The gamma function has a long and interesting history (check out (Davis 1963) excellent review), but one application does not seem to have shown up: minimal surfaces.
A minimal surface is one where the average curvature is always zero; it bends equally in two opposite directions. This is equivalent to having the (locally) minimal area given its boundary: such surfaces are commonly seen as soap films stretched from frames. There exists a rich theory for them, linking them to complex analysis through the Enneper-Weierstrass representation: if you have a meromorphic function g and an analytic function f such that is holomorphic, then
produces a minimal surface .
When plugging in the hyperbolic tangent as g and using f=1 I got a new and rather nifty surface a few years back. What about plugging in the gamma function? Let .
We integrate from the regular point to different points in the complex plane. Let us start with the simple case of .
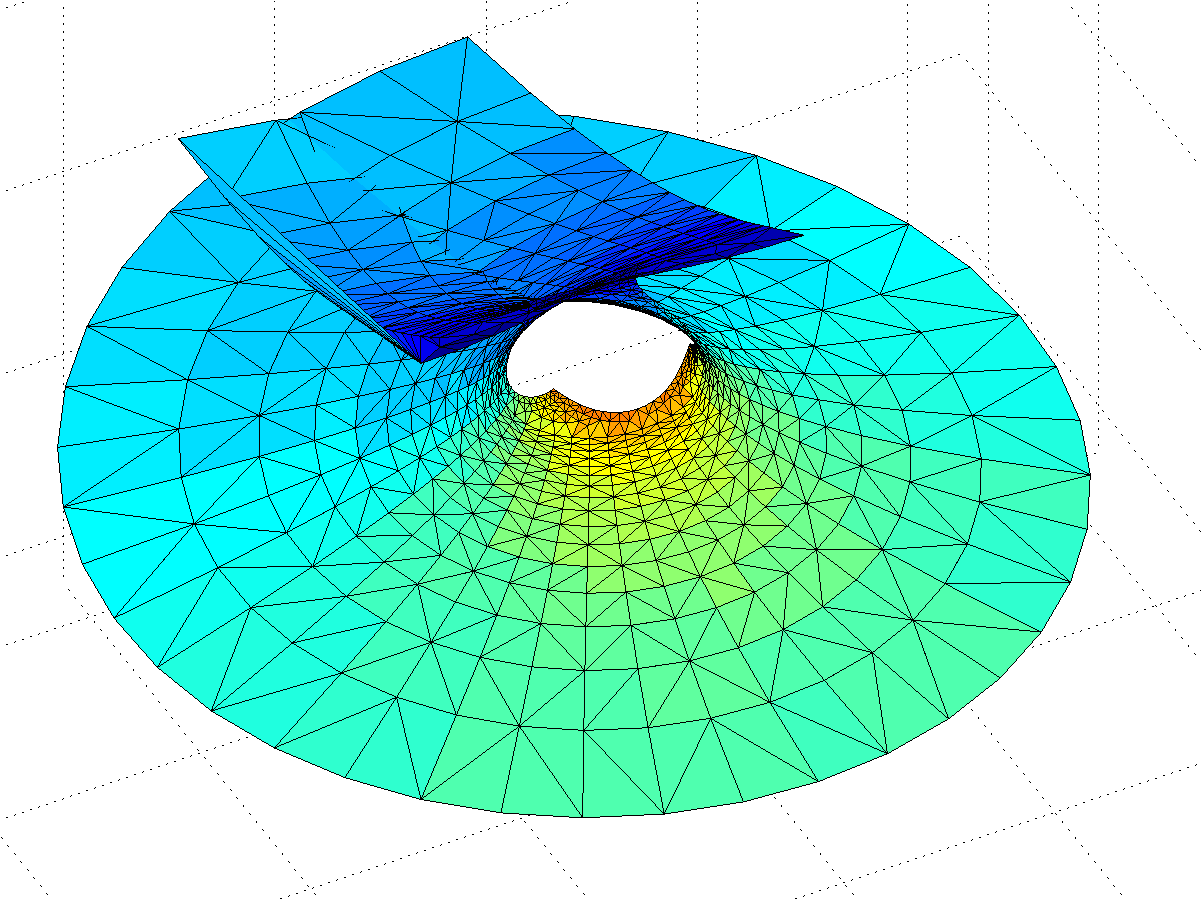
Gamma function minimal surface for z in 0.5<Re(z)<3.5, -8<Im(z)
The surface is a billowing strip, and as we include z with larger and larger real parts the amplitude of the oscillations grow rapidly, making it self-intersect. The behaviour is somewhat similar to the Catalan minimal surface, except that we only get one period. If we go to larger imaginary parts the surface approaches a horizontal plane. OK, the surface is a plane with some wild waves, right?
Not so fast, we have not looked at the mess for Re(z)<0. First, let’s examine the area around the z=0 singularity. Since the values of the integrand blows up close to it, they produce a surface expanding towards infinity – very similar to a catenoid. Indeed, catenoid ends tend to show up where there are poles. But this one doesn’t close exactly: for re(z)<0 there is some overshoot producing a self-intersecting plane-like strip.
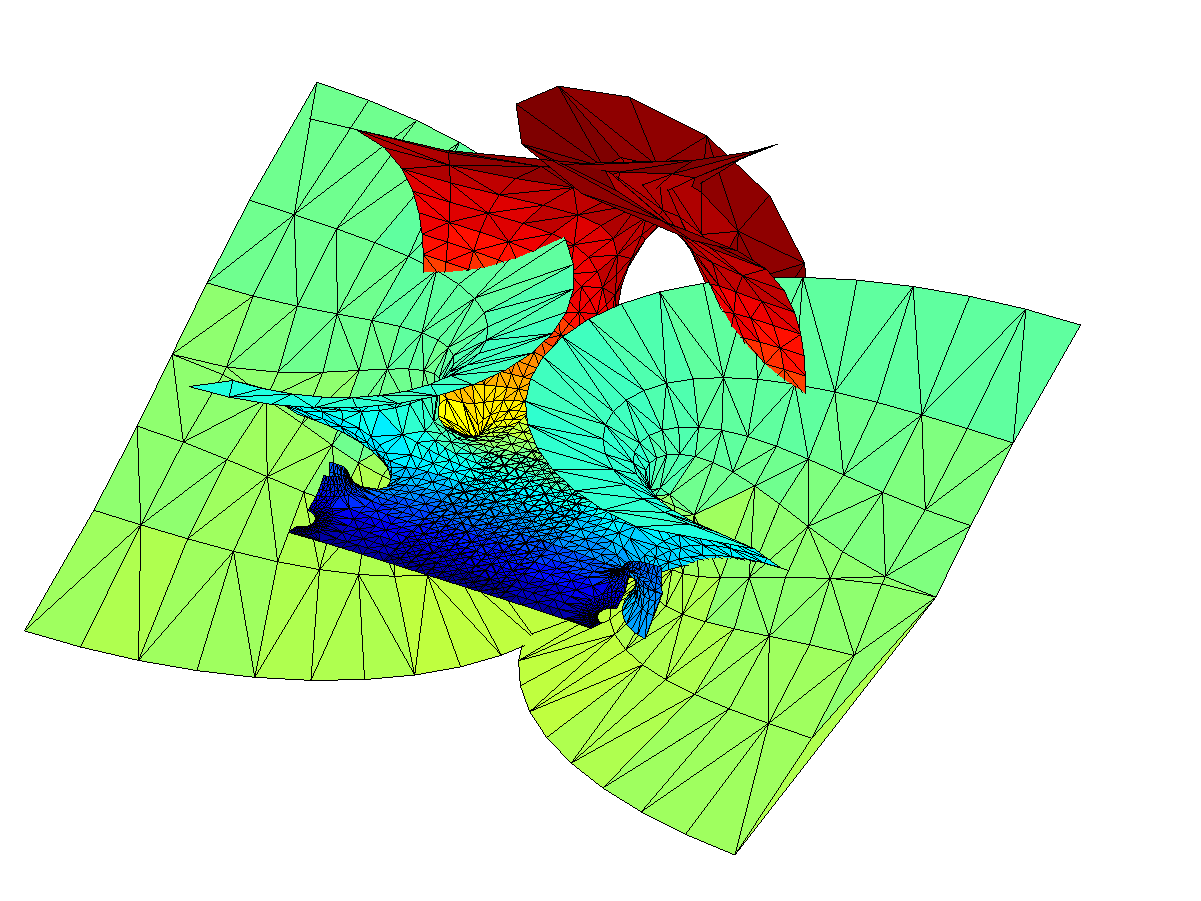
Gamma function minimal surface close to the z=0 singularity. Colour denotes Re(z). Integration contours from 1 to z run clockwise for Im(z)<0 and counterclockwise for Im(z)>0.
