When @fermatslibrary brought up this 1940 paper about why we have nothing to worry about from nuclear chain reactions, I first checked that it was real and not a modern forgery. Because it seems almost too good to be true in the light of current AI safety talk.
It gives a summary of a recent fission experiment that demonstrate a chain reaction where neutrons released from a split atom induces other atoms to split. The article claimed this caused widespread unease:
“Wasn’t there a dangerous possibility that the uranium would at last become explosive ? That the samples being bombarded in the laboratories at Columbia University, for example, might blow up the whole of New York City ? To make matters more ominous, news of fission research from Germany, plentiful in the early part of 1 939, mysteriously and abruptly stopped for some months. Had government censorship been placed on what might be a secret of military importance ?
The press and populace, getting wind of these possibly lethal goings-on, raised a hue and cry.”
However, physicists were unafraid to of being blown up (and blowing up the rest of the world).
“Nothing daunted, however, the physicists worked on to find out whether or not they would be blown up, and the rest of us along with them.”
Then comes a good description of the recent French experiment in making a self-sustaining chain reaction. The resulting neutrons are too fast to interact much with other atoms, making the net number dwindle despite a few initial induced fission. And since it runs out, there is no risk.
There are some caveats, but don’t worry, scientific consensus seems to be firmly on the safety side!
“With typical French – and scientific – caution, they added that this was per haps true only for the particular conditions of their own experiment, which was carried out on a large mass of uranium under water. But most scientists agreed that it was very likely true in general.”
This article was 2 years before the Manhattan Project started, so it is unlikely to have been due to deliberate disinformation: it is an honest take on the state of knowledge at the time. Except of course that there was actually a fair bit to worry about soon…
Human engineering can change conditions *deliberately* to slow down neutrons with a moderator (making a reactor) or use an isotope where hot neutrons cause fission (the atomic bomb). The natural state is not a reliable indicator of the technical state.
It cannot have escaped the contemporary reader that this is very similar to many claims AI will remain safe. It is not reliable enough to self-improve or perform nefarious tasks well, so the chain reaction runs down. Surely nobody can make an AI moderator or find AI plutonium!
More generally, this seems a common argument failure mode: solid empirical evidence against something within known conditions cannot just be extrapolated reliably outside the conditions. What is needed is for the argument to work is (1) the conditions cannot be changed, (2) the result can be smoothly extrapolated, or (3) the impossibility needs to be relevant to the risk.
For nuclear chain reactions both (1) and (2) were wrong (moderators and plutonium). Arguments that AI will always hallucinate may be true, but that does not mean safety follows, since hallucinating humans (the results apply equally to us) are clearly potentially risky.
I think this is a relative to Arthur C. Clarke’s “failure of nerve” (not following extrapolation implications, often leading to overconfident impossibility claims) and “failure of imagination” (not looking outside the known domain or acknowledging there could be anything out there) he discusses in (1982). Profiles of the Future: An Inquiry to the Limits of the Possible.
Also, when reading the article I thought about my discussions with Tom Moynihanabout how many tropes are earlier than the discoveries or events enabling them to become real – in the Scientific American article we already have the planet-destroying explosion and scientists “going dark” for military secrecy.
The funny thing is that this allows enlightened writers to poke fun at those naive people who merely believe in tropes, rather than the real science. The problem is that sometimes we make tropes true.
No terrorist attack in the USA will kill > 100 people: 95%
1 (Orlando: 50)
I will be involved in at least one published/accepted-to-publish research paper by the end of 2015: 95%
1
Vesuvius will not have a major eruption: 95%
1
I will remain at my same job through the end of 2015: 90%
1
MAX IV in Lund delivers X-rays: 90%
1
Andart II will remain active: 90%
1
Israel will not get in a large-scale war (ie >100 Israeli deaths) with any Arab state: 90%
1
US will not get involved in any new major war with death toll of > 100 US soldiers: 90%
1
New Zeeland has not decided to change current flag at end of year: 85%
1
No multi-country Ebola outbreak: 80%
1
Assad will remain President of Syria: 80%
1
ISIS will control less territory than it does right now: 80%
1
North Korea’s government will survive the year without large civil war/revolt: 80%
1
The US NSABB will allow gain of function funding: 80%
1 [Their report suggests review before funding, currently it is up to the White House to respond. ]
US presidential election: democratic win: 75%
0
A general election will be held in Spain: 75%
1
Syria’s civil war will not end this year: 75%
1
There will be no NEO with Torino Scale >0 on 31 Dec 2016: 75%
0 (2016 XP23 showed up on the scale according to JPL, but NEODyS Risk List gives it a zero.)
