Robin Hanson mentions that some people take him to task for working on one scenario (WBE) that might not be the most likely future scenario (“standard AI”); he responds by noting that there are perhaps 100 times more people working on standard AI than WBE scenarios, yet the probability of AI is likely not a hundred times higher than WBE. He also notes that there is a tendency for thinkers to clump onto a few popular scenarios or issues. However:
In addition, due to diminishing returns, intellectual attention to future scenarios should probably be spread out more evenly than are probabilities. The first efforts to study each scenario can pick the low hanging fruit to make faster progress. In contrast, after many have worked on a scenario for a while there is less value to be gained from the next marginal effort on that scenario.
This is very similar to my own thinking about research effort. Should we focus on things that are likely to pan out, or explore a lot of possibilities just in case one of the less obvious cases happens? Given that early progress is quick and easy, we can often get a noticeable fraction of whatever utility the topic has by just a quick dip. The effective altruist heuristic of looking at neglected fields also is based on this intuition.
A model
But under what conditions does this actually work? Here is a simple model:
There are possible scenarios, one of which () will come about. They have probability . We allocate a unit budget of effort to the scenarios: . For the scenario that comes about, we get utility (diminishing returns).
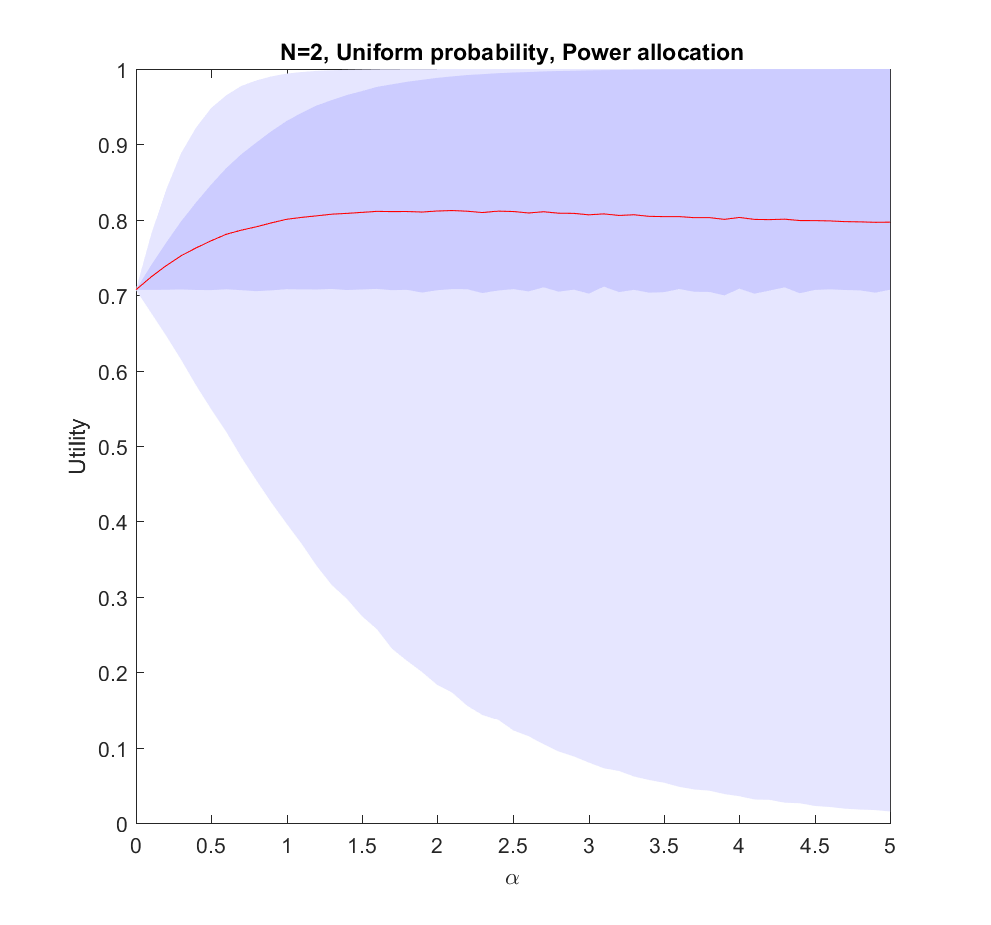
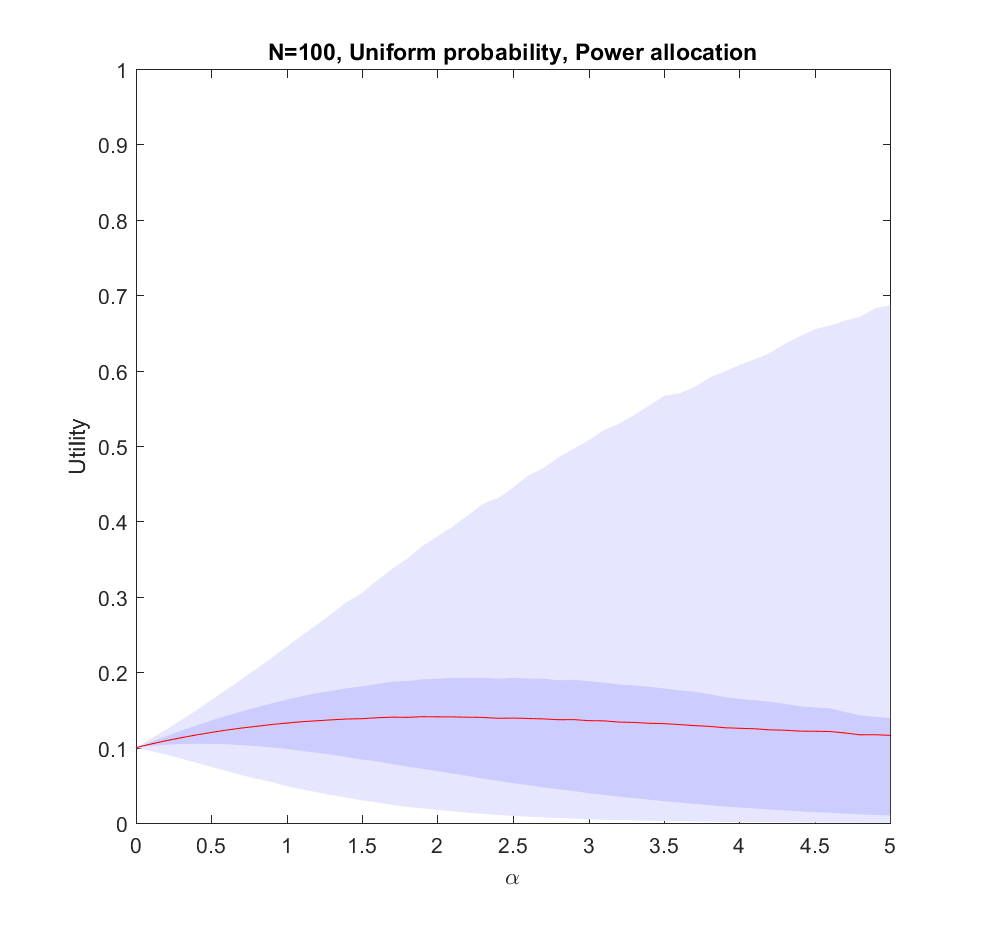
Here is what happens if we allocate proportional to a power of the scenarios, . corresponds to even allocation, 1 proportional to the likelihood, >1 to favoring the most likely scenarios. In the following I will run Monte Carlo simulations where the probabilities are randomly generated each instantiation. The outer bluish envelope represents the 95% of the outcomes, the inner ranges from the lower to the upper quartile of the utility gained, and the red line is the expected utility.
Utility of allocating effort as a power of the probability of scenarios. Red line is expected utility, deeper blue envelope is lower and upper quartiles, lighter blue 95% interval.
This is the case: we have two possible scenarios with probability and (where is uniformly distributed in [0,1]). Just allocating evenly gives us utility on average, but if we put in more effort on the more likely case we will get up to 0.8 utility. As we focus more and more on the likely case there is a corresponding increase in variance, since we may guess wrong and lose out. But 75% of the time we will do better than if we just allocated evenly. Still, allocating nearly everything to the most likely case means that one does lose out on a bit of hedging, so the expected utility declines slowly for large .
Utility of allocating effort as a power of the probability of scenarios. Red line is expected utility, deeper blue envelope is lower and upper quartiles, lighter blue 95% interval. 100 possible scenarios, with uniform probability on the simplex.
The case (where the probabilities are allocated based on a flat Dirichlet distribution) behaves similarly, but the expected utility is smaller since it is less likely that we will hit the right scenario.
What is going on?
This doesn’t seem to fit Robin’s or my intuitions at all! The best we can say about uniform allocation is that it doesn’t produce much regret: whatever happens, we will have made some allocation to the possibility. For large N this actually works out better than the directed allocation for a sizable fraction of realizations, but on average we get less utility than betting on the likely choices.
The problem with the model is of course that we actually know the probabilities before making the allocation. In reality, we do not know the likelihood of AI, WBE or alien invasions. We have some information, and we do have priors (like Robin’s view that ), but we are not able to allocate perfectly. A more plausible model would give us probability estimates instead of the actual probabilities.
