The minimal example would be if each risk had 50% independent chance of happening: then the observable correlation coefficient would be -0.5 (not -1, since there is 1/3 chance to get neither risk; the possible outcomes are: no event, risk A, and risk B). If the probability of no disaster happening is N/(N+2) and the risks are equal 1/(N+2), then the correlation will be -1/(N+1).
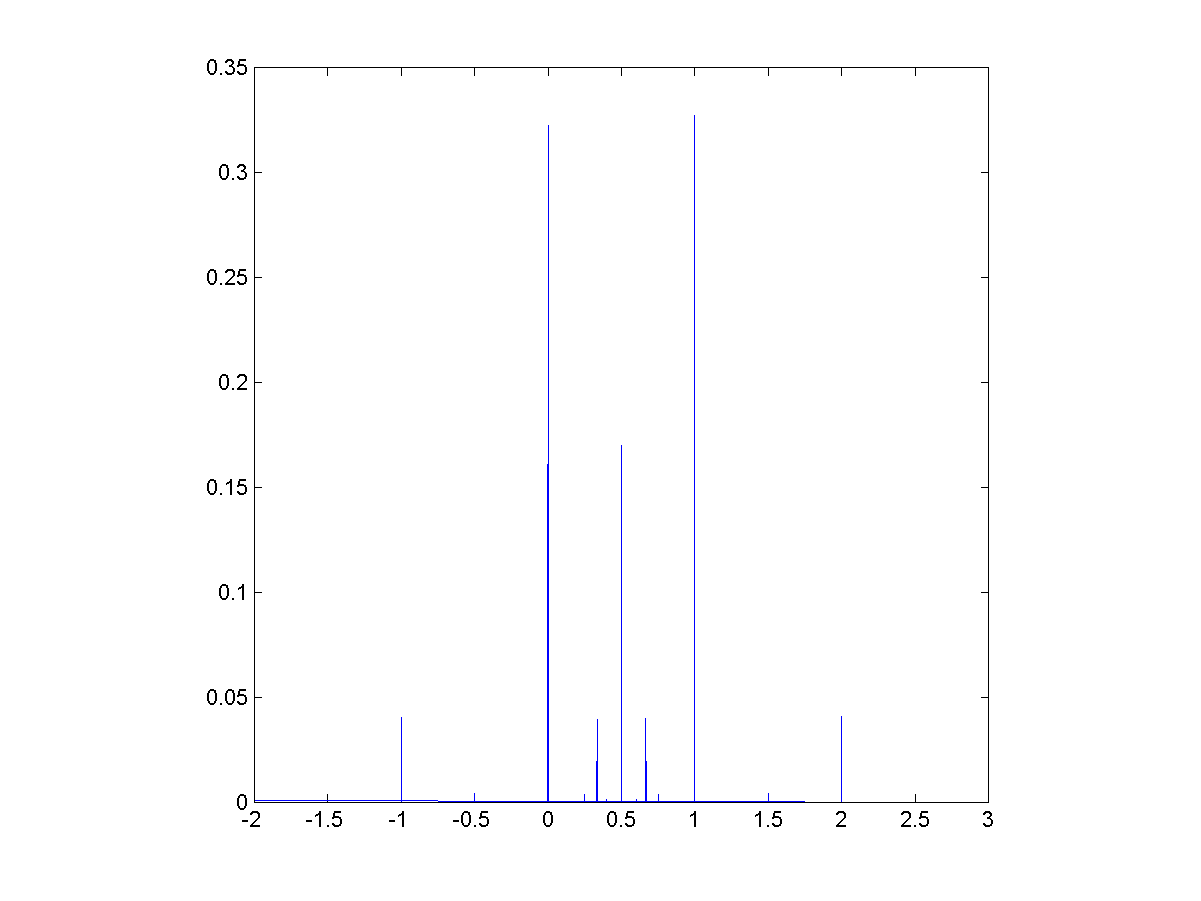
I tried a slightly more elaborate model. Assume X and Y to be independent power-law distributed disasters (say war and pestillence outbreaks), and that if X+Y is larger than seven billion no observers will remain to see the outcome. If we ramp up their size (by multiplying X and Y with some constant) we get the following behaviour (for alpha=3):
(Top) correlation between observed power-law distributed independent variables multiplied by an increasing multiplier, where observation is contingent on their sum being smaller than 7 billion. Each point corresponds to 100,000 trials. (Bottom) Fraction of trials where observers were wiped out.