The Atlantic basin ACE will be below 96.2: 70%
0 (ACE estimate on Jan 1 is 132)
Sweden does not get a seat on the UN Security Council: 70%
0
Bitcoin will end the year higher than $200: 70%
1
Another major eurozone crisis: 70%
0
Brent crude oil will end the year lower than $60 a barrel: 70%
1
I will actually apply for a UK citizenship: 65%
0
UK referendum votes to stay in EU: 65%
0
China will have a GDP growth above 5%: 65%
1
Evidence for supersymmetry: 60%
0
UK larger GDP than France: 60%
1 (although it is a close call; estimates put France at 2421.68 and UK at 2848.76 – quite possibly this might change)
France GDP growth rate less than 2%: 60%
1
I will have made significant progress (4+ chapters) on my book: 55%
0
Iran nuclear deal holding: 50%
1
Apple buys Tesla: 50%
0
The Nikkei index ends up above 20,000: 50%
0 (nearly; the Dec 20 max was 19,494)
Overall, my Brier score is 0.1521. Which doesn’t feel too bad.
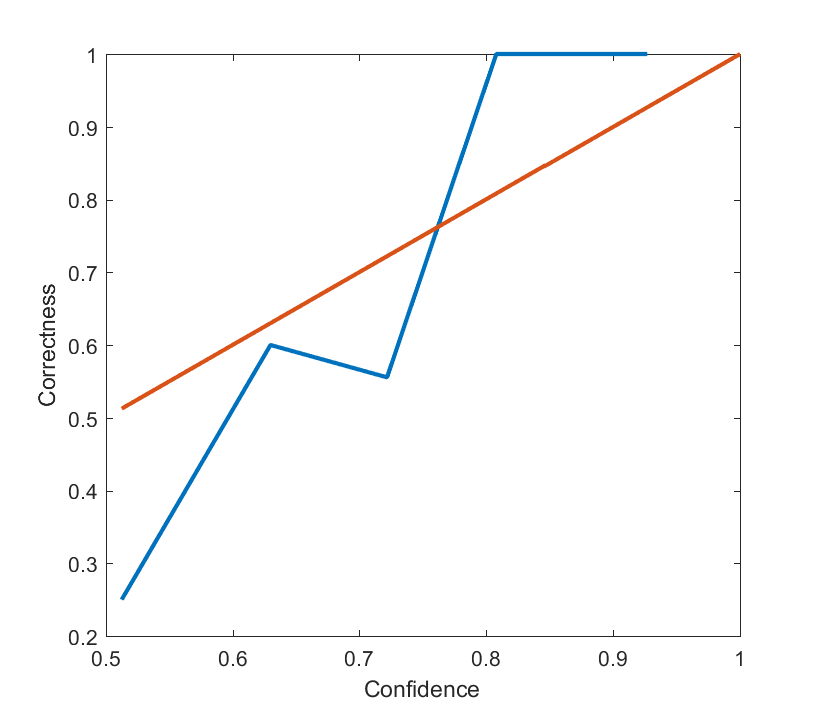
Plotting the results (where I bin together things in [0.5,0.55], [0.5,0.65], [0.7 0.75], [0.8,0.85], [0.9,0.99] bins) give this calibration plot:
Plot of average correctness of my predictions for 2016 as a function of confidence (blue). Red line is perfect calibration.
Overall, I did great on my “sure bets” and fairly weakly on my less certain bets. I did not have enough questions to make this very statistically solid (coming up with good prediction questions is hard!), but the overall shape suggests that I am a bit overconfident, which is not surprising.
Time to come up with good 2017 prediction questions.
Yesterday I gave a talk at the joint Bloomberg-London Futurist meeting “The state of the future” about the future of decisionmaking. Parts were updates on my policymaking 2.0 talk (turned into this chapter), but I added a bit more about individual decisionmaking, rationality and forecasting.
The big idea of the talk: ensemble methods really work in a lot of cases. Not always, not perfectly, but they should be among the first tools to consider when trying to make a robust forecast or decision. They are Bayes’ broadsword:
OK, so in forecasting it looks like using multiple methods, theories and data sources (including experts) is a way to get better results.
Statistical machine learning
A standard problem in machine learning is to classify something into the right category from data, given a set of training examples. For example, given medical data such as age, sex, and blood test results, diagnose what a particular disease a patient might suffer from. The key problem is that it is non-trivial to construct a classifier that works well on data different from the training data. It can work badly on new data, even if it works perfectly on the training examples. Two classifiers that perform equally well during training may perform very differently in real life, or even for different data.
