of much of the nation.
There is a degree of increased personalness in the Chinese case since it also displays their name, but no doubt friends and neighbours would recognize you if they saw you on TV (remember, this was back when we only had two television channels and a fair fraction of people watched TV on Friday evening). There may also be SMS messages involved in some versions of the system. This acts differently: now it is you who gets told off when you misbehave.
A fundamental difference may be the valence of the framing. The TV show did this as happy entertainment, more of a parody of sport television than an attempt at influencing people. The Chinese system explicitly aims at discouraging misbehaviour. The TV show encouraged positive behaviour (if only accidentally).
So the dimensions here may be the extent of the social effect (locally, or nationwide), the degree the feedback is directly personal or public, and whether it is a positive or negative feedback. There is also a dimension of enforcement: is this something that happens every time you transgress the rules, or just randomly?
In terms of actually changing behaviour making the social effect broad rather than close and personal might not have much effect: we mostly care about our standing relative to our peers, so having the entire nation laugh at you is certainly worse than your friends laughing, but still not orders of magnitude more mortifying. The personal message on the other hand sends a signal that you were observed; together with an expectation of effective enforcement this likely has a fairly clear deterrence effect (it is often not the size of the punishment that deters people from crime, but their expectation of getting caught). The negative stick of acting wrong and being punished is likely stronger than the positive carrot of a hypothetical bouquet of flowers.
Where is the rub?
From an ethical standpoint, is there a problem here? We are subject to norm enforcement from friends and strangers all the time. What is new is the application of media and automation. They scale up the stakes and add the possibility of automated enforcement. Shaming people for jaywalking is fairly minor, but some people have lost jobs, friends or been physically assaulted when their social transgressions have become viral social media. Automated enforcement makes the panopticon effect far stronger: instead of suspecting a possibility of being observed it is a near certainty. So the net effect is stronger, more pervasive norm enforcement…
…of norms that can be observed and accurately assessed. Jaywalking is transparent in a way being rude or selfish often isn’t. We may end up in a situation where we carefully obey some norms, not because they are the most important but because they can be monitored. I do not think there is anything in principle impossible about a rudeness detection neural network, but I suspect the error rates and lack of context sensitivity would make it worse than useless in preventing actual rudeness. Goodhart’s law may even make it backfire.
So, in the end, the problem is that automated systems encode a formalization of a social norm rather than the actual fluid social norm. Having a TV commenter narrate your actions is filtered through the actual norms of how to behave, while the face recognition algorithm looks for a pattern associated with transgression rather than actual transgression. The problem is that strong feedback may then lock in obedience to the hard to change formalization rather than actual good behaviour.

 distributed as
distributed as ") . The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value
. The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value ![V=E[x]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x]-1") . Suppose a cursory investigation costing much less gives some indication about
. Suppose a cursory investigation costing much less gives some indication about  . One approach is to select all items above a threshold
. One approach is to select all items above a threshold  , making
, making ![V=E[x_i|y_i<\theta]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx_i%7Cy_i%3C%5Ctheta%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x_i|y_i<\theta]-1") .
., \epsilon \sim N(0,\sigma_\epsilon^2)") , then
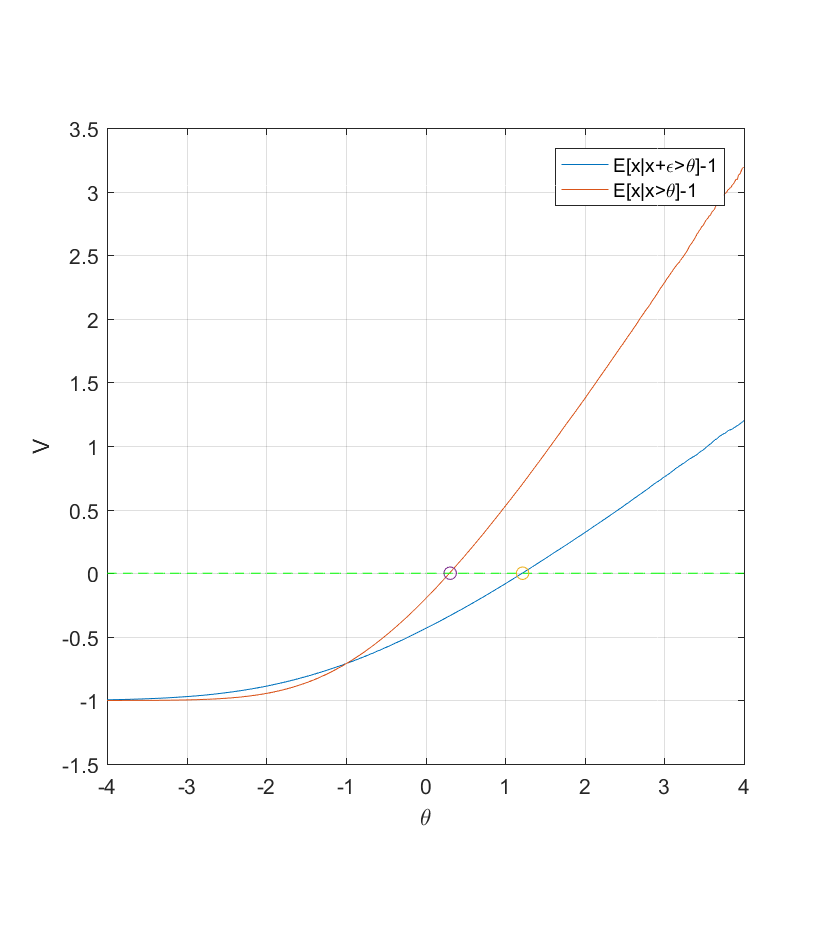
, then  \Phi\left(\frac{t-\mu_x}{\sqrt{\sigma_x^2+\sigma_\epsilon^2}}\right)dt") . While one can ram through this using
. While one can ram through this using  (the correlation between x and y is 0.707, so this is not too much noise):
(the correlation between x and y is 0.707, so this is not too much noise):