The problem is of course the singularity: when integrating in the complex plane we need to avoid them, and depending on the direction we go around them we can get a complex phase that gives us an entirely different value of the function. In this case the branch cut corresponds to the real line: integrating clockwise or counter-clockwise around z=0 to the same z gives different values. In fact, a clockwise turn adds [3.6268i, 3.6268, 6.2832i] (which looks like – a rather neat residue!) to the coordinates: a translation in the positive y-direction. If we extend the surface by going an extra turn clockwise or counterclockwise a number of times, we get copies that attach seamlessly.
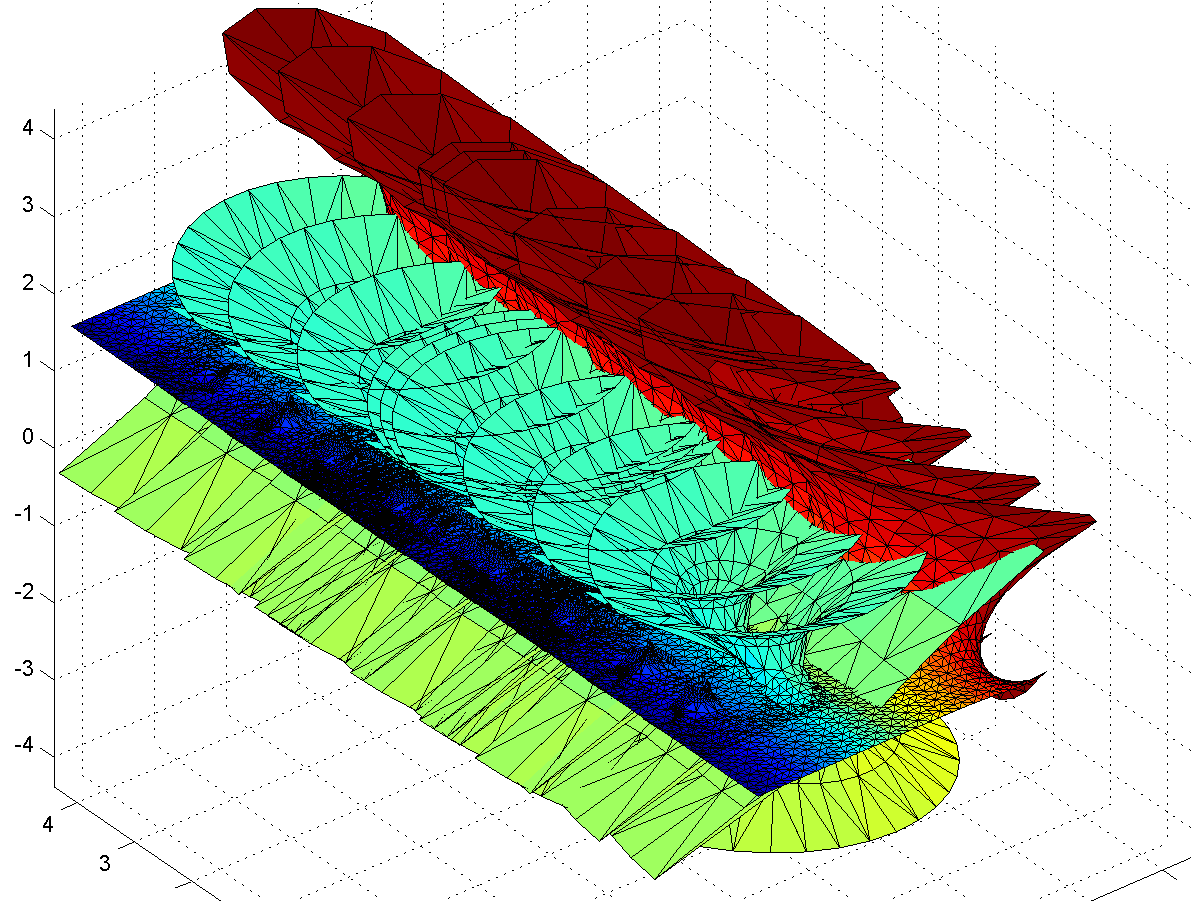
Gamma minimal surface extended by integration paths between the -1 and 0 singularities (blue patches).
Gamma minimal surface patch that can be repeated by translation along the y-axis. Colour denotes Re(z).