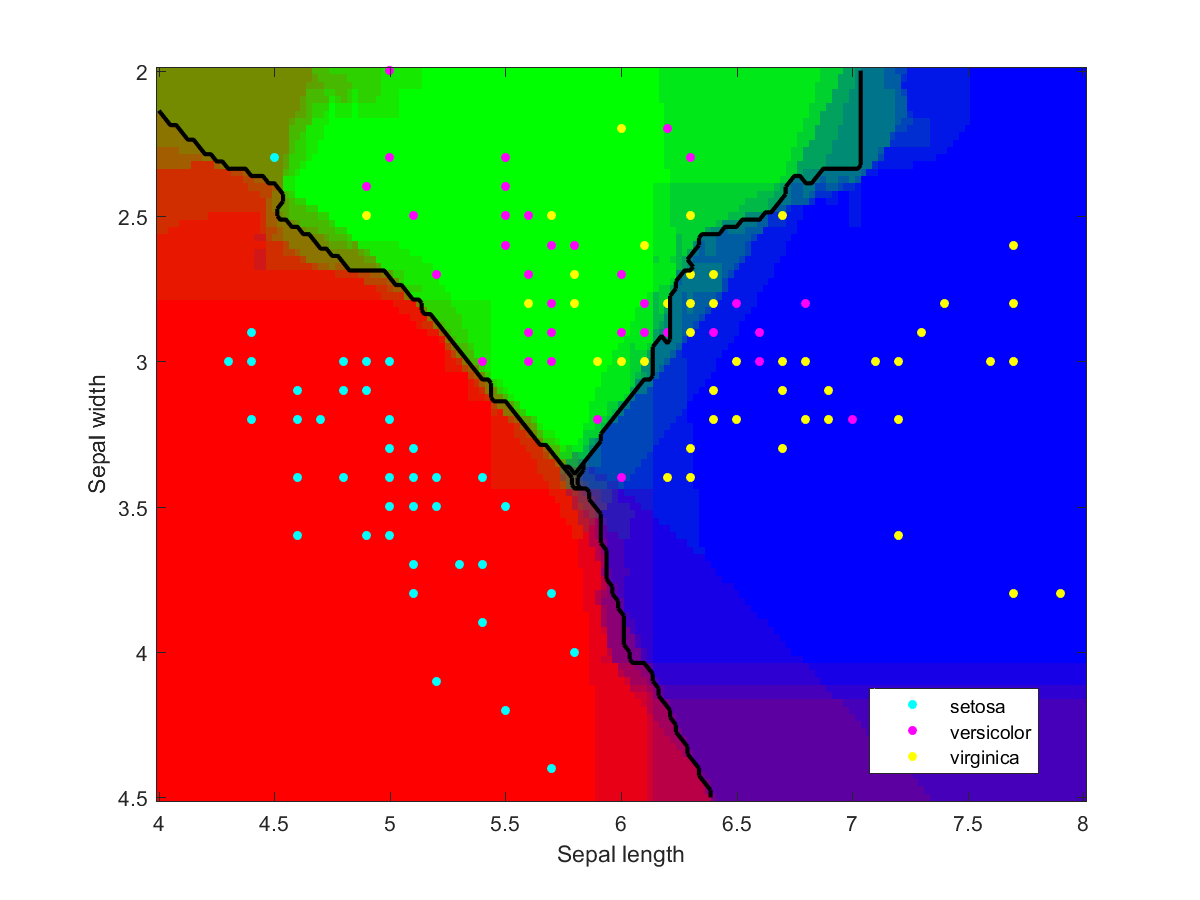
The obvious solution is to combine several classifiers and average (or vote about) their decisions: ensemble based systems. This reduces the risk of making a poor choice, and can in fact improve overall performance if they can specialize for different parts of the data. This also has other advantages: very large datasets can be split into manageable chunks that are used to train different components of the ensemble, tiny datasets can be “stretched” by random resampling to make an ensemble trained on subsets, outliers can be managed by “specialists”, in data fusion different types of data can be combined, and so on. Multiple weak classifiers can be combined into a strong classifier this way.
Iris data classified using an ensemble of classification methods (LDA, NBC, various kernels, decision tree). Note how the combination of classifiers also roughly indicates the overall reliability of classifications in a region.
