 Stefan Heck managed to troll a lot of people into googling “how to join ISIS”. Very amusing, and now a lot of people think they are on a NSA watchlist.
Stefan Heck managed to troll a lot of people into googling “how to join ISIS”. Very amusing, and now a lot of people think they are on a NSA watchlist.
This kind of prank is of course by why naive keyword-based watch lists are total failures. One prank and it gets overloaded. I would be shocked if any serious intelligence agency actually used them for real. Given that people’s Facebook likes give pretty good predictions of who they are (indeed, better than many friends know them) there are better methods if you happen to be a big intelligence agency.
Still, while text and other online behavior signal a lot about a person, it might not be a great tool for making proper watchlists since there is a lot of noise. For example, this paper extracts personality dimensions from online texts and looks at civilian mass murderers. They state:
Using this ranking procedure, it was found that all of the murderers’ texts were located within the highest ranked 33 places. It means that using only two simple measures for screening these texts, we can reduce the size of the population under inquiry to 0.013% of its original size, in order to manually identify all of the murderers’ texts.
At first, this sounds great. But for the US, that means the watchlist for being a mass murderer would currently have 41,000 entries. Given that over the past 150 years there has been about 150 mass murders in the US, this suggests that the precision is not going to be that great – most of those people are just normal people. The base rate problem crops up again and again when trying to find rare, scary people.
The deep problem is that there is not enough positive data points (the above paper used seven people) to make a reliable algorithm. The same issue cropped up with NSA’s SKYNET program – they also had seven positive examples and hundreds of thousands of negatives, and hence had massive overfitting (suggesting the Islamabad Al Jazeera bureau chief was a prime Al Qaeda suspect).
Rational watchlists
The rare positive data point problem strikes any method, no matter what it is based on. Yes, looking at the social network around people might give useful information, but if you only have a few examples of bad people the system will now pick up on networks like the ones they had. This is also true for human learning: if you look too much for people like the ones that in the past committed attacks, you will focus too much on people like them and not enemies that look different. I was told by an anti-terrorism expert about a particular sign for veterans of Afghan guerrilla warfare: great if and only if such veterans are the enemy, but rather useless if the enemy can recruit others. Even if such veterans are a sizable fraction of the enemy the base rate problem may make you spend your resources on innocent “noise” veterans if the enemy is a small group. Add confirmation bias, and trouble will follow.
Note that actually looking for a small set of people on the watchlist gets around the positive data point problem: the system can look for them and just them, and this can be made precise. The problem is not watching, but predicting who else should be watched.
The point of a watchlist is that it represents a subset of something (whether people or stocks) that merits closer scrutiny. It should essentially be an allocation of attention towards items that need higher level analysis or decision-making. The U.S. Government’s Consolidated Terrorist Watch List requires nomination from various agencies, who presumably decide based on reasonable criteria (modulo confirmation bias and mistakes). The key problem is that attention is a limited resource, so adding extra items has a cost: less attention can be spent on the rest.
This is why automatic watchlist generation is likely to be a bad idea, despite much research. Mining intelligence to help an analyst figure out if somebody might fit a profile or merit further scrutiny is likely more doable. As long as analyst time is expensive it can easily be overwhelmed if something fills the input folder: HUMINT is less likely to do it than SIGINT, even if the analyst is just doing the preliminary nomination for a watchlist.