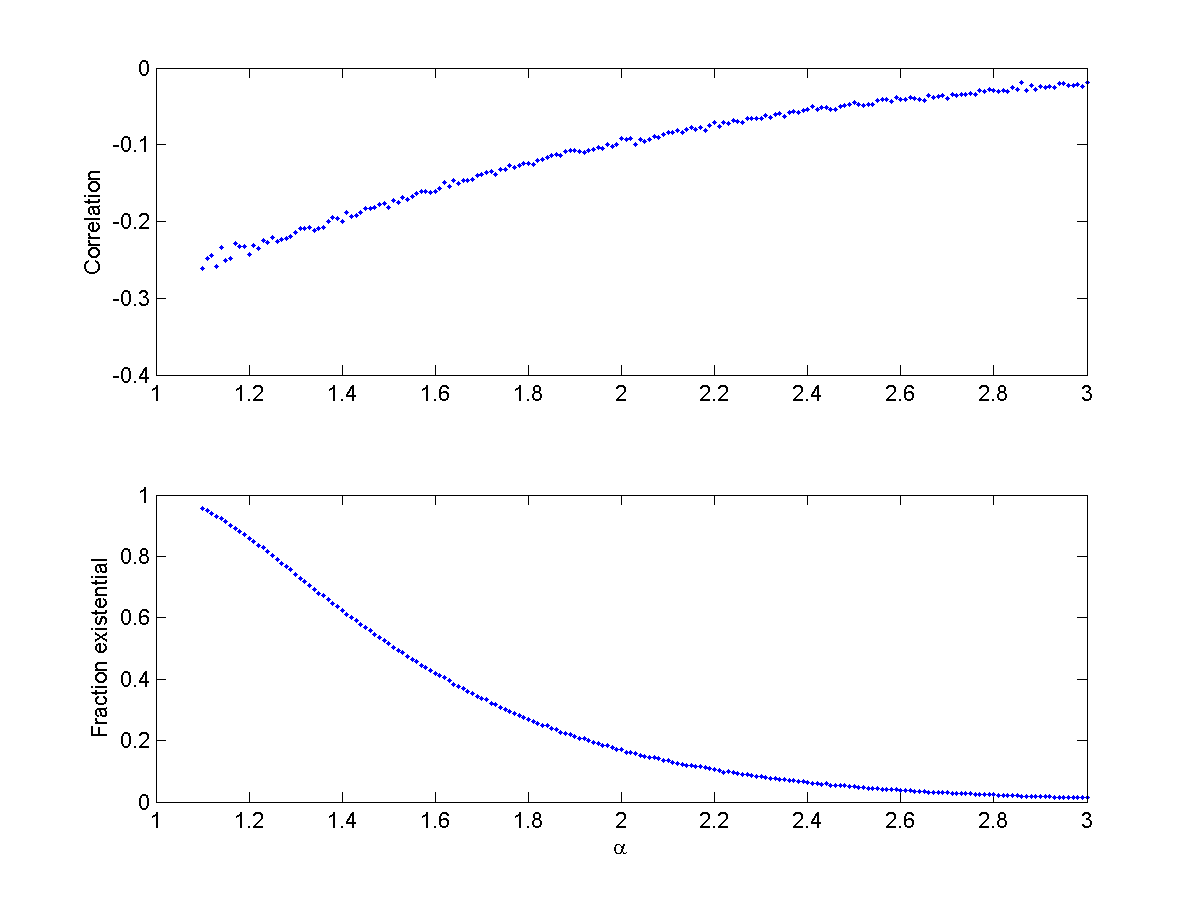
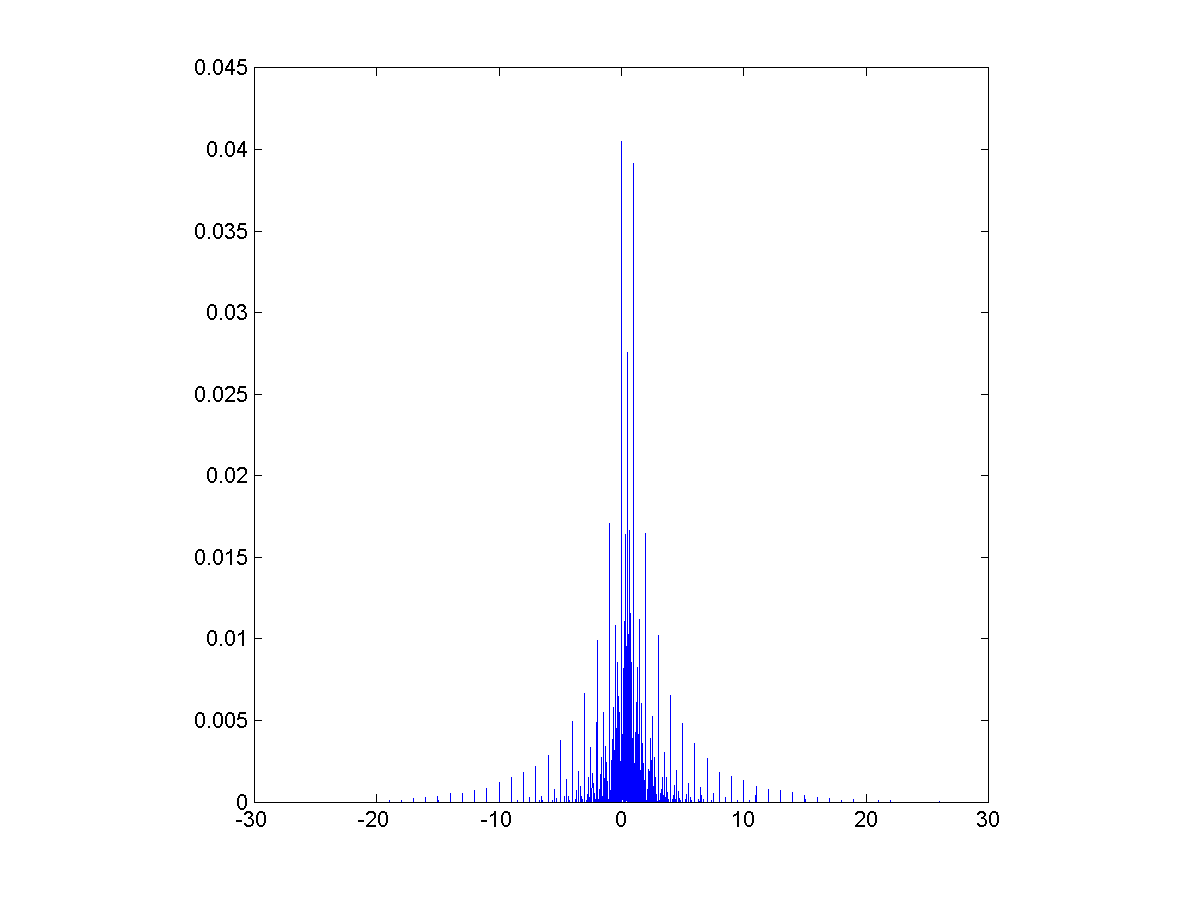
As the situation gets more deadly the correlation becomes more negative. This also happens when allowing the exponent run from the very fat (alpha=1) to the thinner (alpha=3):
(top) Correlation between observed independent power-law distributed variables (where observability requires their sum to be smaller than seven billion) for different exponents. (Bottom) fraction of trials ending in existential disaster. Multiplier=500 million.