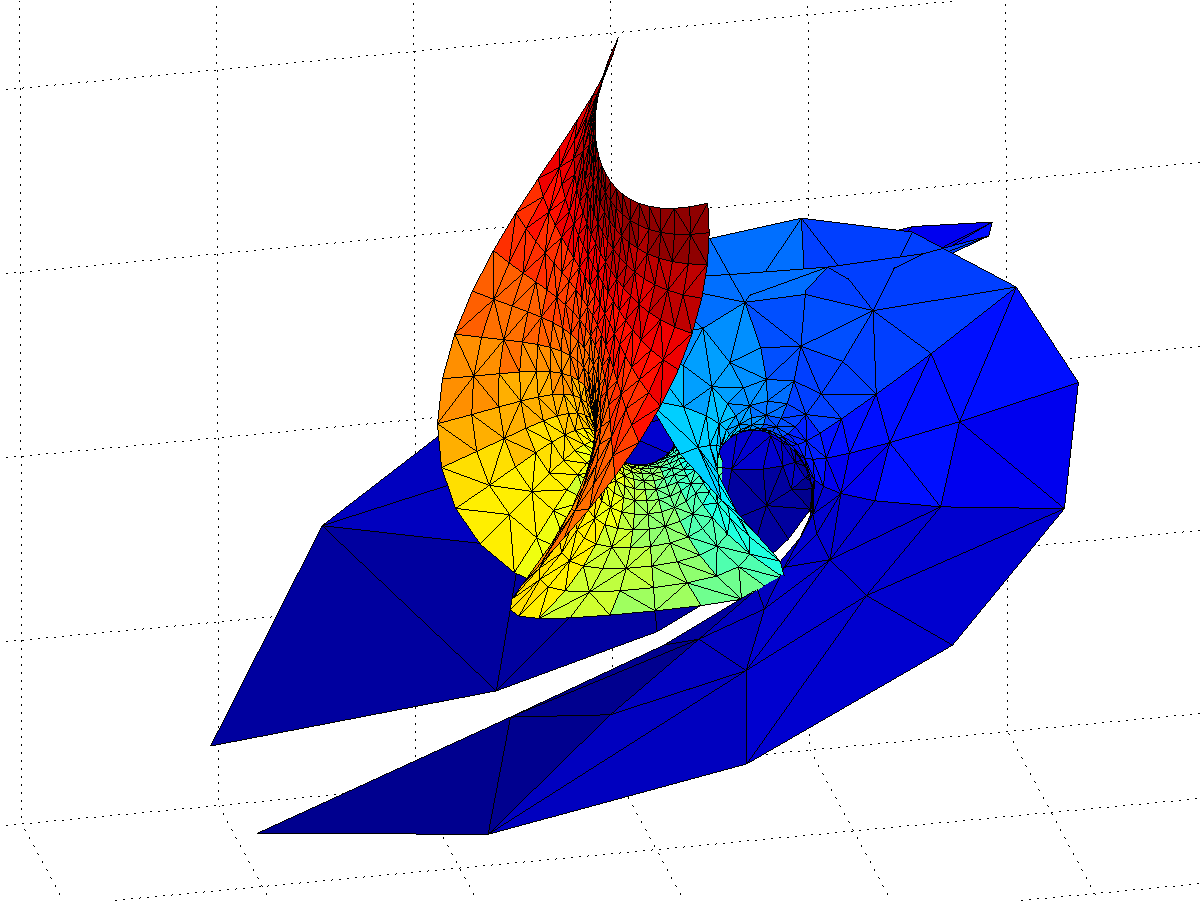
OK, we have a surface with some planar strips that turn wobbly and self-intersecting in the x-direction, with elliptic catenoid ends repeating along the y-direction due to the z=0 singularity. Going down the negative x-direction things look plane between the catenoids… except of course for the catenoids due to all the other singularities for . They also introduce residues along the y-direction, but different ones from the z=0 – their extensions of the surface will be out of phase with each other, making the fully extended surface fantastically self-intersecting and confusing.
Gamma function minimal surface extended by integrating around poles.
So, I think we have a simple answer to why the gamma function minimal surface is not well known: it is simply too messy and self-intersecting.
Of course, there may be related nifty surfaces. is nicely behaved and looks very much like the Enneper surface near zero, with “wings” that oscillate ever more wildly as we move towards the negative reals. No doubt there are other beautiful things to look for in the vicinity.
There are some texts that are worth reading, even if you are outside the group they are intended for. Here is one that I think everybody should read at least the first half of:
Haldane, the Executive Director for Financial Stability at Bank of England, brings up the topic is how to act in situations of uncertainty, and the role of our models of reality in making the right decision. How complex should they be in the face of a complex reality? The answer, based on the literature on heuristics, biases and modelling, and the practical world of financial disasters, is simple: they should be simple.
Using too complex models means that they tend to overfit scarce data, weight data randomly, require significant effort to set up – and tends to promote overconfidence. As Haldane then moves on to his own main topic, banking regulation. Complex regulations – which are in a sense models of how banks ought to act – have the same problem, and also act as incentives for playing the rules to gain advantage. The end result is an enormous waste of everybody’s time and effort that does not give the desired reduction of banking risk.
It is striking how many people have been seduced by the siren call of complex regulation or models, thinking their ability to include every conceivable special case is a sign of strength. Finance and finance regulation are full of smart people who make the same mistake, as is science. If there is one thing I learned in computational biology is that your model better produce more nontrivial results than the number of parameters it has.
But coming up with simple rules or models is not easy: knowing what to include and what not to include requires expertise and effort. In many ways this may be why people like complex models, since there are no tricky judgement calls.
Another of my favourite functions if the Gamma function, , the continuous generalization of the factorial. While it grows rapidly for positive reals, it has fun poles for the negative integers and is generally complex. What happens when you iterate it?
First I started by just applying it to different starting points, . The result is a nice fractal, with some domains approaching 1, and others running off to infinity.
Here I color points that go to infinity in green shades on the number of iterations before they become very large, and the points approaching 1 by . Zooming in a bit more reveals neat self-similar patterns with alternating “beans”:
In the outside regions we have thin tendrils stretching towards infinity. These are familiar to anybody who has been iterating exponentials or trigonometric functions: the combination of oscillation and (super)exponential growth leads to the pattern.
OK,that was a Julia set (different starting points, same formula). What about a counterpart to the Mandelbrot set? I looked at where c is the control parameter. I start with and iterate:
Zooming in shows the same kind of motif copies of Julia sets as we see in the quadratic Mandelbrot set:
In fact, zooming in as above in the counterpart to the “seahorse valley” shows a remarkable similarity.
After a recent lecture about the singularity I got asked about its energy requirements. It is a good question. As my inquirer pointed out, humanity uses more and more energy and it generally has an environmental cost. If it keeps on growing exponentially, something has to give. And if there is a real singularity, how do you handle infinite energy demands?
First I will look at current trends, then different models of the singularity.
I will not deal directly with environmental costs here. They are relative to some idea of a value of an environment, and there are many ways to approach that question.
Current trends
Current computers are energy hogs. Currently general purpose computing consumes about one Petawatt-hour per year, with the entire world production somewhere above 22 Pwh. While large data centres may be obvious, the vast number of low-power devices may be an even more significant factor; up to 10% of our electricity use may be due to ICT.
Koomey’s law states that the number of computations per joule of energy dissipated has been doubling approximately every 1.57 years. This might speed up as the pressure to make efficient computing for wearable devices and large data centres makes itself felt. Indeed, these days performance per watt is often more important than performance per dollar.
Semilog plot of global energy (all types) consumption over time.
Looking at overall energy use trends it looks like overall energy use increases exponentially (but has stayed at roughly the same per capita level since the 1970s). In fact, plotting it on a semilog graph suggests that it is increasing faster than exponential (otherwise it would be a straight line). This is presumably due to a combination of population increase and increased energy use. The best fit exponential has a doubling time of 44.8 years.
Electricity use is also roughly exponential, with a doubling time of 19.3 years. So we might be shifting more and more to electricity, and computing might be taking over more and more of that.
Extrapolating wildly, we would need the total solar input on Earth in about 300 years and the total solar luminosity in 911 years. In about 1,613 years we would have used up the solar system’s mass energy. So, clearly, long before then these trends will break one way or another.
Physics places a firm boundary due to the Landauer principle: in order to erase on bit of information joules of energy have to be dissipated. Given current efficiency trends we will reach this limit around 2048.
The principle can be circumvented using reversible computation, either classical or quantum. But as I often like to point out, it still bites in the form of the need for error correction (erasing accidentally flipped bits) and formatting new computational resources (besides the work in turning raw materials into bits). We should hence expect a radical change in computation within a few decades, even if the cost per computation and second continues to fall exponentially.
What kind of singularity?