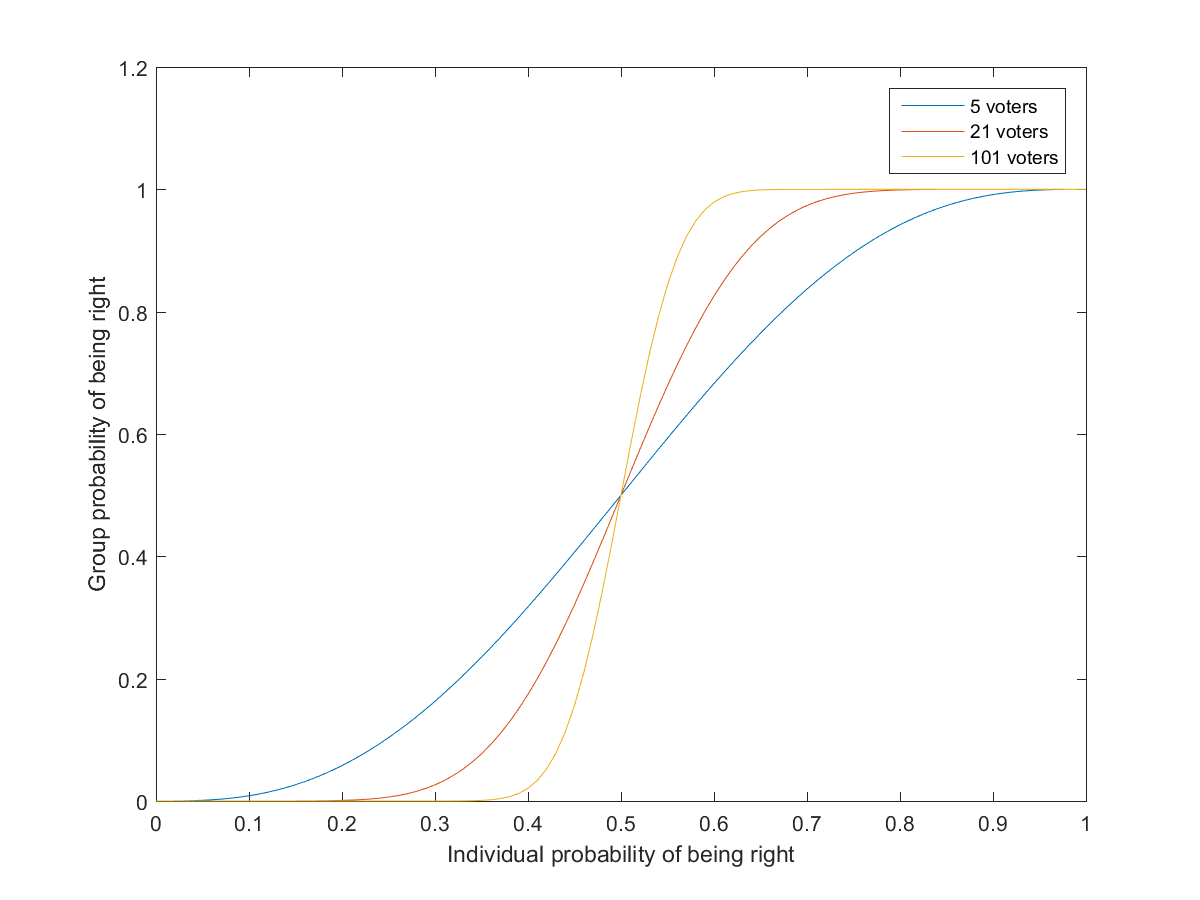
Condorcet’s jury theorem is perhaps the classic result in group problem solving: if a group of people hold a majority vote, and each has a probability p>1/2 of voting for the correct choice, then the probability the group will vote correctly is higher than p and will tend to approach 1 as the size of the group increases. This presupposes that votes are independent, although stronger forms of the theorem have been proven. (In reality people may have different preferences so there is no clear “right answer”)
Probability that groups of different sizes will reach the correct decision as a function of the individual probability of voting right.
By now the pattern is likely pretty obvious. Weak decision-makers (the voters) are combined through a simple procedure (the vote) into better decision-makers.
Group problem solving is known to be pretty good at smoothing out individual biases and errors. In The Wisdom of Crowds Surowiecki suggests that the ideal crowd for answering a question in a distributed fashion has diversity of opinion, independence (each member has an opinion not determined by the other’s), decentralization (members can draw conclusions based on local knowledge), and the existence of a good aggregation process turning private judgements into a collective decision or answer.
Perhaps the grandest example of group problem solving is the scientific process, where peer review, replication, cumulative arguments, and other tools make error-prone and biased scientists produce a body of findings that over time robustly (if sometimes slowly) tends towards truth. This is anything but independent: sometimes a clever structure can improve performance. However, it can also induce all sorts of nontrivial pathologies – just consider the detrimental effects status games have on accuracy or focus on the important topics in science.