The same thing also happens if we multiply X and Y.
I like the phenomenon: it gives us a way to look for anthropic effects by looking for suspicious anticorrelations. In particular, for the same variable the correlation ought to shift from near zero for small cases to negative for large cases. One prediction might be that periods of high superpower tension would be anticorrelated with mishaps in the nuclear weapon control systems. Of course, getting the data might be another matter. We might start by looking at extant companies with multiple risk factors like insurance companies and see if capital risk becomes anticorrelated with insurance risk at the high end.
Most of the time we encounter probability distributions over the reals, the positive reals, or integers. But one can use the rational numbers as a probability space too.
If you take positive independent integers from some distribution and generate ratios , then those ratios will have a distribution that is a convolution over the rational numbers:
One can of course do the same for non-independent and different distributions of the integers. Oh, and by the way: this whole thing has little to do with ratio distributions (alias slash distributions), which is what happens in the real case.
The authors found closed form solutions for integers distributed as a power-law with an exponential cut-off and for the uniform distribution; unfortunately the really interesting case, the Poisson distribution, doesn’t seem to have a neat closed form solution.
In the case of a uniform distributions on the set they get .
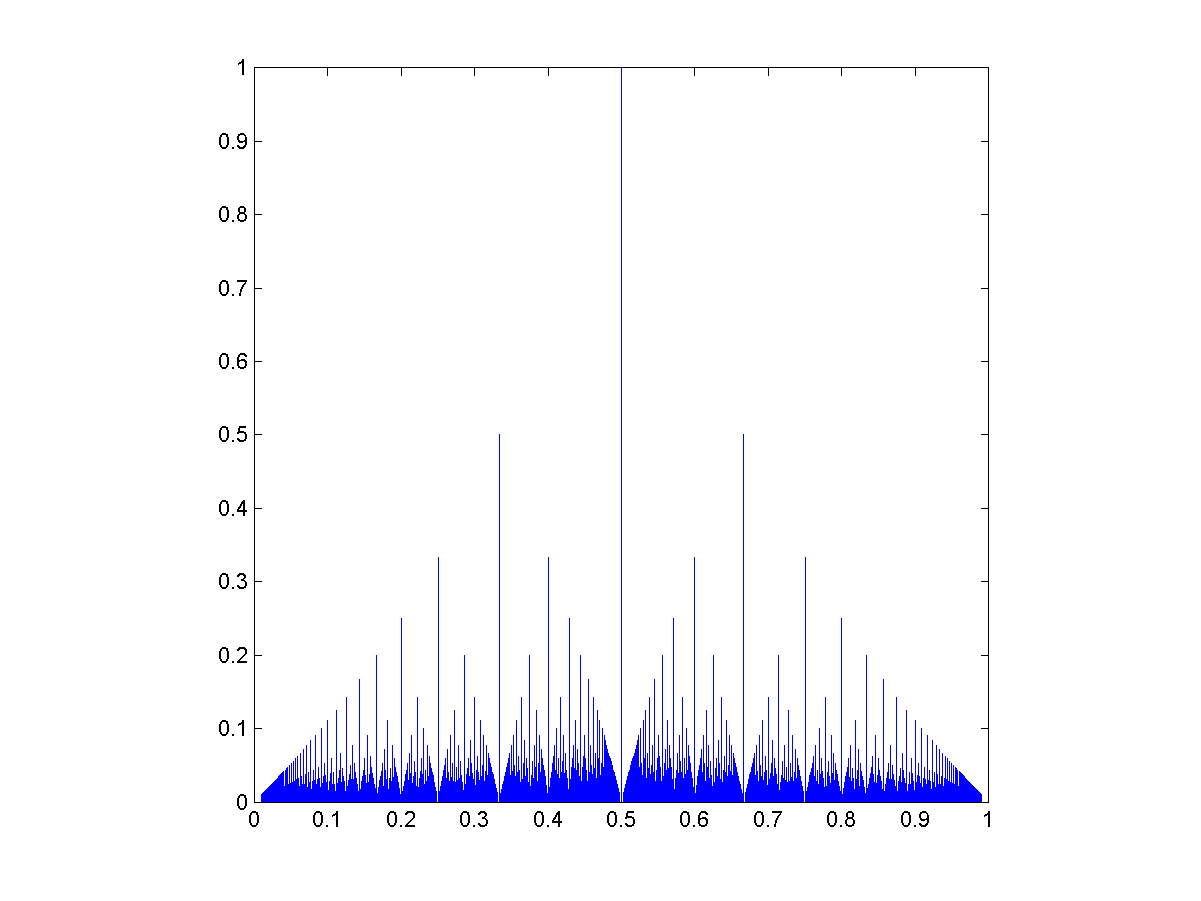
The rational distribution g(a/(a+b))=1/max(a,b) of Trifonov et al.