But how many joules of energy does a technological singularity actually need? It depends on what kind of singularity. In my own list of singularity meanings we have the following kinds:
A. Accelerating change
B. Self improving technology
C. Intelligence explosion
D. Emergence of superintelligence
E. Prediction horizon
F. Phase transition
G. Complexity disaster
H. Inflexion point
I. Infinite progress
Case A, acceleration, at first seems to imply increasing energy demands, but if efficiency grows faster they could of course go down.
He suggests energy rate density may increase as Moore’s law, at least in our current technological setting. If we assume this to be true, then we would have , where is the power of the system and is the mass of the system at time t. One can maintain exponential growth by reducing the mass as well as increasing the power.
However, waste heat will need to be dissipated. If we use the simplest model where a radius R system with density radiates it away into space, then the temperature will be , or, if we have a maximal acceptable temperature, . So the system needs to become smaller as increases. If we use active heat transport instead (as outlined in my previous post), covering the surface with heat pipes that can remove X watts/square meter, then . Again, the radius will be inversely proportional to . This is similar to our current computers, where the CPU is a tiny part surrounded by cooling and energy supply.
If we assume the waste heat is just due to erasing bits, the rate of computation will be bits per second. Using the first cooling model gives us – a massive advantage for running extremely hot and dense computation. In the second cooling model : in both cases higher energy rate densities make it harder to compute when close to the thermodynamic limit. Hence there might be an upper limit to how much we may want to push .
Also, a system with mass M will use up its own mass-energy in time : the higher the rate, the faster it will run out (and it is independent of size!). If the system is expanding at speed v it will gain and use up mass at a rate ; if grows faster than quadratic with time it will eventually run out of mass to use. Hence the exponential growth must eventually reduce simply because of the finite lightspeed.
The Chaisson scenario does not suggest a “sustainable” singularity. Rather, it suggests a local intense transformation involving small, dense nuclei using up local resources. However, such local “detonations” may then spread, depending on the long-term goals of involved entities.
Cases B, C, D(intelligence explosions, superintelligence) have an unclear energy profile. We do not know how complex code would become or what kind of computational search is needed to get to superintelligence. It could be that it is more a matter of smart insights, in which case the needs are modest, or a huge deep learning-like project involving massive amounts of data sloshing around, requiring a lot of energy.
Case E, a prediction horizon, is separate from energy use. As this essay shows, there are some things we can say about superintelligent computational systems based on known physics that likely remains valid no matter what.
Case F, phase transition, involves a change in organisation rather than computation, for example the formation of a global brain out of previously uncoordinated people. However, this might very well have energy implications. Physical phase transitions involve discontinuities of the derivatives of the free energy. If the phases have different entropies (first order transitions) there has to be some addition or release of energy. So it might actually be possible that a societal phase transition requires a fixed (and possibly large) amount of energy to reorganize everything into the new order.
There are also second order transitions. These are continuous do not have a latent heat, but show divergent susceptibilities (how much the system responds to an external forcing). These might be more like how we normally imagine an ordering process, with local fluctuations near the critical point leading to large and eventually dominant changes in how things are ordered. It is not clear to me that this kind of singularity would have any particular energy requirement.
Case G, complexity disaster, is related to superexponential growth, such as the city growth model of Bettancourt, West et al. or the work on bubbles and finite time singularities by Didier Sornette. Here the rapid growth rate leads to a crisis, or more accurately a series of crises increasingly rapidly succeeding each other until a final singularity. Beyond that the system must behave in some different manner. These models typically predict rapidly increasing resource use (indeed, this is the cause of the crisis sequence as one kind of growth runs into resource scaling problems and is replaced with another one), although as Sornette points out the post-singularity state might well be a stable non-rivalrous knowledge economy.
Case H, an inflexion point, is very vanilla. It would represent the point where our civilization is halfway from where we started to where we are going. It might correspond to “peak energy” where we shift from increasing usage to decreasing usage (for whatever reason), but it does not have to. It could just be that we figure out most physics and AI in the next decades, become a spacefaring posthuman civilization, and expand for the next few billion years, using ever more energy but not having the same intense rate of knowledge growth as during the brief early era when we went from hunter gatherers to posthumans.
Case I, infinite growth, is not normally possible in the physical universe. Information can as far as we know not be stored beyond densities set by the Bekenstein bound ( where bits per kg per meter), and we only have access to a volume with mass density , so the total information growth must be bounded by . It grows quickly, but still just polynomially.
The exception to the finitude of growth is if we approach the boundaries of spacetime. Frank J. Tipler’s omega point theory shows how information processing could go infinite in a finite (proper) time in the right kind of collapsing universe with the right kind of physics. It doesn’t look like we live in one, but the possibility is tantalizing: could we arrange the right kind of extreme spacetime collapse to get the right kind of boundary for a mini-omega? It would be way beyond black hole computing and never be able to send back information, but still allow infinite experience. Most likely we are stuck in finitude, but it won’t hurt poking at the limits.
Conclusions
Indefinite exponential growth is never possible for physical properties that have some resource limitation, whether energy, space or heat dissipation. Sooner or later they will have to shift to a slower rate of growth – polynomial for expanding organisational processes (forced to this by the dimensionality of space, finite lightspeed and heat dissipation), and declining growth rate for processes dependent on a non-renewable resource.
That does not tell us much about the energy demands of a technological singularity. We can conclude that it cannot be infinite. It might be high enough that we bump into the resource, thermal and computational limits, which may be what actually defines the singularity energy and time scale. Technological singularities may also be small, intense and localized detonations that merely use up local resources, possibly spreading and repeating. But it could also turn out that advanced thinking is very low-energy (reversible or quantum) or requires merely manipulation of high level symbols, leading to a quiet singularity.
My own guess is that life and intelligence will always expand to fill whatever niche is available, and use the available resources as intensively as possible. That leads to instabilities and depletion, but also expansion. I think we are – if we are lucky and wise – set for a global conversion of the non-living universe into life, intelligence and complexity, a vast phase transition of matter and energy where we are part of the nucleating agent. It might not be sustainable over cosmological timescales, but neither is our universe itself. I’d rather see the stars and planets filled with new and experiencing things than continue a slow dance into the twilight of entropy.
…contemplate the marvel that is existence and rejoice that you are able to do so. I feel I have the right to tell you this because, as I am inscribing these words, I am doing the same. – Ted Chiang, Exhalation
The ever awesome Scott Alexander made a map of the rationalist blogosphere (webosphere? infosphere?) that I just saw (hat tip to Waldemar Ingdahl). Besides having plenty of delightful xkcd-style in-jokes, it is also useful by showing me parts of my intellectual neighbourhood I did not know well and might want to follow (want to follow, but probably can’t follow because of time constraints).
He starts out with pointing at some other concept maps like that, both the classic xkcd one and Julia Galef’s map of Bay Area memespace, which was a pleasant surprise to me. The latter explains the causal/influence links between communities in a very clear way.
One can of course quibble endlessly on what is left in or out (I loved the comments about the apparent lack of dragons on the rationalist map), but the two maps also show two different approaches to relatedness. In the rationalist map distance is based on some form of high-dimensional similarity, crunching it down to 2D using an informal version of a Kohonen map. Bodies of water can be used to “cheat” and add discontinuities/tears. In the memespace map the world is a network of causal/influence links, and the overall similarities between linked groups can be slight even when they share core memes. Here the cheating consists of leaving out broad links (Burning Man is mentioned; it would connect many nodes weakly to each other). In both cases what is left out is important, just as the choice of resolution. Good maps show the information the creator wants to show, and communicates it well.