The optimal Bayesian watchlist
One can analyse this in a Bayesian framework: assume each item has a value 
")
![V=E[x]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x]-1")


![V=E[x_i|y_i<\theta]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx_i%7Cy_i%3C%5Ctheta%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x_i|y_i<\theta]-1")
If we imagine that everything is Gaussian , \epsilon \sim N(0,\sigma_\epsilon^2)")
 \Phi\left(\frac{t-\mu_x}{\sqrt{\sigma_x^2+\sigma_\epsilon^2}}\right)dt")

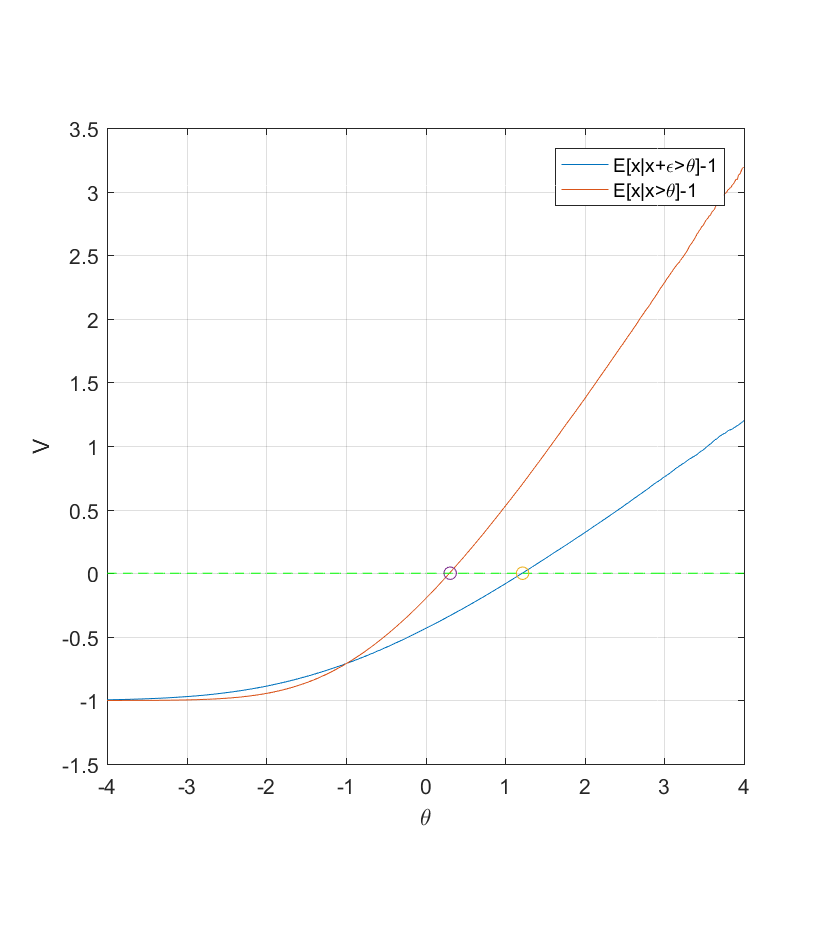
Note that in this case the addition of noise forces a far higher threshold than without noise (1.22 instead of 0.31). This is just 19% of all items, while in the noise-less case 37% of items would be worth investigating. As noise becomes worse the selection for a watchlist should become stricter: a really cursory inspection should not lead to insertion unless it looks really relevant.
Here we used a mild Gaussian distribution. In term of danger, I think people or things are more likely to be lognormal distributed since it is a product of many relatively independent factors. Using lognormal x and y leads to a situation where there is a maximum utility for some threshold. This is likely a problematic model, but clearly the shape of the distributions matter a lot for where the threshold should be.
Note that having huge resources can be a bane: if you build your watchlist from the top priority down as long as you have budget or manpower, the lower priority (but still above threshold!) entries will be more likely to be a waste of time and effort. The average utility will decline.
Predictive validity matters more?
In any case, a cursory and cheap decision process is going to give so many so-so evaluations that one shouldn’t build the watchlist on it. Instead one should aim for a series of filters of increasing sophistication (and cost) to wash out the relevant items from the dross.
But even there there are pitfalls, as this paper looking at the pharma R&D industry shows:
We find that when searching for rare positives (e.g., candidates that will successfully complete clinical development), changes in the predictive validity of screening and disease models that many people working in drug discovery would regard as small and/or unknowable (i.e., an 0.1 absolute change in correlation coefficient between model output and clinical outcomes in man) can offset large (e.g., 10 fold, even 100 fold) changes in models’ brute-force efficiency.
Just like for drugs (an example where the watchlist is a set of candidate compounds), it might be more important for terrorist watchlists to aim for signs with predictive power of being a bad guy, rather than being correlated with being a bad guy. Otherwise anti-terrorism will suffer the same problem of declining productivity, despite ever more sophisticated algorithms.