They note that this is similar to Thomae’s function, a somewhat well-known (and multiply named) counterexample in real analysis. That function is defined as f(p/q)=1/q (where the fraction is in lowest terms). In fact, both graphs have the same fractal dimension of 1.5.
It is easy to generate other rational distributions this way. Using a power law as an input produces a sparser pattern, since the integers going into the ratio tend to be small numbers, putting more probability at simple ratios:
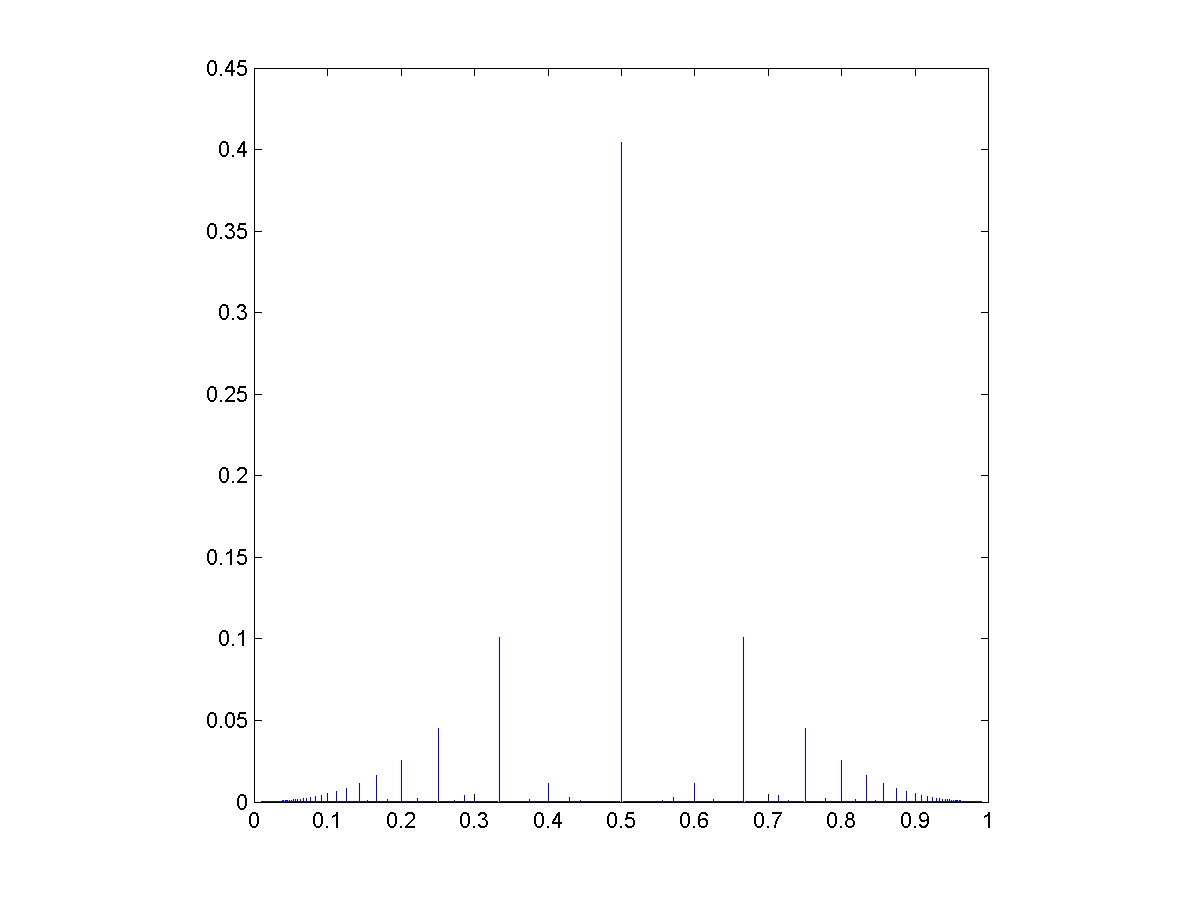
The rational distribution g(a/(a+b))=C(ab)^-2 (rational convolution of two index -2 power-law distributed integers).