Small group problem solving on the other hand is known to be great for verifiable solutions (everybody can see that a proposal solves the problem), but unfortunately suffers when dealing with “wicked problems” lacking good problem or solution formulation. Groups also have scaling issues: a team of N people need to transmit information between all N(N-1)/2 pairs, which quickly becomes cumbersome.
One way of fixing these problems is using software and formal methods.
The Good Judgement Project (partially run by Tetlock and with Armstrong on the board of advisers) participated in the IARPA ACE program to try to improve intelligence forecasts. They used volunteers and checked their forecast accuracy (not just if they got things right, but if claims that something was 75% likely actually came true 75% of the time). This led to a plethora of fascinating results. First, accuracy scores based on the first 25 questions in the tournament predicted subsequent accuracy well: some people were consistently better than others, and it tended to remain constant. Training (such a debiasing techniques) and forming teams also improved performance. Most impressively, using the top 2% “superforecasters” in teams really outperformed the other variants. The superforecasters were a diverse group, smart but by no means geniuses, updating their beliefs frequently but in small steps.
The key to this success was that a computer- and statistics-aided process found the good forecasters and harnessed them properly (plus, the forecasts were on a shorter time horizon than the policy ones Tetlock analysed in his previous book: this both enables better forecasting, plus the all-important feedback on whether they worked).
Another good example is the Galaxy Zoo, an early crowd-sourcing project in galaxy classification (which in turn led to the Zooniverse citizen science project). It is not just that participants can act as weak classifiers and combined through a majority vote to become reliable classifiers of galaxy type. Since the type of some galaxies is agreed on by domain experts they can used to test the reliability of participants, producing better weightings. But it is possible to go further, and classify the biases of participants to create combinations that maximize the benefit, for example by using overly “trigger happy” participants to find possible rare things of interest, and then check them using both conservative and neutral participants to become certain. Even better, this can be done dynamically as people slowly gain skill or change preferences.
The right kind of software and on-line “institutions” can shape people’s behavior so that they form more effective joint cognition than they ever could individually.
Conclusions
The big idea here is that it does not matter that individual experts, forecasting methods, classifiers or team members are fallible or biased, if their contributions can be combined in such a way that the overall output is robust and less biased. Ensemble methods are examples of this.
While just voting or weighing everybody equally is a decent start, performance can be significantly improved by linking it to how well the participants perform. Humans can easily be motivated by scoring (but look out for disalignment of incentives: the score must accurately reflect real performance and must not be gameable).
Having a flexible structure that can change is a good approach to handling a changing world. If people have disincentives to change their mind or change teams, they will not update beliefs accurately.
I got a good question after the talk: if we are supposed to keep our models simple, how can we use these complicated ensembles? The answer is of course that there is a difference between using a complex and a complicated approach. The methods that tend to be fragile are the ones with too many free parameters, too much theoretical burden: they are the complex “hedgehogs”. But stringing together a lot of methods and weighting them appropriately merely produces a complicated model, a “fox”. Component hedgehogs are fine as long as they are weighed according to how well they actually perform.
(In fact, adding together many complex things can make the whole simpler. My favourite example is the fact that the Kolmogorov complexity of integers grows boundlessly on average, yet the complexity of the set of all integers is small – and actually smaller than some integers we can easily name. The whole can be simpler than its parts.)
In the end, we are trading Occam’s razor for a more robust tool: Bayes’ Broadsword. It might require far more strength (computing power/human interaction) to wield, but it has longer reach. And it hits hard.