We know nothing
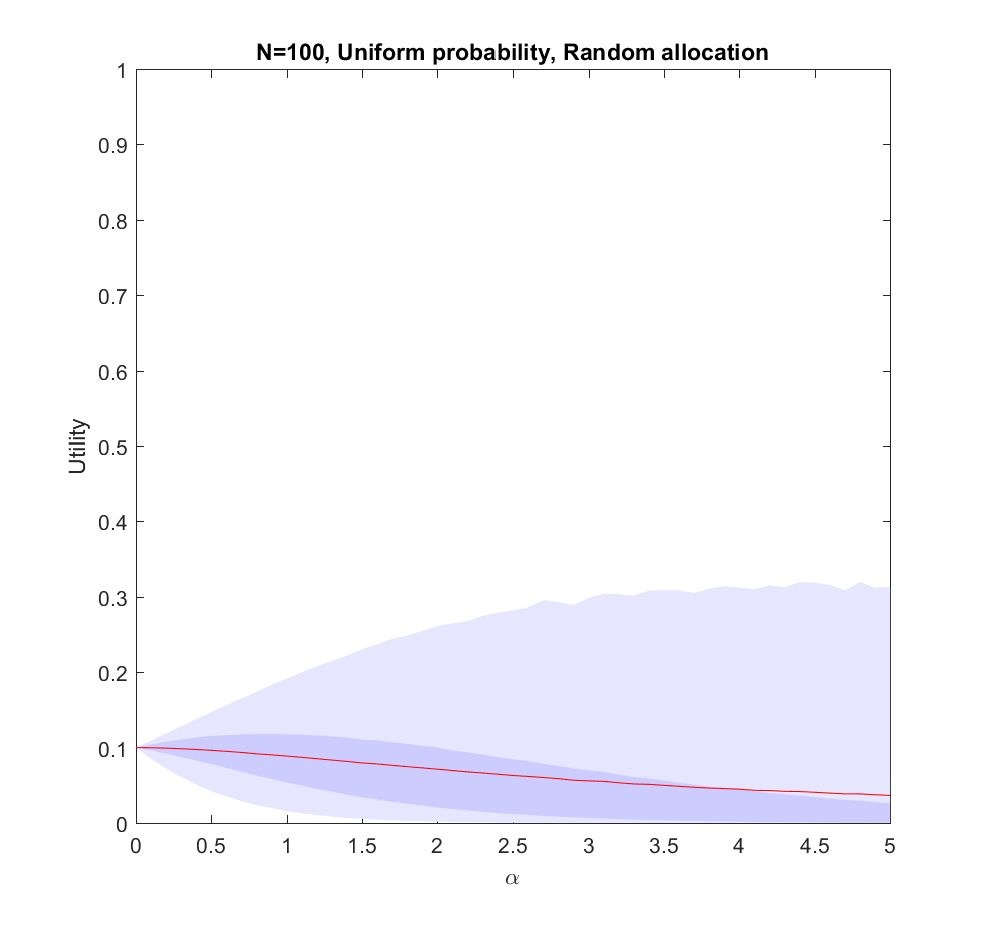
Let us start by looking at the worst possible case: we do not know what the true probabilities are at all. We can draw estimates from the same distribution – it is just that they are uncorrelated with the true situation, so they are just noise.
Utility of allocating effort as a power of the probability of scenarios, but the probabilities are just random guesses. Red line is expected utility, deeper blue envelope is lower and upper quartiles, lighter blue 95% interval. 100 possible scenarios, with uniform probability on the simplex.
In this case uniform distribution of effort is optimal. Not only does it avoid regret, it has a higher expected utility than trying to focus on a few scenarios (). The larger N is, the less likely it is that we focus on the right scenario since we know nothing. The rationality of ignoring irrelevant information is pretty obvious.
Note that if we have to allocate a minimum effort to each investigated scenario we will be forced to effectively increase our above 0. The above result gives the somewhat optimistic conclusion that the loss of utility compared to an even spread is rather mild: in the uniform case we have a pretty low amount of effort allocated to the winning scenario, so the low chance of being right in the nonuniform case is being balanced by having a slightly higher effort allocation on the selected scenarios. For high there is a tail of rare big “wins” when we hit the right scenario that drags the expected utility upwards, even though in most realizations we bet on the wrong case. This is very much the hedgehog predictor story: ocasionally they have analysed the scenario that comes about in great detail and get intensely lauded, despite looking at the wrong things most of the time.
We know a bit
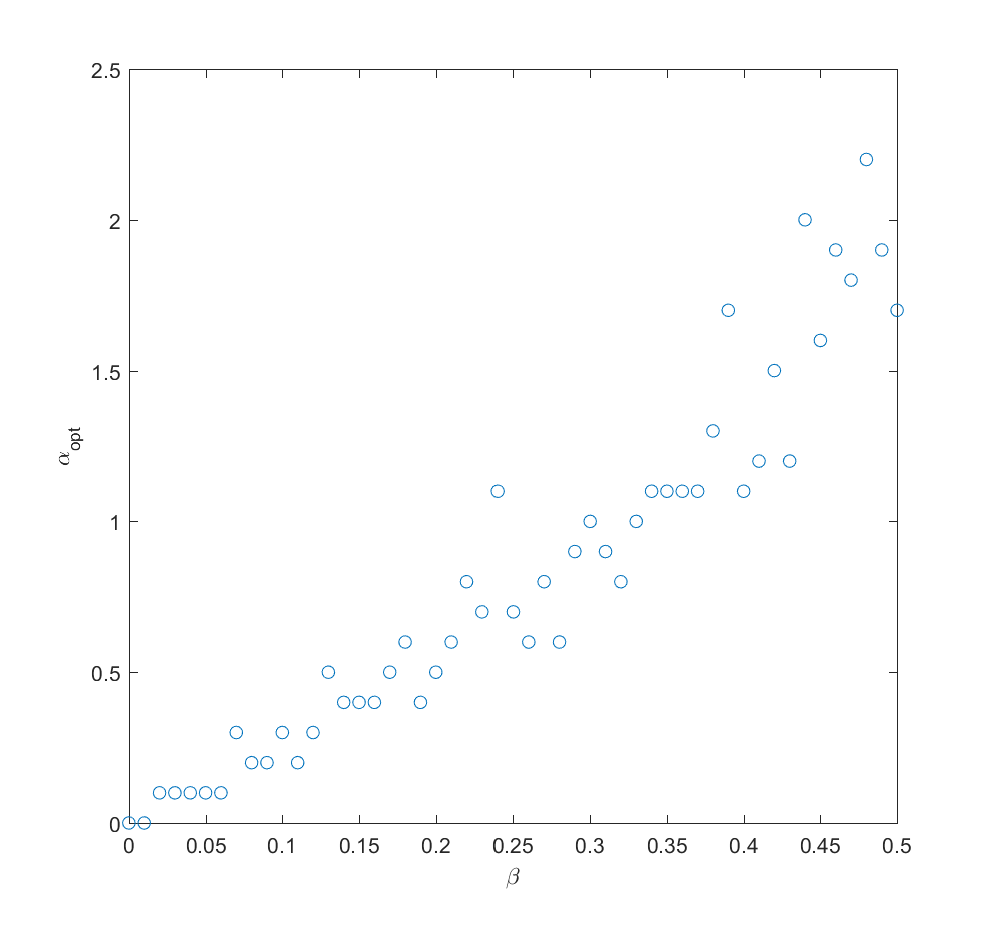
We can imagine that knowing more should allow us to gradually interpolate between the different results: the more you know, the more you should focus on the likely scenarios.
Optimal alpha as a function of how much information we have about the true probabilities (noise due to Monte Carlo and discrete steps of alpha). N=2 (N=100 looks similar).
If we take the mean of the true probabilities with some randomly drawn probabilities (the “half random” case) the curve looks quite similar to the case where we actually know the probabilities: we get a maximum for . In fact, we can mix in just a bit () of the true probability and get a fairly good guess where to allocate effort (i.e. we allocate effort as where is uncorrelated noise probabilities). The optimal alpha grows roughly linearly with , in this case.
We learn
Adding a bit of realism, we can consider a learning process: after allocating some effort to the different scenarios we get better information about the probabilities, and can now reallocate. A simple model may be that the standard deviation of noise behaves as where is the effort placed in exploring the probability of scenario . So if we begin by allocating uniformly we will have noise at reallocation of the order of . We can set , where is some constant denoting how tough it is to get information. Putting this together with the above result we get . After this exploration, now we use the remaining effort to work on the actual scenarios.
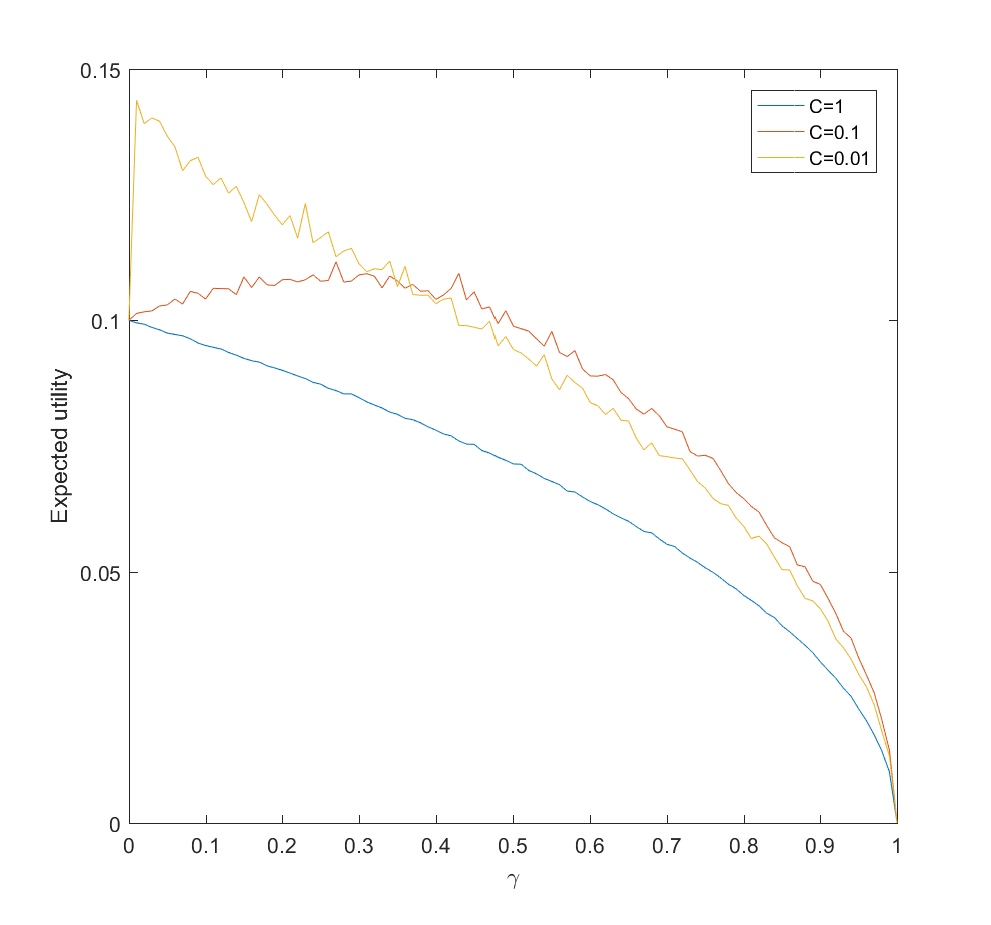
Expected utility as a function of amount of probability-estimating effort (gamma) for C=1 (hard to update probabilities), C=0.1 and C=0.01 (easy to update). N=100.