If we use exponential distributions the pattern is fairly similar, but we can of course change the exponent to get something that ranges over a lot of numbers, putting more probability at nonsimple ratios where :
The rational distribution of two convolved Exp[0.1] distributions.Not everything has to be neat and symmetric. Taking the ratio of two unequal Poisson distributions can produce a rather appealing pattern:
Rational distribution of ratio between a Poisson[10] and a Poisson[5] variable.Of course, full generality would include ratios of non-positive numbers. Taking ratios of normal variates rounded to the nearest integer produces a fairly sparse distribution since high numerators or denominators are rare.
Rational distribution of a/(a+b) ratios of normal variates rounded to nearest integer.
But multiplying the variates by 10 produces a nice distribution.
Rational distribution of a/(a+b) ratios of normal variates that have been multiplied by 10 and rounded.
This approaches the Chauchy distribution as the discretisation gets finer. But note the fun microstructure (very visible in the Poisson case above too), where each peak at a simple ratio is surrounded by a “moat” of low probability. This is reminiscent of the behaviour of roots of random polynomials with integer coefficients (see also John Baez page on the topic).
The rational numbers do tend to induce a fractal recursive structure on things, since most measures on them will tend to put more mass at simple ratios than at complex ratios, but when plotting the value of the ratio everything gets neatly folded together. The lower approximability of numbers near the simple ratios produce moats. Which also suggests a question to ponder further: what role does the über-unapproximable golden ratio have in distributions like these?
In any case, there is something simultaneously ugly and exciting when neat patterns in math just ends for no apparent reason.
Another good example is the story of the Doomsday conjecture. Gwern tells the story well, based on Klarreich: a certain kind of object is found in dimension 2, 6, 14, 30 and 62… aha! They are conjectured to occur in all dimensions. A branch of math was built on this conjecture… and then the pattern failed in dimension 254. Oops.
It is a bit like the opposite case of the number of regular convex polytopes in different dimensions: 1, infinity, 5, 6, 3, 3, 3, 3… Here the series start out crazy, and then becomes very regular.
The volume of a unit sphere increases with dimension until , and then decreases. Leaving the non-intuitiveness of why volumes would shrink aside, the real oddness is that the maximum is for a non-integer dimension. We might argue that the formula is needlessly general and only the integer values count, but many derivations naturally bring in the Gamma function and hence the possibility of non-integer values.
Another association is to this integral problem: given a set of integers , is the integral ? As shown in Moore and Mertens, this is NP-complete. Here the strangeness is that integrals normally are pretty well behaved. It seems absurd that a particular not very scary trigonometric integral should require exponential work to analyze. But in fact, multivariate integrals are NP-hard to approximate, and calculating the volume of a n-dimensional polytope is actually #P-complete.