Whether this is too much depends on the requirements of the system. Typically the relevant question is if the transmission latency is long compared to the processing time of the local processing. In the case of the human brain delays range between a few milliseconds up to 100 milliseconds, and neurons have typical frequencies up to maximally 100 Hz. The ratio between transmission time and a “processing cycle” will hence be between 0.1-10, i.e. not far from unity. In a microprocessor the processing time is on the order of s and delays across the chip (assuming 10% c signals) s, .
If signals move at lightspeed and the system needs to maintain a ratio close to unity, then the maximal size will be (or if information must also be sent back after a request). For nanosecond cycles this is on the order of centimeters, for femtosecond cycles 0.1 microns; conversely, for a planet-sized system (R=6000 km) s, 25 Hz.
The cycle size is itself bounded by lightspeed: a computational element such as a transistor needs to have a radius smaller than the time it takes to signal across it, otherwise it would not function as a unitary element. Hence it must be of size or, conversely, the cycle time must be slower than seconds. If a unit volume performs computations per second close to this limit, , or . (More elaborate analysis can deal with quantum limitations to processing, but this post will be classical.)
This does not mean larger systems are impossible, merely that the latency will be long compared to local processing (compare the Web). It is possible to split the larger system into a hierarchy of subsystems that are internally synchronized and communicate on slower timescales to form a unified larger system. It is sometimes claimed that very fast solid state civilizations will be uninterested in the outside world since it both moves immeasurably slowly and any interaction will take a long time as measured inside the fast civilization. However, such hierarchical arrangements may be both very large and arbitrarily slow: the civilization as a whole may find the universe moving at a convenient speed, despite individual members finding it frozen.
Waste heat dissipation
Information processing leads to waste heat production at some rate Watts per cubic meter.
Passive cooling
If the system just cools by blackbody radiation, the maximal radius for a given maximal temperature is
where is the Stefan–Boltzmann constant. This assumes heat is efficiently distributed in the interior.
If it does computations per volume per second, the total computations are – it really pays off being able to run it hot!
Still, molecular matter will melt above 3600 K, giving a max radius of around km. Current CPUs have power densities somewhat below 100 Watts per cm; if we assume 100 W per cubic centimetre and $R<29$ cm! If we assume a power dissipation similar to human brains the the max size becomes 2 km. Clearly the average power density needs to be very low to motivate a large system.
Using quantum dot logic gives a power dissipation of 61,787 W/m^3 and a radius of 470 meters. However, by slowing down operations by a factor the energy needs decrease by the factor . A reduction of speed to 3% gives a reduction of dissipation by a factor , enabling a 470 kilometre system. Since the total computations per second for the whole system scales with the size as slow reversible computing produces more computations per second in total than hotter computing. The slower clockspeed also makes it easier to maintain unitary subsystems. The maximal size of each such system scales as , and the total amount of computation inside them scales as . In the total system the number of subsystems change as : although they get larger, the whole system grows even faster and becomes less unified.
The limit of heat emissions is set by the Landauer principle: we need to pay at least Joules for each erased bit. So the number of bit erasures per second and cubic meter will be less than . To get a planet-sized system P will be around 1-10 W, implying for a hot 3600 K system, and for a cold 3 K system.
Active cooling
Passive cooling just uses the surface area of the system to radiate away heat to space. But we can pump coolants from the interior to the surface, and we can use heat radiators much larger than the surface area. This is especially effective for low temperatures, where radiation cooling is very weak and heat flows normally gentle (remember, they are driven by temperature differences: not much room for big differences when everything is close to 0 K).
If we have a sphere with radius R with internal volume of heat-emitting computronium, the surface must have area devoted to cooling pipes to get rid of the heat, where is the amount of Watts of heat that can b carried away by a square meter of piping. This can be formulated as the differential equation:
.
The solution is
.
This grows as for larger . The average computronium density across the system falls as as the system becomes larger.
If we go for a cooling substance with great heat capacity per mass at 25 degrees C, hydrogen has 14.30 J/g/K. But in terms of volume water is better at 4.2 J/cm/K. However, near absolute zero heat capacities drop down towards zero and there are few choices of fluids. One neat possibility is superfluid cooling. They carry no thermal energy – they can however transport heat by being converted into normal fluid and have a frictionless countercurrent bringing back superfluid from the cold end. The rate is limited by the viscosity of the normal fluid, and apparently there are critical velocities of the order of mm/s. A CERN paper gives the formula for the heat transport rate per square meter, where is 800 ms/kg at 1.8K, is the density of normal fluid, the superfluid, is the entropy per unit mass. Looking at it as a technical coolant gives a steady state heat flux along a pipe around 1.2 W/cm in a 1 meter pipe for a 1.9-1.8K difference in temperature. There are various nonlinearities and limitations due to the need to keep things below the lambda point. Overall, this produces a heat transfer coefficient of about , in line with the range 10,000-100,000 W/m^2/K found in forced convection (liquid metals have maximal transfer ability).
So if we assume about 1 K temperature difference, then for quantum dots at full speed we have a computational volume for a one km system 7.7 million cubic meters of computronium, or about 0.001 of the total volume. Slowing it down to 3% (reducing emissions by 1000) boosts the density to 86%. At this intensity a 1000 km system would look the same as the previous low-density one.
Conclusion
If the figure of merit is just computational capacity, then obviously a larger computer is always better. But if it matters that parts stay synchronized, then there is a size limit set by lightspeed. Smaller components are better in this analysis, which leaves out issues of error correction – below a certain size level thermal noise, quantum tunneling and cosmic rays will start to induce errors. Handling high temperatures well pays off enormously for a computer not limited by synchronization or latency in terms of computational power; after that, reducing volume heat production has a higher influence on total computation than actual computation density.
Active cooling is better than passive cooling, but the cost is wasted volume, which means longer signal delays. In the above model there is more computronium at the centre than at the periphery, somewhat ameliorating the effect (the mean distance is just 0.03R). However, this ignores the key issue of wiring, which is likely to be significant if everything needs to be connected to everything else.
In short, building a Jupiter-sized computer is tough. Asteroid-sized ones are far easier. If we ever find or build planet-sized systems they will either be reversible computing, or mostly passive storage rather than processing. Processors by their nature tend to be hot and small.
Cognitive enhancement is potentially very valuable to individuals and society, both in pure economic terms but also for living a good life. Intelligence protects against many bad things (from ill health to being a murder victim), increases opportunity, and allows you to create more for yourself and others. Cognitive ability interacts in a virtuous cycle with education, wealth and social capital.
That said, intelligence is not everything. Non-cognitive factors like motivation are also important. And societies that leave out people – due to sexism, racism, class divisions or other factors – will lose out on brain power. Giving these groups education and opportunities is a very cheap way of getting a big cognitive capital boost for society.
I was critiqued for talking about “cognitive enhancement” when I could just have talked about “cognitive change”. Enhancement has a built in assumption of some kind of improvement. However, a talk about fairness and cognitive change becomes rather anaemic: it just becomes a talk about what opportunities we should give people, not whether these changes affect their relationship in a morally relevant way.
Distributive justice
Theories of distributive justice typically try to answer: what goods are to be distributed, among whom, and what is the proper distribution? In our case it would be cognitive enhancements, and the interested parties are at least existing people but could include future generations (especially if we use genetic means).