This is surprisingly inefficient. The reason is that the expected utility declines as and the gain is just the utility difference between the uniform case and optimal , which we know is pretty small. If C is small (i.e. a small amount of effort is enough to figure out the scenario probabilities) there is an optimal nonzero . This optimum decreases as C becomes smaller. If C is large, then the best approach is just to spread efforts evenly.
Conclusions
So, how should we focus? These results suggest that the key issue is knowing how little we know compared to what can be known, and how much effort it would take to know significantly more.
If there is little more that can be discovered about what scenarios are likely, because our state of knowledge is pretty good, the world is very random, or improving knowledge about what will happen will be costly, then we should roll with it and distribute effort either among likely scenarios (when we know them) or spread efforts widely (when we are in ignorance).
If we can acquire significant information about the probabilities of scenarios, then we should do it – but not overdo it. If it is very easy to get information we need to just expend some modest effort and then use the rest to flesh out our scenarios. If it is doable but costly, then we may spend a fair bit of our budget on it. But if it is hard, it is better to go directly on the object level scenario analysis as above. We should not expect the improvement to be enormous.
Here I have used a square root diminishing return model. That drives some of the flatness of the optima: had I used a logarithm function things would have been even flatter, while if the returns diminish more mildly the gains of optimal effort allocation would have been more noticeable. Clearly, understanding the diminishing returns, number of alternatives, and cost of learning probabilities better matters for setting your strategy.
In the case of future studies we know the number of scenarios are very large. We know that the returns to forecasting efforts are strongly diminishing for most kinds of forecasts. We know that extra efforts in reducing uncertainty about scenario probabilities in e.g. climate models also have strongly diminishing returns. Together this suggests that Robin is right, and it is rational to stop clustering too hard on favorite scenarios. Insofar we learn something useful from considering scenarios we should explore as many as feasible.
On practical Ethics I post about the goodness of being multi-planetary: is it rational to try to settle Mars as a hedge against existential risk?
The problem is not that it is absurd to care about existential risks or the far future (which was the Economist‘s unfortunate claim), nor that it is morally wrong to have a separate colony, but that there might be better risk reduction strategies with more bang for the buck.
One interesting aspect is that making space more accessible makes space refuges a better option. At some point in the future, even if space refuges are currently not the best choice, they may well become that. There are of course other reasons to do this too (science, business, even technological art).
So while existential risk mitigation right now might rationally aim at putting out the current brushfires and trying to set the long-term strategy right, doing the groundwork for eventual space colonisation seems to be rational.
My view is largely that moral action is strongly driven and motivated by emotions rather than reason, but outside the world of the blindingly obvious or everyday human activity our intuitions and feelings are not great guides. We do not function well morally when the numbers get too big or the cognitive biases become maladaptive. Morality may be about the heart, but ethics is in the brain.
It is a delightful little spin/parody of Searle’s original, bringing up questions of what constitutes sex, consent and relationships, and quite nicely illuminates some of the issues with technologically mediated human interaction.
This kind of prank is of course by why naive keyword-based watch lists are total failures. One prank and it gets overloaded. I would be shocked if any serious intelligence agency actually used them for real. Given that people’s Facebook likes give pretty good predictions of who they are (indeed, better than many friends know them) there are better methods if you happen to be a big intelligence agency.
Still, while text and other online behavior signal a lot about a person, it might not be a great tool for making proper watchlists since there is a lot of noise. For example, this paper extracts personality dimensions from online texts and looks at civilian mass murderers. They state:
Using this ranking procedure, it was found that all of the murderers’ texts were located within the highest ranked 33 places. It means that using only two simple measures for screening these texts, we can reduce the size of the population under inquiry to 0.013% of its original size, in order to manually identify all of the murderers’ texts.
At first, this sounds great. But for the US, that means the watchlist for being a mass murderer would currently have 41,000 entries. Given that over the past 150 years there has been about 150 mass murders in the US, this suggests that the precision is not going to be that great – most of those people are just normal people. The base rate problem crops up again and again when trying to find rare, scary people.
The deep problem is that there is not enough positive data points (the above paper used seven people) to make a reliable algorithm. The same issue cropped up with NSA’s SKYNET program – they also had seven positive examples and hundreds of thousands of negatives, and hence had massive overfitting (suggesting the Islamabad Al Jazeera bureau chief was a prime Al Qaeda suspect).
Rational watchlists
The rare positive data point problem strikes any method, no matter what it is based on. Yes, looking at the social network around people might give useful information, but if you only have a few examples of bad people the system will now pick up on networks like the ones they had. This is also true for human learning: if you look too much for people like the ones that in the past committed attacks, you will focus too much on people like them and not enemies that look different. I was told by an anti-terrorism expert about a particular sign for veterans of Afghan guerrilla warfare: great if and only if such veterans are the enemy, but rather useless if the enemy can recruit others. Even if such veterans are a sizable fraction of the enemy the base rate problem may make you spend your resources on innocent “noise” veterans if the enemy is a small group. Add confirmation bias, and trouble will follow.
Note that actually looking for a small set of people on the watchlist gets around the positive data point problem: the system can look for them and just them, and this can be made precise. The problem is not watching, but predicting who else should be watched.
The point of a watchlist is that it represents a subset of something (whether people or stocks) that merits closer scrutiny. It should essentially be an allocation of attention towards items that need higher level analysis or decision-making. The U.S. Government’s Consolidated Terrorist Watch List requires nomination from various agencies, who presumably decide based on reasonable criteria (modulo confirmation bias and mistakes). The key problem is that attention is a limited resource, so adding extra items has a cost: less attention can be spent on the rest.
This is why automatic watchlist generation is likely to be a bad idea, despite much research. Mining intelligence to help an analyst figure out if somebody might fit a profile or merit further scrutiny is likely more doable. As long as analyst time is expensive it can easily be overwhelmed if something fills the input folder: HUMINT is less likely to do it than SIGINT, even if the analyst is just doing the preliminary nomination for a watchlist.
The optimal Bayesian watchlist
One can analyse this in a Bayesian framework: assume each item has a value distributed as . The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value . Suppose a cursory investigation costing much less gives some indication about , so that it is now known with some error: . One approach is to select all items above a threshold , making .
If we imagine that everything is Gaussian , then . While one can ram through this using Owen’s useful work, here is a Monte Carlo simulation of what happens when we use (the correlation between x and y is 0.707, so this is not too much noise):
Utility of selecting items for watchlist as a function of threshold. Red curve without noise, blue with N(0,1) noise added.
Note that in this case the addition of noise forces a far higher threshold than without noise (1.22 instead of 0.31). This is just 19% of all items, while in the noise-less case 37% of items would be worth investigating. As noise becomes worse the selection for a watchlist should become stricter: a really cursory inspection should not lead to insertion unless it looks really relevant.
Here we used a mild Gaussian distribution. In term of danger, I think people or things are more likely to be lognormal distributed since it is a product of many relatively independent factors. Using lognormal x and y leads to a situation where there is a maximum utility for some threshold. This is likely a problematic model, but clearly the shape of the distributions matter a lot for where the threshold should be.
Note that having huge resources can be a bane: if you build your watchlist from the top priority down as long as you have budget or manpower, the lower priority (but still above threshold!) entries will be more likely to be a waste of time and effort. The average utility will decline.
Predictive validity matters more?
In any case, a cursory and cheap decision process is going to give so many so-so evaluations that one shouldn’t build the watchlist on it. Instead one should aim for a series of filters of increasing sophistication (and cost) to wash out the relevant items from the dross.
We find that when searching for rare positives (e.g., candidates that will successfully complete clinical development), changes in the predictive validity of screening and disease models that many people working in drug discovery would regard as small and/or unknowable (i.e., an 0.1 absolute change in correlation coefficient between model output and clinical outcomes in man) can offset large (e.g., 10 fold, even 100 fold) changes in models’ brute-force efficiency.
Just like for drugs (an example where the watchlist is a set of candidate compounds), it might be more important for terrorist watchlists to aim for signs with predictive power of being a bad guy, rather than being correlated with being a bad guy. Otherwise anti-terrorism will suffer the same problem of declining productivity, despite ever more sophisticated algorithms.
I recently nerded out about high-energy proton interaction with matter, enjoying reading up on the Bethe equation at the Particle Data Group review and elsewhere. That got me to look around at the PDL website, which is full of awesome stuff – everything from math and physics reviews to data for the most obscure “particles” ever, plus tests of how conserved the conservation laws are.
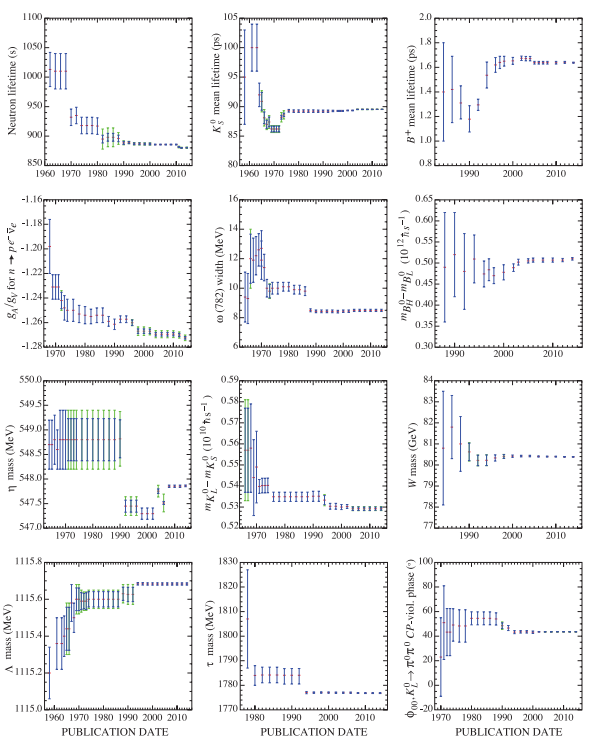
Historical graph of physical constant estimates from K.A. Olive et al. (Particle Data Group), Chin. Phys. C, 38, 090001 (2014) and 2015 update.