We tend to assume that mathematics is smoother and more regular than reality. Everything is regular and exceptionless because it is generated by universal rules… except when it isn’t. The rules often act as constraints, and when they do not mesh exactly odd things happen. Similarly we may assume that we know what problems are hard or not, but this is an intuition built in our own world rather than the world of mathematics. Finally, some mathematical truths maybe just are. As Gregory Chaitin has argued, some things in math are irreducible; there is no real reason (at least in the sense of a comprehensive explanation) for why they are true.
Mathematical anti-beauty can be very deep. Maybe it is like the insects, rot and other memento mori in classical still life paintings: a deviation from pleasantness and harmony that adds poignancy and a bit of drama. Or perhaps more accurately, it is wabi-sabi.
 Stuart Armstrong has come up with another twist on the anthropic shadow phenomenon. If existential risk needs two kinds of disasters to coincide in order to kill everybody, then observers will notice the disaster types to be anticorrelated.
Stuart Armstrong has come up with another twist on the anthropic shadow phenomenon. If existential risk needs two kinds of disasters to coincide in order to kill everybody, then observers will notice the disaster types to be anticorrelated.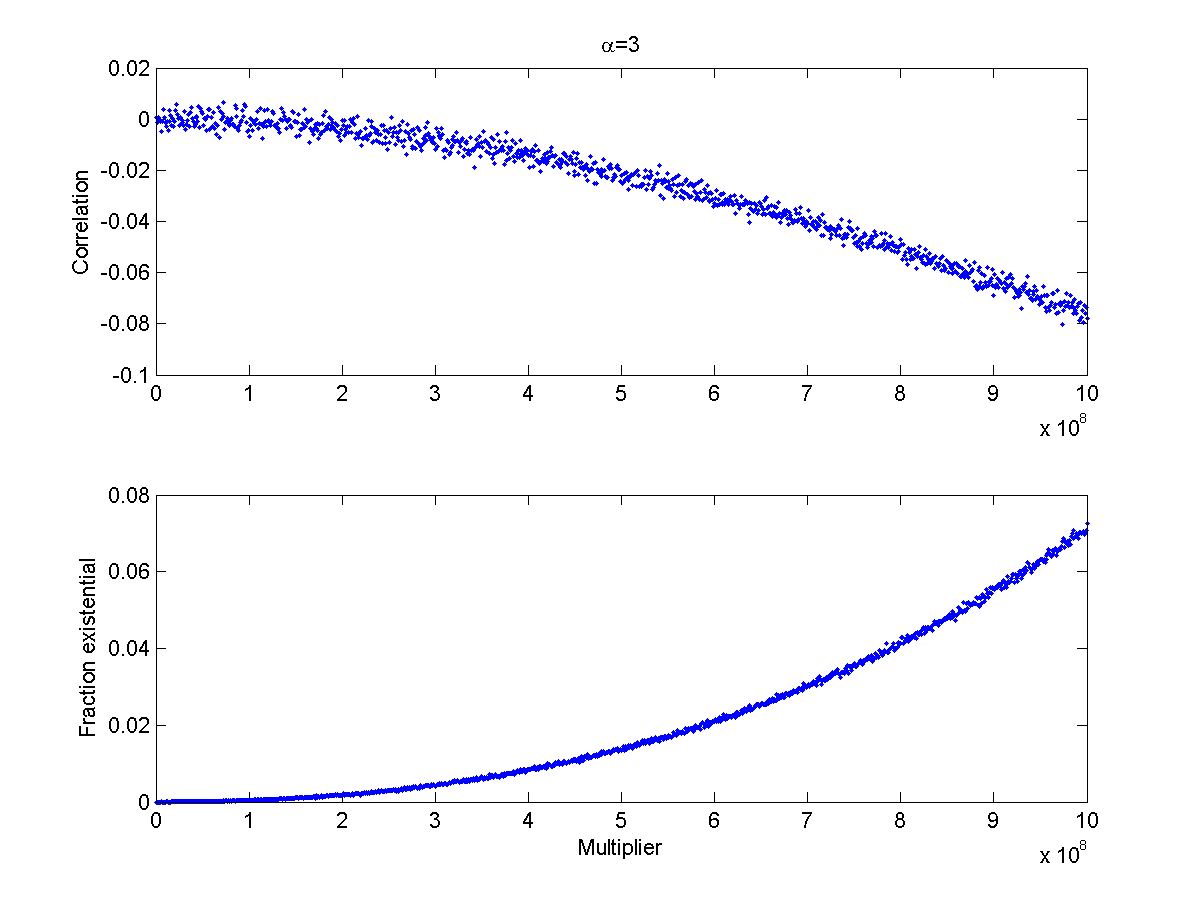

") and generate ratios
and generate ratios ") , then those ratios will have a distribution that is a convolution over the rational numbers:
, then those ratios will have a distribution that is a convolution over the rational numbers:  = g(a/(a+b)) = \sum_{m=0}^\infty \sum_{n=0}^\infty f(m) g(n) \delta \left(\frac{a}{a+b} - \frac{m}{m+n} \right ) = \sum_{t=0}^\infty f(ta)f(tb)")
 they get
they get ) = (1/L^2) \lfloor L/\max(a,b) \rfloor") .