Egalitarian theories argue that there has to be some form of equality, either equality of opportunity (everybody gets to enhance if they want), equality of outcome (everybody equally smart). Meritocratic theories would say the enhancement should be distributed by merit, presumably mainly to those who work hard at improving themselves or have already demonstrated great potential. Conversely, need-based theories and prioritarians argue we should prioritize those who are worst off or need the enhancement the most. Utilitarian justice requires the maximization of the total or average welfare across all relevant individuals.
Most of these theories agree with Rawls that impartiality is important: it should not matter who you are. Rawls famously argued for two principles of justice: (1) “Each person is to have an equal right to the most extensive total system of equal basic liberties compatible with a similar system of liberty for all.”, and (2) “Social and economic inequalities are to be arranged so that they are both (a) to the greatest benefit of the least advantaged, consistent with the just savings principle, and (b) attached to offices and positions open to all under conditions of fair equality of opportunity.”
It should be noted that a random distribution is impartial: if we cannot afford to give enhancement to everybody, we could have a lottery (meritocrats, prioritarians and utilitarians might want this lottery to be biased by some merit/need weighting, or to be just between the people relevant for getting the enhancement, while egalitarians would want everybody to be in).
Why should we even care about distributive justice? One argument is that we all have individual preferences and life goals we seek to achieve; if all relevant resources are in the hands of a few, there will be less preference satisfaction than if everybody had enough. In some cases there might be satiation, where we do not need more than a certain level of stuff to be satisfied and the distribution of the rest becomes irrelevant, but given the unbounded potential ambitions and desires of people it is unlikely to apply generally.
Many unequal situations are not seen as unjust because that is just the way the world is: it is a brute biological fact that males on average live shorter than females, and that there is a random distribution of cognitive ability. But if we change the technological conditions, these facts become possible to change: now we can redistribute stuff to affect them. Ironically, transhumanism hopes/aims to change conditions so that some states, which are at present not unjust, will become unjust!
Some enhancements are absolute: they help you or society no matter what others do, others are merely positional. Positional enhancements are a zero-sum game. However, doing the reversal test demonstrates that cognitive ability has absolute components: a world where everybody got a bit more stupid is not a better world, despite the unchanged relative rankings. There is more accidents and mistakes, more risk that some joint threat cannot be handled, and many life projects become harder and impossible to achieve. And the Flynn effect demonstrates that we are unlikely to be at some particular optimum right now.
The Rawlsian principles are OK with enhancement of the best-off if that helps the worst-off. This is not unreasonable for cognitive enhancement: the extreme high performers have a disproportionate output (patents, books, lectures) that benefit the rest of society, and the network effects of a generally smarter society might benefit everyone living in it. However, less cognitively able people are also less able to make use of opportunities created by this: intelligence is fundamentally a limit to equality of opportunity, and the more you have, the more you are able to select what opportunities and projects to aim for. So a Rawlsian would likely be fairly keen on giving more enhancement to the worst off.
Would a world where everybody had same intelligence be better than the current one? Intuitively it seems emotionally neutral. The reason is that we have conveniently and falsely talked about intelligence as one thing. As several audience members argued, there are many parts of intelligence. Even if one does not buy Gardner’s multiple intelligence theory, it is clear that there are different styles of problem-solving and problem-posing. This is true even if measurements of the magnitude of mental abilities are fairly correlated. A world where everybody thought in the same way would be a bad place. We might not want bad thinking, but there are many forms of good thinking. And we benefit from diversity of thinking styles. Different styles of cognition can make the world more unequal but not more unjust.
Inequality over time
As I have argued before, enhancements in the forms of gadgets and pills are likely to come down in price and become easy to distribute, while service-based enhancements are more problematic since they will tend to remain expensive. Modelling the spread of enhancement suggests that enhancements that start out expensive but then become cheaper first leads to a growth of inequality and then a decrease. If there is a levelling off effect where it becomes harder to enhance beyond a certain point this eventually leads to a more cognitively equal society as everybody catches up and ends up close to the efficiency boundary.
When considering inequality across time we should likely accept early inequality if it leads to later equality. After all, we should not treat spatially remote people differently from nearby people, and the same is true across time. As Claudio Tamburrini said, “Do not sacrifice poor of the future for the poor of the present.”
The risk is if there is compounding: enhanced people can make more money, and use that to enhance themselves or their offspring more. I seriously doubt this works for biomedical enhancement since there are limits to what biological brains can do (and human generation times are long compared to technology change), but it may be risky in regards to outsourcing cognition to machines. If you can convert capital into cognitive ability by just buying more software, then things could become explosive if the payoffs from being smart in this way are large. However, then we are likely to have an intelligence explosion anyway, and the issue of social justice takes back seat compared to the risks of a singularity. Another reason to think it is not strongly compounding is that geniuses are not all billionaires, and billionaires – while smart – are typically not the very most intelligent people. Pickety’s argument actually suggests that it is better to have a lot of money than a lot of brains since you can always hire smart consultants.
Francis Fukuyama famously argued that enhancement was bad for society because it risks making people fundamentally unequal. However, liberal democracy is already based on idea of common society of unequal individuals – they are different in ability, knowledge and power, yet treated fairly and impartially as “one man, one vote”. There is a difference between moral equality and equality measured in wealth, IQ or anything else. We might be concerned about extreme inequalities in some of the latter factors leading to a shift in moral equality, or more realistically, that those factors allow manipulation of the system to the benefit of the best off. This is why strengthening the “dominant cooperative framework” (to use Allen Buchanan’s term) is important: social systems are resilient, and we can make them more resilient to known or expected future challenges.
Conclusions
My main conclusions were:
Enhancing cognition can make society more or less unequal. Whether this is unjust depends both on the technology, one’s theory of justice, and what policies are instituted.
Some technologies just affect positional goods, and they make everybody worse off. Some are win-win situations, and I think much of intelligence enhancement is in this category.
Cognitive enhancement is likely to individually help the worst off, but make the best off compete harder.
Controlling mature technologies is hard, since there are both vested interests and social practices around them. We have an opportunity to affect the development of cognitive enhancement now, before it becomes very mainstream and hard to change.
Strengthening the “dominant cooperative framework” of society is a good idea in any case.
Individual morphological freedom must be safeguarded.
Speeding up progress and diffusion is likely to reduce inequality over time – and promote diversity.
Different parts of the world likely to approach CE differently and at different speeds.
As transhumanists, what do we want?
The transhumanist declaration makes wide access a point, not just on fairness or utilitarian grounds, but also for learning more. We have a limited perspective and cannot know well beforehand were the best paths are, so it is better to let people pursue their own inquiry. There may also be intrinsic values in freedom, autonomy and open-ended life projects: not giving many people the chance to this may lose much value.
Existential risk overshadows inequality: achieving equality by dying out is not a good deal. So if some enhancements increases existential risk we should avoid them. Conversely, if enhancements look like they reduce existential risk (maybe some moral or cognitive enhancements) they may be worth pursuing even if they are bad for (current) inequality.
We will likely end up with a diverse world that will contain different approaches, none universal. Some areas will prohibit enhancement, others allow it. No view is likely to become dominant quickly (without rather nasty means or some very surprising philosophical developments). That strongly speaks for the need to construct a tolerant world system.