The first thing that strikes the viewer is that they have moved a fair bit, including often being far outside the original error bars. 6 of them have escaped them. That doesn’t look very good for science!
Fortunately, it turns out that these error bars are not 95% confidence intervals (the most common form in many branches of science) but 68.3% confidence intervals (one standard deviation, if things are normal). That means having half of them out of range is entirely reasonable! On the other hand, most researchers don’t understand error bars (original paper), and we should be able to do much better.
Sometimes large changes occur. These usually reflect the introduction of significant new data or the discarding of older data. Older data are discarded in favor of newer data when it is felt that the newer data have smaller systematic errors, or have more checks on systematic errors, or have made corrections unknown at the time of the older experiments, or simply have much smaller errors. Sometimes, the scale factor becomes large near the time at which a large jump takes place, reflecting the uncertainty introduced by the new and inconsistent data. By and large, however, a full scan of our history plots shows a dull progression toward greater precision at central values quite consistent with the first data points shown.
Overall, kudos to PDG for showing the history and making it clearer what is going on! But I do not agree it is a dull progression.
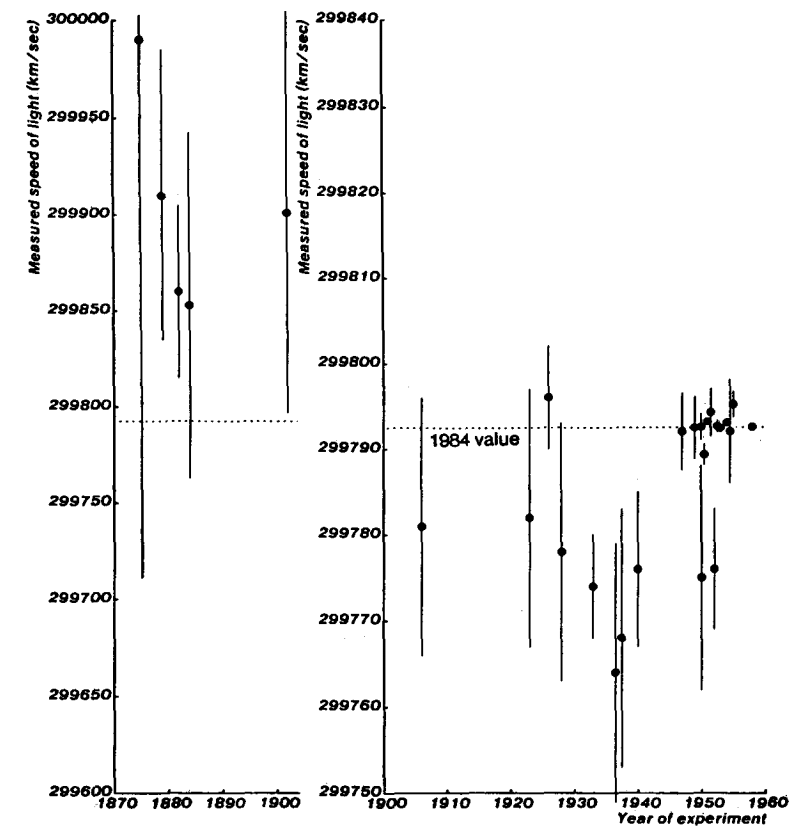
Plot of light-speed measurements 1875-1958. Error bars are standard error. From Max Henrion and Baruch Fischhoff. Assessing uncertainty in physical constants. American Journal of Physics 54, 791 (1986); doi: 10.1119/1.14447.
Note that the shifts were far larger than the estimated error bars. The dip in the 1930s and 40s even made some physicists propose that c could be changing over time. Overall Henrion and Fischhoff find that physicists have been rather overconfident in their tight error bounds on their measurements. The approach towards current estimates is anything but dull, and hides many amusing historical anecdotes.
Stories like this might have been helpful; it is notable that the PDG histories on the right, for newer constants, seem to stay closer to the present value than the longer ones to the left. Maybe this is just because they have not had the time to veer off yet, but one can be hopeful.
Still, even if people are improving this might not mean the conclusions stay stable or approach truth monotonically. A related issue is “negative learning”, where more data and improved models make the consensus view of a topic move in the wrong direction: Oppenheimer, M., O’Neill, B. C., & Webster, M. (2008). Negative learning. Climatic Change, 89(1-2), 155-172. Here the problem is not just that people are overconfident in how certain they can be about their conclusions, but also that there is a bit of group-think, plus that the models change in structure and are affected in different ways by the same data. They point out how estimates of ozone depletion oscillated, or the consensus on the stability of climate has shifted from oscillatory (before 1968) towards instability (68-82), towards stability (82-96), and now towards instability again (96-06). These problems are not due to mere irrationality, but the fact that as we learn more and build better models these incomplete but better models may still deviate strongly from the ground truth because they miss some key component.
Noli fumare
This is related to what Nick Bostrom calls the “data fumes” problem. Early data will be fragmentary and explanations uncertain – but the data points and their patterns are very salient, just as the early models, since there is nothing else. So we begin to anchor on them. Then new data arrives and the models improve… and the old patterns are revealed as statistical noise, or bugs in the simulation or plotting routine. But since we anchored on them, we are unlikely to update as strongly towards the new most likely estimates. Worse, accommodating a new model takes mental work; our status quo bias will be pushing against the update. Even if we do accommodate the new state, things will likely change more – we may well end up either with a view anchored on early noise, or assume that the final state is far more uncertain than it actually is (since we weigh the early jumps strongly because of their saliency).
This is of course why most people prefer to believe a charismatic diet cultleader expert rather than trying to dig through 70 years of messy, conflicting dietary epidemiology.
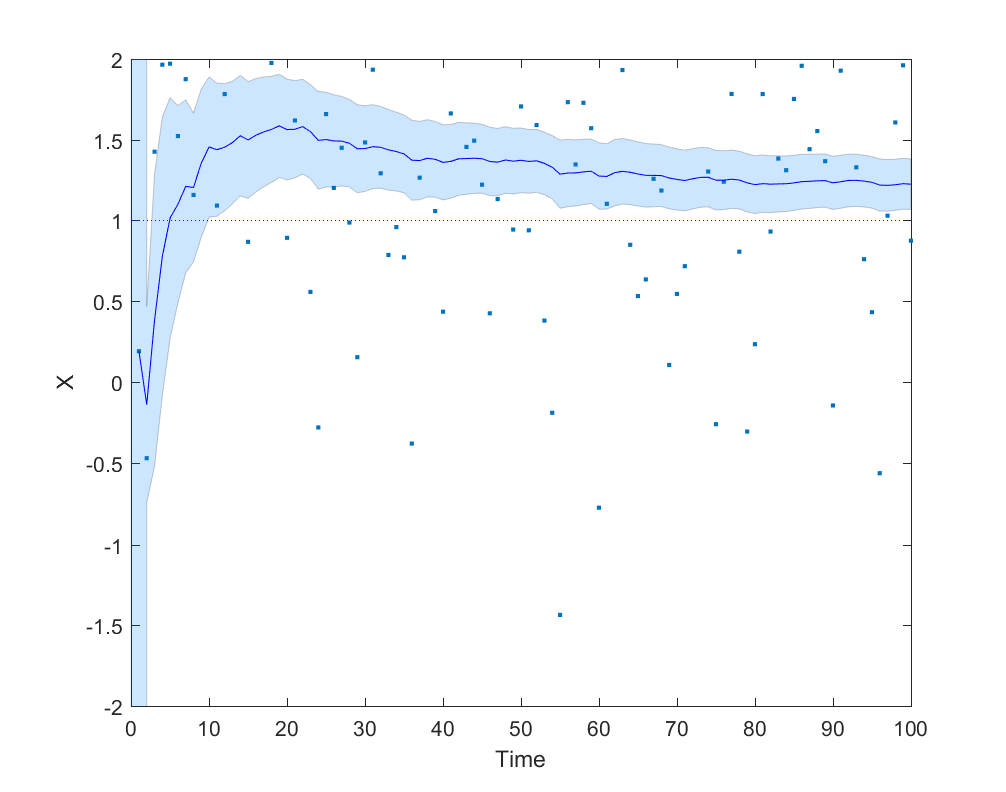
Here is a simple example where an agent is trying to do a maximum likelihood estimation of a Gaussian distribution with mean 1 and variance 1, but is hamstrung by giving double weight to the first 9 data points:
Simple data fume model, showing the slow and biased convergence when the first 9 data points are over-weighted. The blue area is a 95% confidence interval for the mean of the generating Gaussian distribution.
It is not hard to complicate the model with anchoring/recency/status quo bias (estimates get biased towards previous estimates), or that early data points are more polluted by differently distributed noise. Asymmetric error checking (you will look for bugs if results deviate from expectation and hence often find such bugs, but not look for bugs making your results closer to expectation) is another obvious factor for how data fumes can get integrated in models.
The problem with data fumes is that it is not easy to tell when you have stabilized enough to start trusting the data. It is even messier when the inputs are results generated by your own models or code. I like to approach it by using multiple models to guesstimate model error: for example, one mathematical model on paper and one Monte Carlo simulation – if they don’t agree, then I should disregard either answer and keep on improving.
Even when everything seems to be fine there may be a big crucial consideration one has missed. The Turing-Good estimator gives another way of estimating the risk of that: if you have acquired data points and seen big surprises (remember that the first data point counts as one!), then the probability of a new surprise for your next data point is . So if you expect data points in total, when you can start to trust the estimates… assuming surprises are uncorrelated etc. Which you will not be certain about. The progression towards greater precision may be anything but dull.
In Scott Alexander’s kabbalistic sf story Unsong, the archangel Uriel works on a problem while other things are going on in heaven:
All the angels listened in rapt attention except Uriel, who was sort of half-paying attention while trying to balance several twelve-dimensional shapes on top of each other.