.
 where
where  :
:![The rational distribution of two convolved Exp[0.1] distributions.](http://aleph.se/andart2/wp-content/uploads/2014/09/trifonovexp01.png)
![Rational distribution of ratio between a Poisson[10] and a Poisson[5] variable.](http://aleph.se/andart2/wp-content/uploads/2014/09/trifonovpoiss105.png)
=sin(x)/x") for
for  and defined to be 1 for
and defined to be 1 for  . It is not that uncommon as a function. Now look at the following series of integrals:
. It is not that uncommon as a function. Now look at the following series of integrals: dx = \pi/2") ,
, sinc(x/3) dx = \pi/2") ,
, sinc(x/3) sinc(x/5) dx = \pi/2") .
. sinc(x/3) sinc(x/5) \cdots sinc(x/13) dx = \pi/2") .
. sinc(x/3) sinc(x/5)")
 sinc(x/15) dx")

 – nearly a half, but not quite.
– nearly a half, but not quite. dimensions. A branch of math was built on this conjecture… and then the pattern failed in dimension 254. Oops.
dimensions. A branch of math was built on this conjecture… and then the pattern failed in dimension 254. Oops. =\frac{\pi^{n/2}r^n}{\Gamma(1+n/2)}")
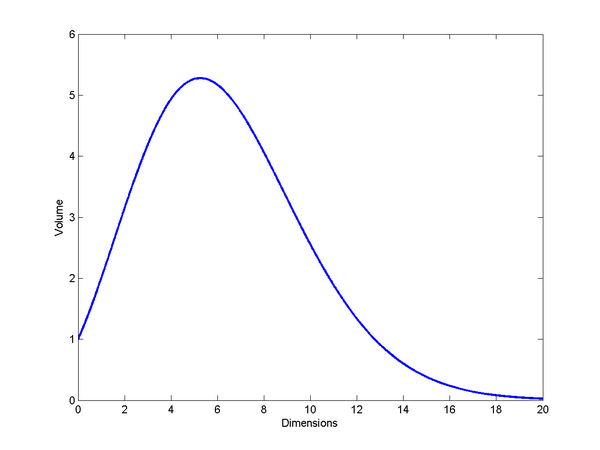
 , and then decreases. Leaving the non-intuitiveness of why volumes would shrink aside, the real oddness is that the maximum is for a non-integer dimension. We might argue that the formula is needlessly general and only the integer values count, but many derivations naturally bring in the Gamma function and hence the possibility of non-integer values.
, and then decreases. Leaving the non-intuitiveness of why volumes would shrink aside, the real oddness is that the maximum is for a non-integer dimension. We might argue that the formula is needlessly general and only the integer values count, but many derivations naturally bring in the Gamma function and hence the possibility of non-integer values. , is the integral
, is the integral  d\theta = 0") ? As shown in
? As shown in