If we have morphological freedom, then preventing cognitive enhancement needs to point at a very clear social harm. If the social harm is less than existing practices like schooling, then there is no legitimate reason to limit enhancement. There are also costs of restrictions: opportunity costs, international competition, black markets, inequality, losses in redistribution and public choice issues where regulators become self-serving. Controlling technology is like controlling art: it is an attempt to control human creativity and exploration, and should be done very cautiously.
I am one of the signatories of an open letter calling for a stronger aim at socially beneficial artificial intelligence.
It might seem odd to call for something like that: who in their right mind would not want AI to be beneficial? But when we look at the field (and indeed, many other research fields) the focus has traditionally been on making AI more capable. Besides some pure research interest and no doubt some “let’s create life”-ambition, the bulk of motivation has been to make systems that do something useful (or push in the direction of something useful).
“Useful” is normally defined in term of performing some task – translation, driving, giving medical advice – rather than having a good impact on the world. Better done tasks are typically good locally – people get translations more cheaply, things get transported, advice may be better – but have more complex knock-on effects: fewer translators, drivers or doctors needed, or that their jobs get transformed, plus potential risks from easy (but possibly faulty) translation, accidents and misuse of autonomous vehicles, or changes in liability. Way messier. Even if the overall impact is great, socially disruptive technologies that appear surprisingly fast can cause trouble, emergent misbehaviour and bad design choices can lead to devices that amplify risk (consider high frequency trading, badly used risk models, or anything that empowers crazy people). Some technologies may also lend themselves to centralizing power (surveillance, autonomous weapons) but reduce accountability (learning algorithms internalizing discriminatory assumptions in an opaque way). These considerations should of course be part of any responsible engineering and deployment, even if handling them is by no means solely the job of the scientist or programmer. Doing it right will require far more help from other disciplines.
The most serious risks come from the very smart systems that may emerge further into the future: they either amplify human ability in profound ways, or they are autonomous themselves. In both cases they make achieving goals easier, but do not have any constraints on what goals are sane, moral or beneficial. Solving the problem of how to keep such systems safe is a hard problem we ought to start on early. One of the main reasons for the letter is that so little effort has gone into better ways of controlling complex, adaptive and possibly self-improving technological systems. It makes sense even if one doesn’t worry about superintelligence or existential risk.
This is why we have to change some research priorities. In many cases it is just putting problems on the agenda as useful to work on: they are important but understudied, and a bit of investigation will likely go a long way. In some cases it is more a matter of signalling that different communities need to talk more to each other. And in some instances we really need to have our act together before big shifts occur – if unemployment soars to 50%, engineering design-ahead enables big jumps in tech capability, brains get emulated, or systems start self-improving we will not have time to carefully develop smart policies.
My experience with talking to the community is that there is not a big split between AI and AI safety practitioners: they roughly want the same thing. There might be a bigger gap between the people working on the theoretical, far out issues and the people working on the applied here-and-now stuff. I suspect they can both learn from each other. More research is, of course, needed.

=\Re\left(\int_{z_0}^z f(1-g^2)/2 dz\right)")
=\Re\left(\int_{z_0}^z if(1+g^2)/2 dz\right)")
=\Re\left(\int_{z_0}^z fg dz\right)")
,Y(z),Z(z))")
")


>1/2")




")

=\int_0^\infty t^{z-1}e^{-t} dt") , the continuous generalization of the factorial. While it grows rapidly for positive reals, it has fun poles for the negative integers and is generally complex.
, the continuous generalization of the factorial. While it grows rapidly for positive reals, it has fun poles for the negative integers and is generally complex. ") . The result is a nice fractal, with some domains approaching 1, and others running off to infinity.
. The result is a nice fractal, with some domains approaching 1, and others running off to infinity.
 . Zooming in a bit more reveals neat self-similar patterns with alternating “beans”:
. Zooming in a bit more reveals neat self-similar patterns with alternating “beans”:

") where c is the control parameter. I start with
where c is the control parameter. I start with 




 operations per second, or somewhere in the zettaFLOPS range
operations per second, or somewhere in the zettaFLOPS range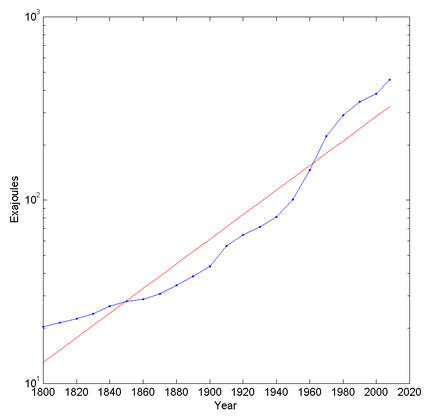
") joules of energy have to be dissipated. Given current efficiency trends we will reach this limit around 2048.
joules of energy have to be dissipated. Given current efficiency trends we will reach this limit around 2048. = \exp(kt) = P(t)/M(t)") , where
, where ") is the power of the system and
is the power of the system and ") is the mass of the system at time t. One can maintain exponential growth by reducing the mass as well as increasing the power.
is the mass of the system at time t. One can maintain exponential growth by reducing the mass as well as increasing the power. radiates it away into space, then the temperature will be
radiates it away into space, then the temperature will be ![T=[\rho \Phi R/3 \sigma]^{1/4}](http://s0.wp.com/latex.php?latex=T%3D%5B%5Crho+%5CPhi+R%2F3+%5Csigma%5D%5E%7B1%2F4%7D&bg=ffffff&fg=000000&s=0 "T=[\rho \Phi R/3 \sigma]^{1/4}") , or, if we have a maximal acceptable temperature,
, or, if we have a maximal acceptable temperature,  . So the system needs to become smaller as
. So the system needs to become smaller as  increases. If we use active heat transport instead (
increases. If we use active heat transport instead (
 . Again, the radius will be inversely proportional to
. Again, the radius will be inversely proportional to ![I = P/kT \ln(2) = \Phi M / kT\ln(2) = [4 \pi \rho /3 k \ln(2)] \Phi R^3 / T](http://s0.wp.com/latex.php?latex=I+%3D+P%2FkT+%5Cln%282%29+%3D+%5CPhi+M+%2F+kT%5Cln%282%29+%3D+%5B4+%5Cpi+%5Crho+%2F3+k+%5Cln%282%29%5D+%5CPhi+R%5E3+%2F+T&bg=ffffff&fg=000000&s=0 "I = P/kT \ln(2) = \Phi M / kT\ln(2) = [4 \pi \rho /3 k \ln(2)] \Phi R^3 / T") bits per second. Using the first cooling model gives us
bits per second. Using the first cooling model gives us  – a massive advantage for running extremely hot and dense computation. In the second cooling model
– a massive advantage for running extremely hot and dense computation. In the second cooling model  : in both cases higher energy rate densities make it harder to compute when close to the thermodynamic limit. Hence there might be an upper limit to how much we may want to push
: in both cases higher energy rate densities make it harder to compute when close to the thermodynamic limit. Hence there might be an upper limit to how much we may want to push  : the higher the rate, the faster it will run out (and it is independent of size!). If the system is expanding at speed v it will gain and use up mass at a rate
: the higher the rate, the faster it will run out (and it is independent of size!). If the system is expanding at speed v it will gain and use up mass at a rate /c^2") ; if
; if  where
where  bits per kg per meter), and we only have access to a volume
bits per kg per meter), and we only have access to a volume  with mass density
with mass density  . It grows quickly, but still just polynomially.