…
There was utter silence throughout the halls of Heaven, except a brief curse as Uriel’s hyperdimensional tower collapsed on itself and he picked up the pieces to try to rebuild it.
…
A great clamor arose from all the heavenly hosts, save Uriel, who took advantage of the brief lapse to conjure a parchment and pen and start working on a proof about the optimal configuration of twelve-dimensional shapes.
This got me thinking about the stability of stacking polytopes. That seemed complicated (I am no archangel) so I started toying with the stability of polytopes on a flat surface.
(Terminology note: I will consistently use “face” to denote the D-1 dimensional elements that bound the polytope, although “facet” is in some use.)
A face of a 3D polyhedron is stable if the polyhedron can rest on it without tipping over. This means that the projection of the center of mass onto the plane containing the face is inside the polygon. The platonic polyhedra are stable on all faces, but it is not hard to make a few faces unstable by moving a vertex far away from the center. A polyhedron has at least one stable face (if it did not, it would be a perpetual motion device: every tip will move the center of mass downwards, but there is a bound on how low it can go. A uni-stable or monostatic polyhedron has just one stable face. It is an unsolved problem what the simplest uni-stable 3D polyhedron is, with the current record 14 faces. Also, it seems unclear whether there are monostatic simplices in dimension 9 (they exist in 10 or more dimensions, but not in 8 or fewer).
So, how many faces of a polytope will typically be unstable?
I wrote a Matlab script to generate random convex polytopes by selecting N points randomly on the surface of a D-dimensional sphere and calculating their convex hull. Using a Delaunay decomposition I can split them into simplices, which allow me to calculate the center of mass. The center of mass of a simplex is just the average of the corners , and the center of mass of the polyhedron is just the sum of the simplex centers of mass weighted by their volumes: . The volume of a simplex is where , the matrix made by sticking together the coordinate vectors of a simplex. Once we know this we can project the center of mass onto the plane of a face by finding its nullspace (the higher dimensional counterpart to a normal) . Finally, to check whether the projection is inside the face, we can look at the matrix A where each column is the coordinates of one of the faces minus and the final row just ones, and solve for Ax=b where b is zero except for a one in the last row (I found this neat algorithm due to elisbben on stack overflow). If the answer vector is all positive, then the point is inside the face. Repeat for all the faces.
Whew. This math is of course really simple to do in Matlab.
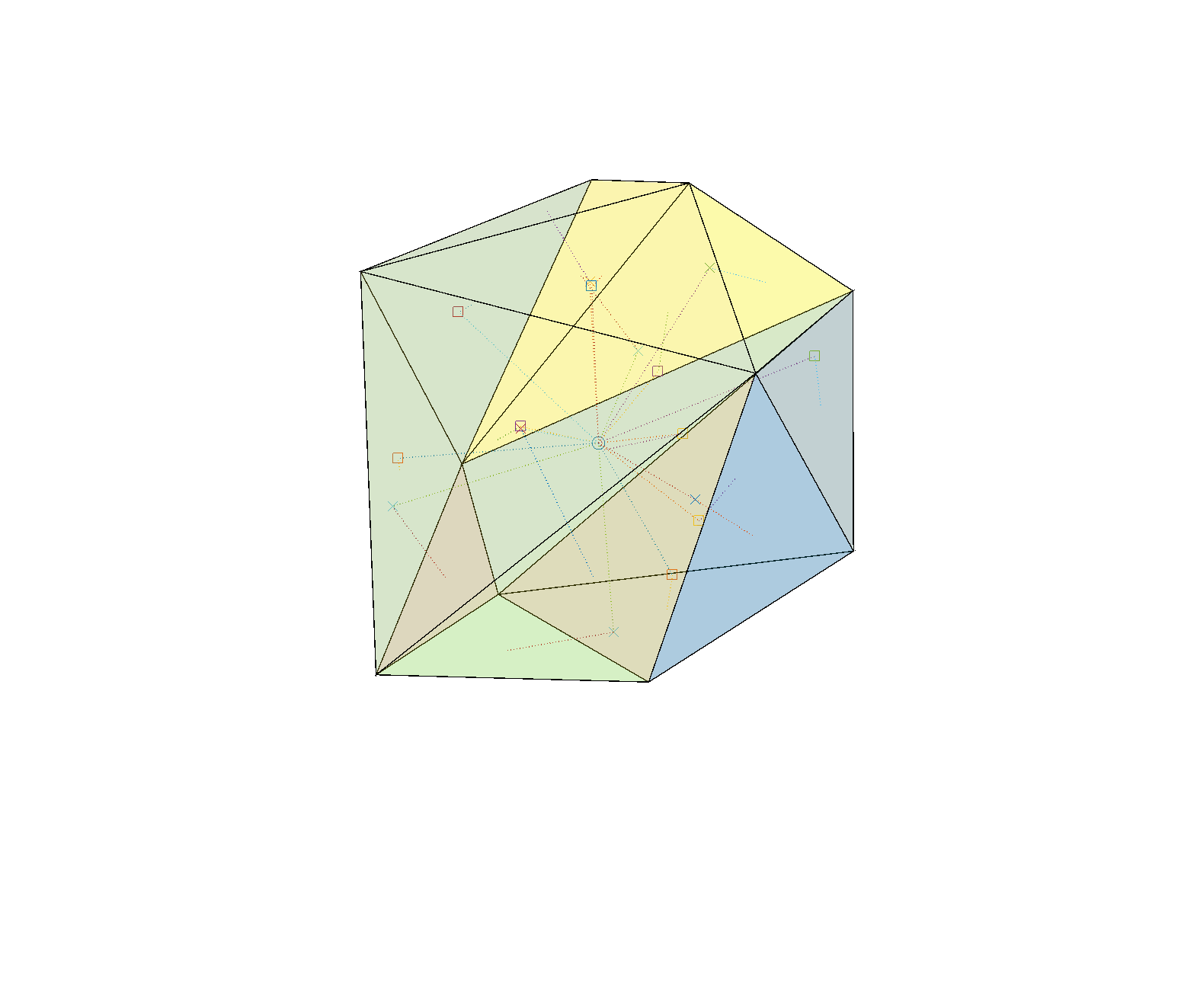
Stable (yellow) and unstable (blue) faces of random polyhedron.Stability of random polyhedron. The center of mass is marked by a circle. It is projected along the dotted lines into the plane of each face, marked with a square (if inside the face and hence a stable face) or a cross (if outside the face, which is hence unstable). A dotted line connects the projection points to the center of their face.
The 12 dimensional case is a bit messier:
Projection of a 12D polytope with 20 vertices. Each of the 2777 faces is a 11 dimensional simplex.
So, what is the average fraction of stable faces on a 3D polyhedron?
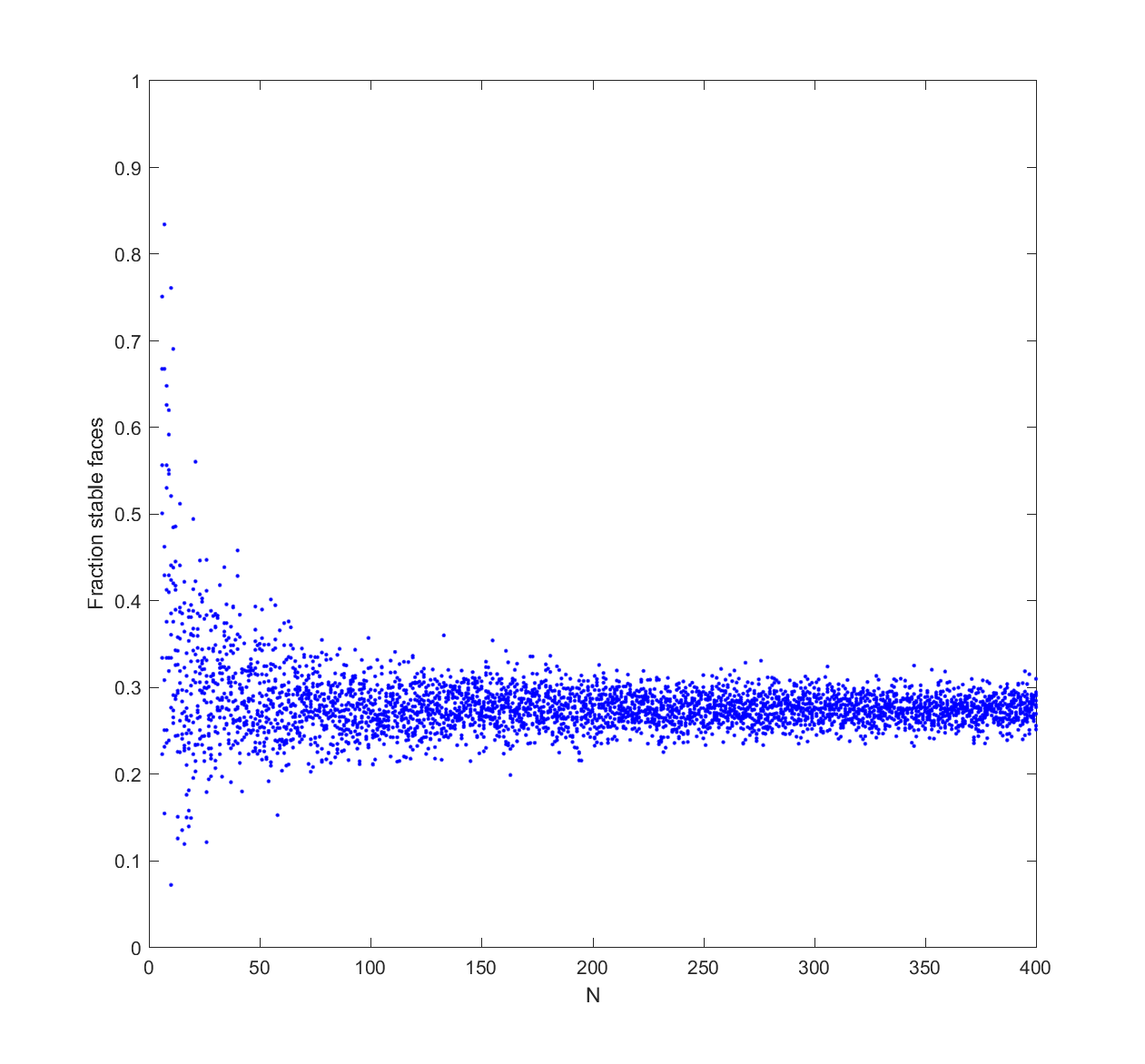
Fraction stable faces on 3D convex hulls of N points on a sphere.