Appendix: individual classifiers
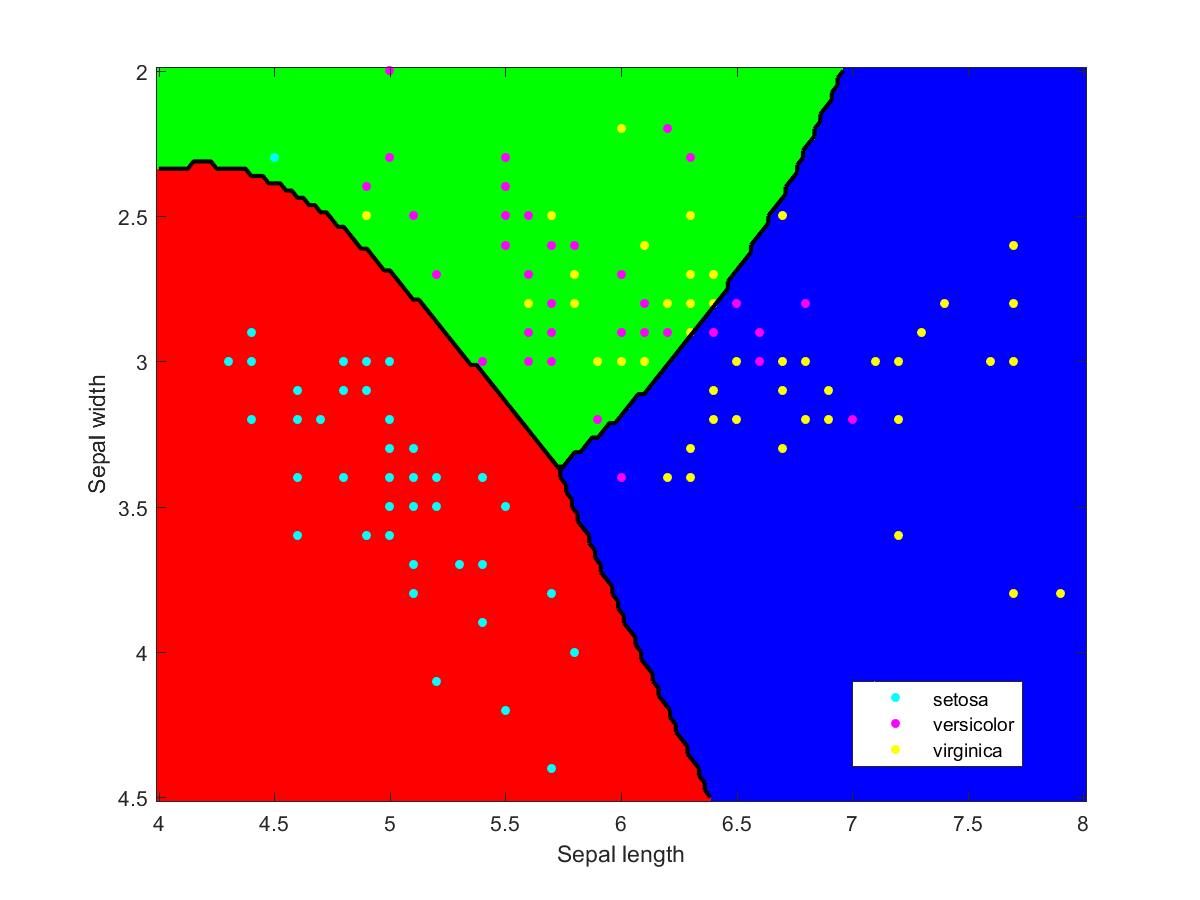
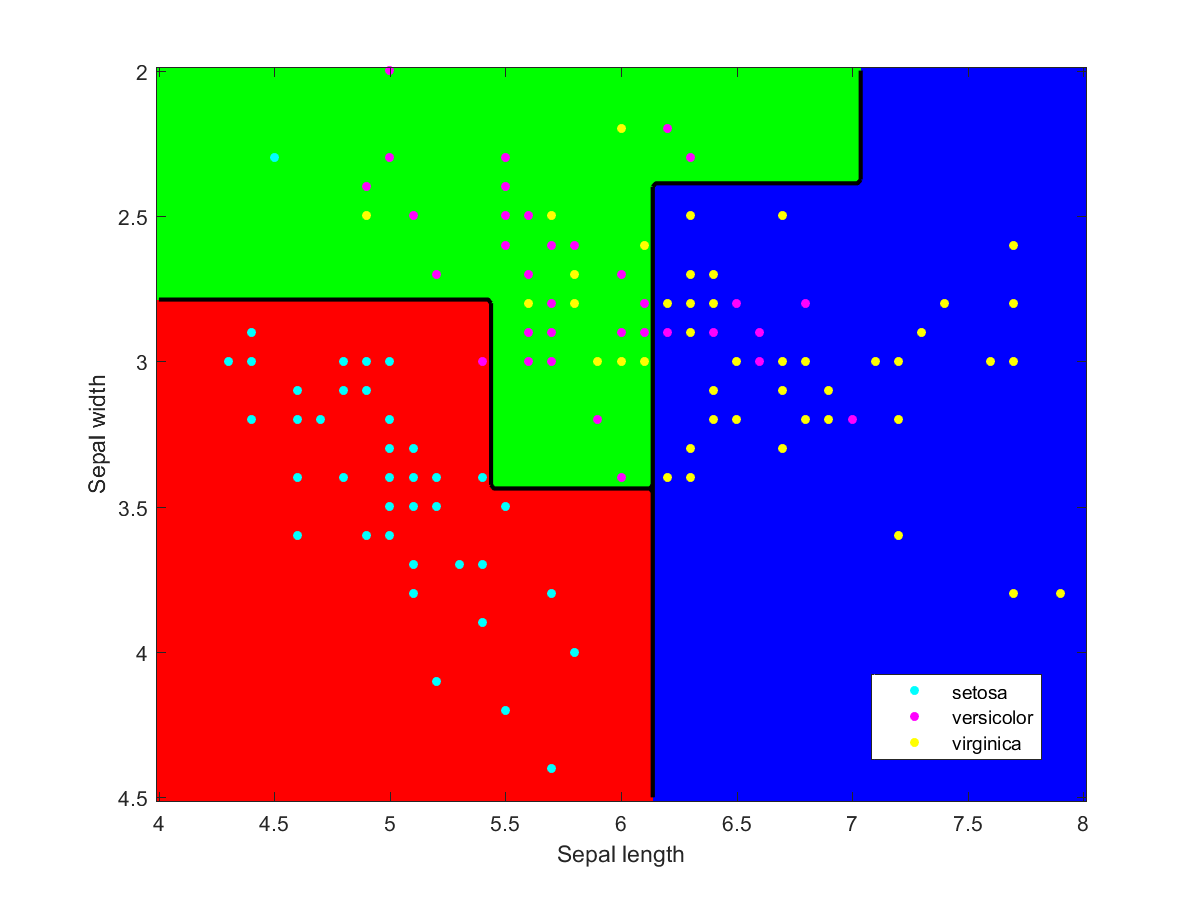
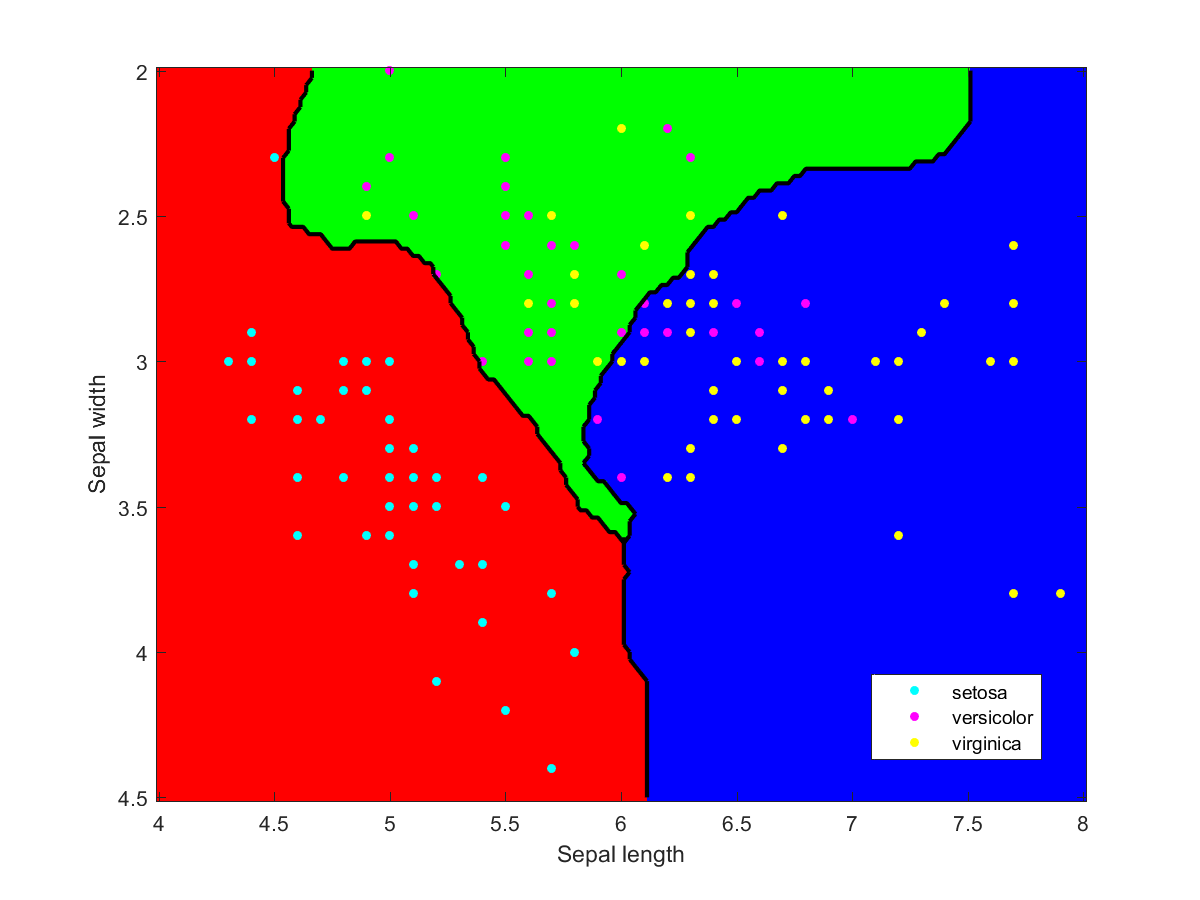
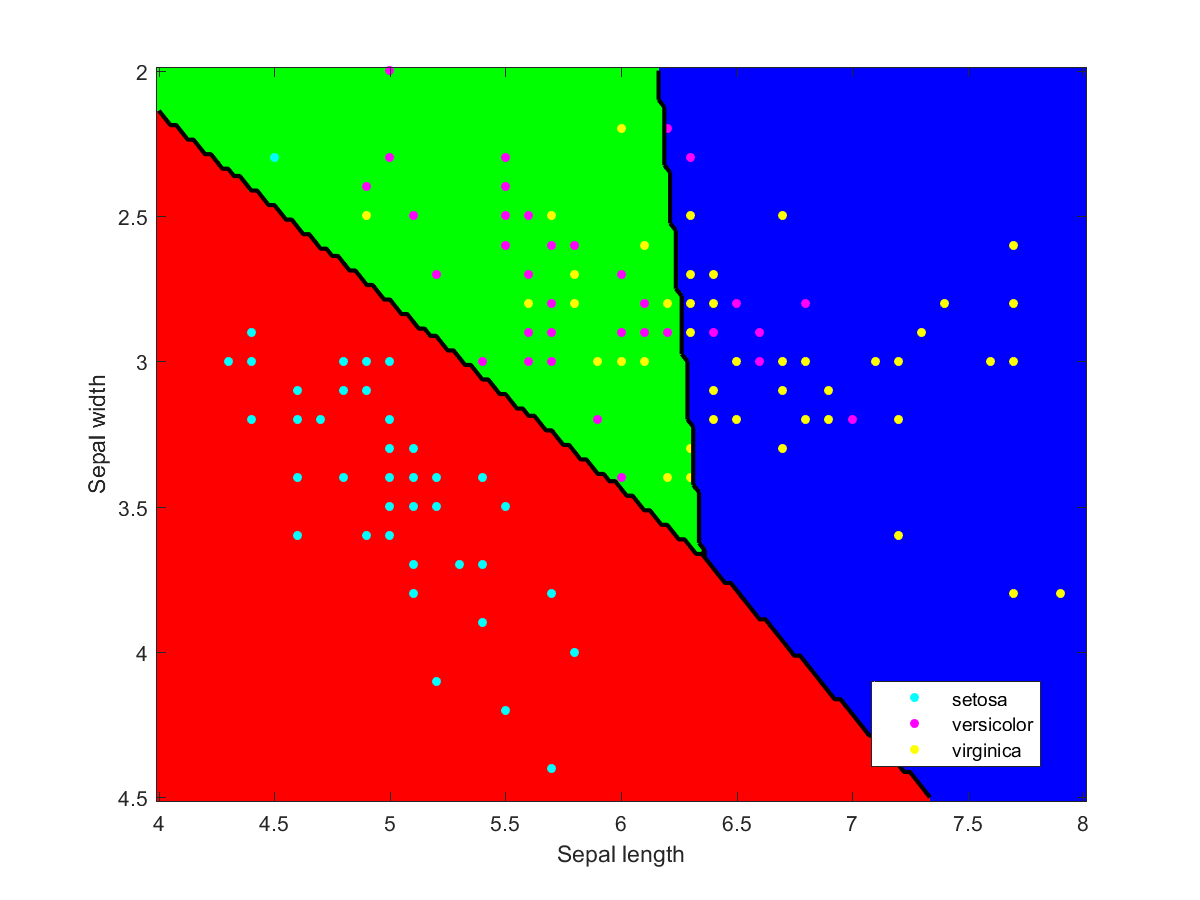
I used Matlab to make the illustration of the ensemble classification. Here are some of the component classifiers. They are all based on the examples in the Matlab documentation. My ensemble classifier is merely a maximum vote between the component classifiers that assign a class to each point.
Iris data classified using a naive Bayesian classifier assuming Gaussian distributions.Iris data classified using a decision tree.Iris data classified using Gaussian kernels.Iris data classified using linear discriminant analysis.