. It grows quickly, but still just polynomially.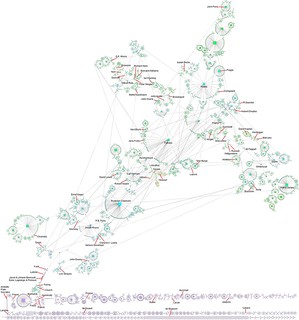

 . It will take maximally
. It will take maximally  seconds to signal across it, and the
seconds to signal across it, and the .
. is long compared to the processing time
is long compared to the processing time  of the local processing. In the case of the human brain delays range between a few milliseconds up to 100 milliseconds, and neurons have typical frequencies up to maximally 100 Hz. The ratio
of the local processing. In the case of the human brain delays range between a few milliseconds up to 100 milliseconds, and neurons have typical frequencies up to maximally 100 Hz. The ratio  between transmission time and a “processing cycle” will hence be between 0.1-10, i.e. not far from unity. In a microprocessor the processing time is on the order of
between transmission time and a “processing cycle” will hence be between 0.1-10, i.e. not far from unity. In a microprocessor the processing time is on the order of  s and delays across the chip (assuming 10% c signals)
s and delays across the chip (assuming 10% c signals)  s,
s,  .
. (or
(or  if information must also be sent back after a request). For nanosecond cycles this is on the order of centimeters, for femtosecond cycles 0.1 microns; conversely, for a planet-sized system (R=6000 km)
if information must also be sent back after a request). For nanosecond cycles this is on the order of centimeters, for femtosecond cycles 0.1 microns; conversely, for a planet-sized system (R=6000 km)  s, 25 Hz.
s, 25 Hz. or, conversely, the cycle time must be slower than
or, conversely, the cycle time must be slower than  seconds. If a unit volume performs
seconds. If a unit volume performs  computations per second close to this limit,
computations per second close to this limit, (1/r)^3") , or
, or  . (More elaborate analysis can deal with quantum limitations to processing, but this post will be classical.)
. (More elaborate analysis can deal with quantum limitations to processing, but this post will be classical.) Watts per cubic meter.
Watts per cubic meter. is
is

 is the Stefan–Boltzmann constant. This assumes heat is efficiently distributed in the interior.
is the Stefan–Boltzmann constant. This assumes heat is efficiently distributed in the interior. – it really pays off being able to run it hot!
– it really pays off being able to run it hot! km. Current CPUs have power densities somewhat below 100 Watts per cm
km. Current CPUs have power densities somewhat below 100 Watts per cm ; if we assume 100 W per cubic centimetre
; if we assume 100 W per cubic centimetre  and $R<29$ cm! If we assume a power dissipation similar to human brains
and $R<29$ cm! If we assume a power dissipation similar to human brains  the the max size becomes 2 km. Clearly the average power density needs to be very low to motivate a large system.
the the max size becomes 2 km. Clearly the average power density needs to be very low to motivate a large system. the energy needs decrease by the factor
the energy needs decrease by the factor  . A reduction of speed to 3% gives a reduction of dissipation by a factor
. A reduction of speed to 3% gives a reduction of dissipation by a factor  , enabling a 470 kilometre system. Since the total computations per second for the whole system scales with the size as
, enabling a 470 kilometre system. Since the total computations per second for the whole system scales with the size as 

 slow reversible computing produces more computations per second in total than hotter computing. The slower clockspeed also makes it easier to maintain unitary subsystems. The maximal size of each such system scales as
slow reversible computing produces more computations per second in total than hotter computing. The slower clockspeed also makes it easier to maintain unitary subsystems. The maximal size of each such system scales as  , and the total amount of computation inside them scales as
, and the total amount of computation inside them scales as  . In the total system the number of subsystems change as
. In the total system the number of subsystems change as ^3 = f^{-3/2}") : although they get larger, the whole system grows even faster and becomes less unified.
: although they get larger, the whole system grows even faster and becomes less unified.") Joules for each erased bit. So
Joules for each erased bit. So  the number of bit erasures per second and cubic meter will be less than
the number of bit erasures per second and cubic meter will be less than ") . To get a planet-sized system P will be around 1-10 W, implying
. To get a planet-sized system P will be around 1-10 W, implying  for a hot 3600 K system, and
for a hot 3600 K system, and  for a cold 3 K system.
for a cold 3 K system.") of heat-emitting computronium, the surface must have
of heat-emitting computronium, the surface must have /X") area devoted to cooling pipes to get rid of the heat, where
area devoted to cooling pipes to get rid of the heat, where  is the amount of Watts of heat that can b carried away by a square meter of piping. This can be formulated as the differential equation:
is the amount of Watts of heat that can b carried away by a square meter of piping. This can be formulated as the differential equation:= 4\pi R^2 - PV(R)/X") .
.=4 \pi ( (P/X)^2R^2 - 2 (P/X) R - 2 \exp(-(P/X)R) + 2) (X^3/P^3)") .
. for larger
for larger  as the system becomes larger.
as the system becomes larger. /K. However, near absolute zero heat capacities drop down towards zero and there are few choices of fluids. One neat possibility is superfluid cooling. They carry no thermal energy – they can however transport heat by being converted into normal fluid and have a frictionless countercurrent bringing back superfluid from the cold end. The rate is limited by the viscosity of the normal fluid, and apparently there are critical velocities of the order of mm/s. A
/K. However, near absolute zero heat capacities drop down towards zero and there are few choices of fluids. One neat possibility is superfluid cooling. They carry no thermal energy – they can however transport heat by being converted into normal fluid and have a frictionless countercurrent bringing back superfluid from the cold end. The rate is limited by the viscosity of the normal fluid, and apparently there are critical velocities of the order of mm/s. A ![Q=[A \rho_n / \rho_s^3 S^4 T^3 \Delta T ]^{1/3}](http://s0.wp.com/latex.php?latex=Q%3D%5BA+%5Crho_n+%2F+%5Crho_s%5E3+S%5E4+T%5E3+%5CDelta+T+%5D%5E%7B1%2F3%7D&bg=ffffff&fg=000000&s=0 "Q=[A \rho_n / \rho_s^3 S^4 T^3 \Delta T ]^{1/3}") for the heat transport rate per square meter, where
for the heat transport rate per square meter, where  is 800 ms/kg at 1.8K,
is 800 ms/kg at 1.8K,  is the density of normal fluid,
is the density of normal fluid,  the superfluid,
the superfluid,  is the entropy per unit mass.
is the entropy per unit mass.  , in line with the range 10,000-100,000 W/m^2/K found in forced convection (liquid metals have maximal transfer ability).
, in line with the range 10,000-100,000 W/m^2/K found in forced convection (liquid metals have maximal transfer ability). we have a computational volume for a one km system 7.7 million cubic meters of computronium, or about 0.001 of the total volume. Slowing it down to 3% (reducing emissions by 1000) boosts the density to 86%. At this intensity a 1000 km system would look the same as the previous low-density one.
we have a computational volume for a one km system 7.7 million cubic meters of computronium, or about 0.001 of the total volume. Slowing it down to 3% (reducing emissions by 1000) boosts the density to 86%. At this intensity a 1000 km system would look the same as the previous low-density one.

{kind=link}
{kind=link}