It tends to converge to 50%. Doing this in higher dimensions shows the same kind of convergence, although to lower fractions.
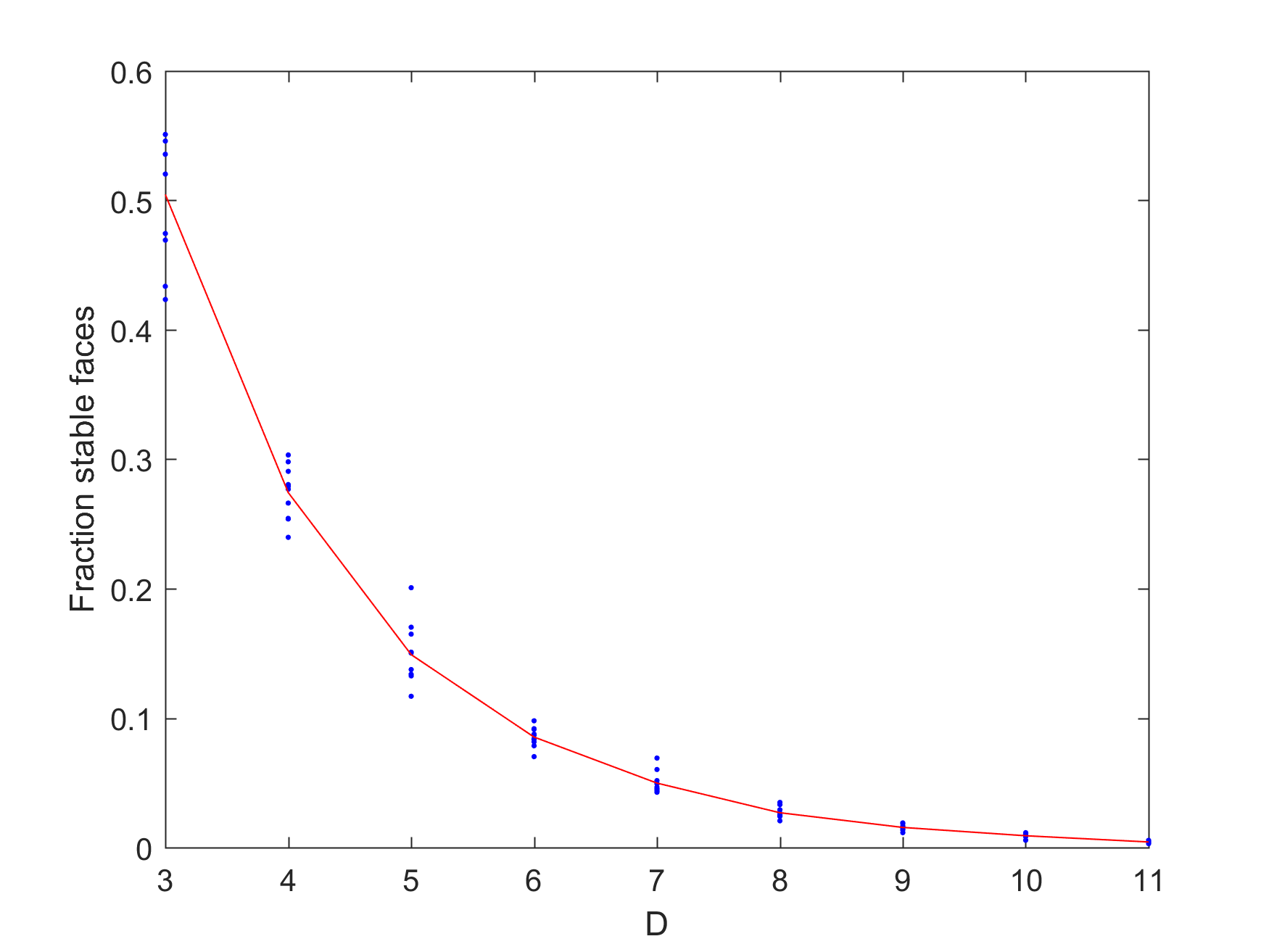
Fraction stable faces on 4D convex hulls of N points on a sphere.Fraction stable faces of N=100 convex hulls in different dimensions. Red line exponential fit.
It looks like the fraction of stable faces declines exponentially with dimensionality.
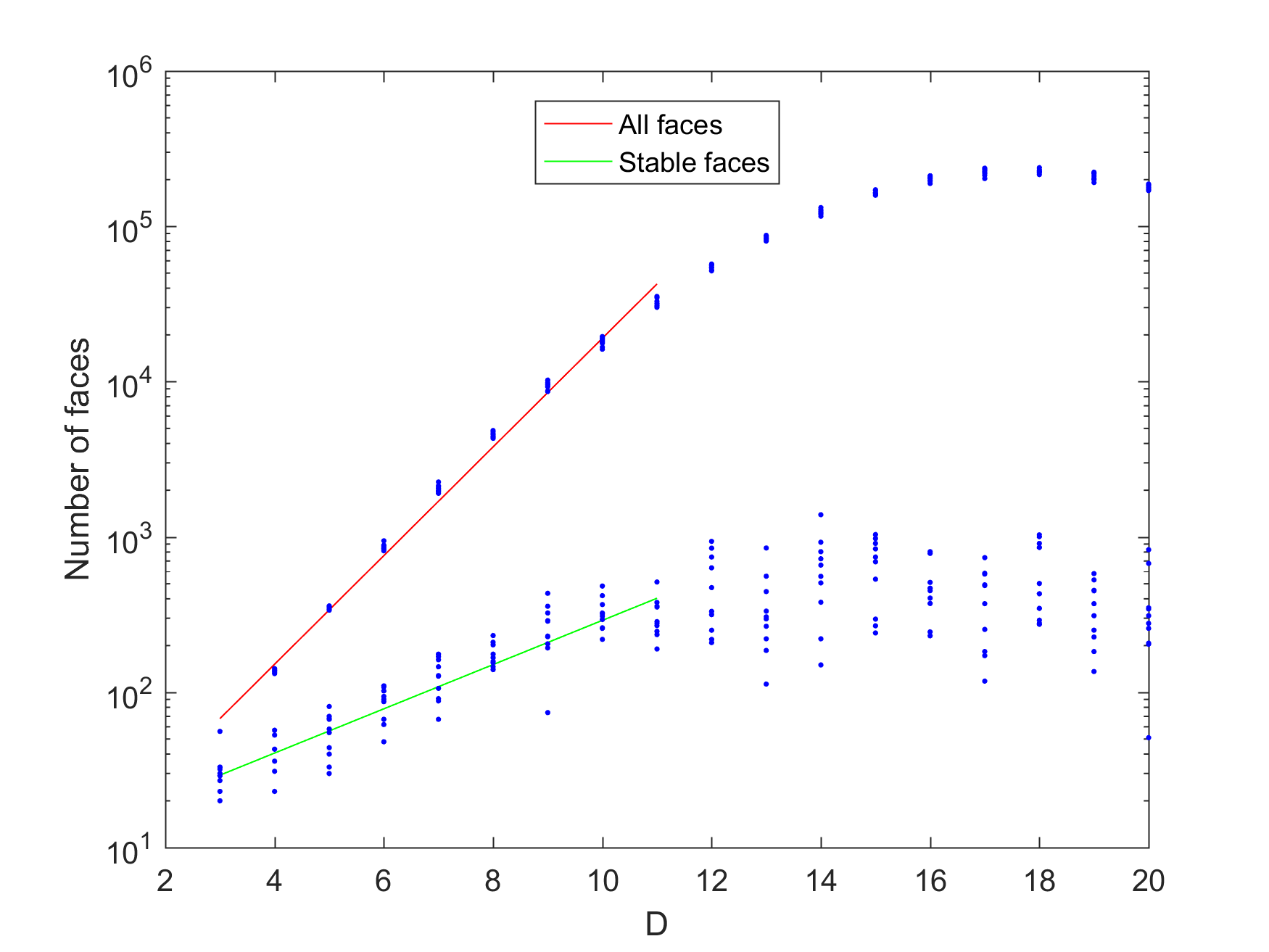
Does this mean that for a sufficiently high dimension it is likely that a random polytope is unistable? The answer is no: the number of faces increases pretty exponentially (as ), but the number of stable faces also increases exponentially with D (as $latex 2^{0.9273 D}$).
Combined plot of number of faces (points with red line) and stable faces (points with green line) as a function of dimension for N=100.
This was based on runs with N=100. Obviously things go much faster if you select a lower N, such as 30. However, as you approach N=D the polytopes become more and more simplex-like, and simplices tend to both have fewer faces and be less stable in high dimensions, so the exponential growth stops. This actually happens far below D; for N=30 the effect is felt already in 11 dimensions. The face growth rates were also lower, with coefficients 1.1621 and 0.4730.
Number of faces and stable faces for N=30 random convex hulls in different dimensions.
(There are some asymptotic formulas known for the growth of the number of faces for random convex hulls; they grow linearly with N but at an accelerating rate with D.)
Stuart Armstrong gave me a very heuristic argument for why there would be so many unstable faces. Consider building up the polytope vertex by vertex, essentially just adding together the simplices from the Delaunay decomposition. If you start from a stable state, eventually you will likely end up with an unstable face. Adding the next vertex will add a simplex to the polyhedron, and the center of mass will move in the direction of the new simplex. To have the face become stable again the shift in center of mass needs to be large enough along the directions parallel to the face to bring the projection back inside the face. But in high dimensional spaces there are many directions you can move in: the probability of a random vector being nearly parallel to another vector is very low. Hence, the next step and the following are likely to preserve the instability. So high dimensional polytopes are likely to have many unstable faces even if they are nicely inscribed in spheres.
The number of steps the polytope rolls over until finding a stable face is also limited: the “drainage basin” of a stable face is a tree, with a branching degree set by D-1 (if faces are D-simplexes). So the number of steps will scale as . Even high-dimensional polytopes will stop flipping quickly in general. (A unistable polytope on the other hand can run through at least half of its faces, so there are some very slow ones too).
The expected minimum distance between two points on this kind of random polytope scales as (if they were optimally distributed it would be ). At the same time, if N is relatively small compared to D (the polytope is simplex-like), the average diameter (the longest edge) of each face seems to approach . Why? I think this is because , the mean of a flipped k=2 Weibull distribution that shows up because of extreme value theory. Meanwhile the average and median cord length between random points on hyperspheres tends towards . Faces hence tends to be fairly wide unless N is large compared to D, but there will typically always be a few very narrow ones that are tricky to balance on.
Stacking no-slip polytopes
What about stacking polytopes?
If you put a polytope on top of another one (assuming no slipping) at first it seems you need to use a stable face of the top polytope, but this is not enough nor necessary.
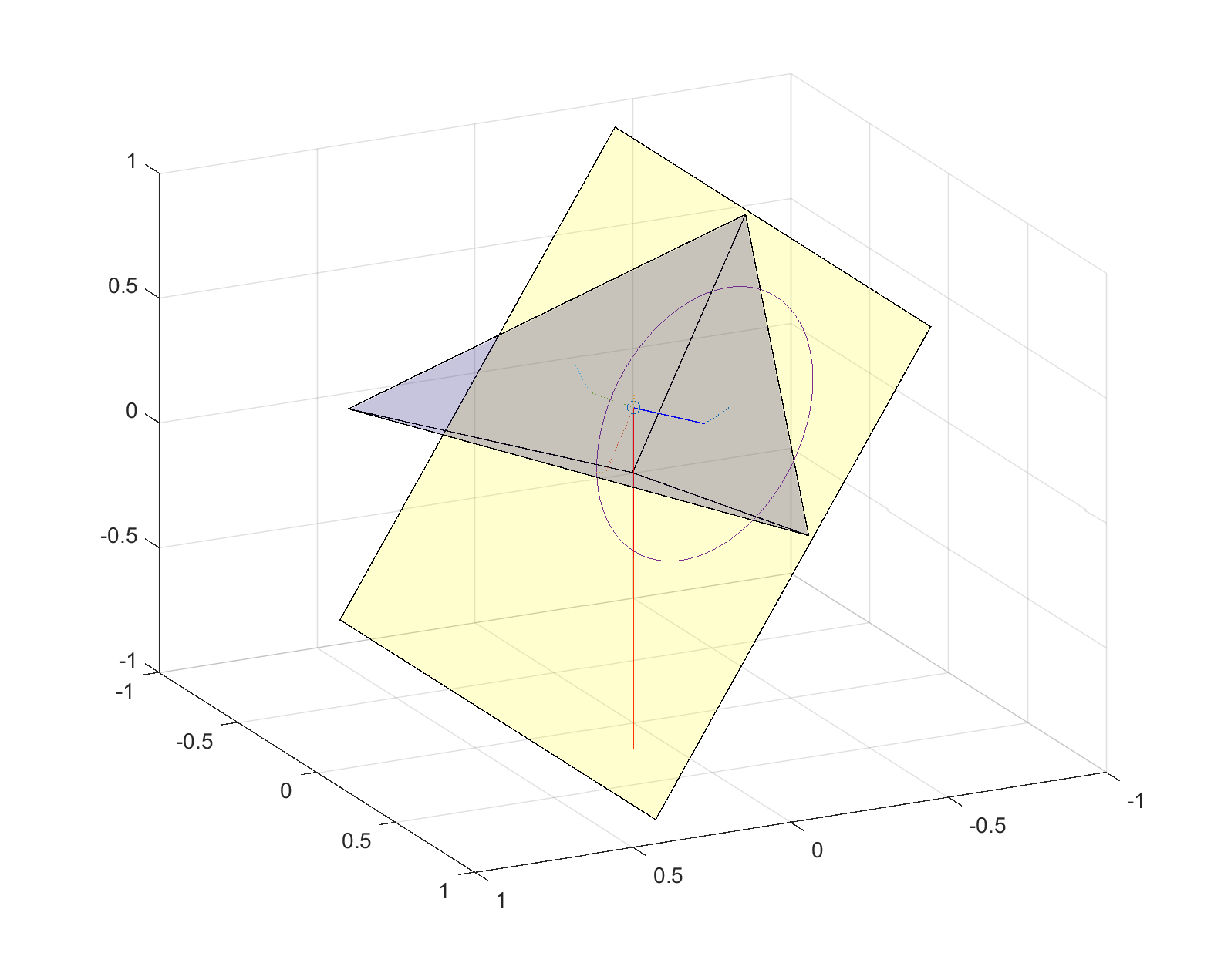
Since the underlying face is likely tilted from the horizontal, the vertical projection of the center of mass has to be within the top face. The upper polytope can be rotated, moving the projection point. The tilt angle (or rather, tilt angles – we are doing this in higher dimensions, remember?) generates a hypersphere of radius around the normal projection point (which is at distance d from the center of mass) where the vertical projection can intersect the face. Only parts of the hypersphere surface that are inside the face represent orientations that are stable. Even an unstable face can (sometimes) be stabilized if you turn it so that the tilted projection is inside, but for sufficiently high angles the hypersphere will be bigger than the face and it cannot be stable.
Stability of polyhedron on tilted surface. The line of gravity from the center of mass intersects the inside the bottom face, so the polyhedron is resting stably. Turning the polyhedron will move the line to some point on the circle, but since all points on the circle are inside the face all orientations are stable.Stability of polyhedron on tilted surface. The line of gravity from the center of mass intersects the outside the bottom face, so the polyhedron is unstable and will flip over. Turning the polyhedron will move the line to some other point on the circle: since some points on the circle are inside the face there are some orientations that are stable.
Having the top polytope stay in place is the first requirement. The second is that the bottom polytope should not become unstable. The new center of mass is moved to a point somewhere along the connecting line between the individual centers of mass of the polytopes, with exact position dependent on their volume ratio (note that turning the top polytope can move the center of mass too). This moves the projection point along the plane of the bottom face, and if it gets outside that face the assembly will tip over.
One can imagine this as adding random (D-1)-dimensional vectors of length 1/N until they reach the edge of the face. I am a bit uncertain about the properties of such random walks (all works on decreasing step size walks I have seen have been in 1D). The harmonic random walk in 1D apparently converges with probability 1, so I think the (D-1)-dimensional one also does it since the distance from the origin to the walker will be smaller than if the walker just kept to a 1D line. Since the expected distance traversed in 1D is $latex E[|X|] \approx 1.0761$ this is actually not a very extreme shift. Given the surprisingly large diameters of the faces if the first condition might be tougher to meet than the second, but this is just a guess.
The no slipping constraint is important. If the polytopes are frictionless, then any transverse force will move them. Hence only polytopes that have some parallel top and bottom stable faces can be stacked, and the problem becomes simpler. There are still surprises there, though: even stacks of rectangular blocks can do surprising things. The block stacking problem also demonstrates that one can have 1/N overhangs (counting downwards), enabling arbitrarily large total overhangs without tipping over. With polytopes with shapes that act as counterweights the overhangs can be even larger.
Uriel’s stacking problems
This leads to what we might call “Uriel’s stacking problem”: given a collection of no-slip convex D-dimensional polytopes, what is the tallest tower that can be constructed from them?
I suspect that this problem is NP-hard. It sounds very much like a knapsack problem, but there is a dependency on previous steps when you add a new polytope that seem to make it harder. It seems that it would not be too difficult to fool a greedy algorithm just trying to put the next polytope on the most topmost face into adding one that makes subsequent steps too unstable, forcing backtracking.
Another related problem: if the polytopes are random convex hulls of N points, what is the distribution of maximum tower heights? What if we just try random stacking?
And finally, what is the maximum overhang that can be done by stacking polytopes from a given set?
Were robots thinking, moral beings liability would be easy: they would presumably be legal subjects and handled like humans and corporations. But now they have an uneasy position as legal objects yet endowed with the ability to perform complex actions on behalf of others, or with emergent behaviors nobody can predict. The challenge may be to design not just the robots or laws, but robots and laws that fit each other (and real social practices): social robotics.
But it is early days. It is actually hard to tell where robotics will truly shine or matter legally, and premature laws can stifle innovation. We also do not really know what principles we ought to use to underpin the social robotics – more research is needed. And if you thought AI safety was hard, now consider getting machines to fit into the even less well defined human social landscape.

















Q_i)^\alpha")







=\sqrt{\gamma/N}/C")

=\sqrt{2\gamma/NC^2}")





 distributed as
distributed as ") . The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value
. The goal of the watchlist is to spend expensive investigatory resources to figure out the true values; say the cost is 1 per item. Then a watchlist of randomly selected items will have a mean value ![V=E[x]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x]-1") . Suppose a cursory investigation costing much less gives some indication about
. Suppose a cursory investigation costing much less gives some indication about  . One approach is to select all items above a threshold
. One approach is to select all items above a threshold  , making
, making ![V=E[x_i|y_i<\theta]-1](http://s0.wp.com/latex.php?latex=V%3DE%5Bx_i%7Cy_i%3C%5Ctheta%5D-1&bg=ffffff&fg=000000&s=0 "V=E[x_i|y_i<\theta]-1") .
., \epsilon \sim N(0,\sigma_\epsilon^2)") , then
, then  \Phi\left(\frac{t-\mu_x}{\sqrt{\sigma_x^2+\sigma_\epsilon^2}}\right)dt") . While one can ram through this using
. While one can ram through this using  (the correlation between x and y is 0.707, so this is not too much noise):
(the correlation between x and y is 0.707, so this is not too much noise):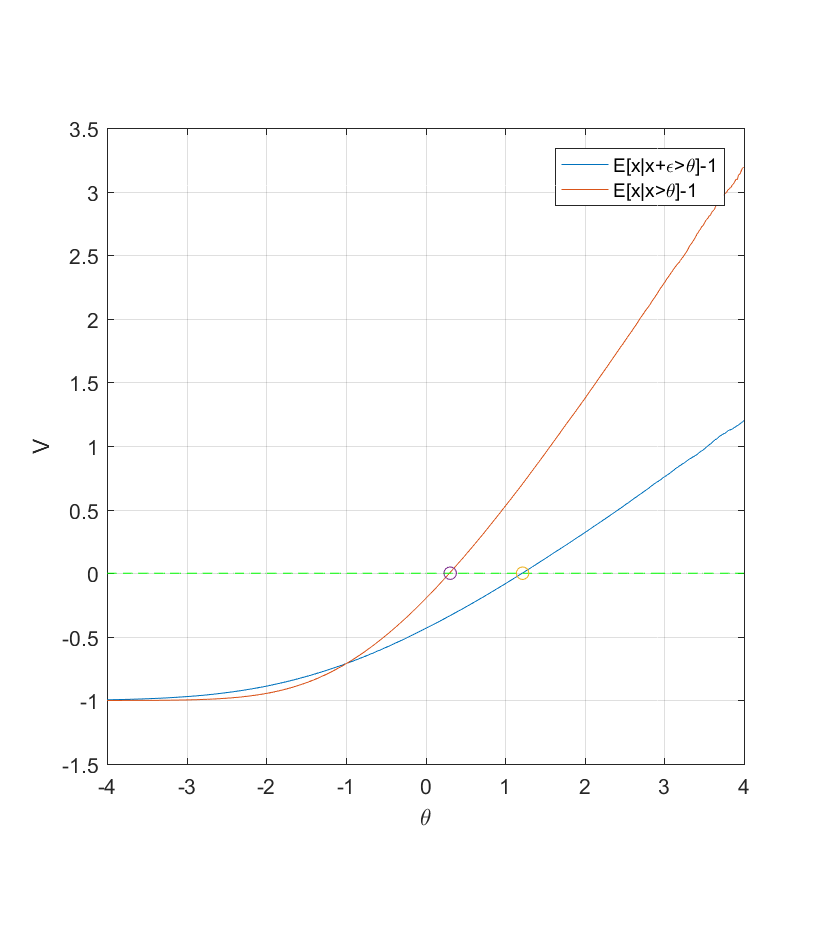
 big surprises (remember that the first data point counts as one!), then the probability of a new surprise for your next data point is
big surprises (remember that the first data point counts as one!), then the probability of a new surprise for your next data point is  . So if you expect
. So if you expect  data points in total, when
data points in total, when /N \ll 1") you can start to trust the estimates… assuming surprises are uncorrelated etc. Which you will not be certain about. The progression towards greater precision may be anything but dull.
you can start to trust the estimates… assuming surprises are uncorrelated etc. Which you will not be certain about. The progression towards greater precision may be anything but dull.
 , and the center of mass of the polyhedron is just the sum of the simplex centers of mass weighted by their volumes:
, and the center of mass of the polyhedron is just the sum of the simplex centers of mass weighted by their volumes:  . The volume of a simplex is
. The volume of a simplex is \mathrm{det}(X_j)") where
where ![X_j=[x_{1j};x_{2j};\ldots;x_{Dj}]](http://s0.wp.com/latex.php?latex=X_j%3D%5Bx_%7B1j%7D%3Bx_%7B2j%7D%3B%5Cldots%3Bx_%7BDj%7D%5D&bg=ffffff&fg=000000&s=0 "X_j=[x_{1j};x_{2j};\ldots;x_{Dj}]") , the matrix made by sticking together the coordinate vectors of a simplex. Once we know this we can project the center of mass onto the plane of a face by finding its nullspace (the higher dimensional counterpart to a normal)
, the matrix made by sticking together the coordinate vectors of a simplex. Once we know this we can project the center of mass onto the plane of a face by finding its nullspace (the higher dimensional counterpart to a normal) \vec{n}") . Finally, to check whether the projection is inside the face, we can look at the matrix A where each column is the coordinates of one of the faces minus
. Finally, to check whether the projection is inside the face, we can look at the matrix A where each column is the coordinates of one of the faces minus  and the final row just ones, and solve for Ax=b where b is zero except for a one in the last row (
and the final row just ones, and solve for Ax=b where b is zero except for a one in the last row (


 ), but the number of stable faces also increases exponentially with D (as $latex 2^{0.9273 D}$).
), but the number of stable faces also increases exponentially with D (as $latex 2^{0.9273 D}$).
D})=0.8407 D \ln(2) / \ln(D-1) \propto D/\ln(D)") . Even high-dimensional polytopes will stop flipping quickly in general. (A unistable polytope on the other hand can run through at least half of its faces, so there are some very slow ones too).
. Even high-dimensional polytopes will stop flipping quickly in general. (A unistable polytope on the other hand can run through at least half of its faces, so there are some very slow ones too). (if they were optimally distributed it would be
(if they were optimally distributed it would be  ). At the same time, if N is relatively small compared to D (the polytope is simplex-like), the average diameter (the longest edge) of each face seems to approach
). At the same time, if N is relatively small compared to D (the polytope is simplex-like), the average diameter (the longest edge) of each face seems to approach  . Why? I think this is because
. Why? I think this is because ") , the mean of a flipped k=2 Weibull distribution that shows up because of
, the mean of a flipped k=2 Weibull distribution that shows up because of  . Faces hence tends to be fairly wide unless N is large compared to D, but there will typically always be a few very narrow ones that are tricky to balance on.
. Faces hence tends to be fairly wide unless N is large compared to D, but there will typically always be a few very narrow ones that are tricky to balance on.") around the normal projection point (which is at distance d from the center of mass) where the vertical projection can intersect the face. Only parts of the hypersphere surface that are inside the face represent orientations that are stable. Even an unstable face can (sometimes) be stabilized if you turn it so that the tilted projection is inside, but for sufficiently high angles the hypersphere will be bigger than the face and it cannot be stable.
around the normal projection point (which is at distance d from the center of mass) where the vertical projection can intersect the face. Only parts of the hypersphere surface that are inside the face represent orientations that are stable. Even an unstable face can (sometimes) be stabilized if you turn it so that the tilted projection is inside, but for sufficiently high angles the hypersphere will be bigger than the face and it cannot be stable.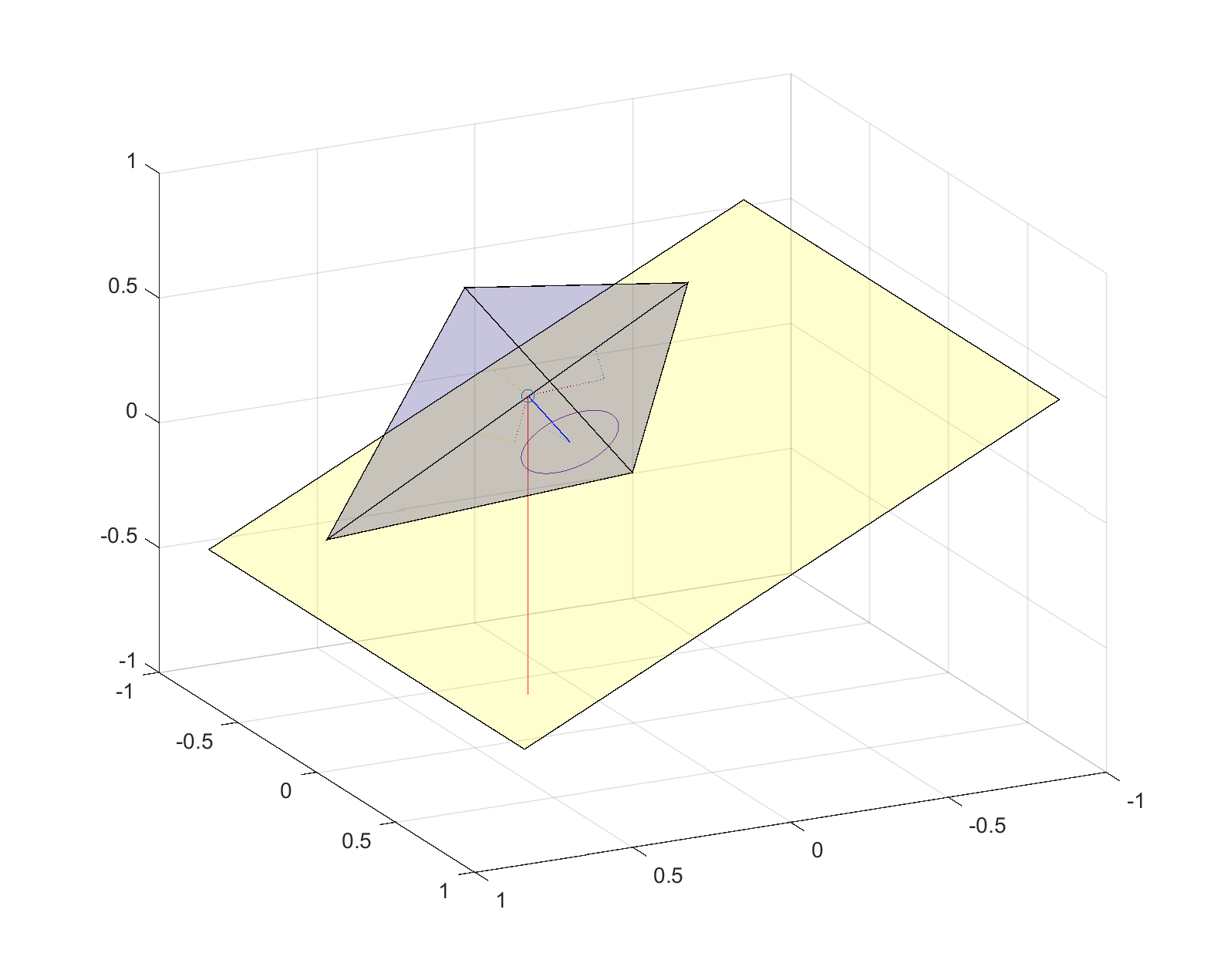
 the first condition might be tougher to meet than the second, but this is just a guess.
the first condition might be tougher to meet than the second, but this is just a guess.
